マストドン構築時に『🐘PGTune』という、良い感じに PostgreSQL の設定値を算出してくれるジェネレーターを使ってみましたが
「それぞれの設定が具体的に何なのか知りたいなぁ」
と思って調べたので、その備忘録です。
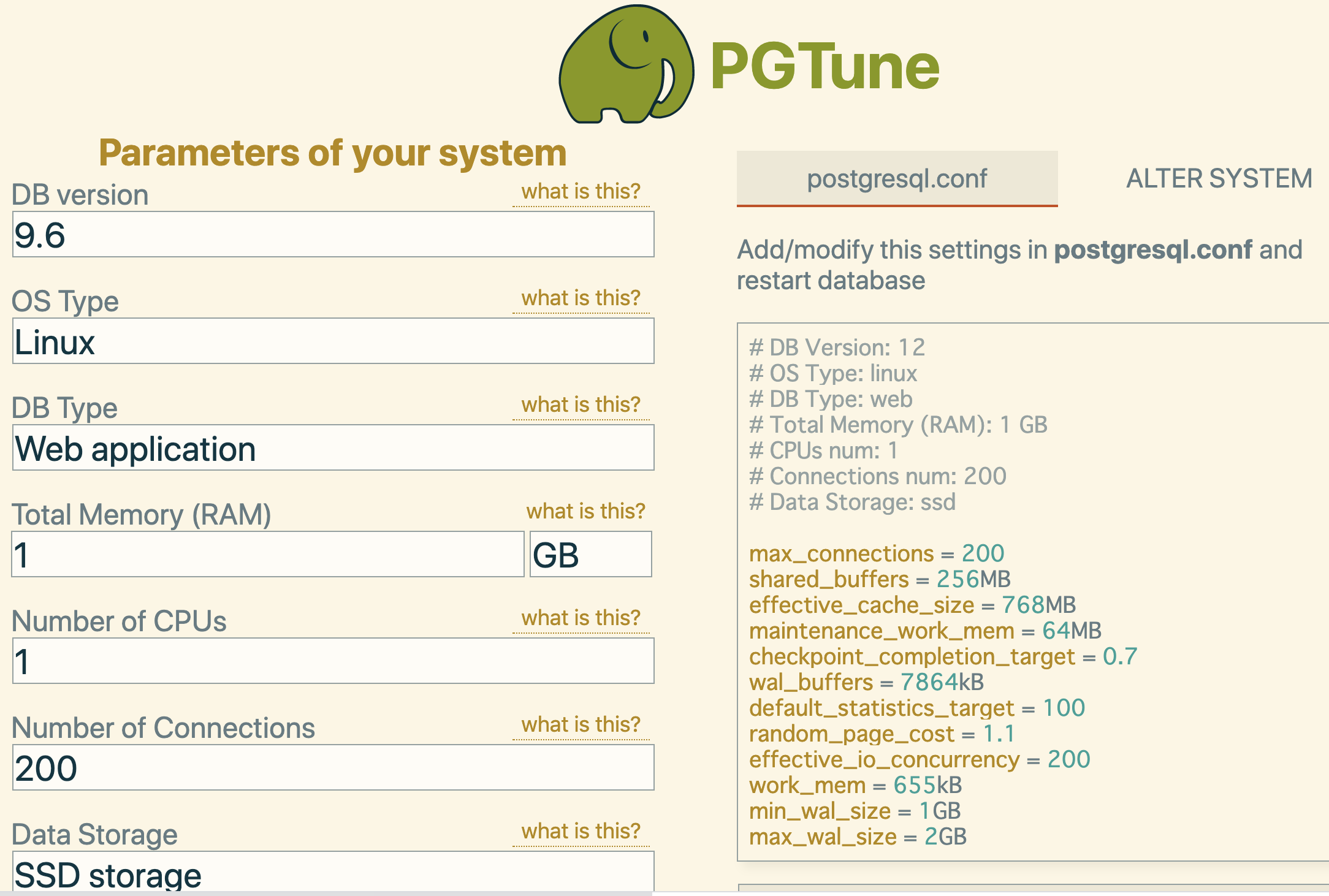
max_connections = 200
DBに同時接続する最大数を設定します。 デフォルトは100接続です。
(この値はサーバ起動時のみに設定可能)
shared_buffers = 256MB
DBが**共有メモリバッファ** (※後述)のために使用するメモリ量を設定します。 デフォルトは128MBです。
また、この設定の最低値は128KBです。より性能を引き出すためには、最小値よりかなり高い値の設定が必要です(※理由は後述します)。
(この値はサーバ起動時にのみ設定可能)
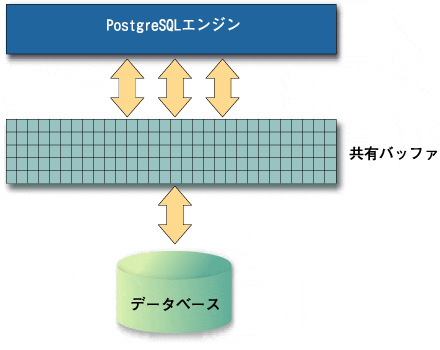
※共有バッファとは
『データベースにアクセスする際のバッファ』
PostgreSQLエンジンがデータベースにアクセスする場合、まずハードディスク上の必要なデータを共有バッファ上に読み込みます。そして共有バッファ上のデータを読み書きすることで処理を行います。
その後また同じデータにアクセスする必要が生じた場合には、ハードディスクにアクセスするのではなく、すでに共有バッファ上に読み込まれているデータに対してアクセスします。
こうすることで、遅いハードディスクへのアクセスを減らして処理性能を稼いでいます。
(画像は以下を参照)
https://thinkit.co.jp/cert/tech/10/1/3.htm
ただ共有バッファはサーバマシンのメモリ上に確保されるため大きさに限界があり、より頻繁にアクセスされるデータを優先的に共有バッファに読み込み、処理を行います。
※shared_buffersの初期値 ~128KBだと小さすぎる~
1GB以上のRAMを載せた専用データベースサーバを使用している場合、shared_buffersに対する妥当な初期値はシステムメモリの25%です。1GB未満のRAMのシステムでは、OSに十分な余裕を残すためにより小さい割合を設定します。
例:メモリ1GBの場合は256MBなど
PostgreSQLはOSキャッシュにも依存するため、shared_buffersにRAMの40%以上を割り当てても、あまり意味がありません。
新規or変更された多量のデータの処理を、時間をかけて書き出すことで分散させるため、shared_buffersをより大きく設定する場合は、max_wal_sizeも増やす必要があります。
effective_cache_size = 768MB
effective: 効果的な
