LLMOpsにはいくつかのサービスがありますが、クラウド上で動作するものが多いです。本稿ではローカルで動かせるOSSであるMLflowのPrompt Engineering UIを構築してみます。
構築にはDockerでPython+Poetryでの開発環境が構築できていることを前提とします。詳細は下記拙稿などを参考にしてください。DockerやPoetryを使っていない場合は適宜読み替えてください。
想定環境
- Windows 11 WSL2
- Python 3.11
- MLflow 2.11.3
本稿ではDocker+Poetryを使って環境構築し、大規模言語モデルにはOpenAI APIを用います。
構築
Dockerfileは普通にPythonをPoetryで動かすだけのものです。$ poetry newでpyproject.tomlの配置などが終わっているものとします。必要に応じてpipなどに読み替えてください。
FROM python:3.11-slim
WORKDIR /app
# お好みで
RUN apt-get update && apt-get install -y \
build-essential \
git \
curl \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN git config --global --add safe.directory /app
RUN pip install poetry \
&& poetry config virtualenvs.create false
COPY ./pyproject.toml ./poetry.lock* ./
RUN poetry install
Docker Composeで、MLflow UIとDeploymentsのふたつを起動します。
UIがMLflowの本体です。Deploymentsは大規模言語モデル用のプロキシのようなものです。以前はMLflow AI Gatewayと呼ばれていたそうです。
ポイントは以下です。
-
mlruns/,mlartifacts/ディレクトリを保存先として使う- マウントしたまま
.gitignoreに含めるなど、他の方法もあると思います
- マウントしたまま
-
MLFLOW_DEPLOYMENTS_TARGETでDeploymentsのURLを指定する - Deploymentsの設定ファイル(ここでは
mlflow_deployments.yaml)を内部に含める - 起動コマンドに
--host 0.0.0.0を含める - ポートを開けるのはUIの方だけでOK
services:
app:
build: .
volumes:
- .:/app
- mlruns:/app/mlruns
- mlartifacts:/app/mlartifacts
env_file:
- .env
environment:
- MLFLOW_DEPLOYMENTS_TARGET=http://mlflow-deployments:7000
ports:
- 5000:5000
command: poetry run mlflow ui --workers 1 --host 0.0.0.0 --port 5000
mlflow-deployments:
build: .
env_file:
- .env
volumes:
- type: bind
source: ./mlflow_deployments.yaml
target: /app/mlflow_deployments.yaml
command: poetry run mlflow deployments start-server --config-path mlflow_deployments.yaml --workers 1 --port 7000 --host 0.0.0.0
volumes:
mlruns:
mlartifacts:
