NLP分野の主要なタスクに要約生成,機械翻訳などテキストの自動生成があります.
今回はテキスト生成モデルの評価指標について調査したため,紹介します.
ROUGE 1
ROUGEは要約生成等のモデルの評価に広く利用される評価指標で,正解要約中のN-gramのうち,どの程度が生成要約に含まれているかで評価します.
ROUGE\mbox{-}N = \frac{\rm{Count_{ExactMatch}}}{\rm{Count_{reference}}}
| 変数 | 説明 |
|---|---|
| $\rm{Count_{reference}}$ | 正解テキストに含まれるN-gramの数 |
| $\rm{Count_{ExactMatch}}$ | 正解テキストと生成テキストとの間で一致するN-gramの数 |
例えば,ROUGE-1は1gramでの一致,ROUGE-2では2gramでの一致をみます.
ROUGEは生成要約を長くすればするほど,正解要約とマッチするN-gramが増えるため,評価値が高くなる傾向にありますが,一般的に要約タスクでは単語数など要約の長さの上限が設けられていることが多いため,要約生成モデルの自動評価指標として広く利用されています.
また,出現する最大の系列(Longest Common Subsequence)での一致をみるROUGE-Lもあります.
こちらの記事2ではROUGEについて詳細に説明してあります.
BLEU 3
BLEUは機械翻訳等のモデルの評価に広く利用される評価指標で生成したテキスト中のN-gramのうち,どの程度が正解テキストに含まれているかで評価します.
ROUGEがRecallベースの評価指標であったのに比べて,BLEUは適合率ベースの評価指標になります.
BLEU = BP(\prod_{n=1}^{N}precision_{n})^{1/N} \\
BP = {\rm min}(1, {\rm exp}(1-\frac{{\rm length}(reference)}{{\rm length}(candidate)})) \\
Precision_{n} = \frac{\sum_{candidate}\sum_{n\mbox{-}gram}{\rm min}({\rm Count_{candidate}}(n\mbox{-}gram), {\rm Count_{reference}}(n\mbox{-}gram))}{\sum_{candidate}{\rm Count_{candidate}}}
| 変数 | 説明 |
|---|---|
| ${\rm length}(reference)$ | 正解テキストの長さ(単語数) |
| ${\rm Count_{candidate}}$ | 生成テキストに含まれるn-gramの数 |
| ${\rm Count_{candidate}}(ngram)$ | ある$n\mbox{-}gram$に対する生成テキストでの出現回数 |
| ${\rm Count_{reference}}(ngram)$ | ある$n\mbox{-}gram$に対する正解テキストでの出現回数 |
単純にマッチしたN-gramの適合率で評価すると,出力テキストが極端に短い場合に不当に高い評価値となってしまいます.
そのため,BLEUでは出力したテキストの長さに対する制約である$BP$(Brevity Penalty)を導入しています.
この制約により,正解テキストの長さに比べて,生成したテキストが短いほど,評価値が下がる仕組みになっています.
テキスト生成に関する論文などでは$N=4$とし評価しているものをよく見かけますが,1,2,3-gramまでは一致する系列が見つかっても,4-gramで一致する系列が見つからなかった場合,$Precision_{4}=0$となり,BLEUスコアも0となってしまう問題があります.
一方で,この問題を回避するために,NLTKに実装されているBLEUはsmoothing処理が施してあり,こちらの記事4で紹介してあります.
CIDEr5
CIDErは画像に対するキャプションの生成モデルに対する評価指標です.
キャプション生成とは入力画像に対する説明文を生成するタスクです.
CIDErでは正解キャプションと生成キャプションから生成キャプションに対する評価値を算出します.
CIDErでは,多くの画像に出現するN-gramに対しては重みを小さく,ある画像にのみ出現するようなN-gramには重みを大きくするようにTF-IDFの重みを計算します.
正解キャプション$s_{i}$の$j$番目の文のN-gramに対するTFIDFベクトル$g_{k}(s_{ij})$は以下の式で計算されます.
