最近チャットボットにRAG(Bedrock Knowledge Base)を導入しようとしているのですが、そもそもどうやってLLMモデルを選んだらよいかわかっていませんでした。
調べてみたらさまざまなリーダーボード(Leaderboard)が乱立していて迷子になったので、自分の理解を整理する意味も含めてまとめてみました。
他のエンジニアの方の参考になればうれしいです。
1. オープンソースモデル向けリーダーボード
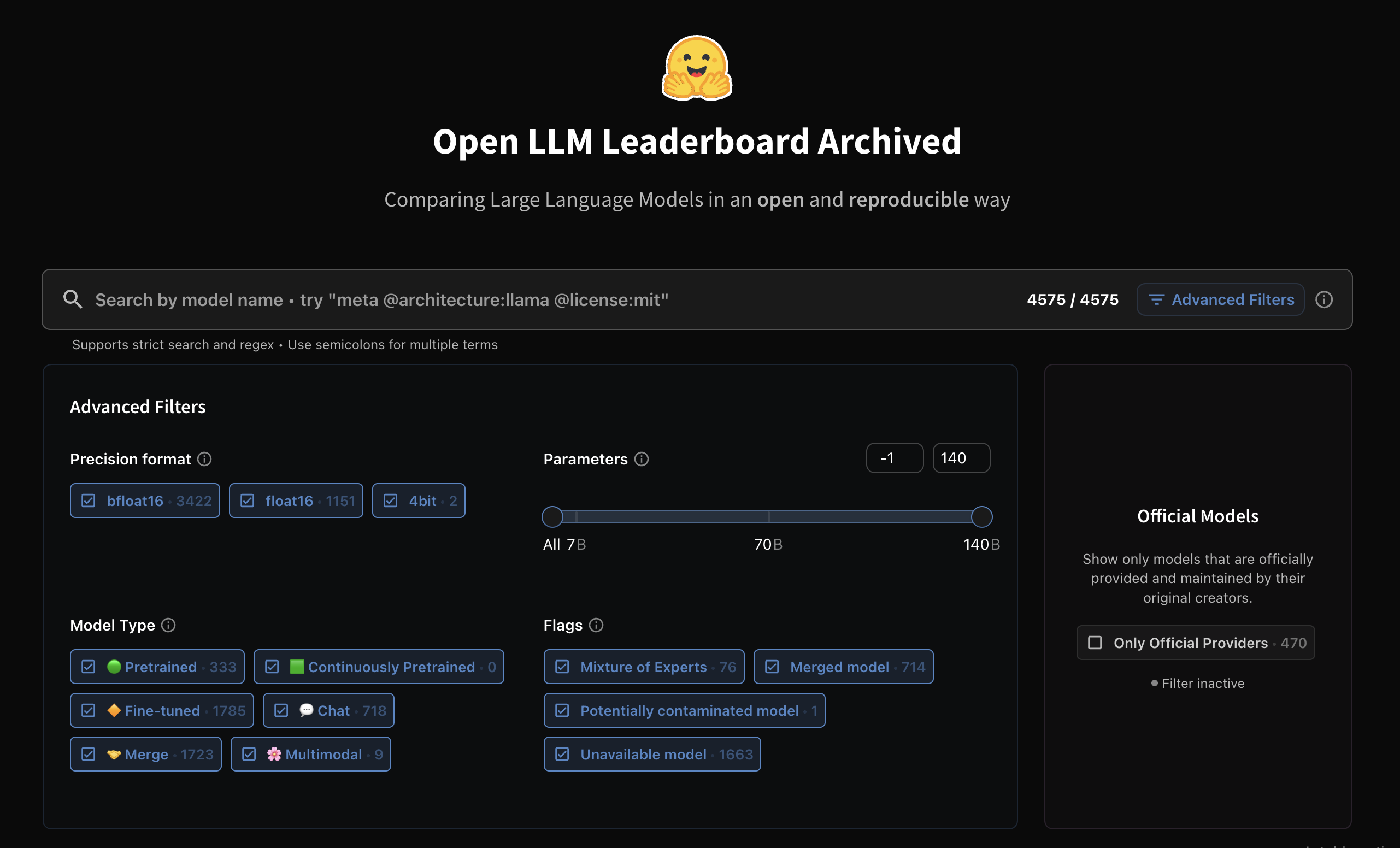
Open LLM Leaderboard
オープンソースモデル比較で一番有名なリーダーボードです。
公式プロバイダーが提供しているかどうか、エッジデバイス向けの軽量モデルかどうか、などでフィルターがかけられるので検索が楽です。
以下が主なベンチマークです。
- IFEval: 指示に従う能力を評価
- BBH(Big Bench Hard): 将来的な能力を測る難しめのベンチマーク
