始めに
CUDAプログラムの実行時間を計測するための色々な方法のまとめ記事です。仕事に必要で自分なりに一生懸命に探した結果なのですが、もし間違っている場合は是非お教えください。
結論から言うと並列処理の最適化をする場合ならNVIDIA Visual Profilerが役に立ちます。コードの最適化の為なら最後のTimer registerを使う方法が一番いいと思います。
ホスト側でCUDAカーネルの実行時間を測定する
CUDAプログラムは基本的にホスト側が主導権を持つ為、タイマーもまたホスト側でコントロールすることが自然な考え方ではあります。その為、関連した関数や文書は容易に探す事ができます1。
CudaEvent
NVIDAで用意した時間測定のためのイベントです。GPUの時間を記録するcudaEvent_tオブジェクトとそのオブジェクトに時間を刻むcudaEventRecord関数を使います。この方法を使えばカーネルが立ち上がる時間からカーネル終了を待つ時間を含めた完全な実行時間を測定できます。
CPU側で測定する事と同じような感じでが、大きな違いはcudaDeviceSynchronizeを使わなくてもカーネル終了後にスタンプを取ってくれる点、ストリームに対応してくれる点にあります。
cudaEvent_t start, stop;
// 初期化
cudaEventCreate(&start);
cudaEventCreate(&stop);
// 開始時間を記録
cudaEventRecord(start);
my_kernel<<<N,M>>>();
// 終了時間を記録
cudaEventRecord(stop);
//イベントの終了を待つ。
cudaEventSynchronize(stop);
// ms単位でstartとstopの差を計算する。
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
// 終了処理
cudaEventDestroy(start);
cudaEventDestroy(stop);
NVIDIA Visual Profilerを使用する
名前の通りNVIDIAで提供するProfilerです2。詳細なGPUの動きを見る事ができます。 タイムラインで見せてくれるのでストリームを使ってプログラムを作る時とかに便利です。実行時間だけではなく様々な情報を見せてくれるのでCUDAプログラムを最適化する時に重宝します。
しかし、実行時間はカーネル単位で計測する為、マクロ関数みたいに扱われる__device__関数を含めコード単位の実行時間は教えてくれません。
 *画面は注釈2のスライドから持ってきました。最近のProfilerとは異なります。*
*画面は注釈2のスライドから持ってきました。最近のProfilerとは異なります。*
デバイス側でCUDAコードの実行時間を測定する
CudaEventやVisual Profilerではカーネルの中の実行時間を測定する事ができません。普通、GPUでは並列処理を行うため、カーネルの中で各々のスレッドのでの実行時間を測定するというのはあまり美しくないように感じますが、最適化の時に特定のコードの実行時間を測定するためにはデバイス側で時間を記録するCudaEventみたいな方法が必要になります。
Clock function
デバイス側での時間を測定する方法を検索するとclock()やclock64()関数が主に出てきます。clock()関数はper-multiprocessor counterを返してくれるデバイス関数です3。cudaGetDevicePropertiesを使えばGPUのClock frequencyを獲得できますのでclockで時間を割り出す事ができます。
しかし、Dynamic parallelismを使う場合、新しいカーネルがロンチされる時にスレッドブロックが違うSMに飛ばされるたりしますのでper-multiprocessor counterを読むこの方法は使えません4。
# include <stdio.h>
# include <cuda.h>
__global__ void my_kernel(long long *clocks)
{
// 開始時間を記録
long long start = clock64();
printf("Start Clock : %ld\n", start);
// 終了時間を記録
clocks[0] = clock64() - start;
}
int main()
{
int clock_rate = 0;
int device = 0;
long long *clock_data;
long long *host_data;
// クロックレートを取る