第一項がTF,第二項がIDFを表しています.

| 変数 | 説明 |
|---|---|
| $s_{ij}$ | 正解キャプション$s_{i} \in S$の$j$番目の文 |
| $\omega$ | N-gramの集合 |
| $h_{k}(s_{ij})$ | 文$s_{ij}$に出現するN-gram$\omega_{k}$の数 |
| $I$ | データセット中の画像の数 |
| $g_{k}(s_{ij})$ | $s_{ij}$の$\omega$に対するTFIDFベクトル |
あるn-gramに対するTFIDFベクトル$g_{k}$を正解キャプション,生成キャプションに対して計算し,ベクトル間の平均コサイン類似度$\rm{CIDEr}_{n}$を計算します.
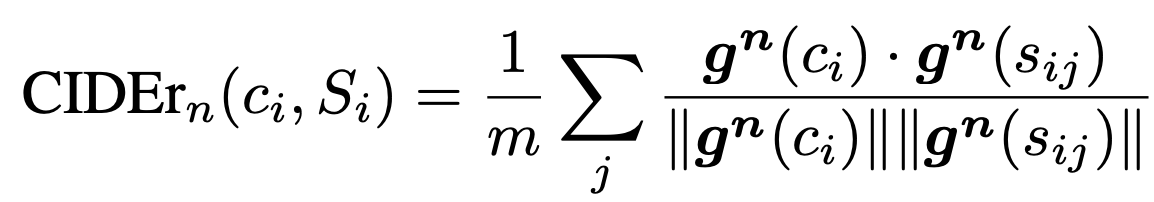
そして,それぞれの$\rm{CIDEr}_{n}$に対する重み付き和が最終的な評価値となります.
原著論文では$N=4$,$w_{n}=1/4$と$\rm{CIDEr}_{n}$の平均を採用しています.
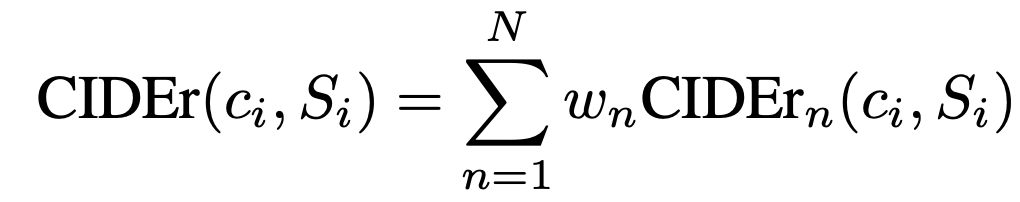
METEOR6
METEORはBLEUやROUGEなどの完全一致で評価する手法に対し,WordNetの同義語やステミング処理などを利用して柔軟にN-gram間の一致を測る評価手法です.
Precision, RecallはUnigram単位のマッチから計算します.
また連続したUnigramがマッチした場合に高い評価値を与えるようにするためにPenaltyを計算します.
$unigrams\mbox{-}matched$は正解テキストと生成テキスト間で一致したunigramの数で,$chunks$は順番が同じ部分系列の数です.
例えば,2つの文"the president spoke to the audience"と"the president then spoke to the audience"があった場合, $unigrams\mbox{-}matched=6$,$chunks$は"the president"と"spoke to the audience"の2つなので$chunks=2$となります.
したがって,順番が一致する系列が少ないほどPenaltyが小さくなるように設計されています.

