対象読者
「Python 並列処理」でググってたどり着いたPython, 並列処理の初心者の方。
並列処理を使ったことはあるけど、概念をよく知らない方。
async, threading, multiprocessing の違いがわからない方。
そんな方々に向けて、3つの手法の概要について、イメージ図も交えてざっくりと説明する記事です。
こまかいことはいいから実装だけ見せろ!
という方は、こちら にサンプルコードを載せています。
async, threading, multiprocessing の概要
Pythonで並列処理したい時に使える3つの手法「async」「threading」「multiprocessing」を紹介します。本記事では小難しい話はせずに、概要とイメージの話にとどめたいと思います。
「そんなことはどうでもいいから実装方法を教えてくれ!」という方は、一番メジャーなThreadingの実装をここに載せているので参照してください。が、本質的な理解をしたいなら記事の順に見ていくことをお勧めします。
スレッド数とコア数に着目した分類表
| スレッド数 | プロセス数 | CPUコア数 | 区分 | |
|---|---|---|---|---|
| async | 1 | 1 | 1 | 非同期処理 |
| threading | N | 1 | 1 | 並行処理 |
| multiprocessing | 1(1コアあたり) | N | N | 並列処理 |
※ 本記事ではざっくりとした理解を目的とするため、スレッドとプロセスとコア、非同期処理と並列処理と並行処理の違いについて詳細には取り扱いません。気になる方は下記の記事などをご参考ください。
async
スレッド数もコア数も1 だから並列処理じゃなくない? というツッコミは正解です。正確には並列処理ではなくて「非同期処理」といいます。フロントエンドのJavascriptから始めた方にはなじみが深いかもしれませんが、「非同期処理」と「並列処理」は全く違う概念なのでご注意ください。
処理の概要としては、最初に複数のリクエストを投げておいて、レスポンスが全部帰ってくるまで待ち、応答が揃ってから処理を再開します。