- MATH: 数学問題解決能力
- GPQA: Google Proof Q&A(論理的推論力のテスト)
- MUSR: 探偵小説を使った推論能力テスト
- MMLU-PRO: 言語理解能力の測定
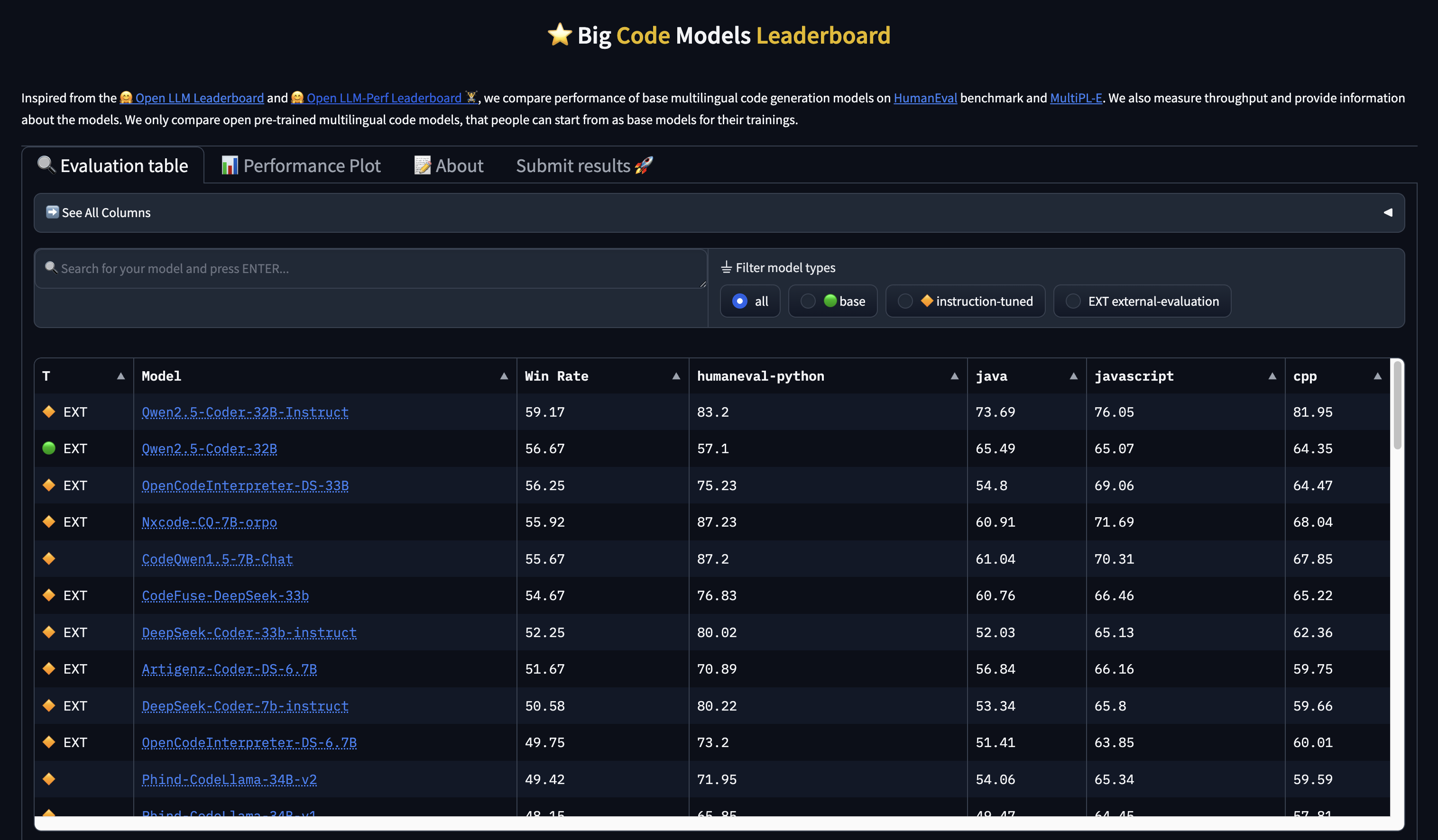
Big Code Models Leaderboard
コード生成に特化したリーダーボードです。
Python、Java、JavaScript、C++など、言語別の性能評価があるので、ターゲット言語に強いモデルを選べます。勝率(Win Rate)でモデルの総合的な評価もわかるので、コーディングアシスタントを作るなどの目的があったらチェックするとよさそうです。
LLM-Perf Leaderboard
実運用を考えると精度だけでなく速度やメモリ使用量も大事だと思うのですが、このリーダーボードはそういった現実的な指標を重視しています。