OPENAI_API_KEYを.envに設定しておきます。
OPENAI_API_KEY=XXXXXXXX
MLflow Deploymentsの設定ファイルを設置します。公式ドキュメントからそのままですが、OpenAI APIの扱いに慣れている人であれば設定内容の理解は難しくないでしょう。公式にはconfig.yamlというファイル名を使うようですが、簡単に変更できるので明確な名前をつけたほうが良いでしょう。ファイル名を変更したらDocker Composeで指定するのを忘れないようにしましょう。
endpoints:
- name: completions
endpoint_type: llm/v1/completions
model:
provider: openai
name: gpt-3.5-turbo
config:
openai_api_key: $OPENAI_API_KEY
limit:
renewal_period: minute
calls: 10
- name: chat
endpoint_type: llm/v1/chat
model:
provider: openai
name: gpt-3.5-turbo
config:
openai_api_key: $OPENAI_API_KEY
- name: embeddings
endpoint_type: llm/v1/embeddings
model:
provider: openai
name: text-embedding-ada-002
config:
openai_api_key: $OPENAI_API_KEY
Poetryなりpipなり利用している環境でMLflowをインストールします。'mlflow[genai]'をつけておく必要があります。
$ docker compose run --rm app poetry add 'mlflow[genai]'
MLflow Prompt Engineering UIの利用
準備ができたら起動します。
$ docker compose up --build
http://localhost:5000/ にアクセスし、MLflowの画面が映ったら成功です。
画面右の「New run」から「using Prompt Engineering」を選択します。
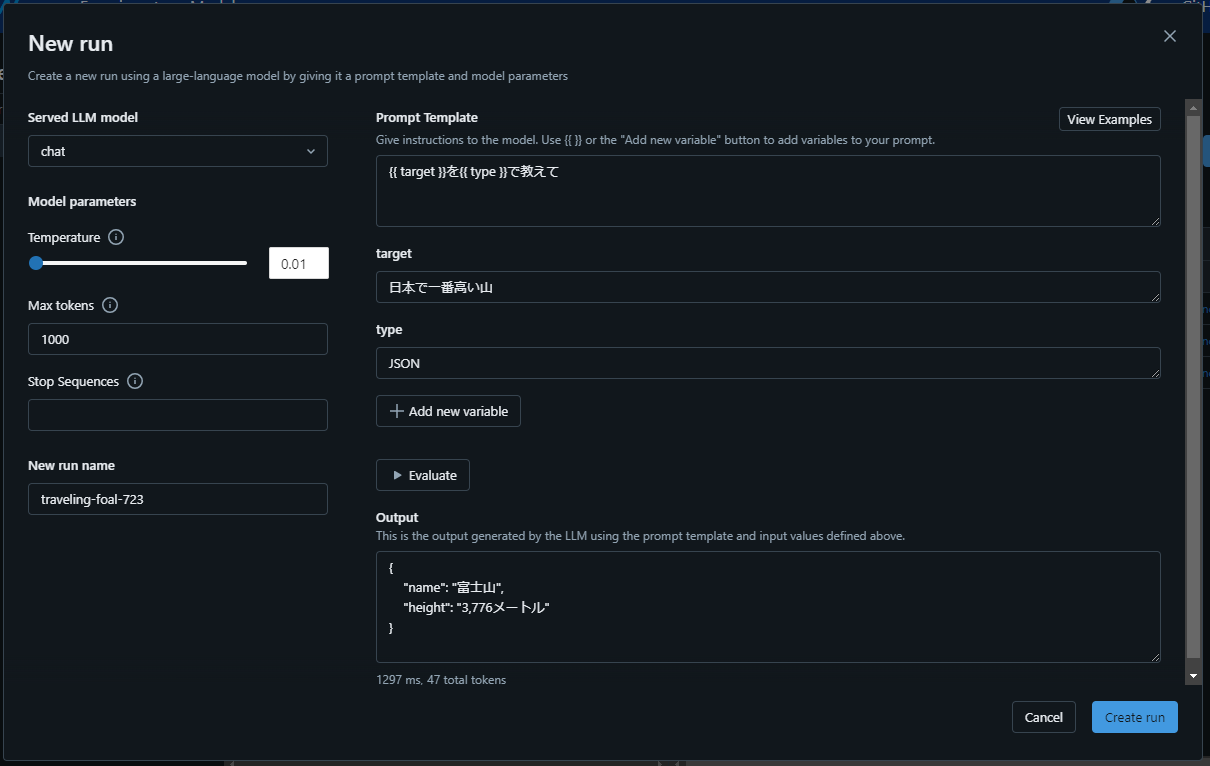
- 「Served LLM model」でモデルを選択します
- GPT-4などを追加したい場合、Deploymentsの設定ファイルに記述すると増えます
- CompletionとChatの両方のモデルが出てくるので注意しましょう。おそらくChatを使うことのほうが多いのではと思います。
- 「Max tokens」の設定を適当に上げておきましょう
- 「Temperature」については拙稿をご確認ください
- 「Prompt Template」にプロンプトを記述します
-
{{ hoge }}のように記述すると変数を定義できます
-
- 「Evaluate」で一度実行できます。
「Evaluation」のビューに行くと結果を確認できます。「Add row」を選択することで、変数に違う値を入れたときの結果をまとめて確認できます。
複数のRunがある場合、同じ変数を入れたときの結果をまとめて確認できます。
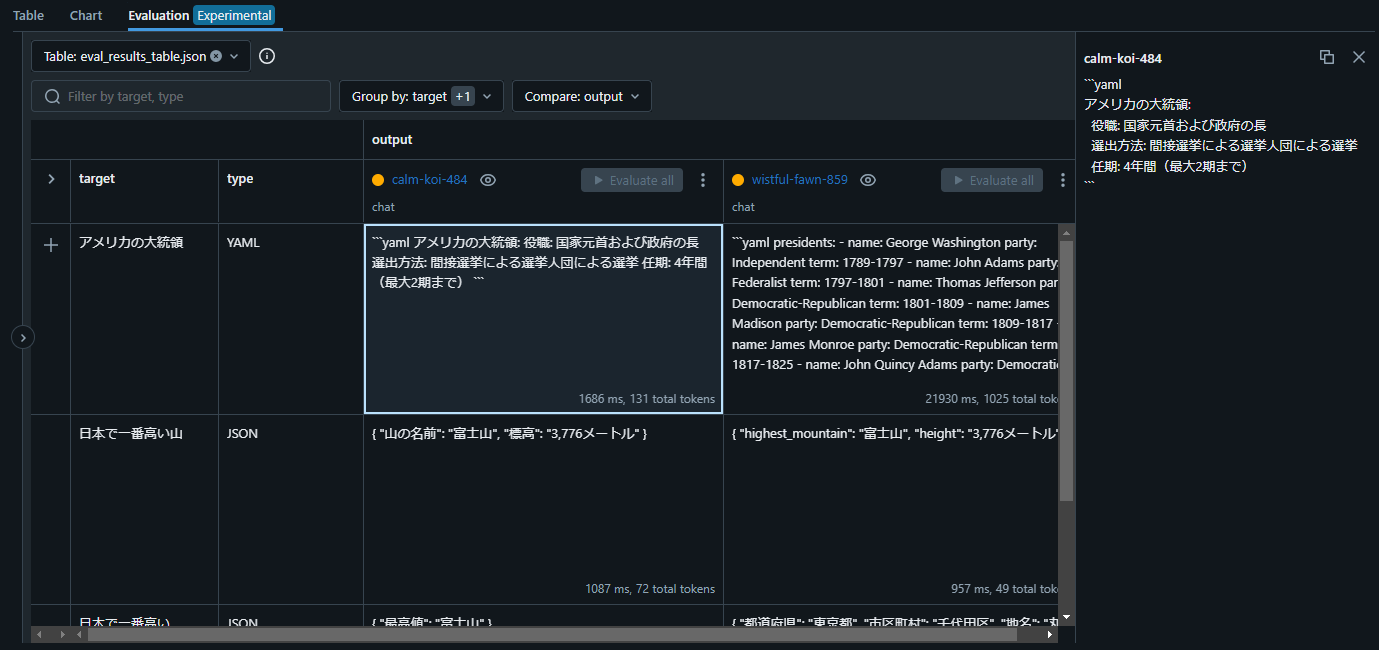
上の図では、「{{ target }}を{{ type }}で教えて」と「{{ target }}について簡潔に回答しなさい。形式は{{ type }}にすること。」というふたつのプロンプトを用意し、「日本で一番高い山」を「JSON」で、「アメリカの大統領」を「YAML」で出力するというふたつのパターンを比較しています。
このように、プロンプトに変数を埋め込んだテンプレートを設定し、複数のテンプレートでの実行結果を一元で確認できました。