ひとつの問い合わせで利用できるディスクキャッシュの容量に関する**プランナ** (※後述) 条件の設定です。 インデックスを使用する推定値です。
高く設定すれば、インデックススキャンが使用されるようになり、小さく設定すれば、シーケンシャルスキャン(箱が空になるまで順番に1つずつ取り出して確認するやり方)が使用されるようになります。
PostgreSQLの共有バッファとデータファイルに使用されるディスクキャッシュ量の両方を考慮して値を設定します。 それぞれのテーブルに対して同時実行される問い合わせの総定数も考慮します。(利用可能な領域を共有するため)
この値は推定目的のみで使用されます。デフォルトは128MBです。
※プランナとは
『最適な実行計画を作るロジック』
絞り込む順序やテーブルを結合する場合の結合の順序などを合わせて「実行計画(アクセスパス)」といいます。このアクセスパスを決定するプログラムロジックを「プランナ(オプティマイザ)」と呼びます。
SQL のチューニングは、いかにプランナに効率的な実行計画を選択させるかがポイントになります。
maintenance_work_mem = 64MB
VACUUM (※後述)、CREATE INDEX (※後述)、および**ALTER TABLE ADD FOREIGN KEY** (※後述)の様な保守操作で使用されるメモリの最大容量を指定します。 デフォルト値は64MBです。 1つのDBセッションでは、一度に1つしか上記の操作はできません。また、通常は設定などでこうした操作が同時多発的に発生することはあまりなく、この値をwork_memよりも大きな値にしても大丈夫です。 大きい値を設定することでvacuum処理と、ダンプしたデータベースのリストア性能が向上します。
ただ、最大でこのメモリのautovacuum_max_workers倍が配分されるので、デフォルトの値をあまり高く設定しないよう注意します。(別の設定項目autovacuum_work_memで制御するのが良いかもしれないです)
※VACUUMとは
『データベースの不要領域の回収とデータベースの解析などを行う』
VACUUM は、不要タプルが使用する領域を回収します。 削除されたタプルや更新によって不要となったタプルはテーブルから物理的に削除されず、VACUUMが完了するまで存在し続けるため、特に更新頻度が多いテーブルではVACUUMを定期的に実行する必要があります。
※CREATE INDEXとは
『新しいインデックスを定義する』
指定したリレーションの指定した列(複数可)に対するインデックスを作ります。
※ALTER TABLE ADD FOREIGN KEYとは
『外部キー制約を追加する』
指定した表に新しく外部キー制約を追加するときに使用します。
外部キー制約とは?