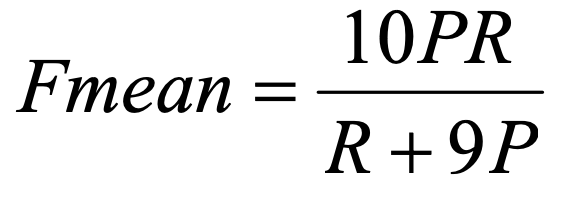
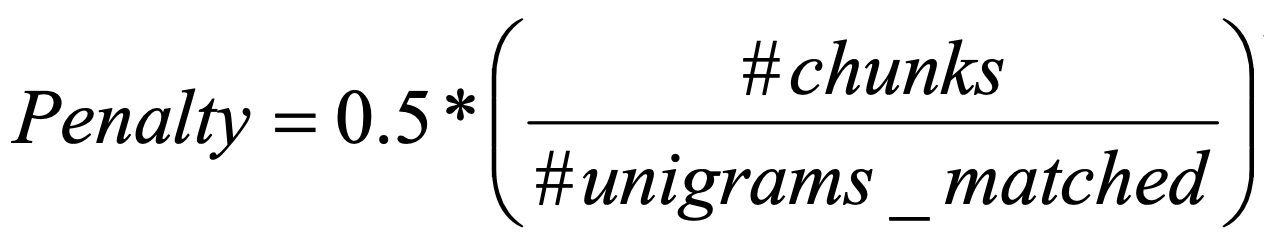
原著論文では,機械翻訳タスクにおいて,METEORはBLEUなどと比べて人手評価とピアソン相関係数が高いという実験結果を報告しています.
Word Movers Distance 7
WMD(Word Movers Distance)は文書間の距離を測る手法です.
従来の文書間の類似度計算では,文書をBag−of−Wordsのベクトルに変換し,類似度を計算する方法などがありますが,言い換え表現などに対応できないため,精度は高くはありませんでした.
一方,単語をベクトル空間に埋め込むskip-gramなどが提案されてから,多くのタスクでword2vecやgloveなどで事前学習した単語ベクトルが利用される様になりました.
WMDでも単語の埋め込みベクトルを利用して文書間の距離を計算しています.
また,単純に単語ベクトルの平均を文書ベクトルとするのではなく,文書間の単語同士を対応付けるコストが小さいほど,それらの文書は類似しているという仮説に基づいています.

WMDはEarth Movers Distance(EMD)という輸送問題という最適化問題を解くことで文書間の類似度を計算します.
WMDについて説明する前にEMDについて説明します.
EMDは2つの確率分布間の距離尺度の一つでシグネチャ(特徴量とその重みのペアの集合)として与えられる分布
$P={(p_{1},w_{p1}),...,(p_{i},w_{pi}),...,(p_{m},w_{pm})}$
$Q={(q_{1},w_{q1}),...,(q_{i},w_{qi}),...,(q_{m},w_{qn})}$
の距離です.
また,EMDは輸送問題に基づいており,簡単に説明します.
Pの各地点$p_{1},...,p_{m}$には重さ$w_{p1},...,w_{pm}$の荷物があります.
一方Qの各地点$q_{1},...,q_{n}$には重さ$w_{q1},...,w_{qn}$の荷物が入る倉庫があります.
また,$p_{i}$から$q_{j}$まで荷物を運ぶ際には$d_{i,j}$のコストがかかります.
更に,$p_{i}$から$q_{j}$まで運ぶ荷物の輸送量を$f_{i,j}$とします.
このとき,Pにある荷物を全て,もしくはQの倉庫が満杯になるまで運ぶときに,全体のコストを最小化するように$f_{ij}$を最適化する問題です.
2拠点間のコストは$d_{ij}$は特徴量がベクトルのときはユークリッド距離,確率分布のときはKLダイバージェンスなどが利用され,事前に定義できる前提のため,最適化する変数は$P$から$Q$まで運ぶ輸送量$F$のみとなります.
{\rm min}\sum_{i=1}^{m}\sum_{j=1}^{n}d_{i,j}f_{i,j}
また,制約として,
・$q_{j}$から$p_{i}$へは荷物は運ばない
f_{i,j}\geq 0, 1\leq i \leq m, 1\leq j \leq n
・$p_{i}$にある荷物しか運べない
\sum_{i=1}^{n}f_{i,j} \leq w_{pi}, 1 \leq i \leq m
・$q_{i}$の容量分しか入らない
\sum_{j=1}^{n}f_{i,j} \leq w_{qj}, 1 \leq j \leq n
・$p_{i}からq_{j}$への輸送量の上限は荷物量$w_{pi}$か容量$w_{qj}$の小さい方
\sum_{i=1}^{m}\sum_{j=1}^{n}f_{i,j}={\rm min}(\sum_{i=1}^{m}w_{pi}, \sum_{j=1}^{n}w_{qj})
この最適化問題を解くことで最適な輸送量$F$が求まります.