これにより、応答に 3~7秒(平均5秒)かかるスクレイピングを100回行う場合、同期処理なら500秒程度かかるところ、asyncを使った非同期処理なら7,8秒程度で実行できます。
(外部との通信で時間がかかるような処理を「IOバウンドな処理」、CPUの演算時間が大きい処理を「CPUバウンドな処理」と言うそうです)
threading
スレッドを分割し、並行処理を実行できる基本的なライブラリです。とりあえず処理を複数に走らせたいなら、これを使えばいいと思います。
ただし、完全な並列処理をしているのではなく、「タスクを高速に切り替えている」だけです。
そんなわけで、threading で解決できない問題が2つあります。
-
大量の演算処理計算を行う場合。
threading は1プロセスが処理を切り替えながら疑似的な並列処理をしているだけなので、こなせる演算量が増えるわけではなく、高速化が見込めません。 -
シビアなタイミング制御が必要になる処理。
例えば30FPS以上の高レートでストリーミング動画処理を行う場合、音声処理のスレッド処理に時間がかかってしまうと、動画の処理タイミングにスレッドが動いておらず、フレームが飛んでしまう現象が発生します。
これらの問題を解決したい場合は、次に紹介するmultiprocesssingを使いましょう。
multiprocessing
Pythonにおいて、multiprocessingはCPUのコアを複数扱うことで並列化を達成しています。
PCを選ぶときに「デュアルコア」とか「クアッドコア」というワードを聞いたことはあるでしょうか? CPUに搭載されている物理的なコアを複数活用することで、高速化を実現しています。
つまり、threadingは1人が複数のタスクをこなすに対して、multiprocesssingは3人に分身してタスクをこなすようなものです。
その結果、threading ではなしえなかった、大量計算の高速化や、シビアなタイミング制御も可能になります。
イメージでなんとなく理解する
文字だけだと意味が分かりにくいという(私のような)方向けに、イメージ図を作ってみました。
以下のワークフローを例に、それぞれの並列化がどんな処理をしているのかを考えます。
- 書類を書く
- 書類を送る
- 返送を待つ(待ち時間)