親テーブルと子テーブルの2つのテーブル間でデータの整合性を保つために設定される制約。具体的には子テーブルにデータを追加するとき、 FOREIGN KEY 制約が設定されたカラムには、親テーブルのカラムに格納されている値しか格納することができなくなります。
checkpoint_completion_target = 0.7
チェックポイント (※後述)の、完了目標をチェックポイント間の総時間の割合として指定します。
このパラメータのデフォルト値は0.5で、これによって次のチェックポイントまでの時間の約半分、すなわちデフォルトではチェックポイント開始から2分30秒の間にチェックポイント処理を完了するよう、チェックポイントの負荷を分散します。
さらに負荷を分散させたい場合は、1.0までの範囲でcheckpoint_completion_targetを大きくすることができますが、0.9程度にとどめておくことが推奨されています。逆にチェックポイントの負荷をもっと大きくしてもよいのであれば、0.5よりも小さくできます。
※checkpoint_completion_targetを必要以上に大きくすると、クラッシュリカバリ時に処理するWALログファイルが増えるので、時間がかかるというデメリットがあります。
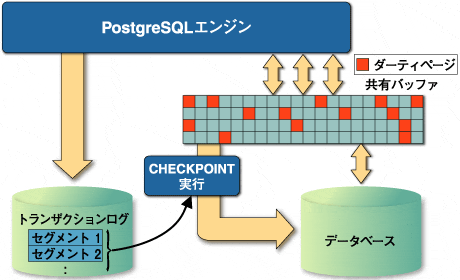
※チェックポイントとは
『WAL(Write Ahead Logging)の内容をテーブルファイルに反映するポイント』
PostgreSQLでは共有バッファをディスクキャッシュとして使っています。共有バッファは「ページ」という8kBの単位で管理されています。データの更新はすぐにハードディスクに書き込まれず共有バッファ上で行われ、代わりにトランザクションログ(WAL)をハードディスクに書き込みます。トランザクションログを削除するタイミングがチェックポイントです。障害時に備えて、トランザクションログは随時ハードディスクに書き込まれています。未書き込みのデータがなくなったところで、トランザクションログは削除されます。
(画像は以下を参照)
https://thinkit.co.jp/free/tech/10/5/1.html
チェックポイントの実行タイミング
- トランザクションログが一定量に達した場合
- 設定されたチェックポイントの実行時間になったら
wal_buffers = 7864kB
これはトランザクションログ(WAL)ファイルをディスクに書き出す時にバッファリングされる共有メモリ領域です。
デフォルトでは-1となっており、shared_buffersの1/32(約3%)の値をとります。自動設定による選択が大きすぎたり、小さすぎる場合この値は手作業で設定できます。 しかし、32kB未満のどんな正の値であっても、32kB として取り扱われます。 ※このパラメータはサーバ起動時のみ設定可能です。
WALバッファの内容はトランザクションのコミット毎にディスクに書き込まれます。
default_statistics_target = 100
ALTER TABLE SET STATISTICS (※後述)でテーブル列に対し、デフォルトの統計対象を設定します。小さな値は適切な実行計画が作成されず、より大きい値はANALYZEが長時間に及ぶ(ロングトランザクション)のリスクが高まりますが、プランナの予測精度が高まります。 デフォルトは100です。
※ALTER TABLE SET STATISTICSとは
『以後のANALYZE(DBの解析)操作において、列単位での統計情報収集対象を設定します』
