概要
画像位置合わせについて日本語記事がほとんど無い(2020/1/22 現在)ため、とても分かりやすいと思った Image Registration: From SIFT to Deep Learning という記事を翻訳というかまとめました。省略したり加筆した箇所もあるので、原典にあたりたい方は元記事の方を読んでください。
画像位置合わせ(image registration)とは?

画像位置合わせとは、2枚の画像の位置ずれを補正する処理のことです。画像位置合わせは、同じシーンの複数の画像を比較する時などに用います。例えば、衛星画像解析やオプティカルフロー、医用画像の分野でよく登場します。
具体例を見てみましょう。上の画像は私が新大久保で食べたマスカットボンボンの画像を位置合わせしたものです。とても美味しかったですが、甘党でない方にはおすすめしません。
この例では、左から2番目のマスカットボンボンの位置を、明るさなどはそのままに、左端のマスカットボンボンの位置に合わせているのがわかると思います。以下では、左端のような、変換されず参照される画像のことを参照画像、左から2番目のような、変換される画像を浮動画像とします。
本記事では、浮動画像と参照画像間で位置合わせを行なうためのいくつかの手法について述べます。なお、反復/信号強度に基づく方法はあまり一般的でないため、本記事では言及しません。
特徴に基づくアプローチ
2000年代初期から、画像位置合わせに特徴に基づくアプローチが用いられてきました。このアプローチは、キーポイントの検出と特徴の記述、特徴のマッチング、画像の変換の3つのステップから成ります。簡単に言うと、両方の画像で関心のある点を選択し、参照画像の各関心のある点を浮動画像の対応点に関連付け、両方の画像の位置が合うように浮動画像を変換します。
キーポイントの検出と特徴の記述
キーポイントは画像において重要かつ特徴的なもの(角やエッジなど)を定義します。各キーポイントは、記述子で表されます。記述子は、キーポイントの本質的な特徴を含む特徴ベクトルです。記述子は、画像変換(ローカリゼーションやスケール、輝度など)に対して頑健でなければいけません。キーポイントの検出と特徴の記述を行なうアルゴリズムは多数存在します。
- SIFT (Scale-invariant feature transform) は、キーポイントの検出に使用される元のアルゴリズムですが、商用利用には有料です。SIFT特徴記述子は、均一なスケーリング、方向、輝度の変換に対して不変であり、アフィン歪に対して部分的に不変です。
- SURF (Speeded Up Robust Features) は、SIFTに影響を受けた検出器および記述子です。SIFTに比べ数倍高速です。また、特許も取得しています。
