はじめに
私の会社のCS部門では、お客さまとの打ち合わせでLooker Studioを用いた分析データを共有しているのですが、このプロセスにはいくつかの課題がありました。
課題の解決にあたって初めてGCP(BigQuery, Cloud Functions)を触ったので、備忘録として記事を書きました。
従来の手順
- アプリケーションの管理画面から過去一週間分のデータをCSV形式でエクスポート
- そのデータをGoogleスプレッドシートに手動でコピー
- スプレッドシートからLooker Studioにデータを読み込み、分析を実施
課題
- CSVファイルのダウンロードとスプレッドシートへのコピー作業にちょっとした手間と時間が必要
- 各顧客データの管理が手作業に依存しており、継続的な更新が必要となるため効率が悪い
- データ量の増加により、スプレッドシートの行数制限に達する恐れがある
- 大容量データのダウンロードが本番DB(RDS)に負荷をかけ、パフォーマンスに影響を及ぼす可能性がある
特にスプレッドシートの行数制限は喫緊の課題でした。
解決策の導入
- Amazon S3に保存されたCSVファイルをGCPのBigQueryに自動的に読み込ませる仕組みを導入
- BigQuery上で、
client_idごとにビュー(仮想テーブル)を作成し、Googleアカウントに応じた権限設定を通じて必要なデータのみアクセス可能にする
この改善により、データ管理の自動化と効率化を実現し、DB負荷を抑えることができました。
BigQueryの選択理由
Looker StudioのデータソースとしてRedshiftやAthenaを利用する案もありましたが、以下の制約からBigQueryを採用しました。
- できるだけ大きなコストをかけたくない
- 各顧客のカスタマイズ要求に応じて、分析ダッシュボードはLooker Studioのまま維持したい
- Looker StudioはAthenaからのデータ読み込みに対応していない