対象として、0から10000までの範囲の値を設定可能です。 また、対象を-1に設定すると、システムのデフォルト統計情報対象(default_statistics_target)が使用されます。
random_page_cost = 1.1
random_page_costには、テーブルの1ページ(8kB固定長の領域)のアクセスにかかる時間を基準として、インデックスから目的の1ページをアクセスするのにかかる時間を設定します。
デフォルトでは4(インデックスへのアクセスには4倍時間かかる)という設定になっています。
メモリを1〜2Gバイト搭載したマシンでは、テーブルが1000万件以上あるようなケースを除くと、デフォルトの4という数字は大きすぎるようです。
random_page_costの値を小さく設定すると、オプティマイザがインデックスを使用した問い合わせを選択する傾向が強くなります。
effective_io_concurrency = 200
PostgreSQLが同時実行可能であると想定する同時ディスクI/O操作の数を設定します。
ビットマップヒープスキャン (※後述)時に、ストレージからのデータ読み込みIOを、データの処理と並行させることでパフォーマンス向上を狙うもので、ビットマップヒープスキャン専用の設定です。
effective_io_concurrencyを1以上に設定することで有効となり、最大は1000です。設定値を上げるほどより多くのデータを非同期で読み込むようになります。
0に設定することで非同期IOを無効化することができます。
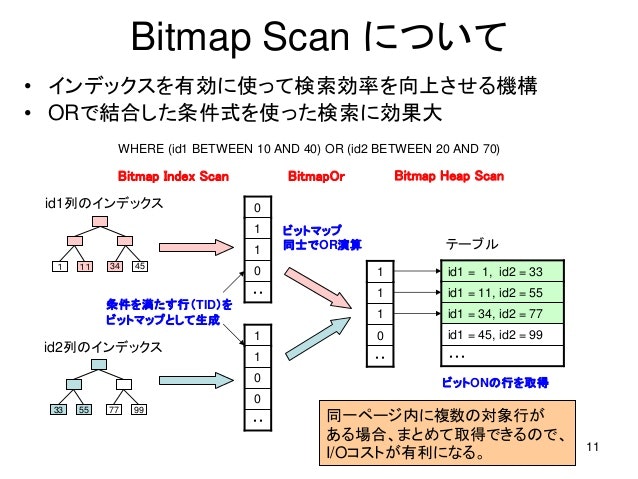
※ビットマップヒープスキャンとは
下記の図のように段階を踏んでソートします。インデックスを使用して条件に合う行の場所を検索した後、テーブルから対象の行を取り出します。
(画像は下記から参照)
https://www.slideshare.net/naka24nori/explain20
work_mem = 655kB
PostgreSQLの各プロセスが使用するソート用のメモリバッファです。
作業メモリの「work_mem」を大きくすると、ソートやハッシュをメモリ上で行えるため、基本的には性能が向上しますが、複雑な問い合わせの場合には、ソートやハッシュが問い合わせの中で複数回実行されることがあります。
瞬間最大でメモリを 「work_mem」×「max_connection」+α 分だけ消費するため、ピークを想定した設定を行います。
min_wal_size = 1GB
min_wal_sizeは、pg_xlog配下に保持するWALファイルの合計サイズの下限を制御するパラメータです。デフォルト値は80MB(WALファイル5個分)に設定されています。また、WALファイルを再利用/削除する際の計算式にも使われています。
max_wal_size = 2GB
max_wal_sizeは、チェックポイントの間隔とpg_xlog配下に保持するWALファイルの合計サイズの上限を制御するパラメータです。指定したサイズ分の変更履歴がWALファイルに書かれた時にチェックポイントが行われます。デフォルト値は1GB(WALファイル64個分)に設定されています。その他、WALファイルを再利用/削除する際の計算式にも使われています。
感想
PGTuneで出た値は、あくまで自動算出された設定値なので
実稼働するなかで、DBの具合を見つつ実情に合わせた設定値に調節する必要があるということが分かりました。
設定値の意味を調べることで、今後チューニングしてパフォーマンスを向上させていきたいという気持ちになったので
ベンチマーク試験をしてみたり、ログの監視を入れてみたりなどして積極的にDBと関わっていきたいと感じました。