BLEU は、正解テキスト(参照文、reference)と生成された文章(生成文、hypothesis)が、どれくらい一致しているかを示す値です。本来は機械翻訳の自動評価手法だと思いますが、文章生成系の様々なタスクで応用されています。
$$
\text{BLEU}=\text{BP}(\prod_{i=1}^{N}precision_i)^{1/N}
$$
$precision_i$ にあたる部分は、$i$-Gramでの文章の一致割合になります。
たとえば「This is a pen」と「This is an apple」は、1gramで2/4一致、2gramで1/3一致なので、$precision_1=\frac{2}{4}$, $precision_2=\frac{1}{3}$です。
Nはよく4が用いられるようですので、1gramから4gramまでの$precision_i$を計算して、総乗をとったもの$(\prod_{i=1}^{N}precision_i)$をBLEUの算出に使います。この値が大きければ大きいほどBLEUも大きくなり、よく一致しているということになります。
計算式の詳しい説明は下記のような記事を参照してください。
ところで総乗を取っているので、$precision_i$のどれかにゼロが入ると全部ゼロになってしまいます。「This is a pen」と「This is an apple」の例で言えば、3gramと4gramでは一致しないためBLEUはゼロです。
このように特定のgram数での一致が無いときBLEUスコアが急激に減少してしまう問題の対策として、Smoothing Functionが提案されています。
たとえば、$precision_i$の値に特定の小さな値を加算するなどしてゼロにならないようにすることで、BLEUの値がゼロにならないようにできます。
NLTKによるBLEUの計算
PythonのNLTKライブラリを用いれば、BLEUスコアは簡単に計算できます。なお本稿では以降NLTKのデフォルトであるBLEU-4(4-gramまで計算)を用います。
import nltk
from nltk import bleu_score
nltk.download('punkt')
print(bleu_score.sentence_bleu([["This", "is", "a", "pen"]], ["This", "is", "an", "apple"]))
#=> 9.53091075863908e-155
ゼロではなく9.53091075863908e-155というとても小さい数値が出力されました。これは実際にはゼロではなくsys.float_info.minを使っているためです。
また、下記のような警告が出力されると思います。
The hypothesis contains 0 counts of 3-gram overlaps.
Therefore the BLEU score evaluates to 0, independently of
how many N-gram overlaps of lower order it contains.
Consider using lower n-gram order or use SmoothingFunction()
SmoothingFunction()を使うように勧められます。
Smoothing Function
NLTKにはSmoothing Functionとして、SmoothingFunctionクラスに手法が7個実装されています。(なにもしないメソッドがmethod0として実装されていて、Smoothing Functionはmethod1~7)
簡単のため、文章を"1","2","3","4"の4種類の語の組み合わせからなるものとして、同じ長さ同士の文章でBLEUを算出してみます。
print(bleu_score.sentence_bleu([["1"]], ["1"]))