- 書類をチェックする(演算処理)
- 上記の書類を、計3枚やり取りする
普通の同期処理の場合
ワークフローを何も考えずに同期処理で実装すると、書類を1通送るごとに待ちが発生します。
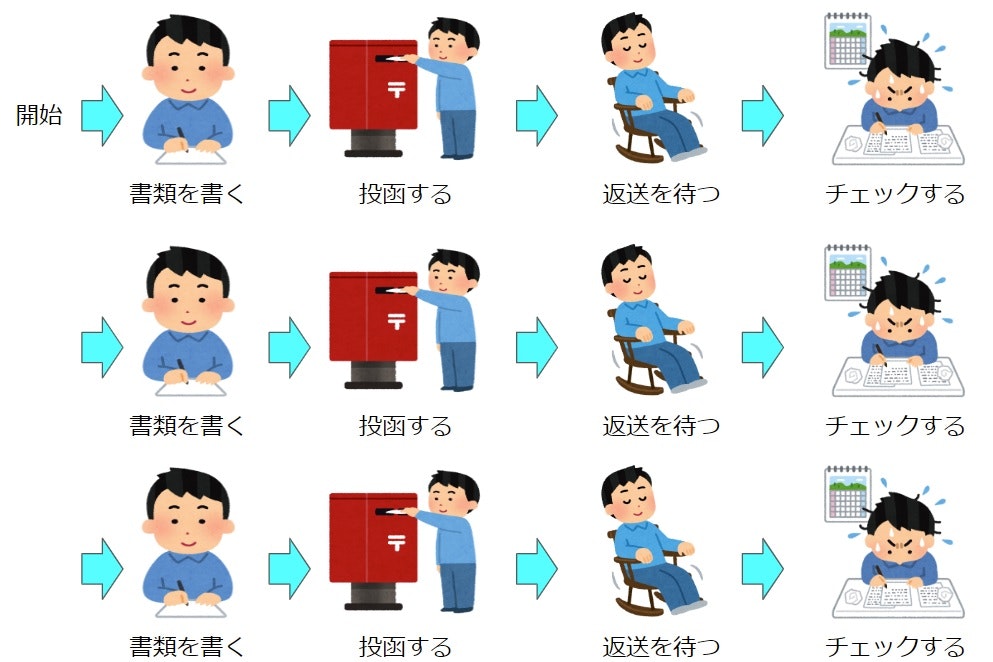
この図では3枚だけですが、これが10枚、50枚、100枚と増えていくと……
ともあれ、スクレイピングやAPIアクセスで待ち時間が発生する場合改善の余地があります。
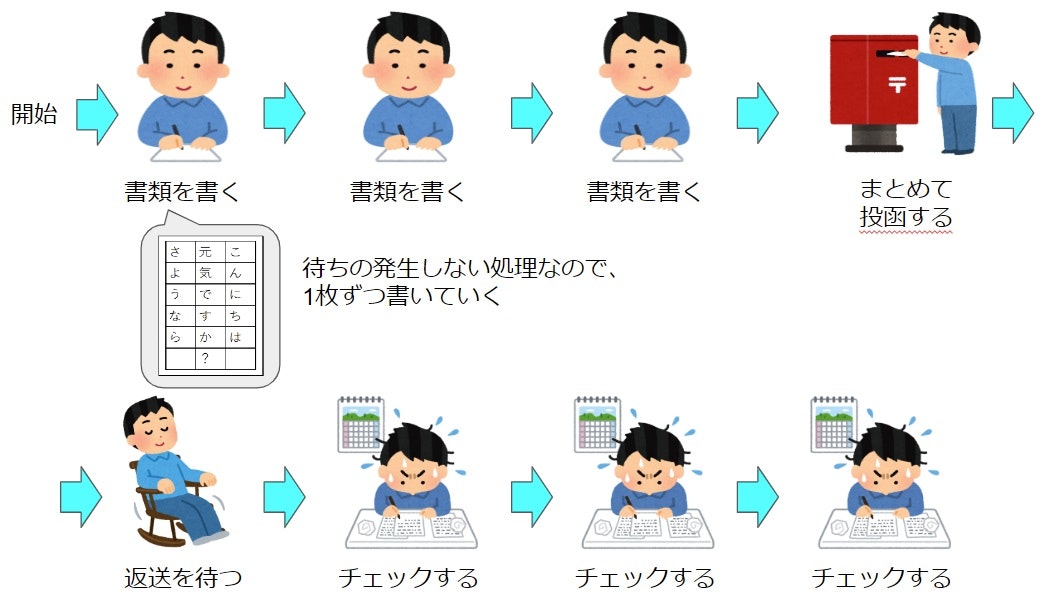
async (非同期処理)の場合
非同期処理の特徴は「まとめて投函」して「全部戻ってくるまで待つ」ところです。同期処理に比べて、待ち時間が1回で済んでいますね。
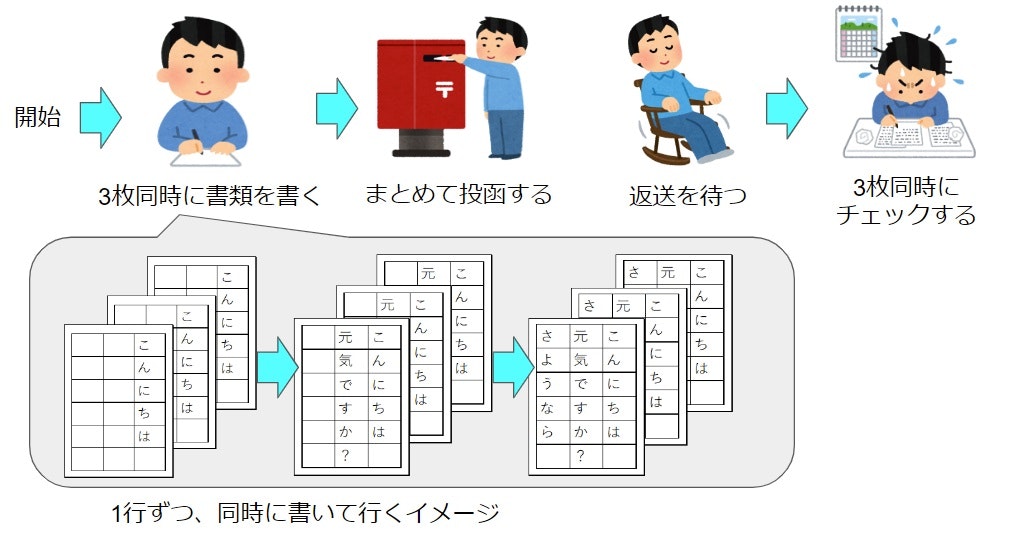
threading (マルチスレッド処理)の場合
マルチスレッド処理では高速でタスクを切り替えながら実行します。
例えばですが、先生に怒られて反省文として原稿用紙1枚に「ごめんなさい」と書けと言われた時、「ごごごごごごごご」「めめめめめめめめめ」...と横向きに埋めていくようなものですね。
※余談ですが、ThreadingはIO待ちが発生した時に切り替わるようで、print("~~~")での出力命令中にスレッドが切り替わってコンソールがぐちゃぐちゃになることはないようです(参考サイト)
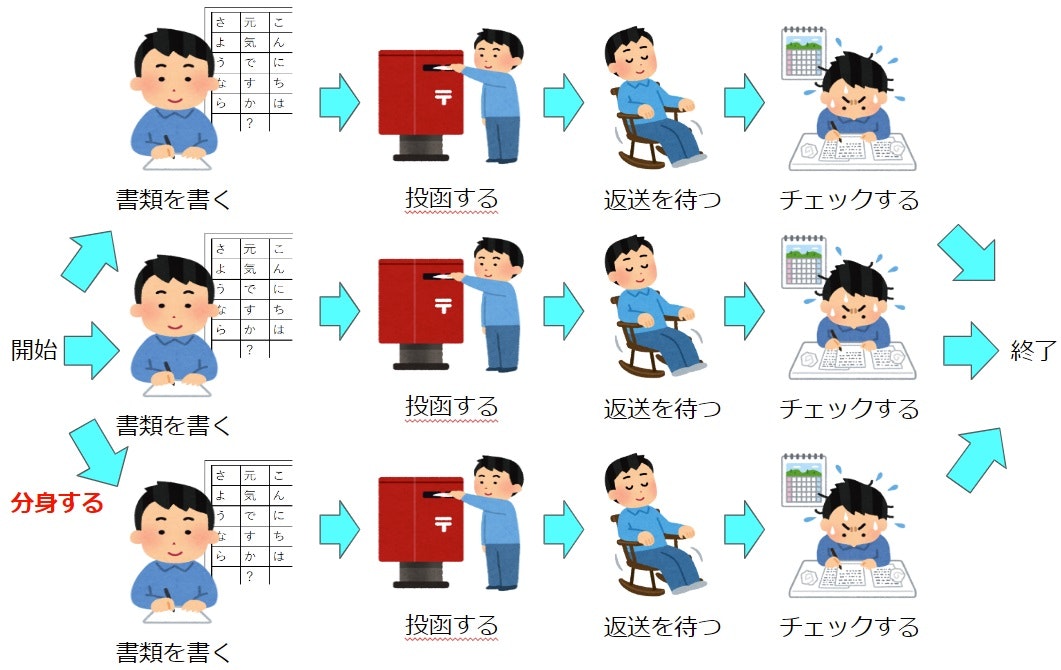
multiprocessing (マルチプロセス処理)の場合
唯一、分身の術を使える処理です。3人でやれば3倍速いよね、という理論で並列化と高速化ができます。
asyncとthreadingでは『チェックする』作業を高速化できないのですが、それができてしまうmultiprocessingの強みです。
「並列処理すれば早くなるはず」という思い込みでthreading を使いそうですが、CPUバウンドな処理だとmultiprocessing しか高速化ができない点は罠だと個人的に思います。
結局何を使えばいいの?
個人的な意見ですのでご了承ください。
async がオススメ
- Webスクレイピング
