はじめに
本記事ではBizCodeXというスクールでの課題として作成した「請求書PDFの自動集計&Slack通知アプリ」のプログラム内容について解説します。
【本プログラムで使用した主な技術・ライブラリ】
-
Tkinter: GUIアプリの作成 -
pdfplumber: PDFからのテキスト抽出 -
pandas: データの集計・Excel出力 -
PyInstaller: Pythonファイルのexe化
動作デモ
まずはプログラムの実際の動作デモをご紹介します。
プログラムは非技術者でも使用可能なように.exeファイルに変換しています(請求書自動集計.exe)。
デモ用に作成した「請求書_202602」フォルダの中には請求書PDFファイルが3つ保存されています。
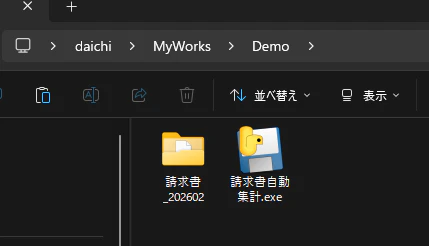
exeファイルを実行すると、以下の様なGUIが表示されます。

「フォルダを選択」をクリックし、集計対象のPDFファイルが保存されているフォルダを選択します(今回は上記の請求書_202602フォルダを選択する)
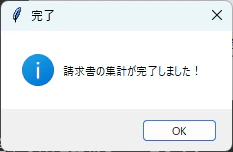
問題なく集計が完了した場合、GUI上で以下のメッセージが表示されます。
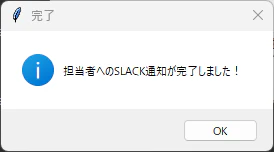
集計が成功したらSlackへの通知も行うため、これも成功すればメッセージが表示されます。
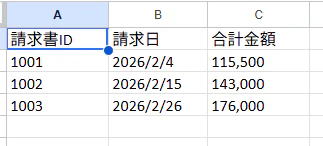
請求書_202602フォルダの中を確認してみると、報告書.xlsxというExcelファイルが出力されています。

内容は以下のように、請求書PDFファイルから集計したデータがまとめられています。
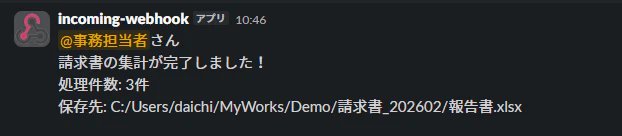
Slackでは連絡が必要な担当者にメンションし、処理件数やExcelファイルのパスを共有しています。
ユーザービリティ向上のため、エラー発生時にGUIで内容を確認出来るようにしました。
例えば以下のようなケースです。
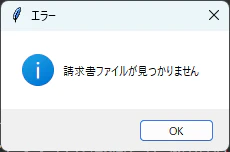
- 選択されたフォルダーに
請求書_*.pdfという名前の請求書ファイルが無い場合
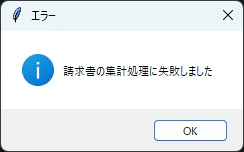
- 集計処理中にエラーが発生した場合
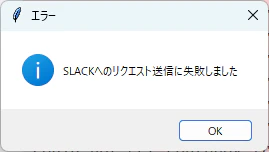
- Slackへのリクエスト送信時にエラーになった場合
以上がプログラムの動作デモになります。
Pythonプログラムの解説
ここでは今回作成したPythonプログラムの具体的な内容や手順を記載していきます。
1. 事前準備
事前準備として、以下項目の実施が必要です。
- pipパッケージのインストール
$ pip install pdfplumber pandas openpyxl pyinstaller
- Slackの設定
-
Incoming Webhookの追加・リクエスト用URLの取得 - 連絡(メンション)するユーザーのユーザーIDの取得
-
2. Tkinterでユーザー用のGUIを作成する
まずはTkinterでGUIアプリの外枠を作成し、請求書ファイルパスの取得まで行います。
# Tkinter, globのインポート
import tkinter as tk
from tkinter import filedialog
from glob import glob
def execute():
# フォルダ選択ダイアログを表示してパスを取得
folder_path = filedialog.askdirectory()
# 選択フォルダ内のPDFファイル一覧を取得
pdf_files = glob(folder_path + "/請求書_*.pdf")
if __name__ == '__main__':
# メインウィンドウの作成と設定
root = tk.Tk()
root.title("請求書自動集計アプリ") # タイトルを指定
root.geometry("400x200+300+300") # ウィンドウサイズ(幅x高さ)と表示位置(x+y)を指定
# 案内テキストのラベルを配置
label=tk.Label(root, text="こんにちは!\n\n\n集計対象の請求書PDFファイルが保存されているフォルダを選択してください:")
label.pack(pady=30)
# フォルダ選択ボタンを配置(クリックでexecute関数を呼び出す)
button = tk.Button(root, text="フォルダを選択", command=execute)
button.pack(pady=5)
# イベントループを開始してウィンドウを表示・待機
root.mainloop()
「フォルダを選択」から集計対象のフォルダを選択すると、フォルダ内の請求書_*.pdfという名前のファイルパスのリストを取得します。
実行したところ以下の通りファイルパスのリストを取得できました。
['C:/Users/daichi/MyWorks/アウトプット2/請求書_202602\\請求書_1001.pdf', 'C:/Users/daichi/MyWorks/アウトプット2/請求書_202602\\請求書_1002.pdf', 'C:/Users/daichi/MyWorks/アウトプット2/請求書_202602\\請求書_1003.pdf']
3. pdfplumberでPDFファイルからテキストを抽出する
次にpdfplumberを使って取得したファイルパスからPDFファイルを読み込み、テキストデータを抽出します。
invoice_dataには、後でExcelファイルに出力するための整形した辞書データを格納していきます。
...