データ更新手順の詳細
データの更新プロセスは、以下のようになっています。
CSVのアップロード先がS3であるのは、アプリケーションのインフラが元々AWSで構成されているためです。
CSVファイルの作成元はRDSです。
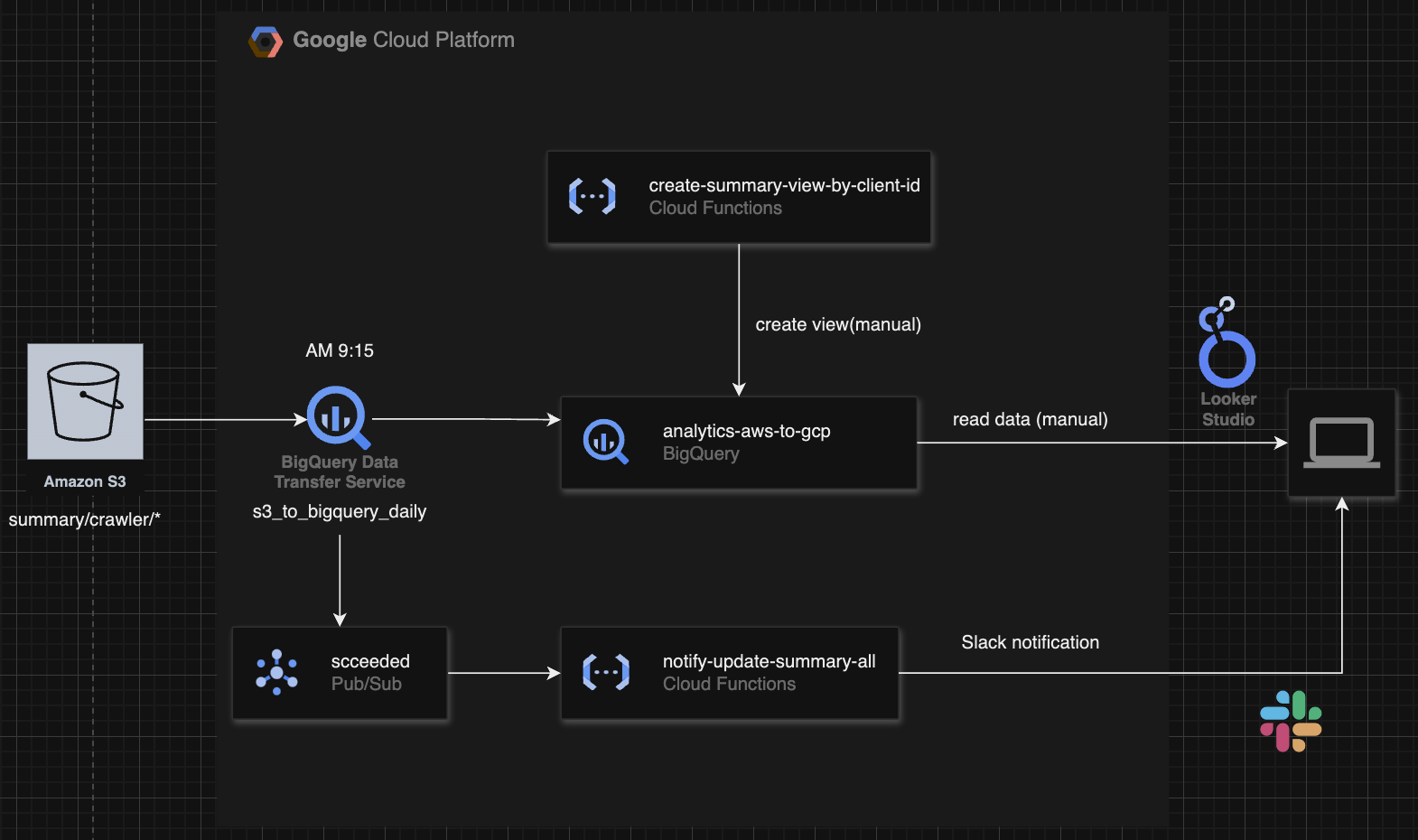
手順は以下の通りです。
-
CSVアップロード(AM 9:00): 前日分の
summaryデータがS3バケット(summary/crawler/*)に自動的にアップロードされる -
BigQueryへのデータ転送(AM 9:15): BigQuery Data Transfer Serviceが起動し、S3からBigQueryの
summaryデータセット内のsummary_allテーブルにデータを転送する -
データ転送成功時の通知: データ転送が成功すると、Cloud Pub/Subの
succeededトピックにメッセージが投稿される。その後、Google Cloud Functions(GCF)notify-update-summary-allがこのメッセージを受け取り、Slackに通知を送信する -
ビューの自動更新:
summary_allテーブルが更新されると、各クライアントに対応するビューも自動的に更新される
実装の概要
既存データの転送
まずはS3で保管している数ヶ月分の日別CSVファイルをBigQueryのテーブルに転送する必要があります。
BigQueryで元データのデータセットとビューを作成
プロジェクトanalytics-aws-to-gcpからデータセットsummaryを作成し、以下のクエリでテーブルsummary_allを作成します。
CREATE TABLE `analytics-aws-to-gcp.summary.summary_all`
(
created_at STRING,
client_id INT64,
url STRING,
...