- ORB FAST Brief (Oriented FAST and Rotated BRIEF) は、FASTキーポイント検出器とBrief記述子の組み合わせに基づく高速バイナリ記述子です。回転に対して不変であり、ノイズに対して頑健です。OpenCV Labsで開発され、SIFTに代わる効率的で無料の代替手段です。
- AKAZE (Accelerated-KAZE) は、KAZEのスピードアップバージョンです。非線形スケール空間の高速マルチスケール特徴検出および記述アプローチを提供します。スケールと回転の両方に対して不変であり、無料です。
これらのアルゴリズムはOpenCVで簡単に使用できます。以下の例では、AKAZEのOpenCV実装を使用しました。アルゴリズムの名前を変更するだけで他のアルゴリズムを使用できます。
import cv2 as cv
# キーポイントなどを見やすくするためにグレースケールで画像読み込み
img = cv.imread('img/float.jpg')
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# キーポイントの検出と特徴の記述
akaze = cv.AKAZE_create()
kp, descriptor = akaze.detectAndCompute(gray, None)
keypoints_img = cv.drawKeypoints(gray, kp, img)
cv.imwrite('keypoints.jpg', keypoints_img)

特徴検出と記述子の詳細については、OpenCVのチュートリアルをご覧ください。
特徴のマッチング
両方の画像でキーポイントを求めた後、対応するキーポイントを関連付けるか、「マッチング」する必要があります。そのためのメソッドの一つは、BFMatcher.knnMatch()です。これは、キーポイント記述子の各ペア間の距離を測定し、各キーポイントに対して、距離が近いものからk個のキーポイントをマッチングします。
次に、比率フィルターを適用して、正しいマッチングのみを保持します。信頼性の高いマッチングを実現するには、マッチングしたキーポイントが最も近い誤ったマッチングより大幅に近い必要があります。
import cv2 as cv
float_img = cv.imread('img/float.jpg', cv.IMREAD_GRAYSCALE)
ref_img = cv.imread('img/ref.jpg', cv.IMREAD_GRAYSCALE)
