本記事はAIによる要約を行った結果を記載しています。詳細は学習コンテンツを閲覧ください。
本記事について
Google Digital Leader公式の学習コンテンツである『Google Cloud Operations を使用したスケーリング』の講義内容を記載しています。
概要:コース全体の紹介
このコース「Scaling with Google Cloud Operations」は、組織がクラウドの力を最大限に活用するための、クラウド管理に関する一連の実践と戦略を学ぶことを目的としています。クラウド管理とは、クラウド上のインフラ、アプリ、サービスを管理・監視し、信頼性、パフォーマンス、セキュリティ、コストを最適化することです。
本コースでは、以下の3つの主要なトピックを学びます。
- 財務ガバナンス: Google Cloudがどのようにクラウド費用の管理を支援するか。
- 運用と信頼性: クラウドにおける最新の運用、信頼性、復元力の基本コンセプト。
- サステナビリティ: Google Cloudが組織のサステナビリティ目標達成にどう貢献するか。
第1部:財務ガバナンスとクラウド費用管理
クラウドへの移行に伴い、従来の予測可能な設備投資(資本支出)から、変動しやすい運用支出へと変化したことで、多くの組織で費用管理が大きな課題となっています。この管理にはIT部門だけでなく、財務やビジネス部門など、組織横断的な関与が不可欠です。
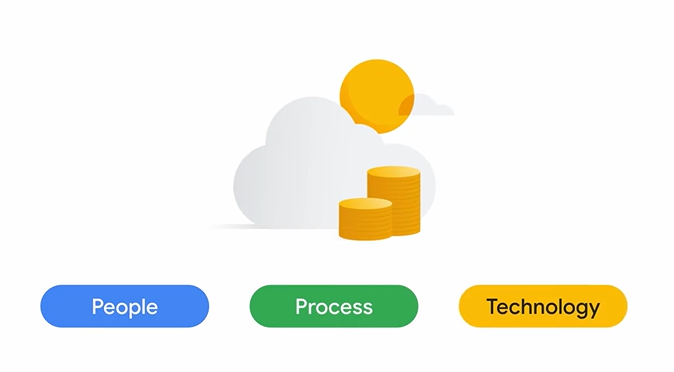
1. クラウドの財務ガバナンスの基本
効果的な費用管理は、「人材」「プロセス」「テクノロジー」の3つの要素で成り立ちます。
- 人材: 財務、テクノロジー、ビジネスチームが連携し、データに基づいた意思決定を行う必要があります。**Cloud Center of Excellence (CCoE)**のような専門チームを設置することが有効です。
- プロセス: 日次・週次で費用を監視・分析し、チーム間に説明責任(アカウンタビリティ)の文化を醸成することで、無駄を迅速に排除します。
- テクノロジー: Google Cloudに組み込まれた費用管理ツールを活用し、可視化、管理、最適化を行います。
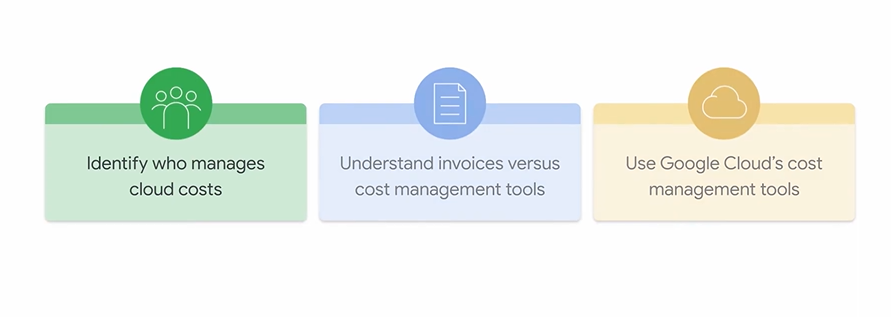
2. 財務ガバナンスのベストプラクティス
-
