reInvent 2024 で発表された S3 の拡張機能 S3 Tables。
ざっくりいうと、Managed Apache Iceberg on S3。
S3上で、オープンソースのテーブルフォーマットIcebergの形式で、データをテーブルとして格納でき、Athena/EMR/Redshiftや、AWS以外のIceberg対応サービス含めて、いろいろな分析サービスで統合的にACIDなデータアクセスができるLakehouse環境を作れる。
AWS re:Invent 2024 - Announcing S3 Tables
https://www.youtube.com/watch?v=eztA5VYH2nM
1. 軽く試す
ここではとりあえずコンソールベースで。
ざっくり主要サービス要素は↓の通り。Lake Formation や Athena は、後述のAWS Analutics Service との統合を有効化することでよしなにセットアップしてくれる。
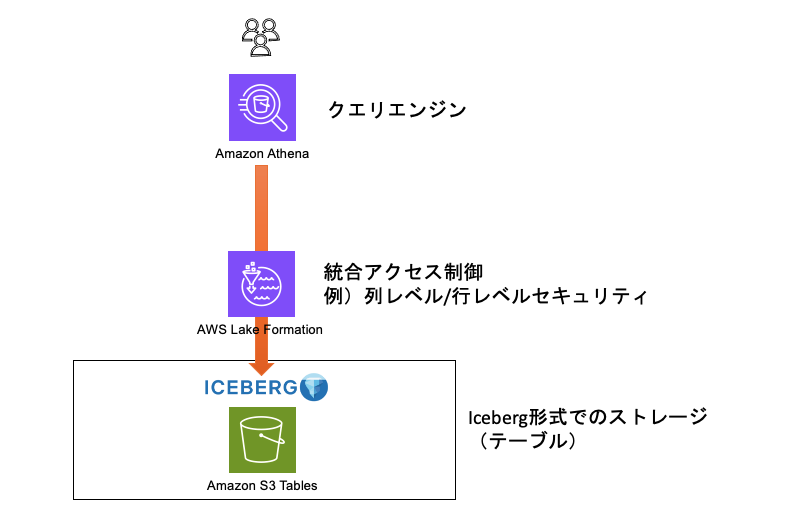
1.1) S3 で Table buckets を作る
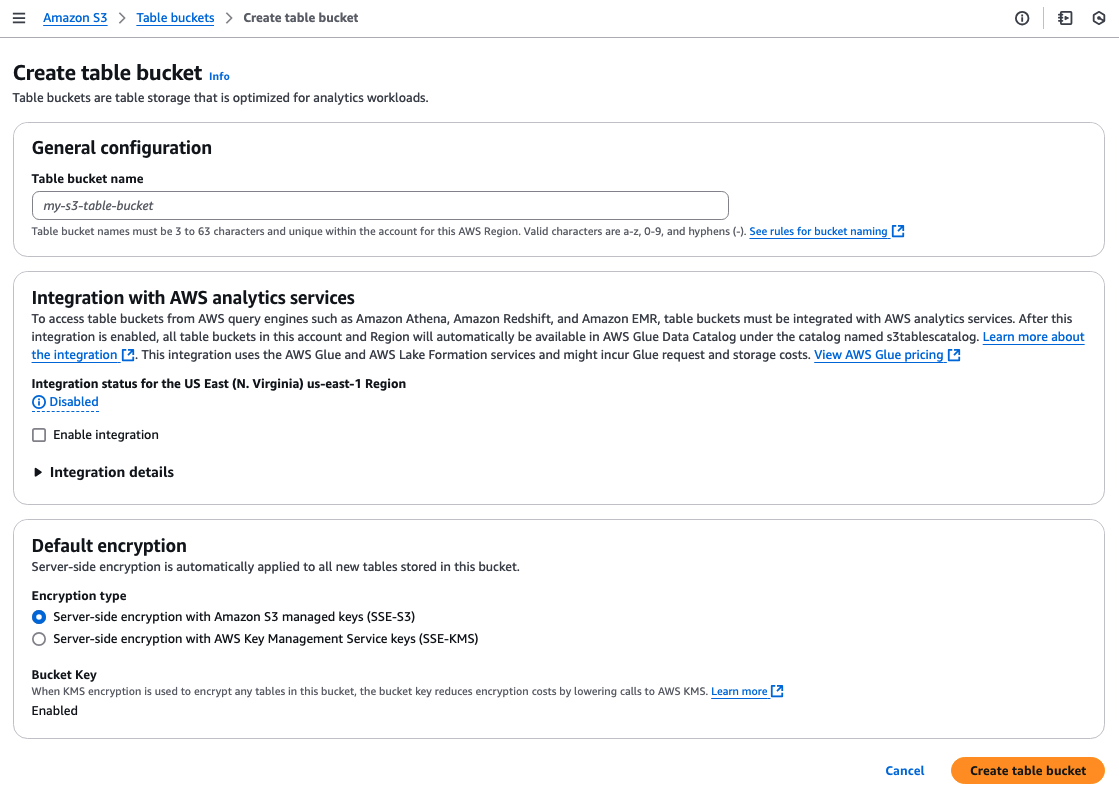
AWS マネコンで S3 に「Table buckets」があるので、そこから作成できる。ポイントとして、S3 Tablesは、従来の汎用オブジェクトを格納するバケットとは別物として定義されている。
AWSの分析サービスでつつく場合は、Integration with AWS Analytics Servicesの「Enable Integration」を有効化しておく。この統合オプションは、リージョン単位で一律適応される模様。
暗号化は、SSE-S3かSSE-KMSが選べる。
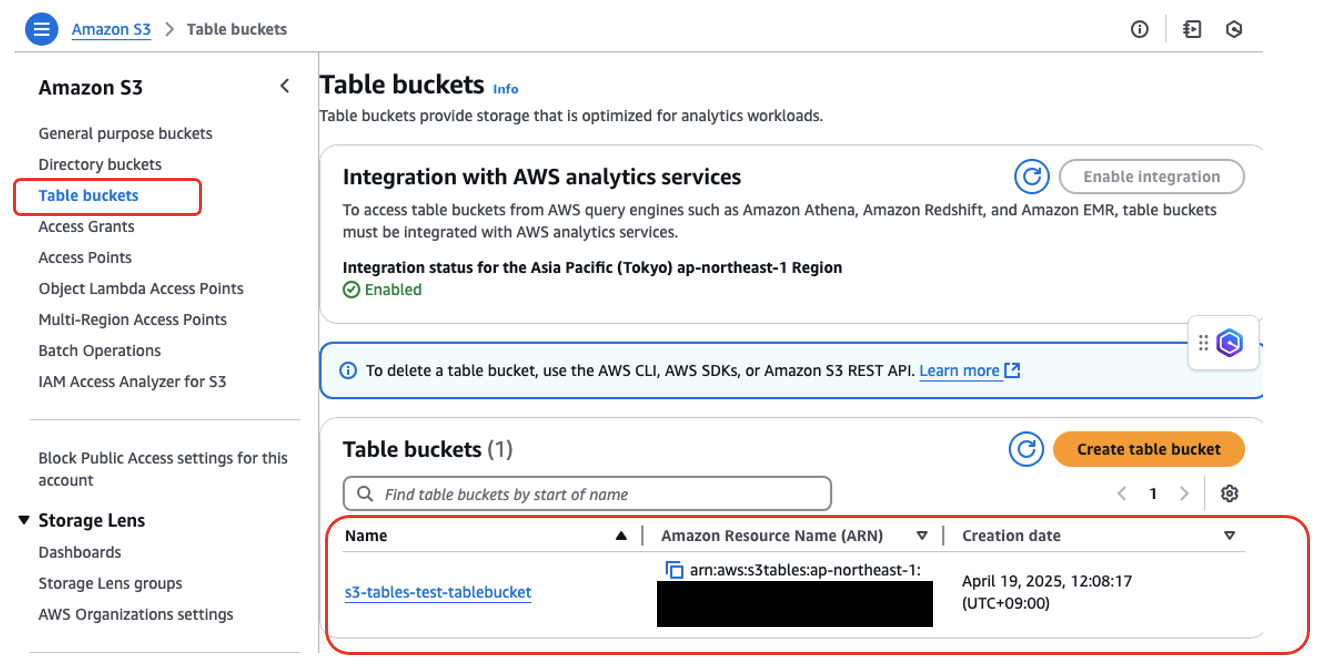
作成すると、以下のようにテーブルバケットがリストで追加される
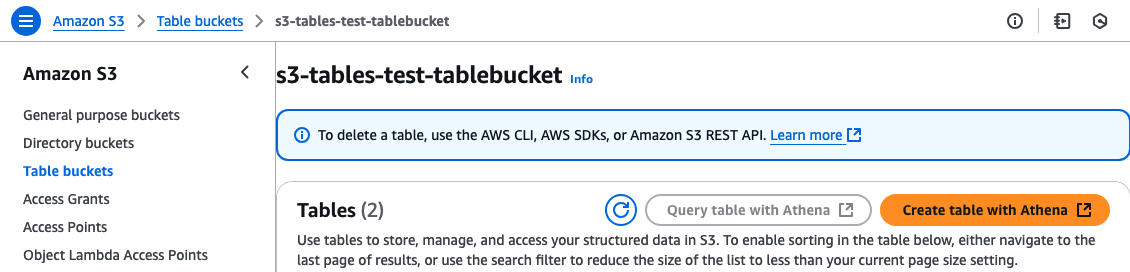