「Find Your Best Model」タブが特に便利で、手元のGPUスペックに合わせてタブを選べば(添付画像はA10-24GB-150W)、最適なモデルがすぐわかります。
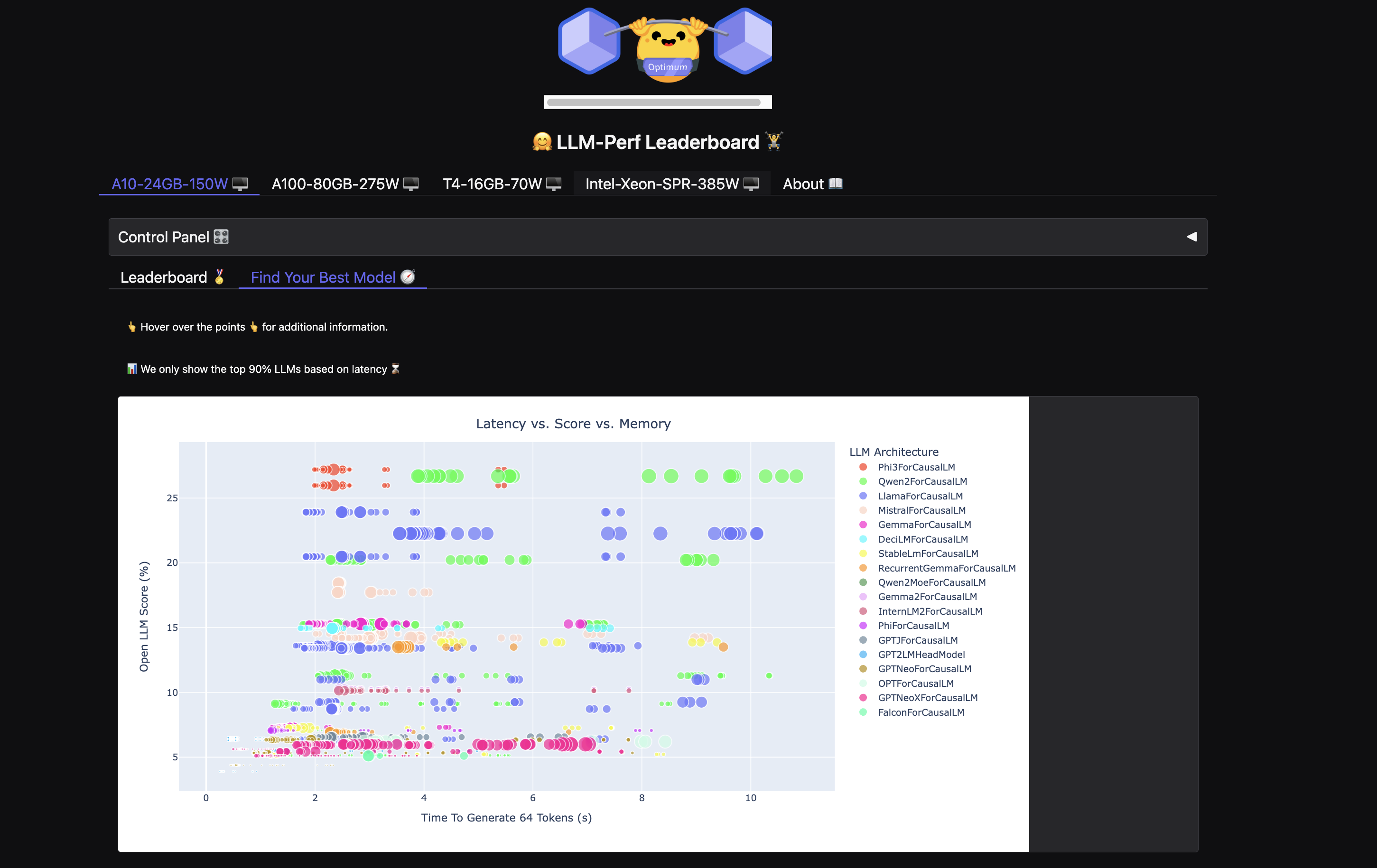
このチャートは非常に便利で、左上にあるほど速度と精度のバランスが良いモデルということになります。また、バブルのサイズが小さいほどメモリ使用量が少ないことを示しています。例えば、AWS環境でg5.xlargeインスタンス(24GB VRAM)での運用を想定しているなら、このチャートで適切なモデルを一目で判断できます。
2. 専門分野別リーダーボード
Hugging Faceにはさまざまな専門分野に特化したリーダーボードもあります。自分のプロジェクトが特定分野なら、これらをチェックすべきです。
Open Medical-LLM Leaderboard
医療分野向けのモデル評価リーダーボードです。臨床知識や医療遺伝学などの専門知識をテストしています。医療系アプリを開発するなら必見です。
言語別リーダーボード
