
初めまして、ベガコーポレーション データ戦略部 分析基盤エンジニア 新卒3年目の武本です。分析基盤の構築をメインに担当しています。digdag+embulkでデータを同期するツールを開発しFargateでHA構成にしたのでご紹介したいと思います。
入社した当初の分析基盤の状況
分析基盤をご紹介する前に開発前の状況についてお話しします。
かれこれ2年前の話になりますが私が入社した頃にBigQueryを導入しようという話になっていました。
分析に必要なデータを一元管理し、クエリを高速に実行させ、ストレスなく分析業務ができる環境を作るというのが一つの目標でした。
とりあえず必要になったのがBigQueryでデータを一元管理する為のシステム。つまり分析基盤の構築です。
分析基盤構築の開発に当たって調べているとdigdag + embulkでデータを同期させるという事例が多く、弊社もdigdag + embulkで分析基盤を構築しようという話になりました。
最初に作った分析基盤のシステム
Digdag Serverというリッチなシステムがあることは知っていたのですが最速で構築する為に digdag + embulk + cronでシステムを稼働させました。詳しくは後日初期運用編の記事を公開します。
初期運用システムの課題点
- 冗長化ができていない
- オートスケーリングに対応できていない
- ログ管理ができていない
- 実行ステータスの確認がslack通知
システムが止まればデータが同期できない状況。将来同期するデータが増えるとパンクする。ログや実行ステータスなどの運用面でも不安。といくつか課題が残りました。
そこでdigdagをserver化し、Fargateで運用しようという話になりました。
digdag・embulkとは
本題に入る前に直々出ているdigdagとembulkについて説明します。
digdagとは
digdagとはワークフローエンジンのソフトウェアです。複数個のタスクのパイプラインを構築し、実行やスケジューリングを行うことができます。Digdag UIでは実行ステータスやログを確認することができる為監視もしやすいツールになっています。今回はDigdag Serverの主な機能・実装方法についてご紹介します。
embulkとは
embulkとはデータ転送に特化したマルチソースバルクデータローダーです。RDSからBigQuery、S3からRDSなどのデータ転送をプラグインを用いて行うことができます。digdagから実行することによりデータ取得とデータ加工をワークフローに則って行うことができます。
Fargateで運用するメリット・デメリット
一般的に言われているFargateのメリット・デメリットに準じますが、Digdag Serverと組み合わせた場合、どのように影響するのか説明します。
メリット
-
冗長化しやすい
必要なタスク数を設定しておけば、もし落ちたとしても自動で再起動してくれるので運用が楽。 -
リソースの拡張・縮小がしやすい
連携するデータ量が増えて処理が重くなればタスク定義でスペックをあげれば良いだけなので管理が楽。
一回で移動させるデータ量が少ないが連携するテーブルが多いという場合はサービスのタスク数を増やしてあげるだけで対応できる。 -
EC2を管理しなくていい
EC2の場合OSやミドルウェアなどの構築や設定操作が必要だが省くことができ、簡易的に構築・管理することが可能。 -
Fargate SPOTで運用
Digdag Serverはフロー管理している為処理の途中で落ちたとしても自動で再実行してくれる。
SPOTとの相性も良く費用を抑えて運用ができている。
デメリット
-
パブリックIPの固定割り当てができない
Digdag UIの閲覧やdigdagのクライアントモードコマンドを実行する際にroute53とALBを噛ませる必要性がある。 -
sshやdocker execが使えない
Digdag Server構築時は実行ログを吐き出させて、その実行ログを元に開発することになる。パラメータストア経由で設定する環境変数のチェックなどの確認が面倒。
デメリットは開発面での話で運用面でのデメリットはほぼないという印象です。
【本題】Digdag Server構築とFargate運用
構成図