まだ枠(テーブルバケット)ができただけなので、「Create table with Athena」というボタンからAthenaで実際のテーブルデータを登録できる
ここで、Namespace(名前空間)という概念が出てくる。テーブルバケット、名前空間、テーブルの関係はざっくりこんな感じ↓。テーブルバケット内に複数のテーブルを含むことができ、テーブルを用途ごとにグループ化するのが名前空間。なお、AWS分析サービスとの統合を有効化した場合のLake Formation Data Catalogとのマッピングも示す。
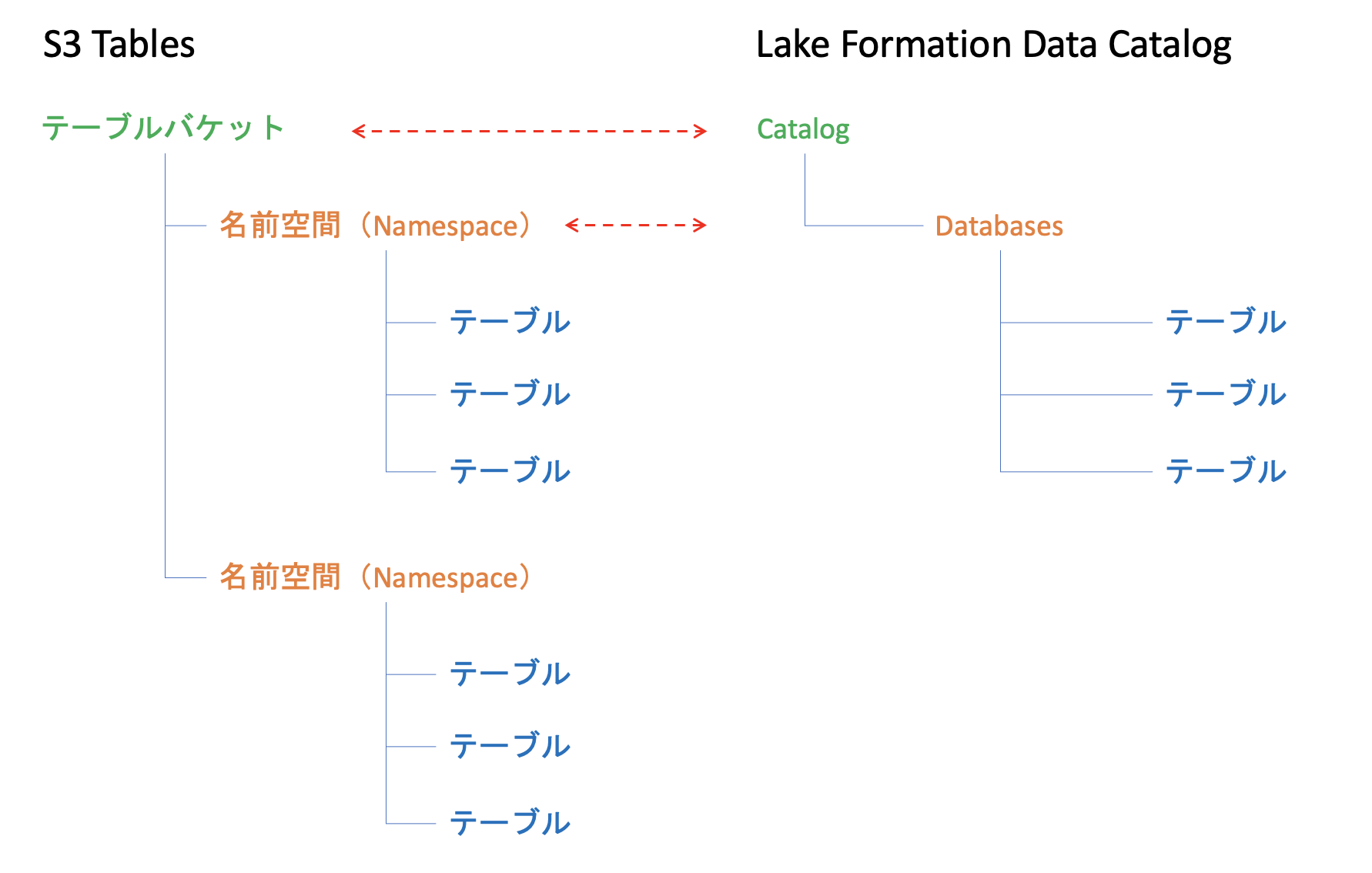
S3 TablesのTable BucketはAthena上ではCatalogとして、名前空間(Namespace)は、Athena上ではDatabasesとしてそれぞれマッピングされる。
※ 参考1)このAthenaが利用するメタデータカタログは、Lake Formation(内部的にGlue)のData Catalogが統合されて利用されている。
※ 参考2)テーブルバケットは 最大10件/Account、名前空間は最大10,000件/TableBuckets、Tableは10,000/TableBuckets まで作成できる(2025年4月時点)
Athenaが立ち上がり、CREATE TABLEや、INSERTで先ほどのテーブルバケット内の指定した名前空間内にテーブルを作成・利用できる。
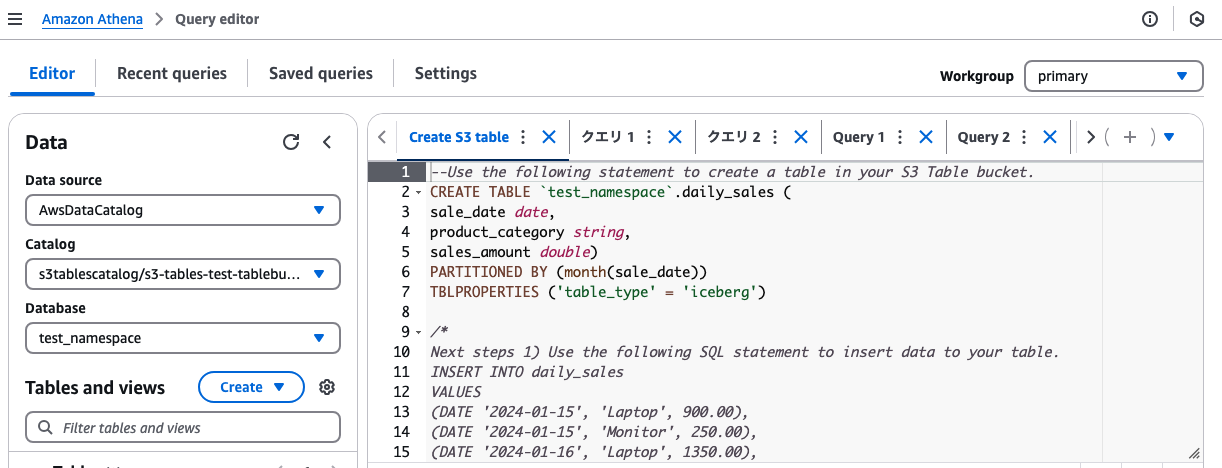
1.2) Athena でデータ登録と分析
Catalog(テーブルバケット)とDatabase(名前空間)をS3 Tablesのものを指定した状態で、例えば以下のサンプルクエリを実行すると、Iceberg形式でS3 Tablesにテーブルを作成し、分析できる。
--Use the following statement to create a table in your S3 Table bucket.