akaze = cv.AKAZE_create()
float_kp, float_des = akaze.detectAndCompute(float_img, None)
ref_kp, ref_des = akaze.detectAndCompute(ref_img, None)
# 特徴のマッチング
bf = cv.BFMatcher()
matches = bf.knnMatch(float_des, ref_des, k=2)
# 正しいマッチングのみ保持
good_matches = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good_matches.append([m])
matches_img = cv.drawMatchesKnn(
float_img,
float_kp,
ref_img,
ref_kp,
good_matches,
None,
flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv.imwrite('matches.jpg', matches_img)

OpenCVに実装されている他の特徴マッチング方法については、ドキュメントをご覧ください。
画像の変換
少なくとも4組のキーポイントをマッチングした後、1つの画像を他の画像に相対的に変換します。これは、image warpingと呼ばれます。空間内の同じ平面上にある2つの画像は、ホモグラフィによって関連付けられます。ホモグラフィは、8つの自由なパラメータを持ち、3x3行列で表される幾何学的変換です。それらは、(局所的な変換とは対照的に、)画像全体に加えられた歪みを表します。したがって、変換された浮動画像を得るには、ホモグラフィ行列を計算し、それを浮動画像に適用します。
最適な変換を保証するために、RANSACアルゴリズムを用いて外れ値を検出し、それらを削除して最終的なホモグラフィを決定します。OpenCVのfindHomographyメソッドに直接組み込まれています。RANSACの代替としてLMEDS:最小メジアン法といったロバスト推定の手段もあります。
import numpy as np
import cv2 as cv
float_img = cv.imread('img/float.jpg', cv.IMREAD_GRAYSCALE)
ref_img = cv.imread('img/ref.jpg', cv.IMREAD_GRAYSCALE)
akaze = cv.AKAZE_create()
float_kp, float_des = akaze.detectAndCompute(float_img, None)