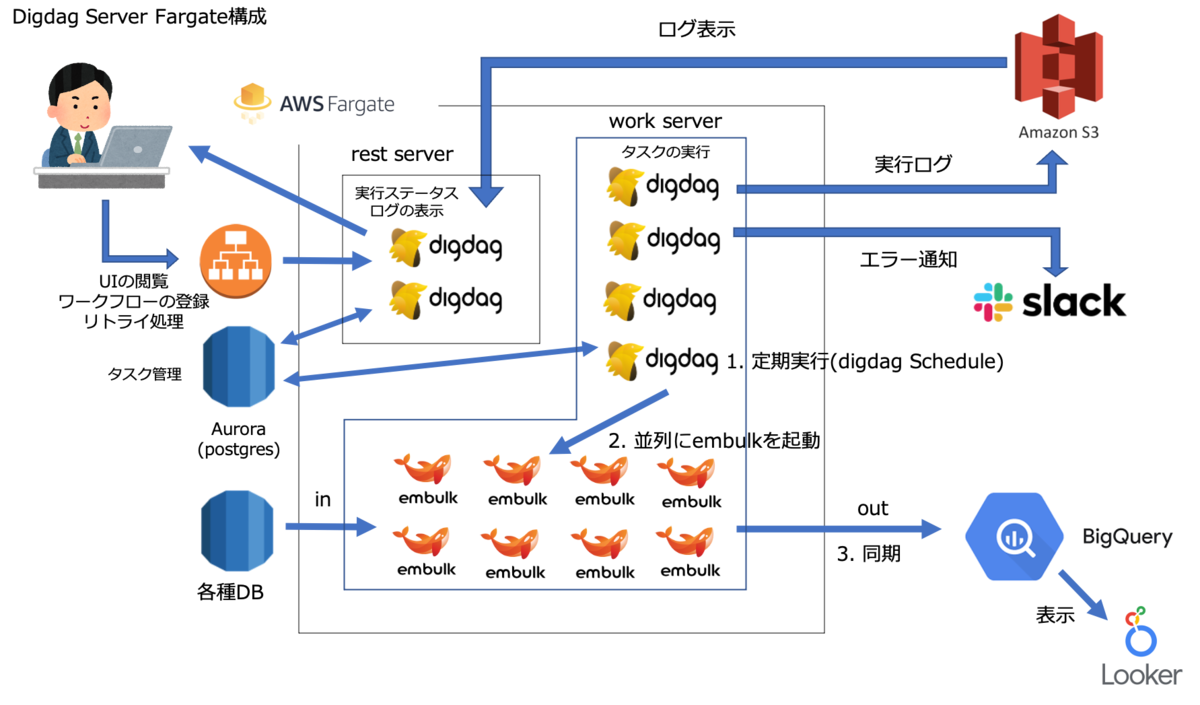
Digdag Server構築
Digdag Server構築に必要な要素についてお話します。
構成
| 役割 | |
|---|---|
| Fargate | サービスの起動やスケーリングを行う |
| rest server | Digdag UI と API Server |
| work server | digdag タスク実行用Server |
| Aurora(postgres) | フロー定義と実行タスクの保存 |
| Amazon S3 | タスク実行ログの保存 |
| 各種DB | 同期元 |
| BigQuery | 同期先(データレイク & データウェアハウス) |
| Looker | BIツール |
rest serverとwork serverの違い
rest serverは Digdag UIとクライアントコマンド受付用です。実行するワークフローをrest serverで登録しwork serverで実行させるという流れになります。rest serverは重たい処理を行わない為リソースは少なくても問題ありません。ECSのタスク定義で調整しつつ環境に合う設定を行ってください。
実装上での違いは指定するオプションとconfigファイルです。
rest
# --disable-executor-loop: Workflow executorを無効にする
# --disable-local-agent: Agentを無効にする
# --disable-scheduler: Schedule Executorを無効にする
digdag server --disable-executor-loop --disable-local-agent --disable-scheduler --config /etc/digdag/server-rest.properties
work
digdag server --config /etc/digdag/server-work.propertie
configファイルに関しては最後の方で説明します。
定期実行(Scheduling workflow)
定期実行はdigファイルの先頭に以下の内容を書くだけで設定できます。
timezone: Asia/Tokyo
schedule:
daily>: 07:00:00
詳しくはScheduling workflowをご覧ください。
タスク管理(PostgreSQL)
digファイルやタスクキューなどはPostgreSQLに保存します。Amazon AuroraのPostgreSQLを採用しています。
以下の設定をdigdagのconfigファイルに記入。 POSTGRES_USERなどもそのまま記入してください。実際の値はパラメータストアに登録し、コンテナ起動時にsedコマンドで上書きします。
database.type = postgresql
database.user = <POSTGRES_USER>
database.password = <POSTGRES_PASSWORD>
database.host = <POSTGRES_HOST>
database.port = <POSTGRES_PORT>
database.database = <POSTGRES_DATABASE>
database.maximumPoolSize=32
ログ管理(S3)
以下の設定をdigdagのconfigファイルに記入
log-server.type = s3
log-server.s3.endpoint = <S3_ENDPOINT>
log-server.s3.bucket = <S3_BUCKET>
log-server.s3.path = <S3_PATH>
log-server.s3.direct_download=false
指定したPATHにログが出力され、Digdag UI上でログの確認できるようになります。
オートスケーリング(Fargate)
データ連携する時間だけworkのタスク数を増やすという運用をしています。
具体的にはdigdagから以下のシェルスクリプトを実行してタスク数を変更します。
#!/bin/sh