CREATE TABLE daily_sales (
sale_date date,
product_category string,
sales_amount double)
PARTITIONED BY (month(sale_date))
TBLPROPERTIES ('table_type' = 'iceberg')
-- Next steps
-- 1) Use the following SQL statement to insert data to your table.
INSERT INTO daily_sales
VALUES
(DATE '2024-01-15', 'Laptop', 900.00),
(DATE '2024-01-15', 'Monitor', 250.00),
(DATE '2024-01-16', 'Laptop', 1350.00),
(DATE '2024-02-01', 'Monitor', 300.00),
(DATE '2024-02-01', 'Keyboard', 60.00),
(DATE '2024-02-02', 'Mouse', 25.00),
(DATE '2024-02-02', 'Laptop', 1050.00),
(DATE '2024-02-03', 'Laptop', 1200.00),
(DATE '2024-02-03', 'Monitor', 375.00);
-- 2) Use the following SQL statement to run a sample analytics query.
SELECT
product_category,
COUNT(*) as units_sold,
SUM(sales_amount) as total_revenue,
AVG(sales_amount) as average_price
FROM daily_sales
WHERE sale_date BETWEEN DATE '2024-02-01' and DATE '2024-02-29'
GROUP BY product_category
ORDER BY total_revenue DESC;
2. Icebergのタイムトラベル機能を試す
通常のオブジェクトストレージとしてS3にファイルを格納してAthenaで分析する方法と、Icebergを利用する方法の違いとして、Iceberg特有の機能の利用ができる点がある。例えば、ACIDトランザクションのサポートやタイムトラベル機能など。
以下のようなサンプルテーブルを用意して、代表的なタイムトラベル機能を試す。

まず、name=Aliceのpriceを更新し、さらにname=Bobの行を削除
UPDATE sample_table SET price = 1200 WHERE name = 'Alice';
DELETE FROM sample_table WHERE name = 'Bob';
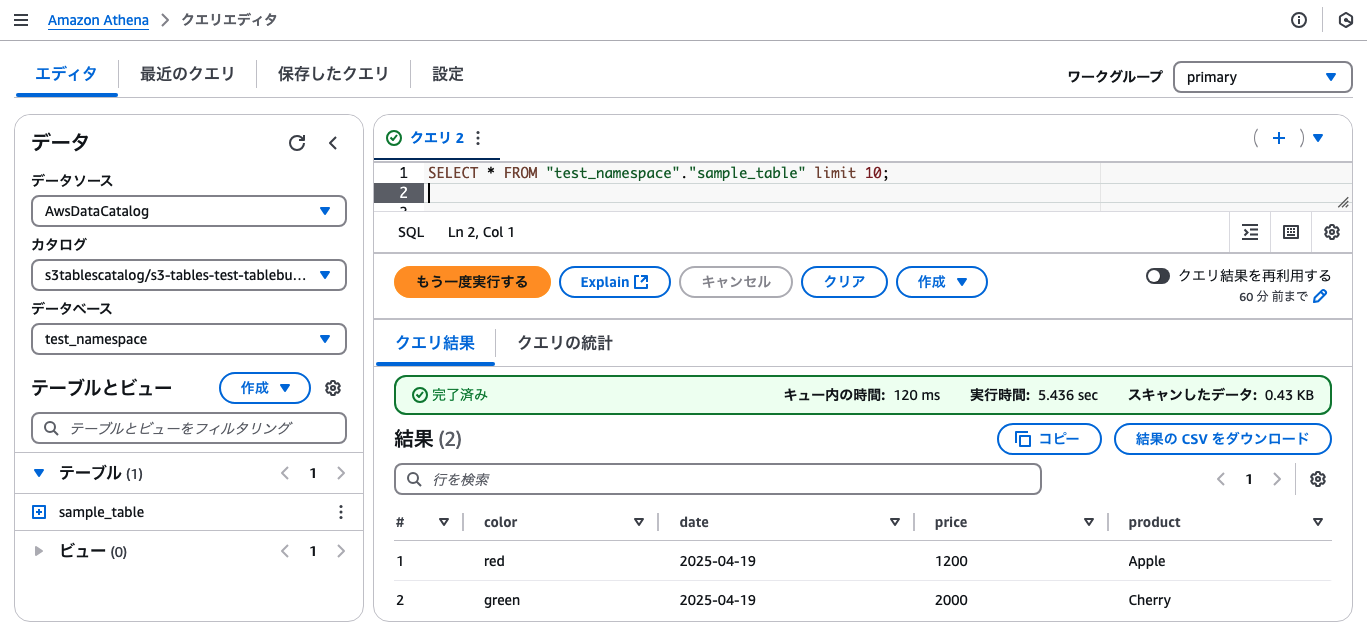
するとSELECT * FROM sample_tableの結果は当然こうなる↓

そこで、過去のsnapshotを確認($snapshotsはIcebergのパラメータ)
SELECT * FROM "sample_table$snapshots"

このように、クエリを実行履歴(最初の状態から、更新と削除をしたので3つの履歴)ごとにsnapshotが生成され、IDが振られている。
そこで、各Snapshot IDを指定して、その時の結果を表示することができちゃう。↓は最初の状態のIDを指定して実行することで、更新や削除前の状態を出力できる。
SELECT * FROM sample_table FOR VERSION AS OF 2350673130279457900

このように、誤ってデータを削除更新してしまった場合や、監査、特定時点のデータの利用など、データを遡ってチェックできる便利な機能。