cudaDeviceGetAttribute(&clock_rate, cudaDevAttrClockRate, device);
// 初期化
host_data = (long long *)malloc(sizeof(long long));
cudaMalloc(&clock_data, sizeof(long long));
my_kernel<<<1, 1>>>(clock_data);
// GPUで測定したクロックの差を持ってくる
cudaMemcpy(host_data, clock_data, sizeof(long long), cudaMemcpyDeviceToHost);
// ms単位で時間に換算する。
printf("Elapsed clock cycles: %ld, clock rate: %d kHz\n", host_data[0], clock_rate);
printf("Execution time: %f ms\n", host_data[0]/(float)clock_rate);
return 0;
}
Timer register
GPUの中には様々な目的のレジスタがあり、その中ではglobaltimerという名前通りの64bitのns単位グローバルタイマーが存在します5。そう言ったレジスタはPTX ISAのmovインストラクションを使って読み取ることができます。globaltimerはns単位での経過した時間そのものを返してくれます。グローバルタイマーな為、Clock functionと違ってDynamic parallelismも使えます。
# include <stdio.h>
# include <cuda.h>
__global__ void my_kernel(long long int *time)
{
long long int start, stop;
// 開始時間を記録
asm volatile("mov.u64 %0, %globaltimer;" : "=l"(start));
printf("Some Event... \n");
// 終了時間を記録
asm volatile("mov.u64 %0, %globaltimer;" : "=l"(stop));
time[0] = stop - start;
}
int main()
{
long long int *time_data;
long long int *host_data;
// 初期化
host_data = (long long *)malloc(sizeof(long long int));
cudaMalloc(&time_data, sizeof(long long int));
my_kernel<<<1, 1>>>(time_data);
cudaMemcpy(host_data, time_data, sizeof(long long int), cudaMemcpyDeviceToHost);
// ns単位でのstartとstopの差
printf("Execution time: %lld ns\n", host_data[0]);
return 0;
}
比較
全てのタイマーを一緒にテストしてみました。
# include <stdio.h>
# include <cuda.h>
# define BILLION (1000000000)
__global__ void saxpy(int n, float a, float *x, float *y, long long *clocks, long long int *times)
{
long long start_clock;
long long int start_time, stop_time;
// 開始時間を記録
start_clock = clock64();
asm volatile("mov.u64 %0, %globaltimer;" : "=l"(start_time));
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
// 終了時間を記録
asm volatile("mov.u64 %0, %globaltimer;" : "=l"(stop_time));
clocks[0] = clock64() - start_clock;
times[0] = stop_time - start_time;
}
int main()
{
int N = 20 * (1 << 20);
float *x, *y, *d_x, *d_y;
// CPU Timer
struct timespec cpu_event_start, cpu_event_end;
