※ これから記載する事項は、私が所属する会社とは一切関係のない事柄です。
今回は注文管理などの大量データのインポートで利用される Bulk API 2.0 を利用してみたいと思います。
Bulk API 2.0 とは(2023/07時点)
まず Bulk API は非同期でレコード操作を行えるため、大量データを扱う際に向いていますが、Bulk API 2.0 は下記の点でさらに優れているようです。(ヘルプ「Bulk API 2.0 と Bulk API の違いは?」より)
- クライアント側のコード記述を削減する。
- ジョブ状況の監視を簡単にする。
- 失敗したレコードを自動再試行する。
- 並列処理をサポートする。
- 取得またはクエリワークフローの完了に必要なコール数を削減する。
- バッチ管理を簡素化する。
一方で、あまり大量なデータではない(2000レコード以下)ような場合は、REST (Composite など) または SOAP による「一括」の同期呼び出しを行うことが推奨されています。
レコード操作を API を利用して行う場合にどの API を利用したらいいかわからない場合はヘルプ「どの API を使用するか?」を参照してみてください。
今回やること
今回は下記の CSV ファイルを取り込んで取引先を追加したいと思います。
Name,Description,NumberOfEmployees
TestAccount1,Description of TestAccount1,30
TestAccount2,Another description,40
TestAccount3,Yet another description,50
完成イメージはこちらです。
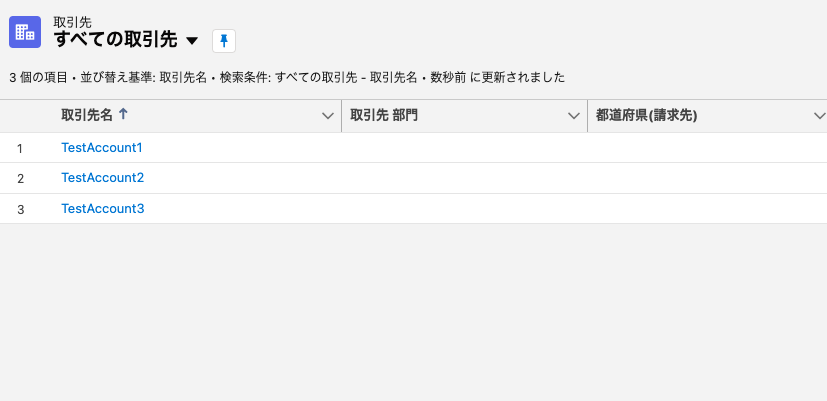
手順
1. 接続アプリケーションの作成とアクセストークンの取得
今回は「OAuth 2.0 ユーザ名パスワードフロー」を利用して API を利用するための認証を行います。
現在では「OAuth 2.0 ユーザ名パスワードフロー」はデフォルトで無効なので他のフローを利用するか、このフローを有効にする設定を行ってください。
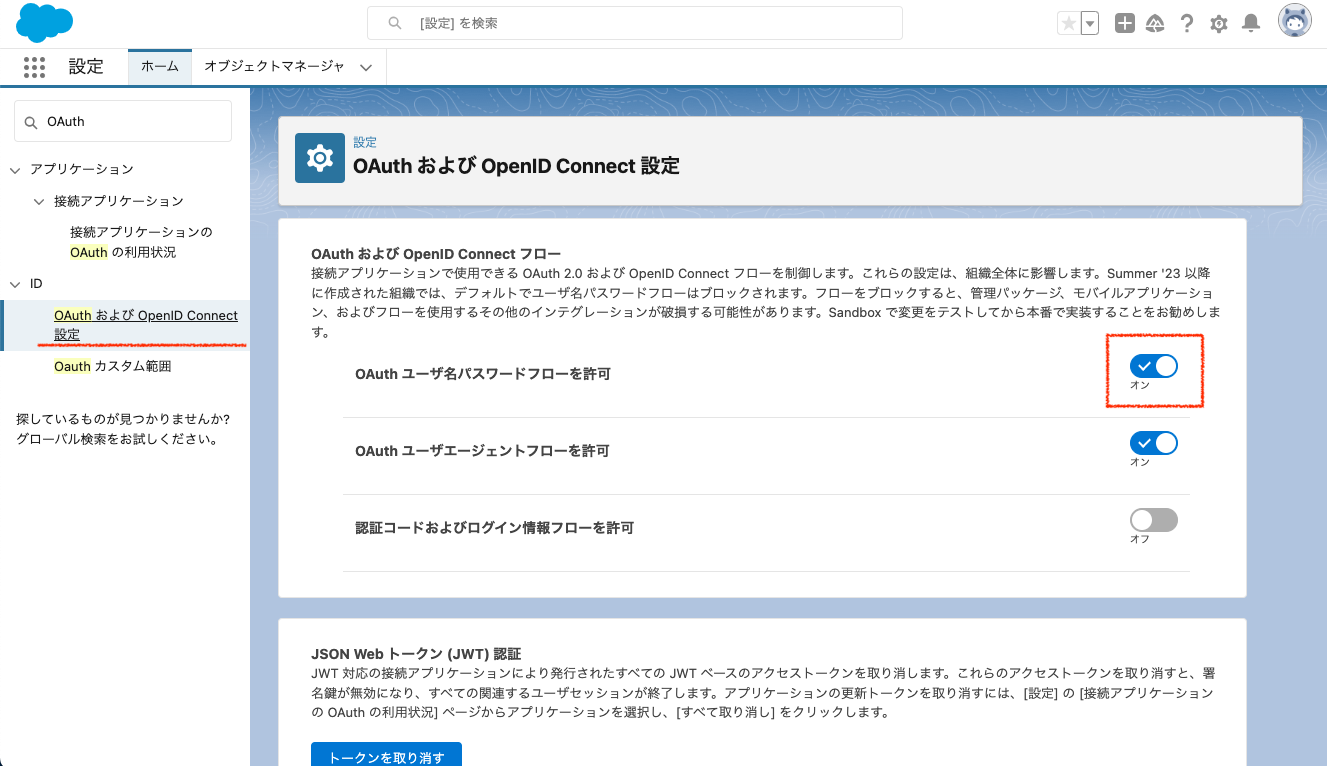
接続アプリケーションの作成
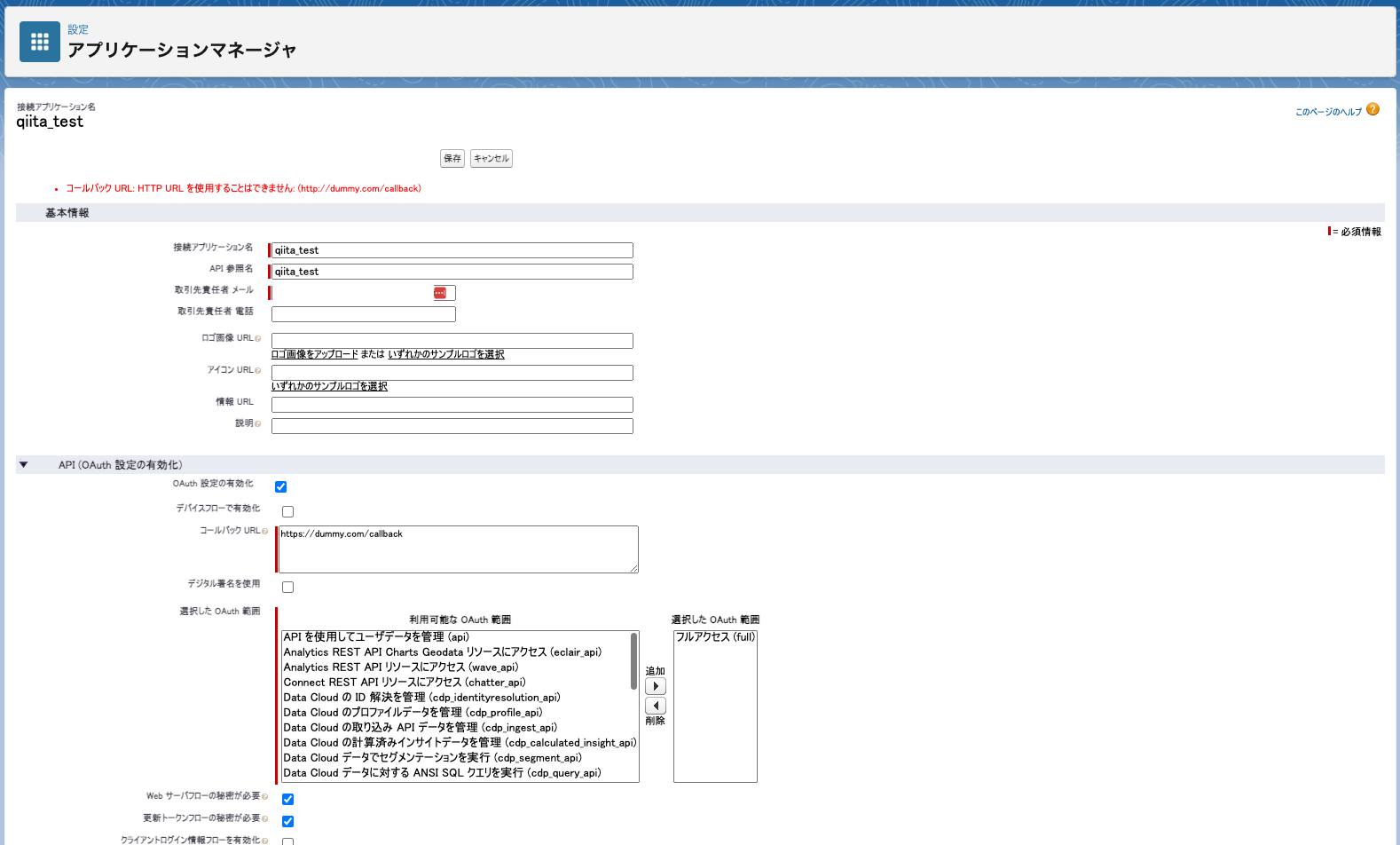