# AutoScaling($1は引数。必要なタスク数をdigdag側で指定)
aws ecs update-service \
--cluster hoge \
--service digdag_work \
--desired-count $1
# スケーリングされるまで待機
aws ecs wait services-stable \
--cluster hoge \
--services digdag_work
# タスク数取得
task=$(aws ecs describe-services \
--cluster hoge \
--services digdag_work \
| jq '.services[].runningCount')
message="task数: ${task}"
#タスク数出力
echo $message
if test $task -ne $1 ; then
exit 1
fi
digdag側では _parallelをtrueにすることで並列処理を行い、スケーリングの効果を発揮させます。
# スケールアウト
+scaling:
sh>: shell/autoscaling.sh 5
_error:
_export:
message: "Failed Scale Out"
slack>: slack/failed-to-sync.yml
# テーブル取得
+sync:
for_each>:
data: ${source_table} # json形式の取得時の情報(select, from, whereなど)
_parallel: true
_do:
call>: run_embulk.dig
まだ試してはいませんが digdag 0.10.0で 並列化する数を制限できるようになったみたいなのでスケーリングと組み合わせると綺麗な実装になるかもしれません。 Release 0.10.0
digdag secrets
embulkでアクセスするDBの接続情報はdigdag secrets で管理します。
以下の設定をdigdagのconfigファイルに記入
digdag.secret-encryption-key = <SECRET_ENCRYPTION_KEY>
詳しくはsecret-encryption-key をご覧ください。
続いて、接続するDBの情報をjson形式で保存します。
gcp.credentialは必要に応じて用意してください。
{
"host": "xxxxxxxx",
"user": "xxxxxxxx",
"password": "xxxxxxxx",
"db": "xxxxxxxxx"
}
以下のコマンドを実行してdigdag serverに登録します。
# secretsキーデプロイ
digdag secrets --project ${PROJECT} --set @${DIR}/secrets.json -e ${URL}
# gcp.credential設定
digdag secrets --project ${PROJECT} --set gcp.credential=@credential.json -e ${URL}
-eオプションでURLを指定して登録できます。rest serverのURLを指定してください。
ログイン認証
ログイン認証はbasic認証で行います。アクセスするのはrest serverなのでrest serverのみ設定を行います。
以下の設定をrest用のconfigファイルに記入
server.authenticator-class = io.digdag.standards.auth.basic.BasicAuthenticator
basicauth.username = <USERNAME>
basicauth.password = <PASSWORD>
basicauth.admin = true
Digdag UIの認証設定
ログイン画面は機能していない為、Google Chrome のプラグイン simple-modify-headers を利用します。
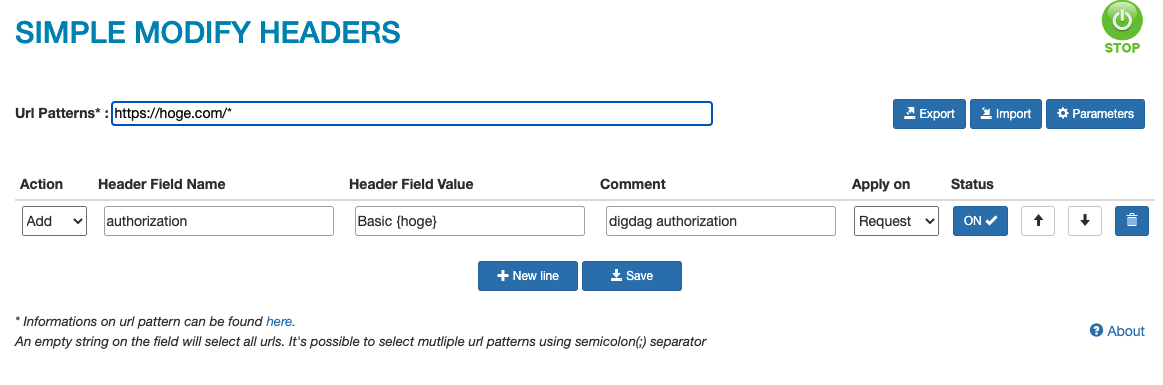
クライアントコマンドの認証設定
以下のコマンドで設定します。