参考)
Icebergテーブルのクエリ
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/querying-iceberg-table-data.html
3. その他 S3 Tables の便利機能
素のIcebergをS3にセルフマネージドでセットアップすることも可能だが、S3 Tablesを利用するメリットは以下がある
自動メンテナンス
Iceberg形式で扱う場合、一般的にパフォーマンス担保のためのメンテナンスが必要になる。例えばファイル圧縮/コンパクションや、スナップショット管理、参照されないファイルの削除など。S3 Tablesではこららを自動的に対応してくれる。なお、自動メンテナンスは無効化もできる。
AWS サービスとのネイティブ統合
SageMaker LakehouseやGlue、Athena、Redshift、EMRなど、AWSの各種サービスとの統合ができる。ガバナンス面はLakeFormationが利用される。
テーブル用に最適化された専用ストレージ
"汎用バケットのセルフマネージドテーブルと比較して、1 秒あたりのトランザクション (TPS) が高く、クエリスループットが向上" するというのが公式メッセージ
などなど
4. AWS 分析サービスとの統合について ( Lake Formation )
S3 Tablesでテーブルバケットを作成する際のオプション「Integration with AWS analytics services」について補足。
これは有効化するとリージョン単位で一律適応され、自動的にLake FormationのData Catalogと統合され、Lake Formation側で統合的なアクセス管理が可能になる。
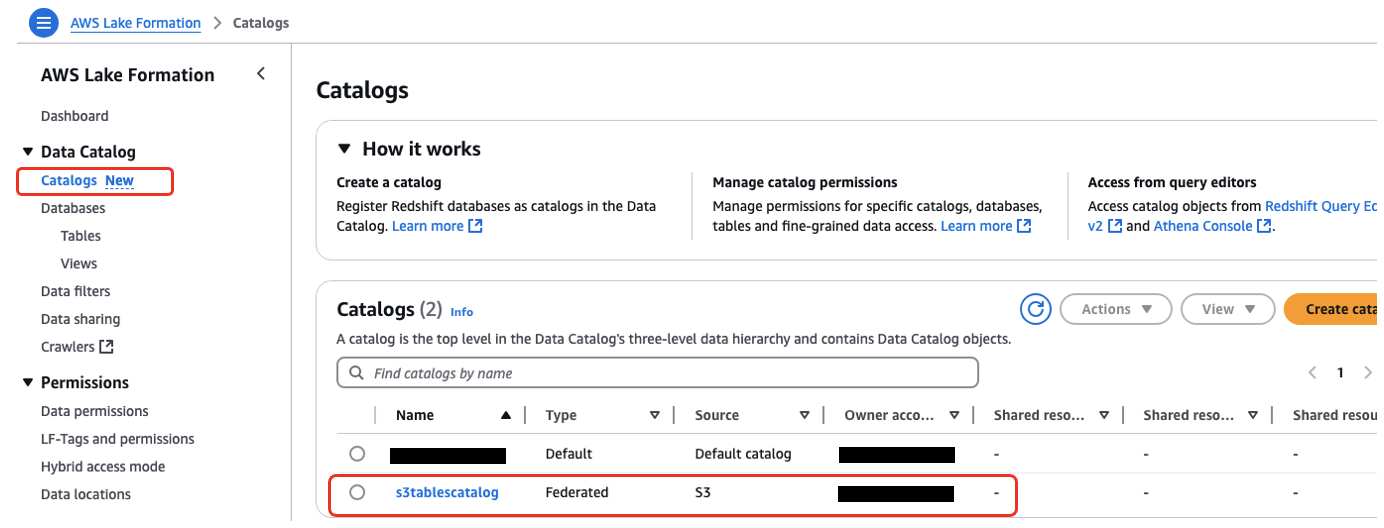
自動的に統合されるので、Lake FormationのData Catalogから↓のようにスキーマ情報を確認もできる