設定 > Lightning Experience アプリケーションマネージャ に遷移し、右上の [新規接続アプリケーション] をクリックし、下記のような接続アプリケーションを設定しました。
設定 > Lightning Experience アプリケーションマネージャ から作成したアプリケーションの右横のメニューリストから [参照] を選択しアプリケーションの詳細を表示させた上で [コンシューマの詳細を管理] ボタンをクリックする
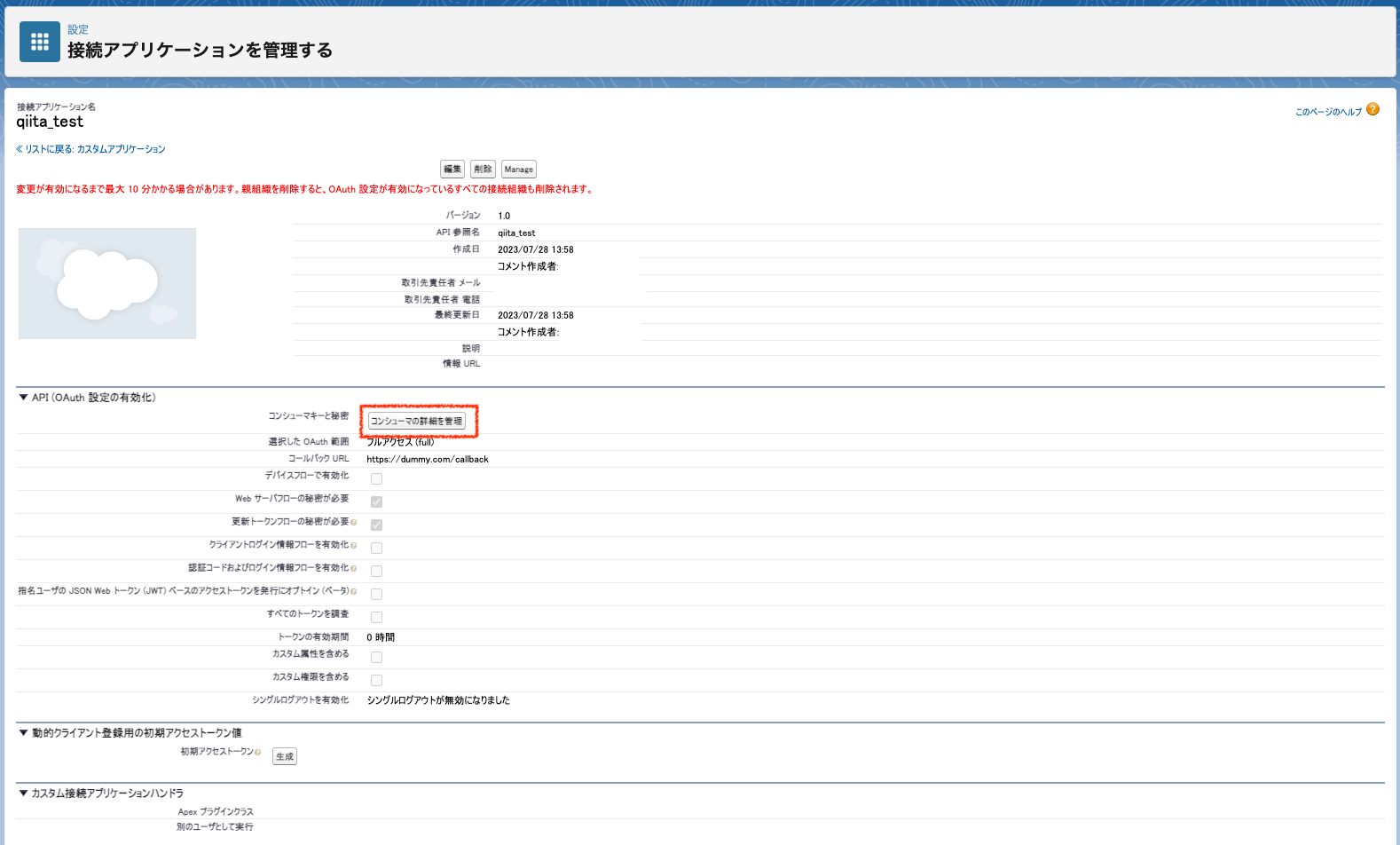
認証後、下記のように認証情報が表示されるのでコピーしておく。
アクセストークンの取得
下記のように HTTP リクエストを行います。
POST /services/oauth2/token HTTP/1.1
Host: login.salesforce.com
Content-Type: application/x-www-form-urlencoded
grant_type=password&username={ユーザID}&password={ユーザパスワード}&client_id={接続アプリケーションのコンシューマ鍵}&client_secret={接続アプリケーションのコンシューマの秘密}
するとレスポンスの access_token にアクセストークンが入っているので取得しておきます。後に記載している {accessToken} をこのアクセストークンに置き換えてください。
{
"access_token": "{アクセストークン}",
"instance_url": "https://XXXXXXXX.my.salesforce.com",
"id": "https://login.salesforce.com/id/XXXXXXXX/XXXXXXXX",
"token_type": "Bearer",
"issued_at": "1690520603751",
"signature": "XXXXXXXX"
}
2. ジョブの作成
まずジョブの作成を行います。
下記のような HTTP リクエストで今回は CSV を利用して取引先(Account)を作成(insert)するためのジョブを作成します。
POST /services/data/v57.0/jobs/ingest HTTP/1.1
Host: XXXXXX.my.salesforce.com
Content-Type: application/json
Authorization: Bearer {accessToken}