ref_kp, ref_des = akaze.detectAndCompute(ref_img, None)
bf = cv.BFMatcher()
matches = bf.knnMatch(float_des, ref_des, k=2)
good_matches = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good_matches.append([m])
# 適切なキーポイントを選択
ref_matched_kpts = np.float32(
[float_kp[m[0].queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
sensed_matched_kpts = np.float32(
[ref_kp[m[0].trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
# ホモグラフィを計算
H, status = cv.findHomography(
ref_matched_kpts, sensed_matched_kpts, cv.RANSAC, 5.0)
# 画像を変換
warped_image = cv.warpPerspective(
float_img, H, (float_img.shape[1], float_img.shape[0]))
cv.imwrite('warped.jpg', warped_image)

これらの3つのステップの詳細に関心がある場合、OpenCVは一連の便利なチュートリアルをまとめています。
深層学習アプローチ
最近の画像位置合わせのほとんどの研究は、深層学習の使用に関するものです。過去数年間で、深層学習により、分類、検出、セグメンテーションなどのコンピュータビジョンタスクの最先端のパフォーマンスが可能になりました。画像位置合わせに関しても例外ではありません。
特徴抽出
最初に深層学習が画像位置合わせに使用されたのは、特徴抽出のためでした。畳み込みニューラルネットワーク(CNN)の連続層は、ますます複雑な画像特徴をとらえ、タスク固有の特徴を学習します。2014年以来、研究者はこれらのネットワークをSIFTまたは同様のアルゴリズムではなく、特徴抽出ステップに適用しています。
- 2014年、Dosovitskiyらは、教師なしデータのみを用いてCNNを学習することを提案しました。これらの特徴の汎用性により、変換に対して頑健になりました。これらの特徴または記述子は、SIFT記述子よりも優れていました。