struct timespec cpu_event_end_without_sync;
int64_t cpu_timer_in_nanoseconds = 0;
// Cuda Event Timer
cudaEvent_t gpu_event_start, gpu_event_stop;
float gpu_timer_in_milliseconds = 0;
// Device Clock Timer
long long *clock_data_h;
long long *clock_data_d;
int clock_rate = 0;
int device = 0;
// Device register Timer
long long int *time_data_h;
long long int *time_data_d;
// 初期化
x = (float*)malloc(N*sizeof(float));
y = (float*)malloc(N*sizeof(float));
cudaMalloc(&d_x, N*sizeof(float));
cudaMalloc(&d_y, N*sizeof(float));
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
// Cuda Event Timerの初期化
cudaEventCreate(&gpu_event_start);
cudaEventCreate(&gpu_event_stop);
// Device Clock Timerの初期化
clock_data_h = (long long *)malloc(sizeof(long long));
cudaMalloc(&clock_data_d, sizeof(long long));
cudaDeviceGetAttribute(&clock_rate, cudaDevAttrClockRate, device);
// Device register Timerの初期化
time_data_h = (long long *)malloc(sizeof(long long int));
cudaMalloc(&time_data_d, sizeof(long long int));
// 開始時間を記録(CPU)
clock_gettime(CLOCK_MONOTONIC, &cpu_event_start);//start time
// 開始時間を記録(GPU)
cudaEventRecord(gpu_event_start, 0);
saxpy<<<(N+511)/512, 512>>>(N, 2.0f, d_x, d_y, clock_data_d, time_data_d);
// シンク無しに終了時間を記録(CPU)
clock_gettime(CLOCK_MONOTONIC,&cpu_event_end_without_sync);
// 終了時間を記録(GPU)
cudaEventRecord(gpu_event_stop, 0);
// イベントの終了を待つ。
cudaEventSynchronize(gpu_event_stop);
cudaDeviceSynchronize();
// シンクありで終了時間を記録(CPU)
clock_gettime(CLOCK_MONOTONIC,&cpu_event_end);
cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(clock_data_h, clock_data_d, sizeof(long long), cudaMemcpyDeviceToHost);
cudaMemcpy(time_data_h, time_data_d, sizeof(long long int), cudaMemcpyDeviceToHost);
printf("Elapsed clock cycles: %ld, clock rate: %d kHz\n", clock_data_h[0], clock_rate);
// ns単位でstartとstopの差を計算する。
cpu_timer_in_nanoseconds = BILLION * (cpu_event_end.tv_sec-cpu_event_start.tv_sec)
+ cpu_event_end.tv_nsec - cpu_event_start.tv_nsec; // ns
printf("Execution time by cpu timer: %llu us\n", cpu_timer_in_nanoseconds/1000);
// ns単位でstartとstopの差を計算する。