Request Body:
{
"operation" : "insert",
"object" : "Account",
"contentType" : "CSV"
}
下記のようなレスポンスが返ってくるのでのちに jobId として利用するので id を取得しておきましょう。
{
"id": "XXXXXXXX",
"operation": "insert",
"object": "Account",
"createdById": "XXXXXXXX",
"createdDate": "2023-07-28T05:09:42.000+0000",
"systemModstamp": "2023-07-28T05:09:42.000+0000",
"state": "Open",
"concurrencyMode": "Parallel",
"contentType": "CSV",
"apiVersion": 57.0,
"contentUrl": "services/data/v57.0/jobs/ingest/XXXXXXXX/batches",
"lineEnding": "LF",
"columnDelimiter": "COMMA"
}
3. CSV アップロード
次に CSV のアップロードを行います。
下記のリクエストで CSV をアップロードしています。 Content-Type が text/csv になっていることがポイントです。リクエストが成功すると HTTP ステータスとして 201 Created が返却されます。
PUT /services/data/v57.0/jobs/ingest/{jobId}/batches HTTP/1.1
Host: XXXXXX.my.salesforce.com
Content-Type: text/csv
Authorization: Bearer {accessToken}
Request Body:
Name,Description,NumberOfEmployees
TestAccount1,Description of TestAccount1,30
TestAccount2,Another description,40
TestAccount3,Yet another description,50
4. 処理の開始
CSV のアップロードが終了したら、処理を開始します。
下記のように UploadComplete というステートを送信するとジョブが終了し、キューの送信され、処理が開始されます。