)
S3からBigQueryへのデータ転送
S3からBigQueryのテーブルへのデータ転送には、BigQuery Data Transfer Serviceを使用します。
データ転送から転送の作成を行います。
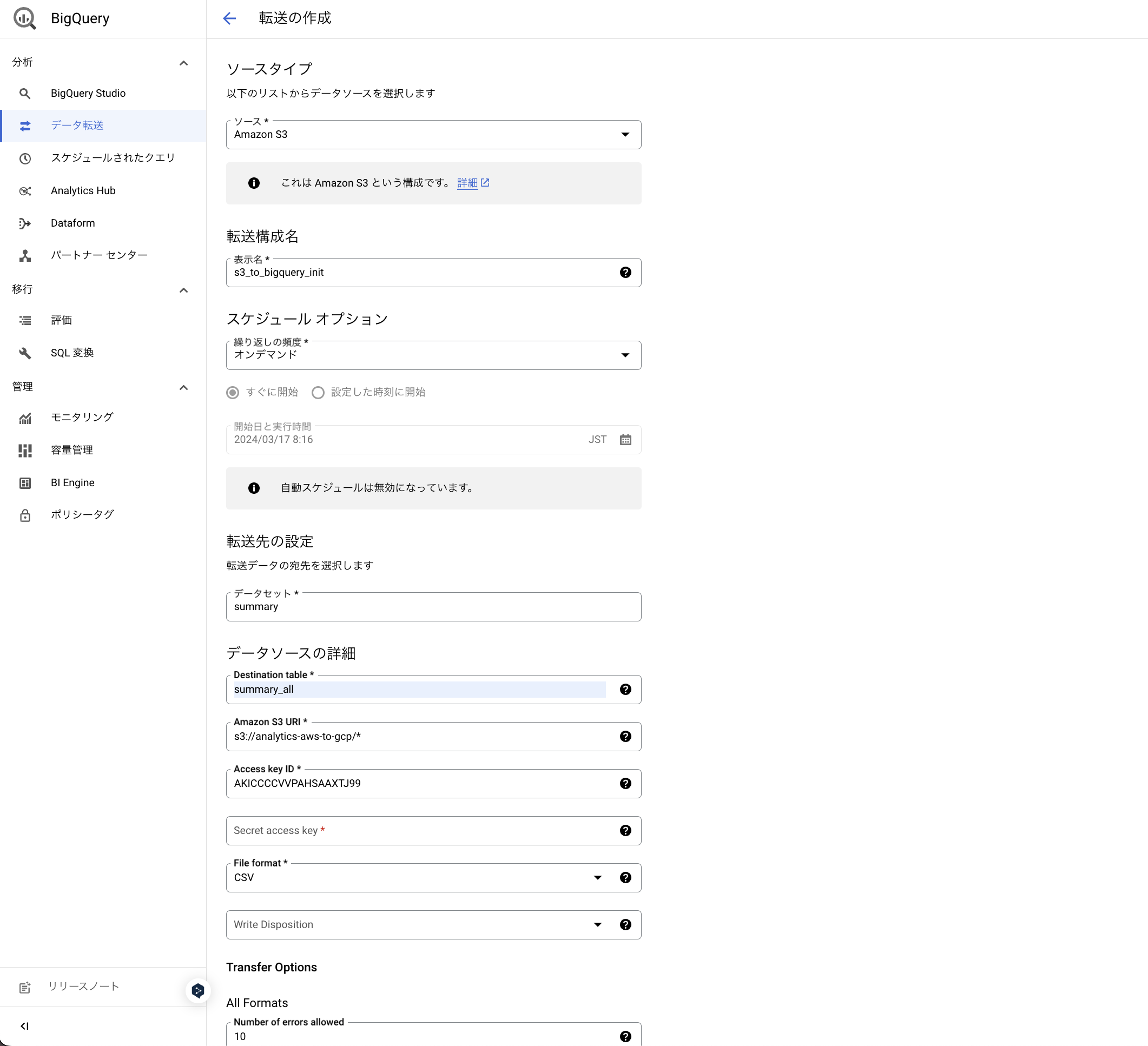
データソースのS3バケットanalytics-aws-to-gcpから複数のCSVを読み込むため、Amazon S3 URIにはs3://analytics-aws-to-gcp/*のようにワイルドカードを使用します。
また、BigQueryからS3へのアクセスにはクレデンシャル(アクセスキーとシークレットアクセスキー)が必要です。
そのため、AWS側でAmazonS3ReadOnlyAccessポリシーを付与したIAMユーザーを作成し、アクセスキーを発行する必要があります。
Number of errors allowedでデータ転送時に許容されるエラーの最大数を指定できます。
各クライアントのビューの自動作成
BigQueryのsummary_allテーブルへ既存データの転送が完了したら、各クライアントに対応したビューを作成します。
手動でも作成できるのですが、多数のクライアントが存在するので、Cloud Functionscreate-summary-view-by-client-idで自動作成します。
import os
from google.cloud import bigquery
from flask import jsonify
def create_summary_view_by_client_id(_):
# BigQueryクライアントを初期化
client = bigquery.Client()
print("Function execution started.")