- 時間のかかる外部APIをたくさん叩くとき
処理終了後に待ち合わせるような処理に向いています。
async はシングルスレッドなのですが、シングルスレッドで動作すること自体が強み だと思います。
スレッドセーフな設計が必要がなく、ステップ実行によるデバッグも容易なので、とても開発しやすいです(個人的にはこれがとても嬉しい)。
なので、async で簡単に実装できそうならasync を使うのが楽そうです。
threading がオススメ
- 処理の内容、目的がバラバラ
- スレッドごとにある程度のリアルタイム性を持たせたい
- 特定の処理を常に動かし続けたい(ストリーミング処理、バックグラウンド処理など)
- とりあえず並行処理をしたい
あまり深いことを考えないのであれば、これを使っておけばOKだと思います。
asyncは処理終了を待ち合わせる使い方が基本なので、各処理内でwhileループをまわしたり長期間処理を継続するならthreading の方が便利です。
あと一応、WebスクレイピングやAPI処理をthreadingで実装しても全く問題ないです。ただし、共有リソースを使う場合はLock機能などを使ってスレッドセーフな実装を心がけましょう。
multiprocessing がオススメ
- 大量の演算処理
- シビアなタイミング制御が必要な並列処理
エラーが出た時の原因追及含め、実装難易度は高いと思います。
ですが、multiprocessing でしか解決できない場面というのもあるので、頭に留めておくといいでしょう。
またCPUのコアを複数使うので、当然CPUコア数以上の並列化はできません(公式ドキュメントに、使用可能なコア数を返してくれる関数を発見しました)。
実装例
先ほどのイメージ図になぞらえて、書類を送る処理を再現してみました。
処理速度についても記載しています。
async
※クリックすると開きます
async のソースコード
import asyncio
import time
def write_mail(number):
print(f"書き込み({number}番目):こんにちは")
time.sleep(0.03)
print(f"書き込み({number}番目):げんきですか?")