- 2018年、Yangらは、同じ考えに基づいた非剛体位置合わせ方法を開発しました。彼らは事前に学習されたVGGネットワークの層を用いて、畳み込み情報とローカリゼーション特徴の両方を保持する特徴記述子を生成しました。これらの記述子は、特にSIFTに多くの外れ値が含まれているか、十分な数の特徴点とマッチングできない場合に、SIFTのような検出器よりも優れているようです。
後者の論文のコードはここにあります。この位置合わせ方法は15分以内に手元の画像で試せますが、前半で実装したSIFTのような方法よりも約70倍遅いです。
ホモグラフィ学習
研究者たちは、深層学習の使用を特徴抽出に限定せず、ニューラルネットワークを用いて幾何学的変換を直接学習し、位置合わせを実現しようとしました。
教師あり学習
2016年、DeToneらは、2つの画像に関連するホモグラフィを学習するVGGスタイルモデルである回帰ホモグラフィネットを説明する深層画像ホモグラフィ推定を公開しました。このアルゴリズムには、ホモグラフィとCNNモデルのパラメータをエンドツーエンドで同時に学習するという利点があります。特徴抽出とマッチングのプロセスは不要です。
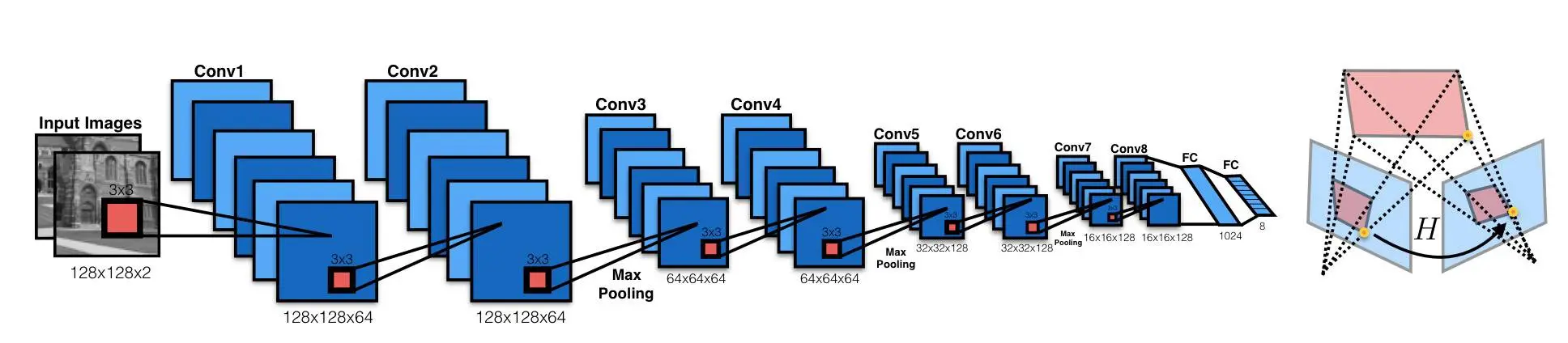
ネットワークは、出力として8つの実数値を生成します。出力とグランドトゥルースホモグラフィ間の損失によって教師あり学習を行います。
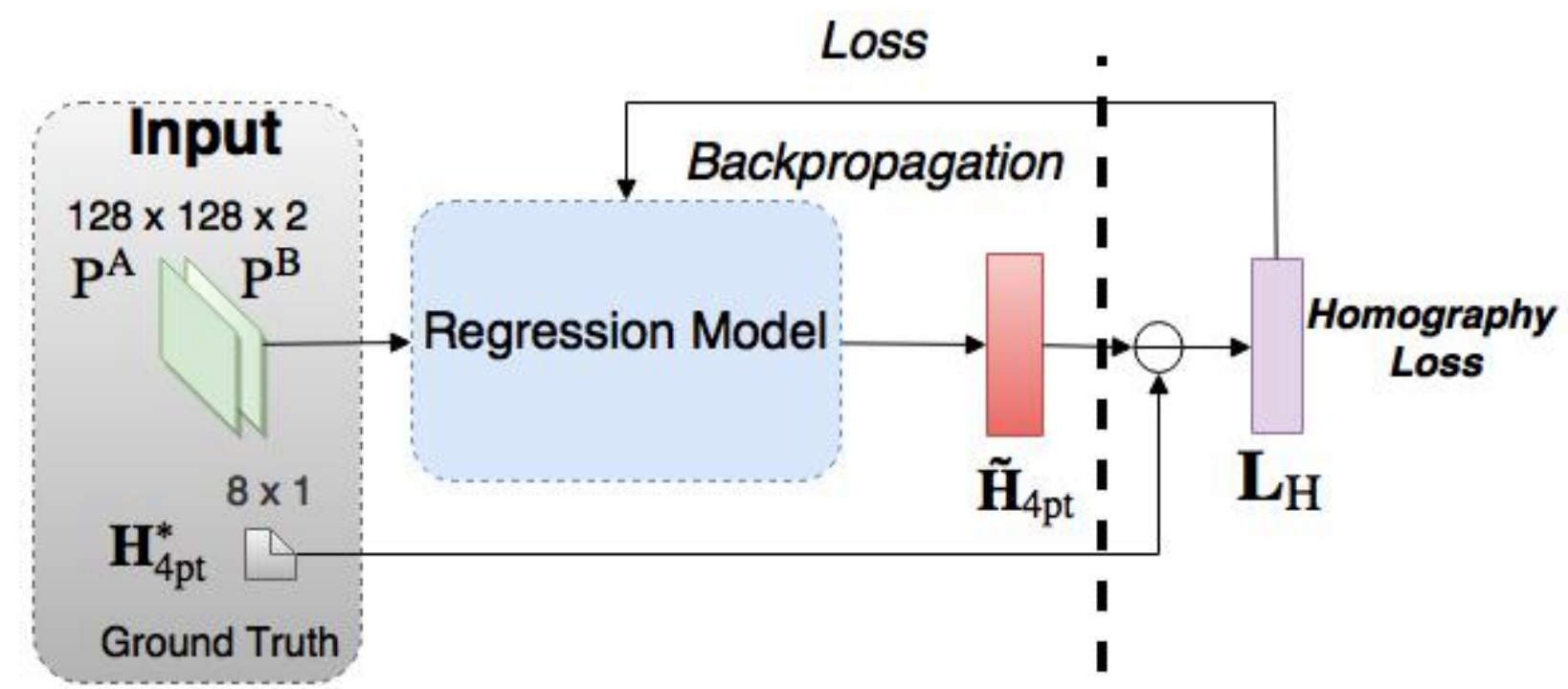
他の教師あり学習アプローチと同様に、このホモグラフィ推定法は教師データのペアが必要です。しかし、実際のデータでグランドトゥルースホモグラフィを得るのは簡単ではありません。
教師なし学習
Nguyenらは、深層画像ホモグラフィ推定への教師なし学習アプローチを提示しました。彼らは同じCNNを用いましたが、教師なしアプローチに適した損失関数を使用する必要がありました。そこで、グランドトゥルースラベルを必要としないフォトメトリック損失を選択しました。参照画像と変換した浮動画像の類似度を計算します。
$$
\mathbf{L}_{PW} = \frac{1}{|\mathbf{x} _i|}
\sum _{\mathbf{x} _i}|I^A(\mathscr{H}(\mathbf{x} _i))-I^B(\mathbf{x} _i)|
$$
彼らのアプローチは、Tensor Direct Linear TransformとSpatial Transformation Layerという2つの新しいネットワーク構造を導入しています。
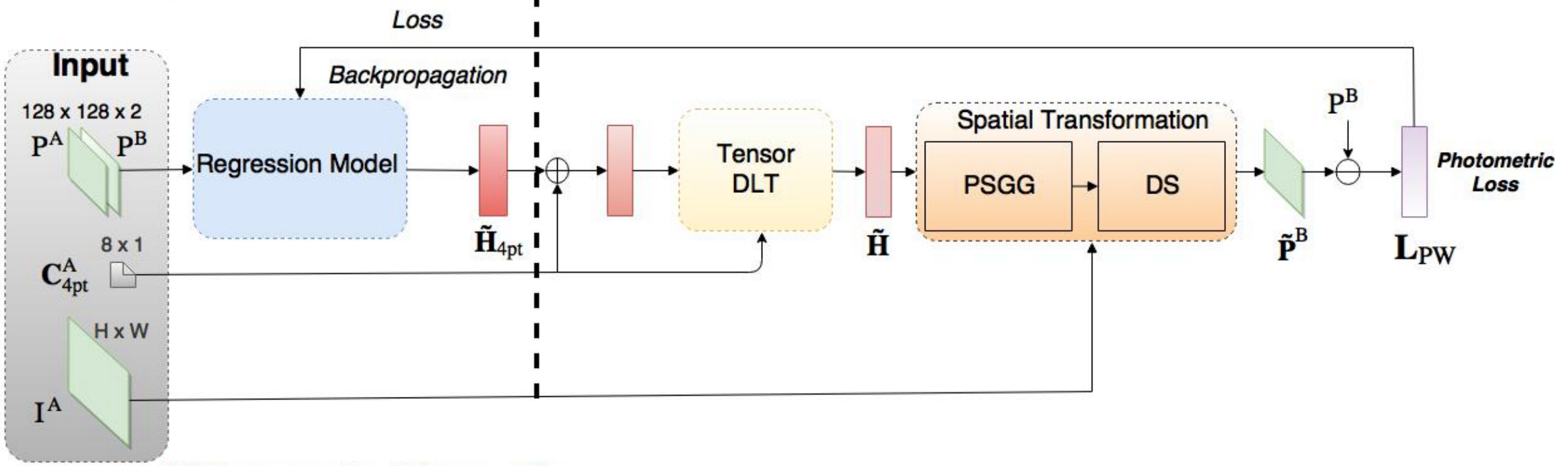