最終的にEMDは以下の式で求まります.
EMD = \frac{\sum_{i=1}^{m}\sum_{j=1}^{n}f_{i,j}d{i,j}}{\sum_{i=1}^{m}\sum_{j=1}^{n}f_{i,j}}
WMDではPとQをそれぞれ文と考え,文P中の単語を文Qに対応付けるコストを計算し,そのコストが小さいほど文Pと文Qが類似していると考えます.
EMDと同じく,特徴量$p_{i}$($q_{i}$)は文P(文Q)の$i$番目の単語の特徴量を表します.
また,重み$w_{pi}$($w_{qi}$)は文の長さで正規化された出現頻度になります.
例えば, $D_{1}$の"Obama speaks to the media in Illinois."という文ではStopWordを除くと,"Obama speaks media Illinois"の4単語であるため,それぞれの単語の重み$w_{d0,i} = 1/4$となります.
また文P中の単語$i$と文Q中の単語$j$の間のコスト$d_{i,j}$は$p_{i}$と$q_{j}$のユークリッド距離で計算できます.
後はEMDと同じく,対応付け行列$F$(語彙数$v$×$v$)を最適化します.
{\rm min}\sum_{i=1}^{v}\sum_{j=1}^{v}d_{i,j}f_{i,j}\\
\sum_{j=1}^{v}T_{i,j} = w_{p,i}\quad(1 \leq i \leq v)\\
\sum_{i=1}^{v}T_{i,j} = w_{q,j}\quad(1 \leq j \leq v)
EMDの解き方はこちらの記事8で説明されています.
またこちらの記事7では実例を交えてWMDを説明しています.
BERTScore 9
BERTScoreは言語モデルBERTを利用した自動評価指標でICLR2020にAcceptされたようです.
事前学習されたBERTから得られるベクトル表現を利用して,テキスト間の類似度を計算する評価手法です.
スコアは論文中の以下の図のような処理で計算します.
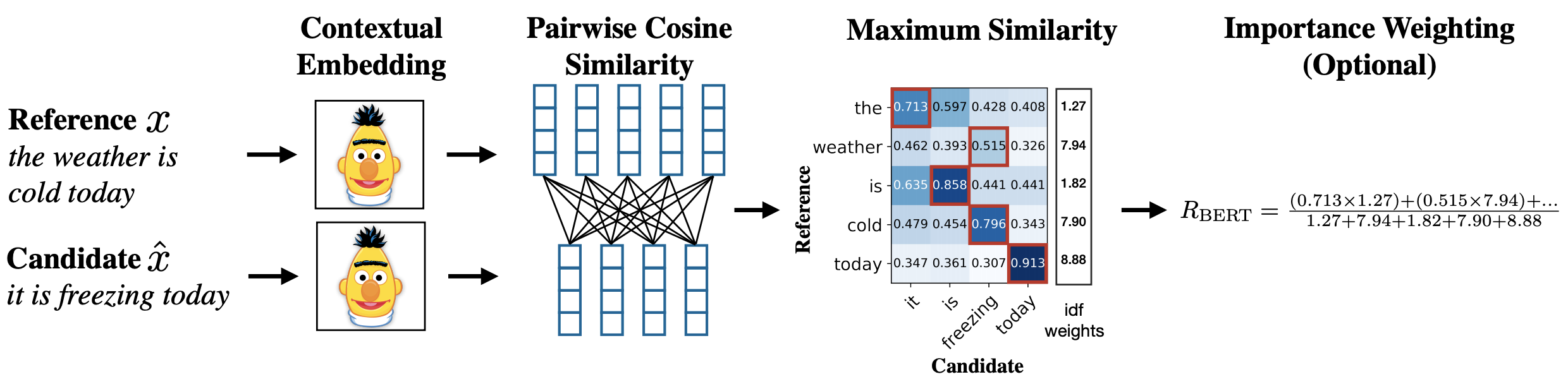
まず生成テキスト$Candidate$と正解テキスト$Reference$をBERTに入力し,トークンのベクトル表現を獲得します.