日本語などの特定言語を扱うプロジェクトなら、言語別のリーダーボードも役に立ちます。
3. クローズドソースとオープンソースを比較するリーダーボード
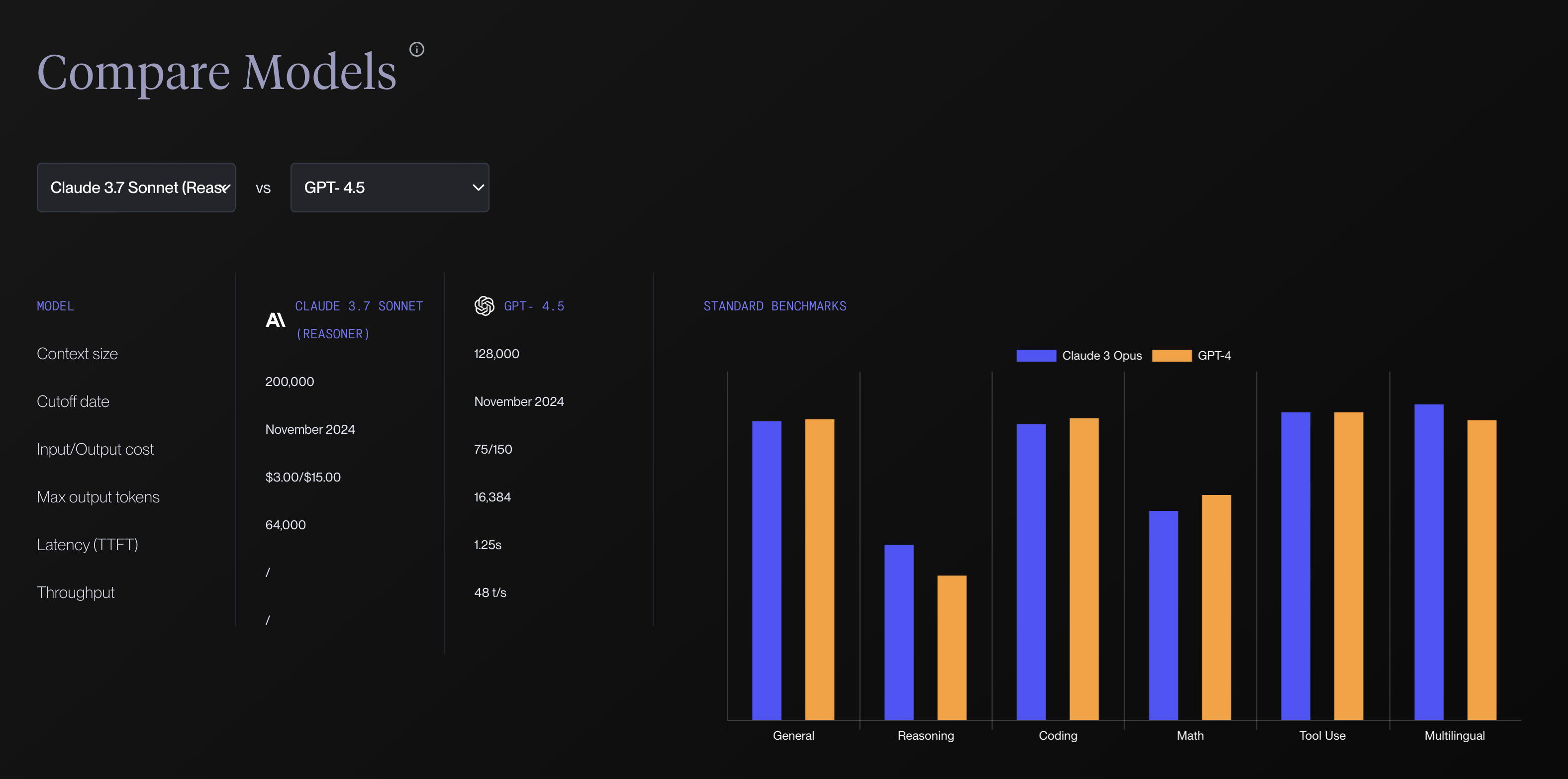
Vellum Leaderboard
GPTやClaudeなどのクローズドソースモデルとLlamaなどのオープンソースモデルを直接比較できます。
モデルの生成速度、レイテンシーなどの情報があるのはもちろんなのですが、コンテキストウィンドウサイズとトークン単価の情報もあるのが非常に便利です。
また、2つのモデルを直接比較する機能があるので、最新モデルがでてきたときに旧世代モデルとの比較にすごく便利です。
APIサービスとして利用するか自社でホスティングするか迷っているなら、このリーダーボードのコスト情報が参考になります。
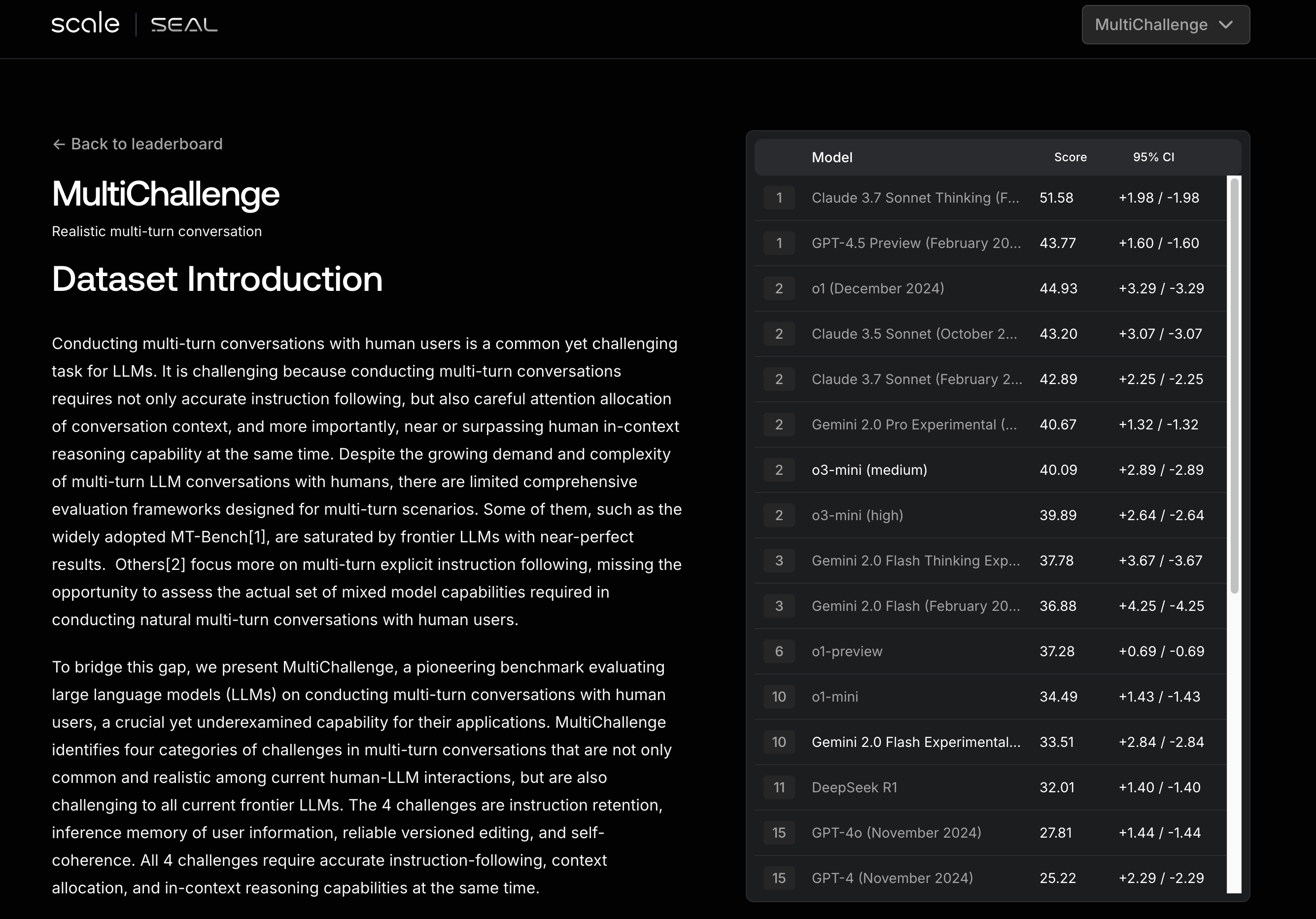
SEAL Leaderboard