# `client_id` のリストを抽出するクエリを実行
client_ids_query = """
SELECT DISTINCT client_id
FROM `analytics-aws-to-gcp.summary.summary_all`
"""
query_job = client.query(client_ids_query)
# クエリの結果から client_id のリストを生成
client_ids = [row["client_id"] for row in query_job.result()]
for client_id in client_ids:
# クライアントごとのデータセットを作成
dataset_id = f"analytics-aws-to-gcp.summary_{client_id}"
dataset = bigquery.Dataset(dataset_id)
dataset.location = "asia-northeast1"
try:
client.create_dataset(dataset, exists_ok=True) # データセットがない場合は作成
print(f"Created dataset {dataset_id}")
except Exception as e:
print(f"Error creating dataset for client_id {client_id}: {e}")
continue
# データセット内にビューを作成
view_id = f"{dataset_id}.summary_view"
view_query = f"""
SELECT *
FROM `analytics-aws-to-gcp.summary.summary_all`
WHERE client_id = {client_id}
"""
view = bigquery.Table(view_id)
view.view_query = view_query
try:
# ビューを作成し、結果のTableオブジェクトを取得
created_view = client.create_table(view, exists_ok=True)
print(f"Created view at {created_view.full_table_id}")
except Exception as e:
print(f"Error creating view for client_id {client_id} in dataset {dataset_id}: {e}")
print("Function execution completed successfully.")
return jsonify({"message": "View creation completed successfully"}), 200
functions-framework==3.*
google-cloud-bigquery
「テスト中」タブからCLOUD SHELLを開いて、テストコマンドから関数を実行します。
curl -m 3610 -X POST https://asia-northeast1-analytics-aws-to-gcp.cloudfunctions.net/create-summary-view-by-client-id \