export DIGDAG_CONFIG=client.http.headers.Authorization="Basic {hoge}"
{hoge} の取得方法
echo -n '{username}:{password}' | openssl base64
{username}と{password}はそれぞれ basicauth.username と basicauth.passwordです。
コンテナ起動時のコマンド
設定はECSのタスク定義にて行います。
コンテナ起動時に以下のことを行います。
- configファイルの上書き
ログイン認証・PostgreSQL・S3などのユーザー名、パスワードはAWSのパラメータストアで管理する。
パラメータストアの値を反映させる為、sedコマンドでconfigファイルを上書きする。 - PostgreSQLの起動
- Digdag Serverの起動
configファイルと実行オプションでrestとworkを切り分ける。
rest server起動用のシェルスプリクト
#!/bin/sh
sed -i -e "s/<USERNAME>/${USERNAME}/" \
-e "s/<PASSWORD>/${PASSWORD}/" \
-e "s/<POSTGRES_USER>/${POSTGRES_USER}/" \
-e "s/<POSTGRES_PASSWORD>/${POSTGRES_PASSWORD}/" \
-e "s/<POSTGRES_HOST>/${POSTGRES_HOST}/" \
-e "s/<POSTGRES_PORT>/${POSTGRES_PORT}/" \
-e "s/<POSTGRES_DATABASE>/${POSTGRES_DATABASE}/" \
-e "s/<S3_ENDPOINT>/${S3_ENDPOINT}/" \
-e "s/<S3_BUCKET>/${S3_BUCKET}/" \
-e "s~<S3_PATH>~${S3_PATH}~" \
-e "s/<SECRET_ENCRYPTION_KEY>/${SECRET_ENCRYPTION_KEY}/" /etc/digdag/server-rest.properties
# rendering pgpass file
echo "$POSTGRES_HOST:$POSTGRES_PORT:$POSTGRES_DATABASE:$POSTGRES_USER:$POSTGRES_PASSWORD" > ~/.pgpass
chmod 600 ~/.pgpass
# postgresが起動するまで待機
COUNT=0
until psql -h "$POSTGRES_HOST" -U "$POSTGRES_USER" -p "$POSTGRES_PORT" -d "$POSTGRES_DATABASE" -c '\l' || test $COUNT -gt 10 ; do
let COUNT++
sleep 10
done
# Digdag Server起動
# --disable-executor-loop: Workflow executorを無効にする
# --disable-local-agent: Agentを無効にする
# --disable-scheduler: Schedule Executorを無効にする
digdag server --disable-executor-loop --disable-local-agent --disable-scheduler --config /etc/digdag/server-rest.properties
work用もシェルスプリクトを用意するが、異なるのはDigdag Server起動のオプションとログイン認証の部分のみ。
Digdag ServerのオプションについてはCommand referenceをご覧ください。
まとめ
今回はDigdag ServerをFargateで動かす方法についてご紹介しました。FargateでDigdag Serverを動かしてみるという記事は少なく手探り状態で開発しましたが、期待以上のシステムになったのではないのかなと思っています。digdag導入初期の運用やデータの同期方法については別の記事でご紹介したいと考えています。