より細かい専門スキルごとにモデルを評価している点が特徴的なリーダーボードです。一般的なベンチマークだけでなく、実務に直結する具体的な能力を測定しています。
例えば、人間との自然な会話能力や複雑な指示への対応力を総合的に評価するベンチマークとして「MultiChallenge」があります。
「会話の一貫性」や「説明の明瞭さ」や「情報統合能力」といった評価項目も含まれているので、自分がつくったチャットボット用のモデルさでは「MultiChallenge」が重要な選定基準となりました。
LMS Chatbot Arena
これは他のリーダーボードと全く異なるアプローチで、機械的なベンチマークではなく、実際の人間の判断でモデルを評価しています。
統計データにない人間の好みの部分もあるので、このリーダーボードは実際のユーザー体験を予測するのに役立ちます。
余談
さまざまなリーダーボードでモデルを比較検討したものの、実際のプロジェクト制約に直面することも多いですよね..
私の場合、Bedrock Knowledge BaseをTokyoリージョンで構築する必要があったのですが、使えるオンデマンドモデルがClaude 3.5 SonnetかClaude 3 Haikuくらいしかなく(3.5 Haikuが使えないという..)、しかも Tokyoリージョンではカスタムモデルインポートにも対応していないことが判明しました。
結局、現実的な選択としてClaude 3.5 Sonnetで検証をスタートしました。機能面では十分満足できるレベルで、特にクエリ分解やFMPやチャンギングによる最適化で返答精度は大幅に向上しました。
ただ、クエリ分解でレイテンシが大きくなってしまったので(レスポンスまでに10秒強)、その対策をどうしようかを現在検討中です。
それこそ、Bedrockのみバージニアリージョンで利用して、クロスリージョンによる通信のオーバーヘッドも受け入れつつ、3.5 Haikuなどのモデルを使うか、Llamaなどのオープンソースモデルをカスタムモデルインポートで使おうか、などと考えています。