責任の明確化: 誰が費用を管理するのかを特定し、プロジェクトの所有者を明確にします。予算を作成し、実際の費用や予測費用に基づいたアラートを設定することが重要です。
-
請求書とコスト管理ツールの違いを理解: 請求書は「支払う金額」を示しますが、コスト管理ツールは「何に、なぜ支出しているのか」という詳細なデータや傾向を分析し、最適化のための洞察を提供します。

-
予測と管理: Google Cloudの料金計算ツールで費用の見積もりを行い、レポート機能で実際の支出を定期的に監視・報告する体制を整えます。
3. リソース階層を使用したアクセス制御
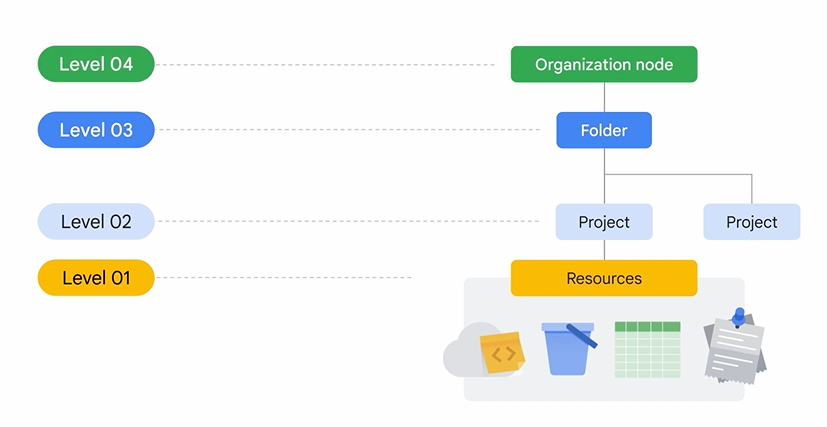
Google Cloudでは、リソースを以下の階層で管理し、効率的かつ安全にアクセスを制御します。
- 階層構造: 組織ノード > フォルダ > プロジェクト > リソース (VMなど)
- ポリシーの継承: 上位レベル(例: フォルダ)で設定されたアクセス権限ポリシーは、下位のプロジェクトやリソースに自動的に継承されます。これにより、管理が簡素化され、一貫性が保たれます。
- 利点: きめ細かいアクセス制御、最小権限の原則の適用によるセキュリティ強化、監査の容易化を実現します。
4. クラウド使用量の管理
コスト削減、可視性の向上、コンプライアンス遵守のために、以下のツールでクラウドの使用量を制御します。
- リソース割り当てのポリシー: プロジェクトやユーザーが使用できるリソースの上限を設定し、過剰な支出を防ぎます。
- 予算しきい値のルール: 設定した予算を超えそうになるとアラートを通知し、早期に対応を促します。
- Cloud Billing レポート: 請求データをBigQueryにエクスポートし、Looker Studioなどで可視化・詳細分析を行います。
-
確約利用割引 (CUD): 予測可能なワークロードに対して、一定期間のリソース利用を確約することで、大幅な割引を受けられます。

第2部:効果的な運用と信頼性の大規模な確保
クラウドの価値を最大化するには、増加するワークロードを処理しつつ、中断のないサービス提供を保証する「効果的な運用と信頼性」が不可欠です。
1. クラウドの信頼性の基本
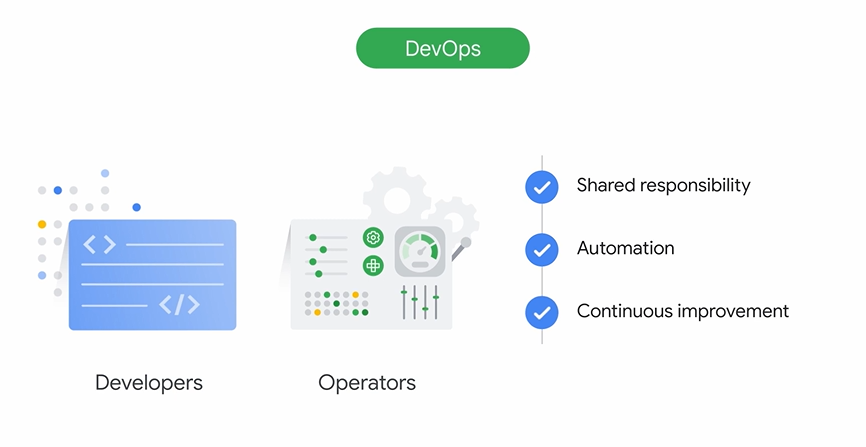
-