print(bleu_score.sentence_bleu([["1", "2"]], ["1", "2"]))
print(bleu_score.sentence_bleu([["1", "2", "3"]], ["1", "2", "3"]))
print(bleu_score.sentence_bleu([["1", "2", "3", "4"]], ["1", "2", "3", "4"]))
#=> 1.821831989445342e-231
#=> 1.491668146240062e-154
#=> 1.2213386697554703e-77
#=> 1.0
どれも文章は完全に一致しているのですが、長さ3以下ではとても小さい値になり、長さ4になってはじめて1になりました。
ここで例えばSmoothingFunction().method1を与えてみます。
fn = bleu_score.SmoothingFunction().method1
print(bleu_score.sentence_bleu([["1"]], ["1"], smoothing_function=fn))
print(bleu_score.sentence_bleu([["1", "2"]], ["1", "2"], smoothing_function=fn))
print(bleu_score.sentence_bleu([["1", "2", "3"]], ["1", "2", "3"], smoothing_function=fn))
print(bleu_score.sentence_bleu([["1", "2", "3", "4"]], ["1", "2", "3", "4"], smoothing_function=fn))
#=> 0.1778279410038923
#=> 0.316227766016838
#=> 0.5623413251903491
#=> 1.0
小さい値ではありますが、最も小さくても0.17と、$1.82*10^{-231}$だったSmoothing無しの例に比べてかなり大きくなっていて、1.0まで段階的に上がるようになっています。
本稿では、文章の長さによってSmoothingがどれくらい変わるのかを可視化して調べてみます。
下記プログラムで、長さが1~10までの文章を生成し、それぞれに対してBLEUを計算していきます。
import pandas
def numberlist(num: int):
return [ str(i+1) for i in range(num) ]
def bleu_matrix(smoothing_fn = None, ref_max: int = 10, gen_max: int = 10):
data = []
for i_ref in range(10):
i_ref += 1
for i_gen in range(10):
i_gen += 1
try:
score = bleu_score.sentence_bleu([numberlist(i_ref)], numberlist(i_gen), smoothing_function=smoothing_fn)
except:
score = -1
data.append({
"i_ref": i_ref,
"i_gen": i_gen,
"bleu": score,
"bleu_p": int(score * 100)
})
return pandas.DataFrame(data)
bokehで可視化します。
from bokeh.io import output_notebook, show
from bokeh.models import ColumnDataSource, LinearColorMapper
from bokeh.plotting import figure