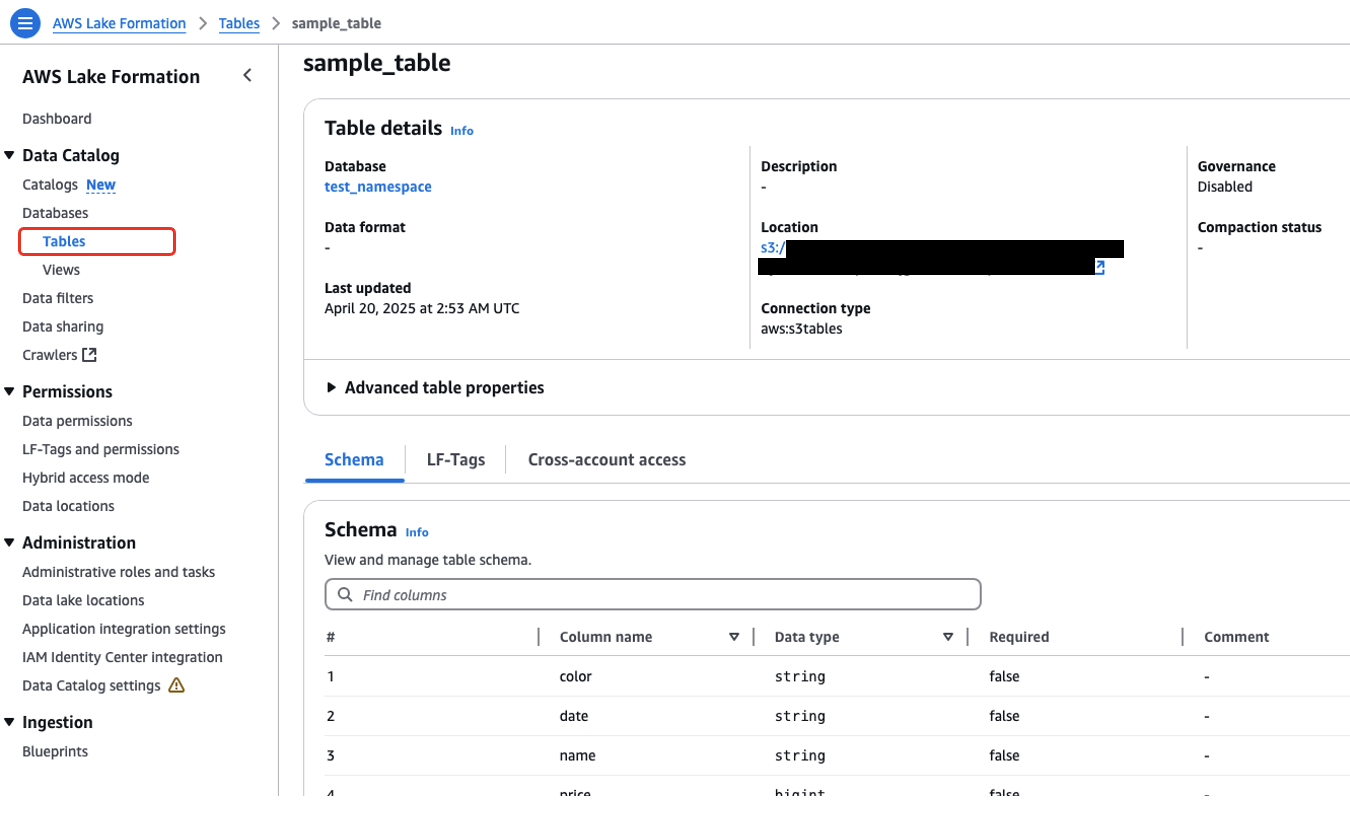
4.1)Lake Formation を利用したきめ細かいアクセス制御を試す
Lake Formation ではTable、View単位で、行レベル列レベルのアクセス制御の設定ができる。S3 Tablesで登録したテーブルに対しても以下のようにテーブル単位で、ユーザやグループ毎に権限付与ができる。
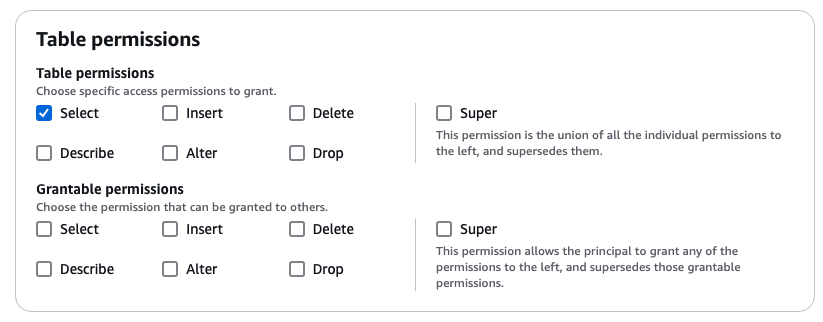
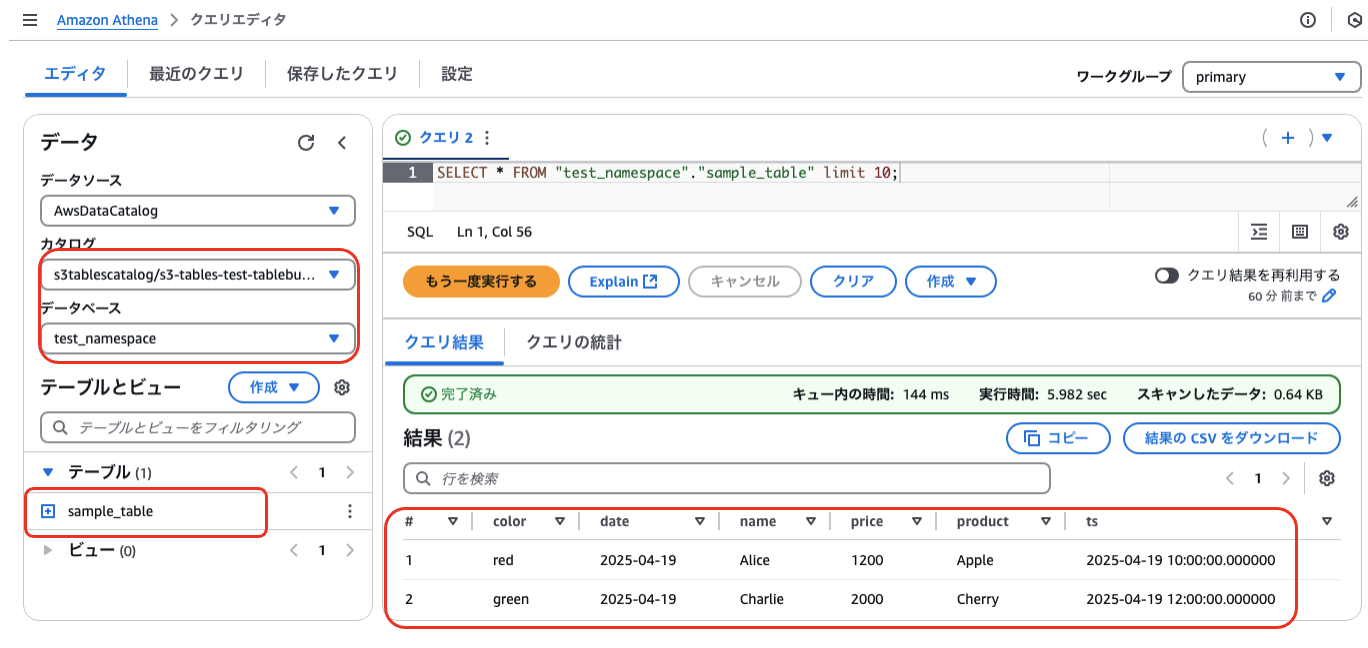
S3 Tables で複数のテーブルを作成した状態で、特定のテーブル「sample_table」に上記の通りSelect権限のみ付与すると、Athena上からは以下の通り該当テーブルのみリストに表示され、Selectが実行できるようになる。
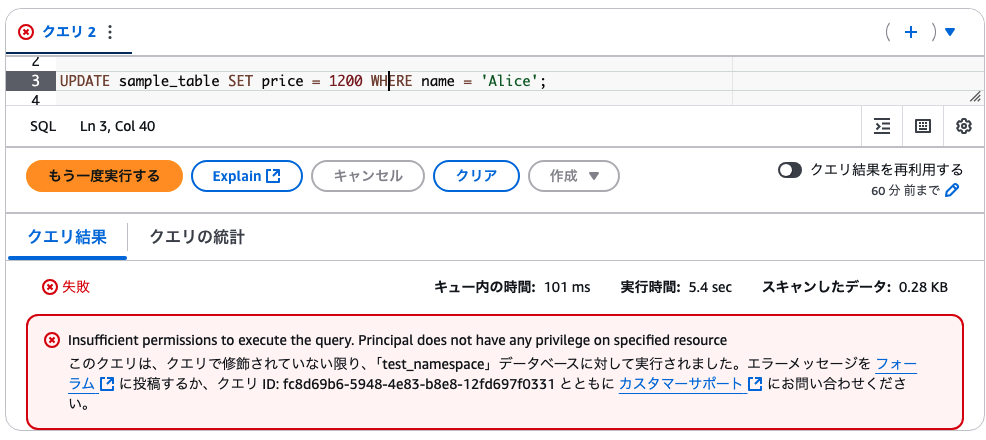
試しに権限付与していない更新作業を実行すると、以下の通りちゃんと権限不足エラーになる
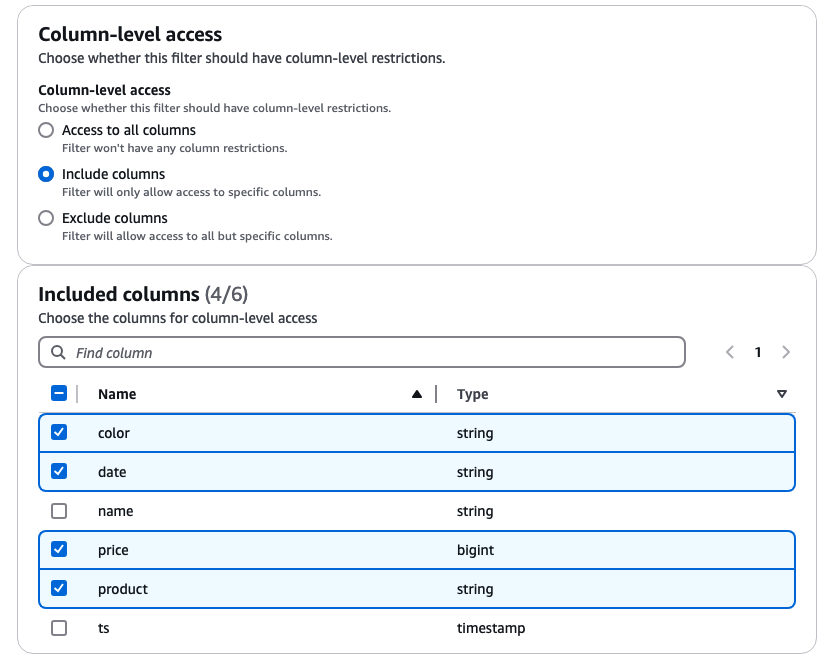
さらに列レベルのアクセス制御を追加したい場合は、例えばData Filtersで以下の通りカラム指定が可能。例えば名前を出力させたくないといったユースケースで使える。
この出力列を制限するフィルタを適応すると、Select * を実行しても↓の通りNameカラムは出力されない
Lake Formationは、Athena以外のEMRやRedshiftなどさまざまな分析サービスからアクセスされるS3のデータに対して、このようなきめ細かいアクセス制御を統合的に適応するためのサービス。
5. 既存のS3ファイルをS3 Tablesへ登録
前述の手順は INSERT でデータ登録をしているが、通常はS3上のファイルからロードなどが想定される。
そこで、Athenaでロードできるか試した↓
試行1)