DevOpsとSRE: 従来、アジリティを重視する開発チームと、安定性を重視する運用チームには隔たりがありました。DevOpsはこの2チームの連携を促す文化・手法です。**サイト信頼性エンジニアリング (SRE)**は、DevOpsの具体的な実践方法であり、ソフトウェアエンジニアリングのアプローチでシステムの信頼性を保証します。
-
4つのゴールデンシグナル: システムの健全性を測るための重要な指標です。
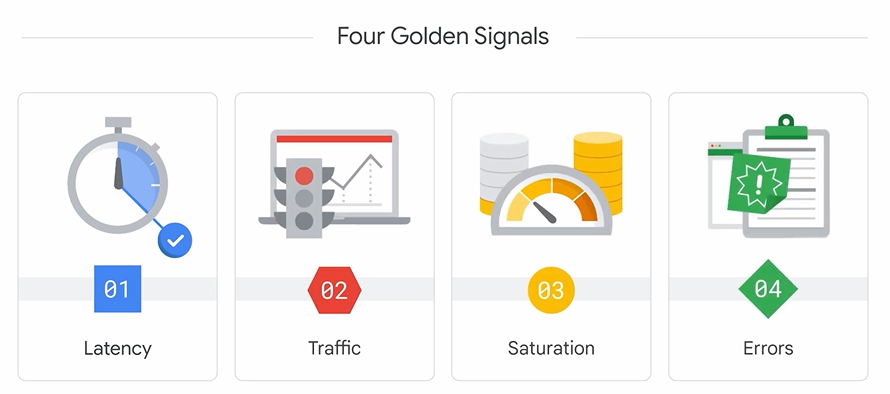
- レイテンシ: リクエストへの応答時間。
- トラフィック: システムへのリクエスト数。
- エラー: 失敗したリクエストの割合。
- 飽和度: システムがどれだけ逼迫しているか。
-
サービスレベルの定義:

- SLI (指標): 稼働率やレスポンス時間など、サービスのパフォーマンスを測る具体的な測定値。
- SLO (目標): 「可用性99.9%」など、SLIに基づいて設定する信頼性の目標値。
- SLA (契約): プロバイダと顧客間で交わされる、SLOを達成できなかった場合のペナルティなどを含む法的な契約。
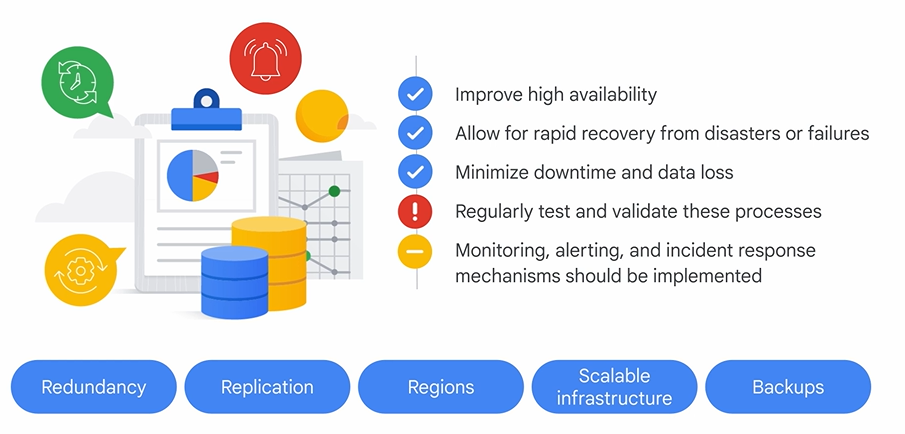
2. 復元力の高いインフラとプロセスの設計
高可用性と障害復旧を実現するための主要な設計要素です。
- 冗長性とレプリケーション: 重要なコンポーネントやデータを複数用意・複製し、単一障害点をなくします。
- 複数リージョンへの分散: 自然災害など地域規模の障害に備え、リソースを地理的に異なる複数のリージョンに分散させます。
- スケーラビリティ: 自動スケーリング機能により、需要の増減に応じてリソースを自動的に調整し、パフォーマンスを維持します。
- バックアップと復元: データを定期的にバックアップし、地理的に離れた場所に保管することで、データ損失から迅速に復旧できるようにします。
3. 事業運営のモダナイゼーション
物理的にアクセスできないクラウド環境では、システムの内部状態を把握するオブザーバビリティ (可観測性) が重要です。Google Cloudではオペレーションスイートがこの役割を担います。
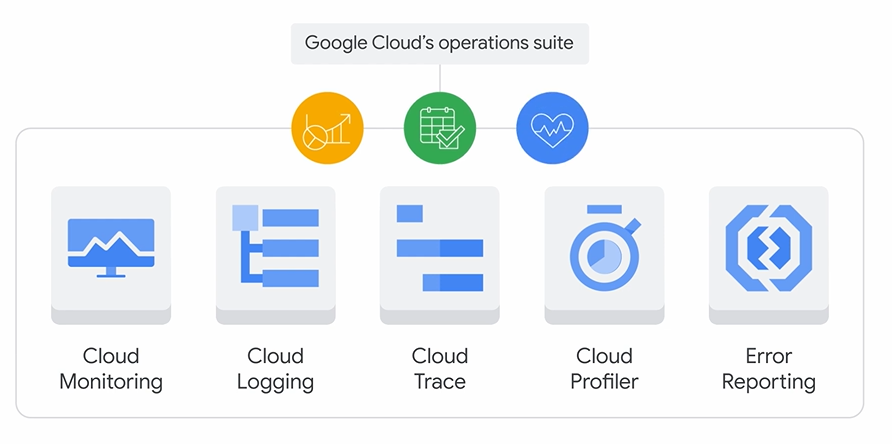
- Cloud Monitoring: 指標、ログ、トレースを収集・可視化し、システムのパフォーマンスや健全性を監視。アラートも設定可能。