PATCH /services/data/v57.0/jobs/ingest/{jobId} HTTP/1.1
Host: XXXXXX.my.salesforce.com
Content-Type: application/json
Authorization: Bearer {accessToken}
Request Body:
{
"state": "UploadComplete"
}
リクエストが成功すると下記のようにジョブの状態が返却されます。
{
"id": "XXXXXXXX",
"operation": "insert",
"object": "Account",
"createdById": "XXXXXXXX",
"createdDate": "2023-07-28T05:09:42.000+0000",
"systemModstamp": "2023-07-28T05:09:42.000+0000",
"state": "UploadComplete",
"concurrencyMode": "Parallel",
"contentType": "CSV",
"apiVersion": 57.0
}
5. ジョブの状況の取得
処理の状況を確認します。
下記のリクエストでジョブの状況を確認します。
GET /services/data/v57.0/jobs/ingest/{jobId} HTTP/1.1
Host: XXXXXX.my.salesforce.com
Authorization: Bearer {accessToken}
下記のようなレスポンスが返却されますが、state が JobComplete になっていたら処理が完了しています。その他の state の値については要求の処理方法をご覧ください。
{
"id": "XXXXXXXX",
"operation": "insert",
"object": "Account",
"createdById": "XXXXXXXX",
"createdDate": "2023-07-28T05:09:42.000+0000",
"systemModstamp": "2023-07-28T05:09:53.000+0000",
"state": "JobComplete",
"concurrencyMode": "Parallel",
"contentType": "CSV",
"apiVersion": 57.0,