# pdfplumberのインポート
import pdfplumber
def execute():
...
# 各PDFから抽出したデータを格納するリスト
invoice_data = []
# PDFファイルを1件ずつ処理
for file in pdf_files:
with pdfplumber.open(file) as pdf:
# 1ページ目のテキストを取得
text = pdf.pages[0].extract_text()
if __name__ == '__main__':
...
抽出したテキストデータは以下になります。
請 求 書
株式会社 御中
ABC No 1001
請求⽇ 2026/2/4
下記のとおり、御請求申し上げます。 サンプル株式会社
件名 サンプルプロジェクト 〒100-0001
⽀払期限 2022/5/31 東京都千代⽥区千代⽥1-1-1
振込先 サンプル銀⾏ 本店 普通 1111111 サンプルビル3階
サンプル(カ TEL:03-0000-0000
担当:サンプル太郎
円 税込
合計 115,500 ( )
摘要 数量 単位 単価 ⾦額
サンプル1 3 式 (10,000) (30,000)
サンプル2 2 式 (15,000) (30,000)
サンプル3 1 式 (20,000) (20,000)
サンプル4 1 式 (25,000) (25,000)
⼩計 (105,000)
消費税 (10,500)
合計 (115,500)
備考
4. 抽出したテキストから必要な辞書データを構築する
抽出テキストデータから必要な情報を抽出し、辞書データを作成していきます。
forループを1行ずつ回す方法もあるのですが、今回はループを使わずに済むようにreで正規表現を使って以下の項目を抜き出します。
- 請求書ID
- 請求日
- 合計金額
...
# pdfplumberのインポート
import pdfplumber
# reのインポート
import re
def execute():
...
# PDFファイルを1件ずつ処理
for file in pdf_files:
with pdfplumber.open(file) as pdf:
# 1ページ目のテキストを取得
text = pdf.pages[0].extract_text()
### 以下を追加 ###
# テキストから抽出したデータを格納する辞書を初期化
data = {}
# 正規表現で請求書ID・請求日・合計金額を抽出
invoice_id = re.search(r"No\s*\(?([0-9]+)\)?", text).group(1)
date = re.search(r"請求⽇\s*\(?([0-9/]+)\)?", text).group(1)
amount = re.search(r"合計\s*\(?([0-9,]+)\)?", text).group(1)
# 抽出結果を辞書に格納
data['請求書ID'] = invoice_id
data['請求⽇'] = date
data['合計金額'] = amount
# 辞書をinvoice_dataに追加
invoice_data.append(data)
if __name__ == '__main__':
...
invoice_dataに請求書ファイルごとの辞書データが格納されました。
[{'請求書ID': '1001', '請求⽇': '2026/2/4', '合計金額': '115,500'}, {'請求書ID': '1002', '請求⽇': '2026/2/15', '合計金額': '143,000'}, {'請求書ID': '1003', '請求⽇': '2026/2/26', '合計金額': '176,000'}]
5. pandasでDataFrameを作成しExcelファイルへ出力する
invoice_dataをpandasでDataFrame化し、GUI上で選択したフォルダ内にExcelファイルに出力します。
...
# pandasのインポート
import pandas as pd
#
def execute():
...
# リストをDataFrameに変換してExcelファイルとして出力
df = pd.DataFrame(invoice_data)
df.to_excel(f"{folder_path}/報告書.xlsx", index=False)
messagebox.showinfo("完了", "請求書の集計が完了しました!")
if __name__ == '__main__':
...