次に,それらのベクトル表現を利用して,トークン間のcos類似度行列を作成します.
最後に各トークンに対して最大類似度(赤枠で囲まれた値)を利用して,Precision,Recall,F値を計算し,スコアとします.
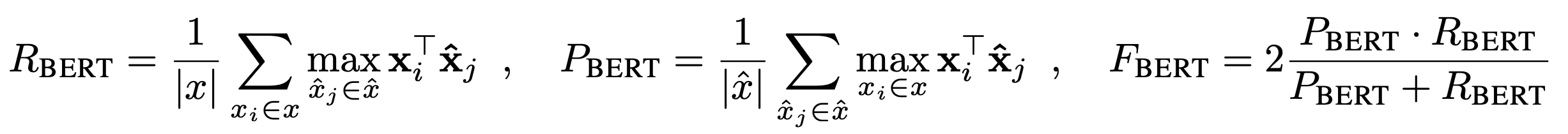
また,トークンの重要度を表す重みとしてIDF値を利用する場合は以下のようになります.
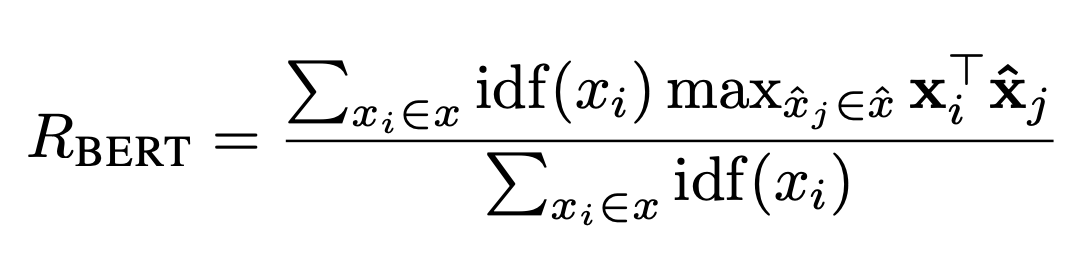
実験では機械翻訳やキャプション生成において,上述したBLEUやCIDErなどの評価手法と比べて,人手評価値との相関が高いことを示しています.
個人的にはシステムが出力した生成テキストと正解テキスト,それらに対する人手評価値までが付与されたデータセットが公開されているのは知らず,評価指標の評価や評価指標同士の比較が行いやすくなっているように感じます.
MoverScore 10
上記のBERTScoreを改良した位置づけにあるのがMoverScoreになります.
MoverScoreはBERTから得られたベクトル表現に対してWMDを適用することで,2つのテキスト間の類似度を計算しています.
BERTScoreは計算時に各トークンに対する最大の類似度(赤枠)を利用していました.
一方で,MoverScoreはトークン間の対応付けをWMDを用いて行うため,BERTScoreのように1-1のハードなアライメントではなく,1-Nのようなソフトなアライメントを実現しています.