cpu_timer_in_nanoseconds = BILLION * (cpu_event_end_without_sync.tv_sec-cpu_event_start.tv_sec)
+ cpu_event_end_without_sync.tv_nsec - cpu_event_start.tv_nsec; // ns
printf("Execution time by cpu timer without sync: %llu us\n", cpu_timer_in_nanoseconds/1000);
// ms単位でstartとstopの差を計算する。
cudaEventElapsedTime(&gpu_timer_in_milliseconds, gpu_event_start, gpu_event_stop);
printf("Execution time by gpu event timer: %f us\n", gpu_timer_in_milliseconds*1000);
// デバイス側で測定した結果
cudaEventElapsedTime(&gpu_timer_in_milliseconds, gpu_event_start, gpu_event_stop);
printf("Execution time by device clcok: %f us\n", clock_data_h[0]/(float)clock_rate*1000);
printf("Execution time by register: %f us\n", time_data_h[0])/1000;
// 終了処理
cudaEventDestroy(gpu_event_start);
cudaEventDestroy(gpu_event_stop);
return 0;
}
そして、その結果です。
Elapsed clock cycles: 21115, clock rate: 1380000 kHz
Execution time by cpu timer: 2328 us
Execution time by cpu timer without sync: 52 us
Execution time by gpu event timer: 2296.031982 us
Execution time by device clcok: 15.300725 us
Execution time by register: 15.300725 us
上の結果を以て整理します。
- CPU側のタイマーは
cudaDeviceSynchronize()の後で時間を測定しなければなりません。 - ホスト側のCPU timerとGPU event timerは似たようなカーネル実行時間を見せます。
- デバイス側のDevice clcokとGlobal timer registerも似たようなコード実行時間を教えてくれます。
おまけ
比較コードをNVIDIA Visual Profilerを使って分析してみました。
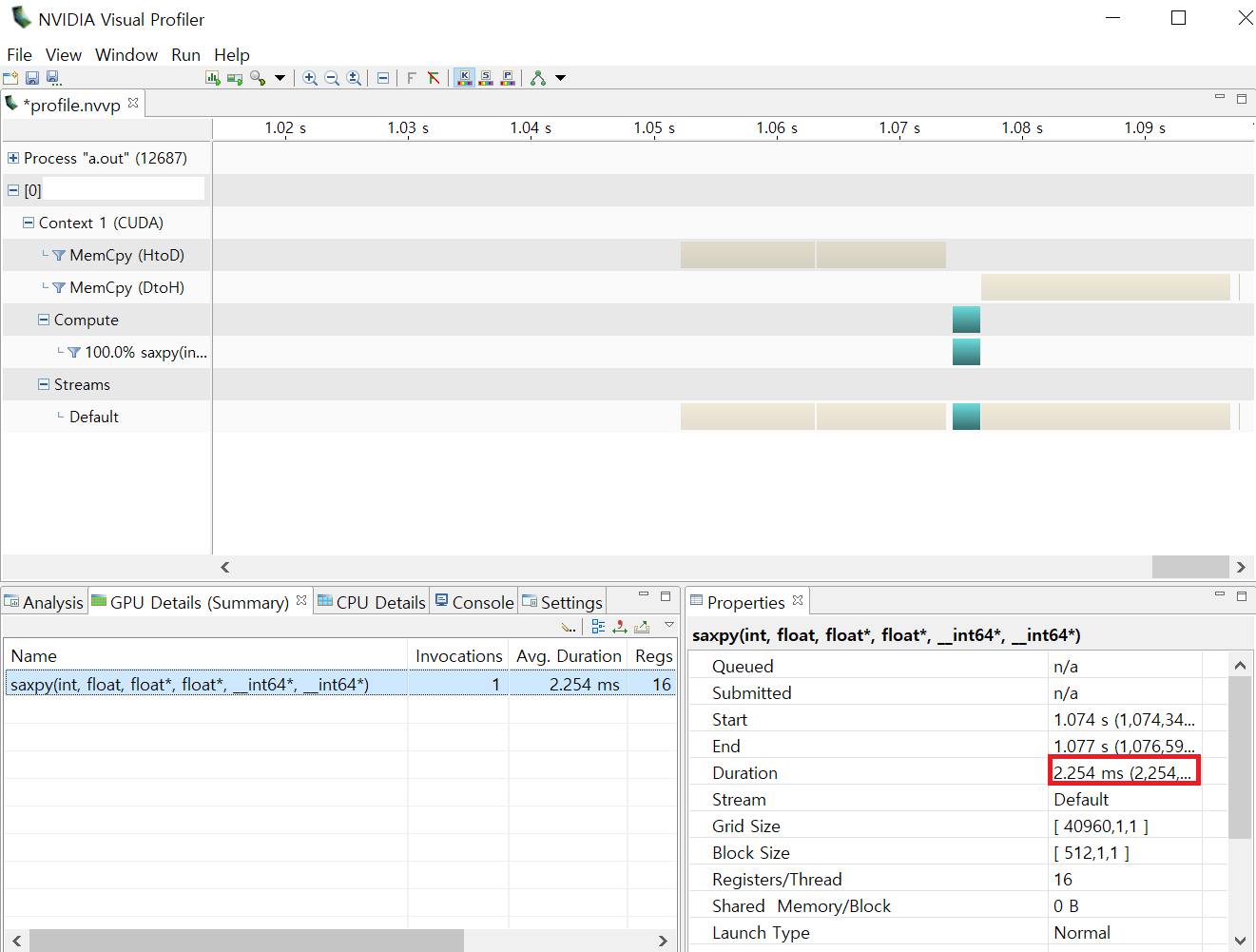
タイマーで測定した時間と似たような時間が掛かっている事が分かります。
-
How to Implement Performance Metrics in CUDA C/C++, https://devblogs.nvidia.com/how-implement-performance-metrics-cuda-cc ↩
-
Optimizing Application Performance with CUDA Profiling Tools, http://developer.download.nvidia.com/GTC/PDF/GTC2012/PresentationPDF/S0419B-GTC2012-Profiling-Profiling-Tools.pdf ↩
-
Cuda-c-programming-guide#time-function, https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#time-function ↩
-
NVIDIA Developer Forums - clock64() reversed, https://devtalk.nvidia.com/default/topic/935282/clock64-reversed/ ↩
-
parallel-thread-execution#special-registers-globaltimer, https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#special-registers-globaltimer ↩