CREATE TABLE でLOCATIONプロパティで汎用S3上のパス指定でできるかな?と思ったら、Table location can not be specified for tables hosted in S3 table buckets エラーに。
試行2)
CTAS を試したらQueries of this type: CREATE_TABLE_AS_SELECT, are not supported for this catalogエラーに。
5.1 EMR (Spark) で、汎用S3上のParquetをS3 Tablesにロード
データロードはいくつか方法あるが、インタラクティブクエリでロードするのにまだAthenaで↑の方法はできなかった(2025年4月時点)ため、EMR Sparkで試す。
基本は↓の手順の通り
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/s3-tables-integrating-emr.html
1)EMRクラスタの作成
Cloud Shellで一通りできる。
まずは以下内容でconfigurations.jsonを作成
[{
"Classification":"iceberg-defaults",
"Properties":{"iceberg.enabled":"true"}
}]
EMRクラスタにSSH接続するならssh-keygenとかで鍵を作成しておく
クラスター作成コマンド↓
aws emr create-cluster --release-label emr-7.5.0 \
--applications Name=Spark \
--configurations file://configurations.json \
--region us-east-1 \
--name My_Spark_Iceberg_Cluster \
--log-uri s3://amzn-s3-demo-bucket/ \
--instance-type m5.xlarge \
--instance-count 2 \
--service-role EMR_DefaultRole \
--ec2-attributes \
InstanceProfile=EMR_EC2_DefaultRole,SubnetId=subnet-1234567890abcdef0,KeyName=mykey
KeyNameにはさっき作ったSSHのための鍵名をセット
ここで、↑の2つのRole EMR_DefaultRoleとEMR_EC2_DefaultRoleは、以下コマンド作成できる。ポリシーは適宜修正
aws emr create-default-roles
2) EMRにSSH接続
以下コマンドでEMRに接続
aws emr ssh --cluster-id j-2AL4XXXXXX5T9 --key-pair-file ~/mykey.pem
3) Sparkに接続
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/amzn-s3-demo-bucket1 \
--conf spark.sql.defaultCatalog=s3tablesbucket \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
4) SQL でS3上のファイルをS3 Tablesへロード
すでにs3tablesbucket.my_namespace.my_tableを作成している前提で↓でロード
val data_file_location = "Path such as S3 URI to data file"
val data_file = spark.read.parquet(data_file_location)
data_file.writeTo("s3tablesbucket.my_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
ロードしたら、Athenaでも、EMRでも参照できる