time.sleep(0.03)
print(f"書き込み({number}番目):さようなら")
time.sleep(0.03)
# 非同期処理を行う関数は、async と付けなければならない
async def send_mail(number):
print(f"送付({number}番目)")
await asyncio.sleep(5)
def check_response(number):
hoge=0
# 無駄な計算
for i in range(1, 100000000):
hoge += i/3 + i/5 + i/7 + i/9 + i/11
print(f"確認OK({number}番目)")
async def task():
# 書類書き込み(同期処理)
write_mail(1)
write_mail(2)
write_mail(3)
# メール送付&待ち(非同期処理) <- ここだけ非同期処理
await asyncio.gather( # 処理が全部終わるまで待つ
send_mail(1),
send_mail(2),
send_mail(3)
)
# 書類チェック(同期処理)
check_response(1)
check_response(2)
check_response(3)
if __name__ == '__main__':
start_time=time.time()
asyncio.run(task())
print(f"かかった時間:{time.time()-start_time}s")
実行結果
書き込み(1番目):こんにちは
書き込み(1番目):げんきですか?
書き込み(1番目):さようなら
書き込み(2番目):こんにちは
書き込み(2番目):げんきですか?
書き込み(2番目):さようなら
書き込み(3番目):こんにちは
書き込み(3番目):げんきですか?
書き込み(3番目):さようなら
送付(1番目)
送付(2番目)
送付(3番目)
確認OK(1番目)
確認OK(2番目)
確認OK(3番目)
かかった時間:79.07915616035461s
threagding
threading のソースコード
import threading
import time
def write_mail(number):
print(f"書き込み({number})番目:こんにちは")
time.sleep(0.03)
print(f"書き込み({number}番目):げんきですか?")
time.sleep(0.03)
print(f"書き込み({number}番目):さようなら")
time.sleep(0.03)
def send_mail(number):
print(f"送付({number}番目)")
time.sleep(5)
def check_response(number):
hoge=0
# 無駄な計算
for i in range(1, 100000000):
hoge += i/3 + i/5 + i/7 + i/9 + i/11
print(f"確認OK({number}番目)")
def task(thread_num):
write_mail(thread_num)
send_mail(thread_num)
check_response(thread_num)
if __name__ == '__main__':
start_time=time.time()
t1 = threading.Thread(target=task, args=(1,))# 引数を与える時はこんな感じで
t2 = threading.Thread(target=task, args=(2,))
t3 = threading.Thread(target=task, args=(3,))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(f"かかった時間:{time.time()-start_time}s")
実行結果
書き込み(1番目):こんにちは
書き込み(2番目):こんにちは
書き込み(3番目):こんにちは
書き込み(2番目):げんきですか?
書き込み(3番目):げんきですか?
書き込み(1番目):げんきですか?