6. Slack上で担当者へ通知出来るようにする
事前準備で用意したSlackのWebhook URLとユーザーIDを使用して、集計完了を担当者へ通知します。
...
# requestsのインポート
import requests
# Slack Incoming Webhook URL(通知の送信先)
WEBHOOK_URL = 'WEBHOOKのURL'
# 通知先のSlackユーザーID
SLACK_ID = 'SlackのユーザーID'
def execute():
...
# Slackへ送信するメッセージを作成
message = f"<@{SLACK_ID}>さん\n請求書の集計が完了しました!\n処理件数: {len(df)}件\n保存先: {folder_path}/報告書.xlsx"
payload = {"text": message}
# Webhook URLへPOSTリクエストを送信
response = requests.post(WEBHOOK_URL, json=payload)
if __name__ == '__main__':
...
担当者がSlackからすぐファイルを確認出来るよう、Excelファイルのパスも記載するようにしています。
7. エラーハンドリング、自動終了を追加する
ここまでで主要な機能は実装できましたが、実運用に耐えうるようエラーハンドリングとGUIの自動終了処理を追加します。
エラーハンドリングにはtry-except構文を使用し、処理を中断させたい箇所で root.destroy() を呼んでプログラムを終了させます。
また、tkinterのmessageboxを使って、何のエラーが起きたかを使用者に通知するようにしました。
...
def execute():
"""
「フォルダを選択」ボタン押下時に実行されるメイン処理。
フォルダ内のPDFを読み込み、請求書データを集計してExcel出力・Slack通知を行う。
"""
# フォルダ選択ダイアログを表示してパスを取得
folder_path = filedialog.askdirectory()
# 選択フォルダ内のPDFファイル一覧を取得
pdf_files = glob(folder_path + "/*.pdf")
# PDFファイルが1件も見つからない場合はエラーを表示して終了
if len(pdf_files) == 0:
messagebox.showinfo("エラー", "請求書ファイルが見つかりません")
root.destroy()
return
# 各PDFから抽出したデータを格納するリスト
invoice_data = []
try:
# PDFファイルを1件ずつ処理
for file in pdf_files:
with pdfplumber.open(file) as pdf:
# 1ページ目のテキストを取得
text = pdf.pages[0].extract_text()
# テキストから抽出したデータを格納する辞書を初期化
data = {}
# 正規表現で請求書ID・請求日・合計金額を抽出
invoice_id = re.search(r"No\s*\(?([0-9]+)\)?", text).group(1)
date = re.search(r"請求⽇\s*\(?([0-9/]+)\)?", text).group(1)
amount = re.search(r"合計\s*\(?([0-9,]+)\)?", text).group(1)
# 抽出結果を辞書に格納
data['請求書ID'] = invoice_id
data['請求⽇'] = date
data['合計金額'] = amount
invoice_data.append(data)
except:
messagebox.showinfo("エラー", "請求書の集計処理に失敗しました")
root.destroy()
return
try:
# リストをDataFrameに変換してExcelファイルとして出力
df = pd.DataFrame(invoice_data)
df.to_excel(f"{folder_path}/報告書.xlsx", index=False)
messagebox.showinfo("完了", "請求書の集計が完了しました!")
except:
messagebox.showinfo("エラー", "報告書ファイルの出力に失敗しました")
root.destroy()
return
try:
# Slackへ送信するメッセージを作成
message = f"<@{SLACK_ID}>さん\n請求書の集計が完了しました!\n処理件数: {len(df)}件\n保存先: {folder_path}/報告書.xlsx"
payload = {"text": message}
# Webhook URLへPOSTリクエストを送信
response = requests.post(WEBHOOK_URL, json=payload)
if response.ok:
messagebox.showinfo("完了", "担当者へのSlack通知が完了しました!")
else:
# ステータスコードが200番台以外の場合はエラーを表示
messagebox.showinfo("エラー", f"Slack通知のステータスコードが異常値({response.status_code})でした")
except:
messagebox.showinfo("エラー", "Slackへのリクエスト送信に失敗しました")
# 処理完了後にウィンドウを閉じる
root.destroy()
return
if __name__ == '__main__':
...