from bokeh.transform import transform
output_notebook()
def show_heatmap(df):
colors = [ f"#f{hex(15-i)[2:]}{hex(15-i)[2:]}" for i in range(10) ]
mapper = LinearColorMapper(palette=colors, low=0, high=1)
source = ColumnDataSource(df)
p = figure()
p.rect(x="i_ref", y="i_gen", width=1, height=1, source=source, line_color=None, fill_color=transform('bleu', mapper))
p.text(x="i_ref", y="i_gen", text="bleu_p", source=source, text_align="center", text_baseline="middle")
p.xaxis.axis_label = "参照文の長さ"
p.yaxis.axis_label = "生成文の長さ"
show(p)
smoothing_function = None(method0)
とりあえずSmoothingは無しでプログラムを動かしてみます。
show_heatmap(bleu_matrix())
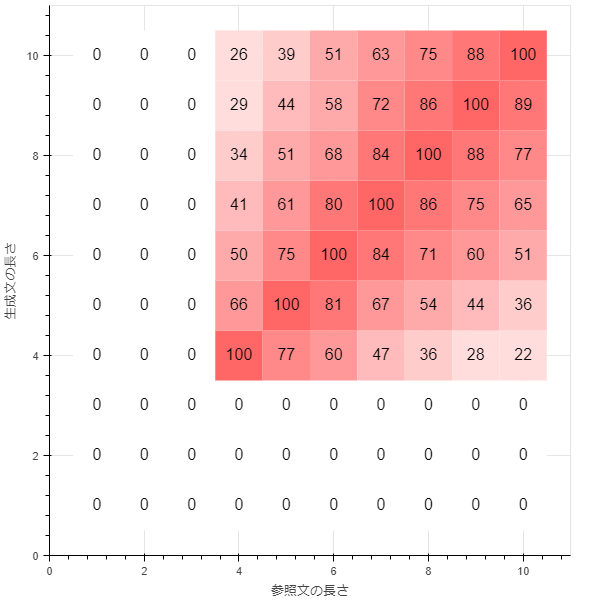
可視化にあたって、BLEUは100倍してパーセント表示にしています。(原則として0~100)
長さが4に満たない場合ゼロになっており、値が急に変わってしまっているのが分かります。
smoothing_function = method1
SmoothingFunction.method1を使ってみます。これは、$precision_i$がゼロだった時に小さな値epsilonを加算しています。
show_heatmap(bleu_matrix(smoothing_fn = bleu_score.SmoothingFunction().method1))

Smoothingをしていない時に比べて、文章の長さが4未満のときの値とスコアがなめらかに繋がっているように見えます。
smoothing_function = method2
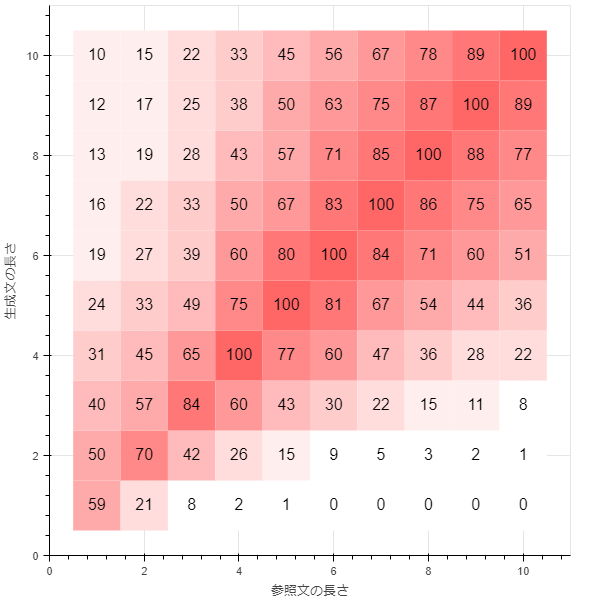
smoothing_function = method3

smoothing_function = method4
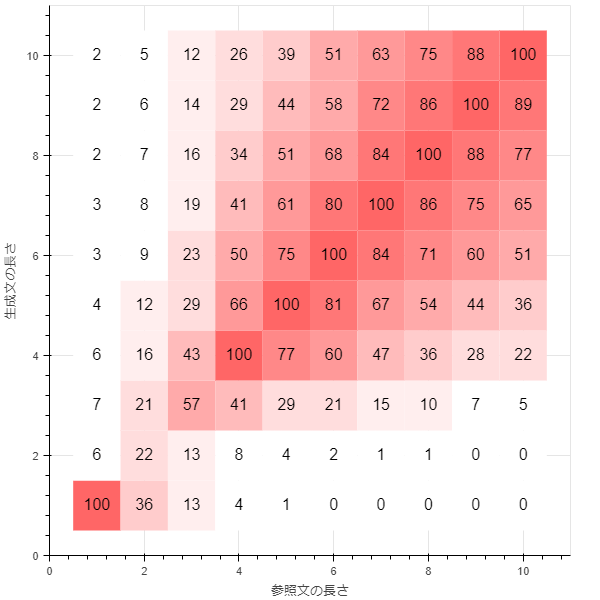
method3に似ていますが、短い文章でよりBLEUスコアが小さくなるようになっています。
smoothing_function = method5
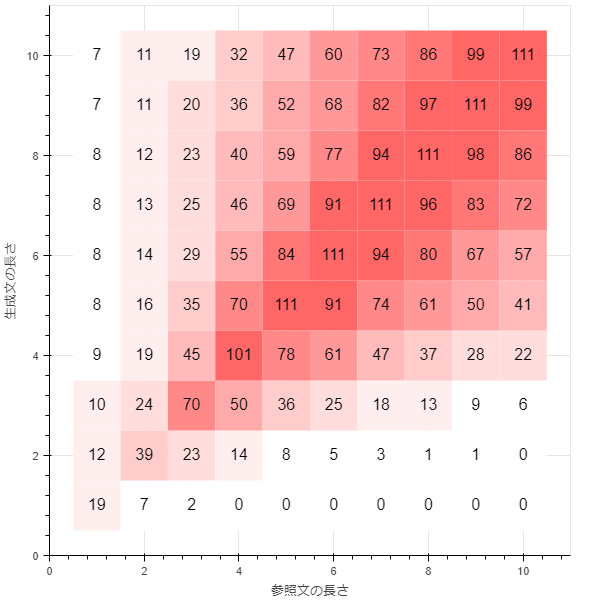
BLEU-4であっても5-gramの$precision_5$まで計算して、移動平均のようなものを取る手法のようです。
BLEUの値が1(グラフ上では100)を超えている所がある点に注意です。
smoothing_function = method6
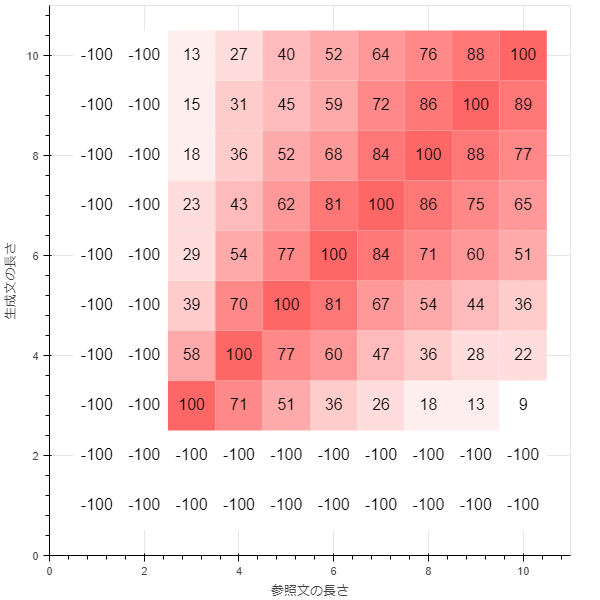
長さが2以下の場合、算出できないのでBLEUが-1(グラフ上では-100)で表記しています。
smoothing_function = method7
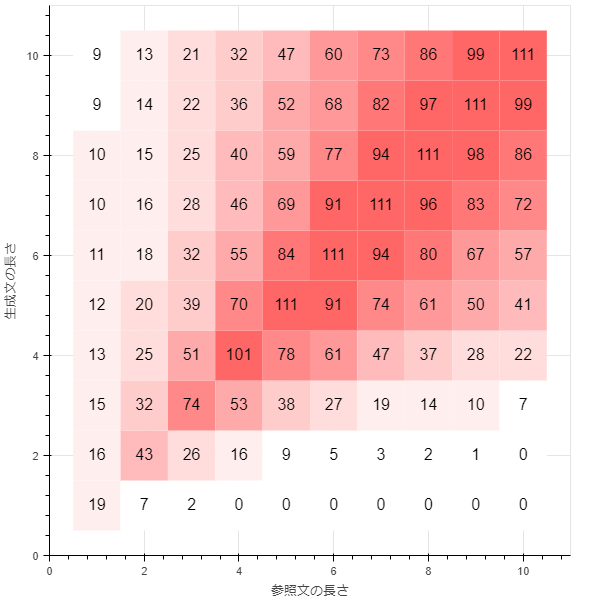
method4とmethod5を順番に適用したものです。
まとめ
大量のコーパスを処理してBLEUを計算する時に、BLEUがゼロになってしまう値が含まれていたりすると、統計的な集計をするときに大きな影響が出てしまいます。Smoothingを使うことで、そういった影響を緩和できると思います。