書き込み(2番目):さようなら
書き込み(3番目):さようなら
書き込み(1番目):さようなら
送付(2番目)
送付(3番目)
送付(1番目)
確認OK(2番目)
確認OK(3番目)
確認OK(1番目)
かかった時間:98.54962968826294s
multiprocessing
multiprocessing のソースコード
from multiprocessing import Process
import time
def write_mail(number):
print(f"書き込み({number}番目):こんにちは")
time.sleep(0.03)
print(f"書き込み({number}番目):げんきですか?")
time.sleep(0.03)
print(f"書き込み({number}番目):さようなら")
time.sleep(0.03)
def send_mail(number):
print(f"送付({number}番目)")
time.sleep(5)
def check_response(number):
hoge=0
# 無駄な計算
for i in range(1, 100000000):
hoge += i/3 + i/5 + i/7 + i/9 + i/11
print(f"確認OK({number}番目)")
def task(process_num):
write_mail(process_num)
send_mail(process_num)
check_response(process_num)
if __name__ == '__main__':
start_time=time.time()
t1 = Process(target=task, args=(1,))
t2 = Process(target=task, args=(2,))
t3 = Process(target=task, args=(3,))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(f"かかった時間:{time.time()-start_time}s")
実行結果
書き込み(1番目):こんにちは
書き込み(2番目):こんにちは
書き込み(3番目):こんにちは
書き込み(1番目):げんきですか?
書き込み(2番目):げんきですか?
書き込み(3番目):げんきですか?
書き込み(1番目):さようなら
書き込み(3番目):さようなら
書き込み(2番目):さようなら
送付(3番目)
送付(2番目)
送付(1番目)
確認OK(1番目)
確認OK(2番目)
確認OK(3番目)
かかった時間:46.62982702255249s
その他の手法
ナウい並列処理ライブラリ"concurrent"
Python3.2から実装されたらしい、concurrentというライブラリがあります。
特長として、
- threadingとmultiprocessingの機能を、1行変えるだけで使い分けられる
- スレッド数を制限して使いまわす機能が、ライブラリ内に用意されている
など、便利なことができるらしいです。
今回の記事でPython の並列処理についてざっくりと理解したら、今後はこちらを使うのがいいのかもしれませんね。かくいう私も使ったことはないですが、今度並列処理の実装が必要になったらこちらを使ってみたいです。
分散処理ライブラリを使う
並列処理のごたごたした処理をもう書きたくない! という方は、分散処理ライブラリをインストールしてしまうのも一つの手です。
例えばPythonの分散処理ライブラリであるrayを使用すると、並列処理の煩雑な部分をすべてお任せして簡単に実装することができます。
さらに、AWS Glue のようなクラウドサービスなどではrayに最適化されたプラットフォームも用意されているので、より大規模な処理を書きたいときにもサクッと移行することができます。とにかく便利で最初の敷居が低いので、ぜひ使ってみてください。
始めるには以下のサイトが良さげです。
最後に
イメージ・概要を掴むためのまとめでした。
Pythonを学び始めたころ、何も知らずに「Python 並列処理」と調べて大いにハマった自分と、同じような境遇の方の助けになれば幸いです。
スレッド・コア・プロセスの違い、並行・並列処理の違い、GILによって1プロセス1スレッドしか動作できないことなど、突き詰めるともっと深い話になってしまうので、そちらは先輩方の記事にお任せしたいと思います。
補足(2022/7/28)
標準的な並行処理モジュールでは高速化ができず、マルチコアにすると並列処理ができるという話でしたが、Javaなどの他言語だと事情が違ったりします。ライブラリによってはマルチコアでなくても高速化を見込めたりします。その理由は「Python GIL」や「スレッド プロセス コア 違い」などとググると出てくるかと思いますが、注意が必要なのはThreadingで高速化できないのはあくまでPythonの特徴、ということです。
参考
- asyncの詳しい説明が載っているサイト
- 並列処理について、導入から深い部分まで丁寧に解説されているサイト
- スライド形式でわかりやすいサイト
- 並列処理関連の単語がわかるようになるサイト
- スレッド数とプロセス数の違いについて書いてあったサイト
- 並行&並列, 同期&非同期などの整理
変更履歴
2022/07/22 タイトルを少しだけ変更。記述ミスを修正。
2022/07/28 補足を追加。
2022/07/29 補足の文章を少し修正。