-H "Authorization: bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{}
データセットへの権限付与
ビューを作成した後、各クライアントが自分に関連するデータのみを閲覧できるように、細かい権限設定を行います。
しかし、ビューが元データセットsummaryのsummary_allテーブルを参照しているため、単にクライアントごとのデータセットに権限を付与しても、summaryデータセットへのアクセス権限がなければビューを閲覧できません。
解決策として、元のデータセットsummary内で、クライアントごとのビューを承認済みビューとして登録します。
これにより、各クライアントは自分のビューを介してsummary_allテーブルのデータを安全に閲覧できるようになります。

日次データの自動更新
既存データの転送と初期設定が完了したら、日次で新たなデータが自動的に追加されるようにします。
S3からBigQueryへのデータ転送
既存データを転送したときと同様に、BigQuery Data Transfer Serviceを使用します。
転送日時はUTCで指定します。
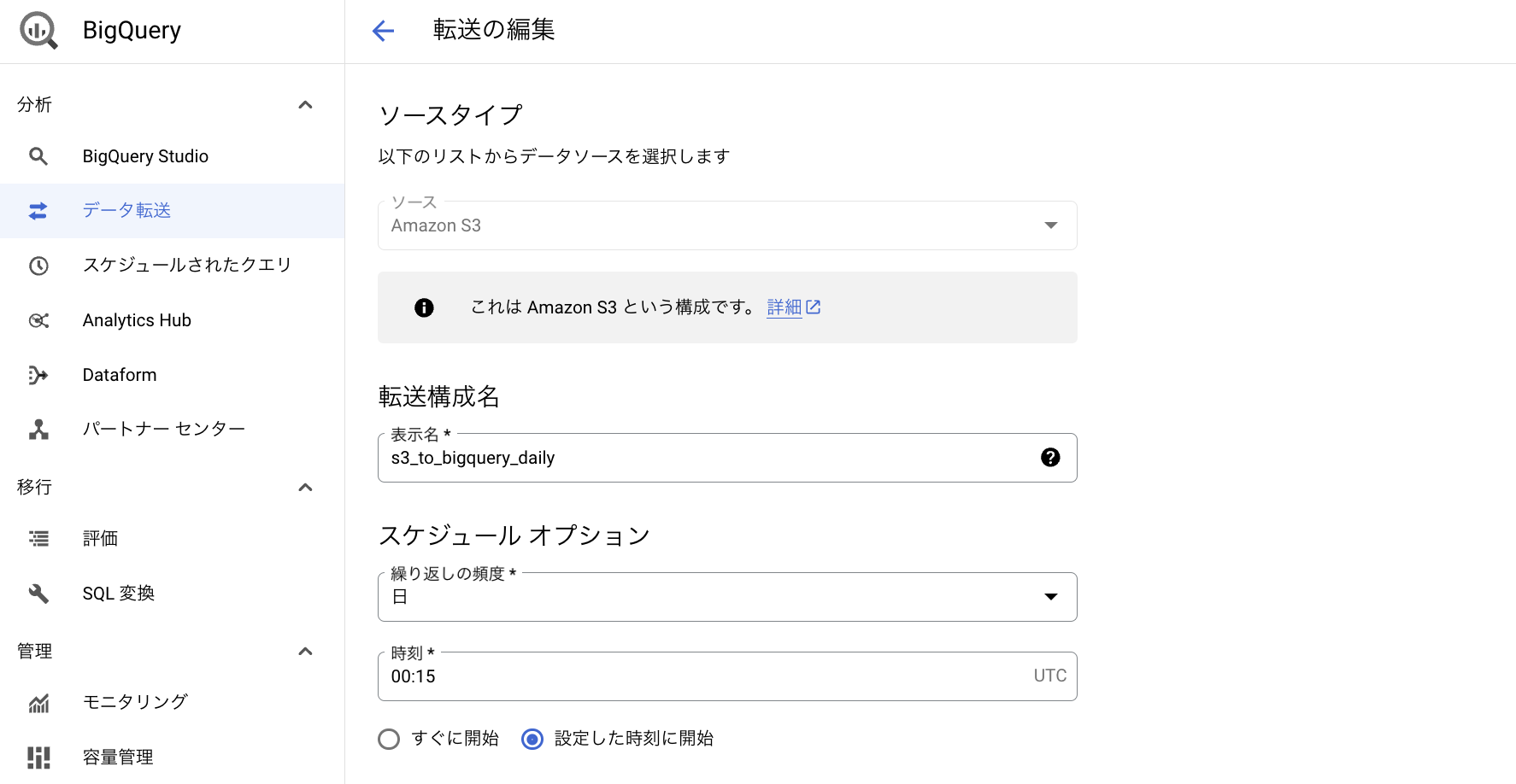
また、通知オプションのPub/Sub通知をONにします。
これで転送が成功したとき、Pub/Subトピックにメッセージがパブリッシュされ、Slack通知に活用することができます。

Slack通知の自動化
Cloud Functionsでnotify-update-summary-allを作成します。
BigQuery Data Transfer Serviceによるデータ転送の成功をPub/Subから受け取ったメッセージに基づいてSlackに通知します。
import os
import json
import requests
import base64
from flask import jsonify
def notify_update_summary_all(event, context):
# Slack Webhook URL
webhook_url = os.environ.get('SLACK_WEBHOOK_URL')
if 'data' in event:
message_data = base64.b64decode(event['data']).decode('utf-8')
message = json.loads(message_data)
else:
message = {'message': 'No data found in Pub/Sub message'}
slack_message = {
"text": f"BigQueryへのサマリデータ転送が完了したよ!: {message.get('message')}"
}
response = requests.post(webhook_url, json=slack_message)
print(response.text)
return jsonify(success=True), 200
functions-framework==3.*
requests
この関数をデプロイする際、Pub/Subトピックをイベントトリガーとして指定し、ランタイム環境変数にはSlackのWebhook URLを設定します。
これにより、関数は指定されたトピックにメッセージが公開されるたびに実行され、指定したSlackチャンネルに通知が送信されます。