"jobType": "V2Ingest",
"lineEnding": "LF",
"columnDelimiter": "COMMA",
"numberRecordsProcessed": 3,
"numberRecordsFailed": 0,
"retries": 0,
"totalProcessingTime": 482,
"apiActiveProcessingTime": 391,
"apexProcessingTime": 54
}
6. 処理に成功したレコードの取得
最後に正常に処理されたレコードの CSV を取得します。
下記のリクエストで処理に成功したレコードの CSV を確認します。 他に失敗したレコードや未処理のレコードの取得も可能です。
GET /services/data/v57.0/jobs/ingest/{jobId}/successfulResults HTTP/1.1
Host: XXXXXX.my.salesforce.com
Accept: text/csv
Authorization: Bearer {accessToken}
下記のような CSV で返却されます。
"sf__Id","sf__Created",Name,Description,NumberOfEmployees
"XXXXXXXX","true","TestAccount1","Description of TestAccount1","30"
"XXXXXXXX","true","TestAccount2","Another description","40"
"XXXXXXXX","true","TestAccount3","Yet another description","50"
オープンソースライブラリの Bulk API 状況
今回は純粋な HTTP API を利用しましたが、下記のようなライブラリでも Bulk API の利用は可能ですが一部 Bulk 2.0には対応してないようです。
- Java
- wsc (Bulk API 2.0 に対応してなさそう)
- salesforce-bulkv2-java
- Node.js
- Python
- simple-salesforce (Bulk 2.0 の作成中の形跡はあるが現状未対応のよう)
- salesforce-bulk-python
- Golang
- simpleforce (Bulk API には対応していない)
- go-sfdc