8. .pyファイルを.exeファイルに変換する
最後に作成した.pyファイルを.exeファイルに変換します。
$ pyinstaller invoice_app.py --onefile --noconsole --name "請求書自動集計"
プログラム全体
これまでの内容をまとめた、最終的なプログラム全体は以下の通りです。
# 必要なモジュールのインポート
import tkinter as tk
from tkinter import filedialog, messagebox
import pdfplumber, re, requests
from glob import glob
import pandas as pd
# Slack Incoming Webhook URL(通知の送信先)
WEBHOOK_URL = 'WEBHOOKのURL'
# 通知先のSlackユーザーID
SLACK_ID = 'SLACKのユーザーID'
def execute():
"""「フォルダを選択」ボタン押下時に実行されるメイン処理。
フォルダ内のPDFを読み込み、請求書データを集計してExcel出力・Slack通知を行う。
"""
# フォルダ選択ダイアログを表示してパスを取得
folder_path = filedialog.askdirectory()
# 選択フォルダ内のPDFファイル一覧を取得
pdf_files = glob(folder_path + "/*.pdf")
# PDFファイルが1件も見つからない場合はエラーを表示して終了
if len(pdf_files) == 0:
messagebox.showinfo("エラー", "請求書ファイルが見つかりません")
root.destroy()
return
# 各PDFから抽出したデータを格納するリスト
invoice_data = []
try:
# PDFファイルを1件ずつ処理
for file in pdf_files:
with pdfplumber.open(file) as pdf:
# 1ページ目のテキストを取得
text = pdf.pages[0].extract_text()
# テキストから抽出したデータを格納する辞書を初期化
data = {}
# 正規表現で請求書ID・請求日・合計金額を抽出
invoice_id = re.search(r"No\s*\(?([0-9]+)\)?", text).group(1)
date = re.search(r"請求⽇\s*\(?([0-9/]+)\)?", text).group(1)
amount = re.search(r"合計\s*\(?([0-9,]+)\)?", text).group(1)
# 抽出結果を辞書に格納
data['請求書ID'] = invoice_id
data['請求⽇'] = date
data['合計金額'] = amount
invoice_data.append(data)
except:
messagebox.showinfo("エラー", "請求書の集計処理に失敗しました")
root.destroy()
return
try:
# リストをDataFrameに変換してExcelファイルとして出力
df = pd.DataFrame(invoice_data)
df.to_excel(f"{folder_path}/報告書.xlsx", index=False)
messagebox.showinfo("完了", "請求書の集計が完了しました!")
except:
messagebox.showinfo("エラー", "報告書ファイルの出力に失敗しました")
root.destroy()
return
try:
# Slackへ送信するメッセージを作成
message = f"<@{SLACK_ID}>さん\n請求書の集計が完了しました!\n処理件数: {len(df)}件\n保存先: {folder_path}/報告書.xlsx"
payload = {"text": message}
# Webhook URLへPOSTリクエストを送信
response = requests.post(WEBHOOK_URL, json=payload)
if response.ok:
messagebox.showinfo("完了", "担当者へのSlack通知が完了しました!")
else:
# ステータスコードが200番台以外の場合はエラーを表示
messagebox.showinfo("エラー", f"Slack通知のステータスコードが異常値({response.status_code})でした")
except:
messagebox.showinfo("エラー", "Slackへのリクエスト送信に失敗しました")
# 処理完了後にウィンドウを閉じる
root.destroy()
return
if __name__ == '__main__':
# メインウィンドウの作成と設定
root = tk.Tk()
root.title("請求書自動集計アプリ") # タイトルを指定
root.geometry("400x200+300+300") # ウィンドウサイズ(幅x高さ)と表示位置(x+y)を指定
# 案内テキストのラベルを配置
label=tk.Label(root, text="こんにちは!\n\n\n集計対象の請求書PDFファイルが保存されているフォルダを選択してください:")
label.pack(pady=30)
# フォルダ選択ボタンを配置(クリックでexecute関数を呼び出す)
button = tk.Button(root, text="フォルダを選択", command=execute)
button.pack(pady=5)
# イベントループを開始してウィンドウを表示・待機
root.mainloop()
まとめ
いかがでしたでしょうか。
今回は「請求書のようなPDFファイルから情報を抜き出して集計し、成功したら担当者に通知する」という実務でよくある作業を想定して、それをPythonで自動化・GUI化してみました。
今回は想定をシンプルにするために請求書のフォーマットを統一しましたが、実際の現場では多様なフォーマットの請求書が存在する可能性があります。
その場合はテキストデータを抽出する際にもっと複雑な正規表現や条件分岐など、考慮すべきことが出てくるかもしれません。
ともかく想定ではありますが、非エンジニアでも使える形で「1つの業務効率化ツール」を完成させられたことは大きな経験になりました。
今後も学習を続けて、より実務に直結する大きな貢献ができるように頑張っていきたいです。
最後までお読みいただきありがとうございました!