概要
RDSで出力してくるSlow QueryをDatadog Log Management上で可視化したのでその手順を書きます。
ログのParseに苦戦したのでよかったら参考にしてください。
環境
- RDS(MySQL) 5.7.19
事前準備
Slow QueryのログをCloudWatch Logsに出力
事前にRDSでSlow QueryのログをCloudWatch Logsに出力させておく必要があります。
詳細はこちらを参照
CloudWatch LogsをSlow QueryをDatadogに転送
CloudWatch Logsに出力されたSlow QueryをDatadogに転送する必要があります。
仕組みとしては、Lambdaファンクションを作成し、そのLambdaファンクションによっログを収集、Datadogへと送信します。こちらもすでに手順があるため、省きます。
詳細はこちらを参照
手順
ここからがDatadogの設定です。
上記手順を行うと、何もParseされていない状態でLog Managementに転送さていることが確認できます。
ログサンプルはこちら
# Time: 2019-06-28T03:52:11.487326Z
# User@Host: username[username] @ [172.31.xxx.xxx] Id: 6825
# Query_time: 2.492360 Lock_time: 0.000149 Rows_sent: 1 Rows_examined: 12269468
SET timestamp=1561693931;
SELECT
hogehoge
FROM
fugafuga
今回はこのログをParseしていきます。
パイプラインの作成
Datadogにログインし、Log Explorer → Configuration → New Pipline でパイプラインを作成します。
パイプラインは、転送されて来たログをフィルタリングし、それらを後述するプロセッサに適用していきます。
設定例)

プロセッサーの作成
作成したパイプラインを選択し、Add Processorをクリックしてプロセッサ追加します。
プロセッサで意味のある情報や属性を半構造化テキストから抽出して、それらを後述するファセットとして再利用できます。
Select the processor typeは、Grok Parserを選択し、Define 1 or multiple parsing rulesは以下のようにしました。
MyRule ^\# Time: %{date("yyyy-MM-dd'T'HH:mm:ss.SSSSSSZ"):date}\n+\# User@Host: %{notSpace: user1}\[%{notSpace: user2}\] @ \[%{ip: host}\] Id:[\x20\t]+%{number: id}\n+\# Query_time: %{number: query_time} Lock_time: %{number: lock_time} Rows_sent: %{number: rows_sent} Rows_examined: %{number: rows_examined}\n+ *SET timestamp=%{number: timestamp};\n+%{regex("[a-zA-Z].*"):query}.
かなり見づらいですが、ポイントは
- 改行は、
\n+で書く - #は、
\でエスケープする - 可変な部分はMatcher(
%{}の箇所)を記載する
です。
Matcherについては、こちらを参照してください。
確認
Log Exploer → Searchに移動し、左メニューのFilterをrdsで絞ると、Slow QueryログがParseされていることが確認できます。
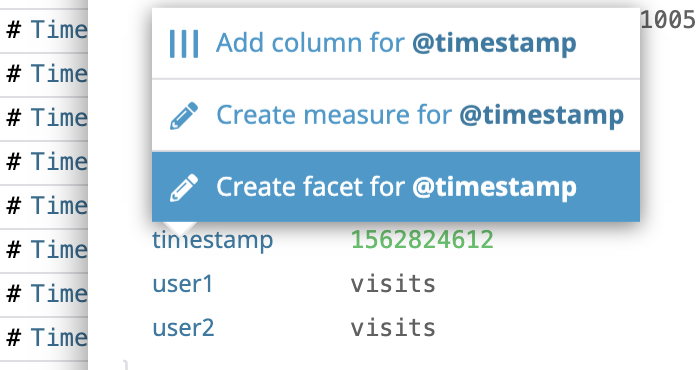
ファセットと追加
あとはFilterしたいAttributeのfacetを作成すれば、Filterで検索できるようになります。
facetの作成方法は、当該ログのAttributeを開いて、クリックしてCreate Facetするだけです。
例)
確認
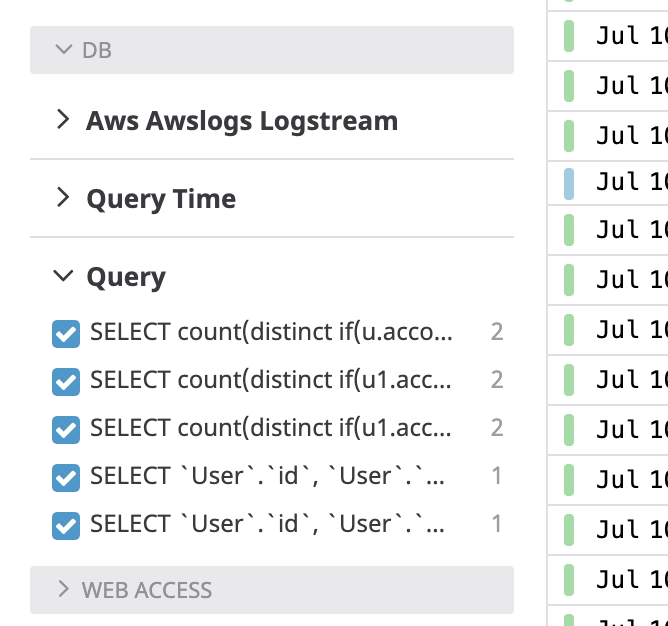
例えば、queryのfacetを追加することで、以下のようにクエリごとにFilterすることが可能となります。
またSlow Queryの件数を元にアラート出したりもできるようになります。
例 Queryの場合)
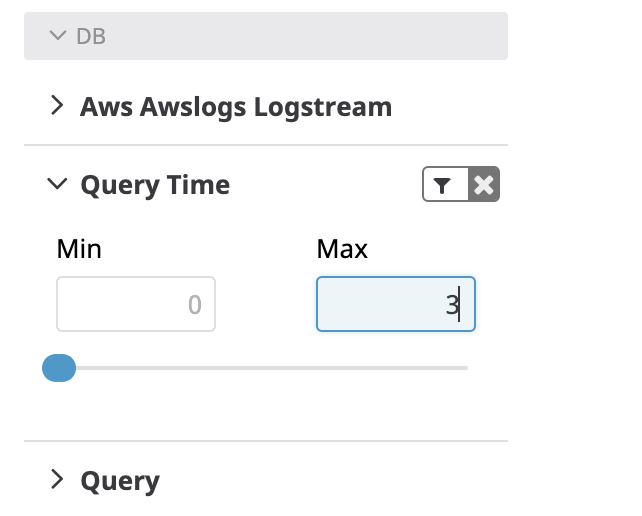
Query Timeのfacetを作成しておくと、Query TimeでFilterをかけれます。
例 Query Timeの場合)
最後に
Datadog Log Managementは、Filter機能、結構使えそうです。どんどん活用していきたいと思います。