著者は、この教師なしの方法は、従来の特徴に基づく方法と比較して、より早い推論速度であり、同等以上の精度と照明変動に対して頑健性を持つと主張しています。さらに、教師あり手法と比較して、適応性とパフォーマンスに優れています。
その他のアプローチ
強化学習
深層強化学習は、医療アプリケーションの位置合わせ方法として注目されています。事前定義された最適化アルゴリズムとは対照的に、このアプローチでは、訓練されたエージェントを用いて位置合わせを実行します。
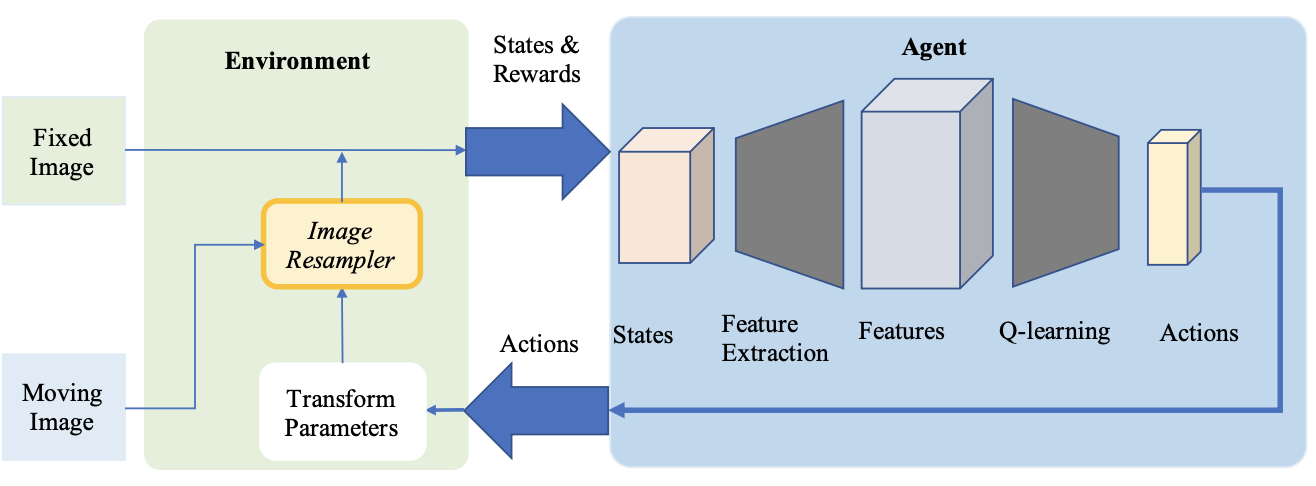
- 2016年、Liaoらは画像位置合わせに強化学習を最初に使用しました。彼らの方法は、エンドツーエンド学習のための貪欲な教師ありアルゴリズムに基づいています。その目標は、モーションアクションの最適なシーケンスを見つけることにより画像を位置合わせすることです。このアプローチはいくつかの最先端の方法より優れていましたが、剛体変換にのみ使用されました。
- 強化学習はより複雑な変換にも使用されています。Krebsらはエージェントに基づくアクション学習により頑健な非剛体位置合わせを行いました。変換モデルのパラメータを最適化するために人工エージェントを適用します。この方法は、前立腺MRIの被験者間位置合わせで評価され、2次元および3次元で有望な結果を示しました。
複雑な変換
かなりの割合の画像位置合わせにおける現在の研究が、医用画像の分野に関係しています。多くの場合、2つの医用画像間の変換は、被験者の局所的な変換(呼吸や解剖学的変化など)のために、ホモグラフィ行列によって単純に記述することはできません。変位ベクトル場で表現できる微分同相写像など、より複雑な変換モデルが必要です。

研究者は、ニューラルネットワークを用いて、多くのパラメータを持つこれらの大きな変換モデルを推定しようとしました。
- 最初の例は、上記のKrebsらの強化学習法です。
- 2017年、De VosらはDIRNetを提案しました。これは、CNNを用いてコントロールポイントのグリッドを予測するネットワークであり、このグリッドを用いて変位ベクトル場を生成し、参照画像に従って浮動画像をワープします。
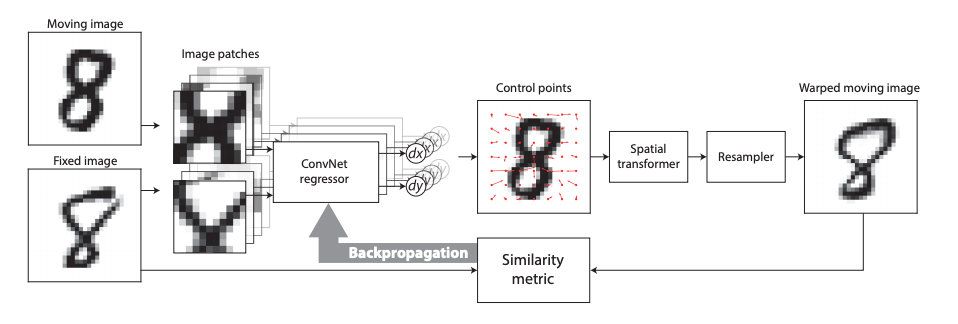
- Quicksilver位置合わせは、同様の問題に対処します。Quicksilverは、深層符号化復号化ネットワークを用いて、画像の外観でパッチごとの変換を直接予測します。
まとめ
画像位置合わせを行なうための手法をいくつか紹介してきました。特徴点を用いる手法から、深層学習で画像を直接変換する手法に変化しつつあることがわかりました。