- Cloud Logging: アプリやインフラのログを一元的に収集・分析。
- Cloud Trace / Profiler: アプリのパフォーマンスのボトルネックや、CPU/メモリ使用量を特定。
- Error Reporting: アプリケーションで発生したクラッシュをリアルタイムで収集・分析。
4. Google Cloud カスタマーケア
ビジネスニーズに応じて選択できる4つのサポートプランを提供しています。

- ベーシック (無料), スタンダード (開発向け), エンハンスト (本番向け), プレミアム (ビジネスクリティカル向け) の順でサポートレベルが向上します。
- サポートケースのライフサイクル: ケースは、作成 → 優先順位付け → 調査 → 解決策の提示・検証 → 終了という流れで処理されます。エスカレーションはケースが行き詰まった際に有効ですが、影響の大きい問題では逆に遅延を招く可能性があるため、慎重に利用すべきです。
第3部:Google Cloudによるサステナビリティの実現
Googleはテクノロジーを通じて、より持続可能な世界の実現を目指しています。

-
Googleの取り組み:
- 高効率なデータセンター: ISO 14001認証を取得し、フィンランドのデータセンターでは海水を利用した冷却システムを導入するなど、エネルギー効率を追求しています。
- カーボンフリーへの道: 2007年にカーボンニュートラルを、その後再生可能エネルギー100%利用を達成。2030年までに全事業でカーボンフリーエネルギーによる運営を目指しています。
-
顧客のサステナビリティ目標達成を支援:
- 事例 (Kaluza社): Google Cloud (BigQuery, GKE) を活用し、電気自動車 (EV) のスマート充電プラットフォームを構築。電力需要が低く、CO2排出量が少ない安価な時間帯に自動で充電することで、ユーザーのコスト削減と電力網の負荷軽減、環境負荷の低減を同時に実現しています。
まとめ
このコースでは、クラウド費用を管理する財務ガバナンス、システムの安定稼働を支える効果的な運用と信頼性、そして環境への貢献を可能にするサステナビリティについて学びました。これらの知識は、Cloud Digital Leader認定資格の取得にも繋がります。