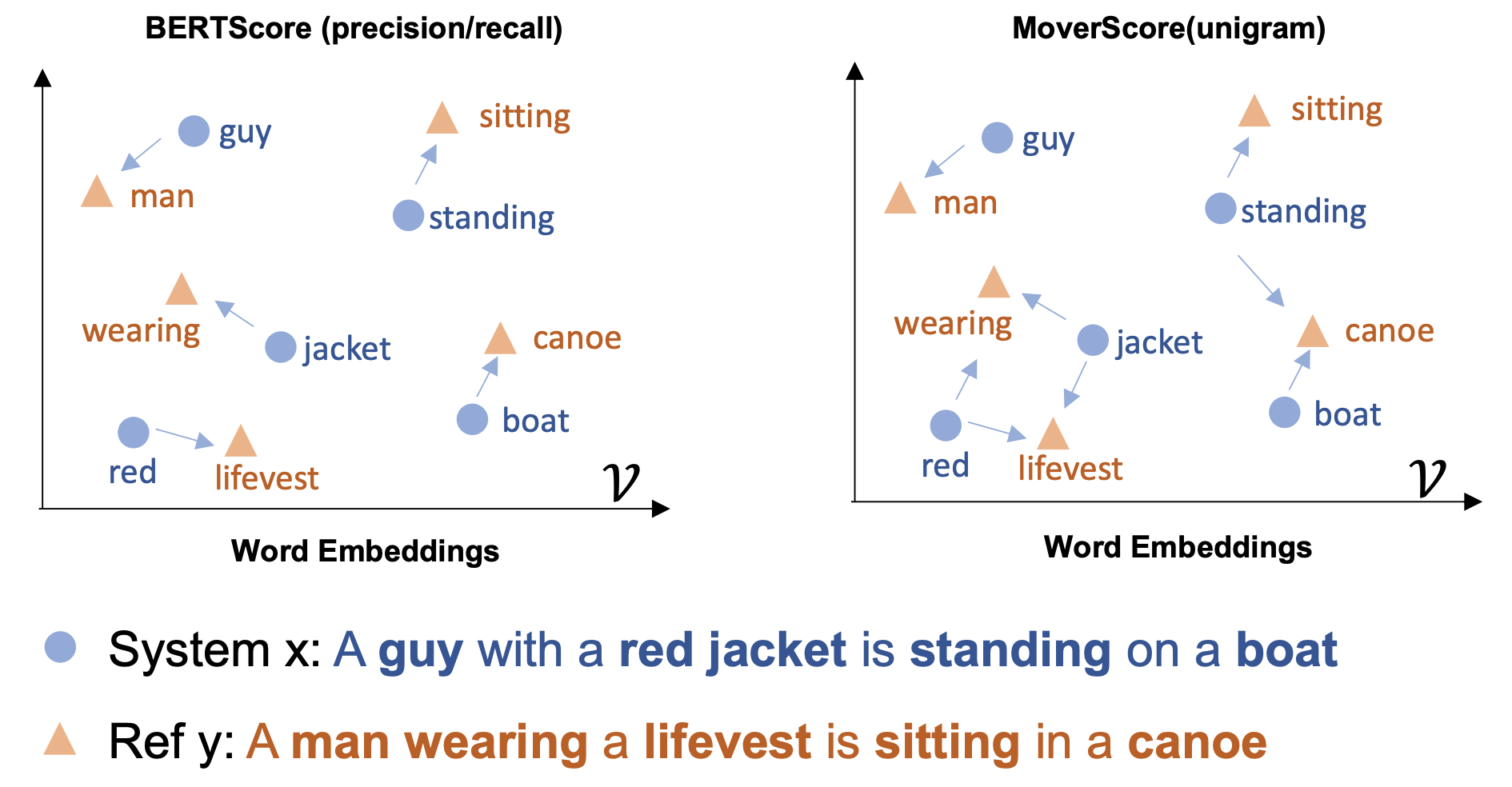
また実験では機械翻訳,キャプション生成などのデータセットを利用して人手評価値との相関が高いことを示しています.
特に,BERTScoreとも比較しており,MoverScoreの方が人手評価値との相関が高い結果となっていました.
まとめ
N-gramベースの一致に基づいた手法や単語の分散表現を利用した評価指標についていくつかまとめました.
多くの論文がこれまでベースとなっていた評価指標に比べ,人手評価値との相関が高いことを示していました.
特にBERTを利用した評価指標は教師なしかつ質の高いベクトル表現が得られるため,広く利用されそうです.
他にも載せられていないものがあるので,適宜更新しようかと思います.
間違いがあれば教えてください.