AWS初心者ですが、最近担当した業務で、APIが出力しているログを
さくっと分析・調査したい場面があったのでCloudWatch Logs Insightsを使ってみました。
実際に調査で使ったクエリの例なども含めて、備忘録も兼ねてまとめます。
これからCloudWatch Logs Insightsを使う方にとって、少しでもお役に立てれば幸いです。
CloudWatch Logs Insightsとは?
CloudWatch Logsのログデータに対し、独自の構文を使って
クエリのようにデータを検索したり分析したりすることができる機能です。
従量課金制で、スキャンしたデータに応じて料金がかかります。
スキャンしたデータ 1 GB あたり 0.0076USD
使い方
準備
AWSマネジメントコンソール>CloudWatchを開き、サイドバーから「インサイト」を開きます。

基本的な操作
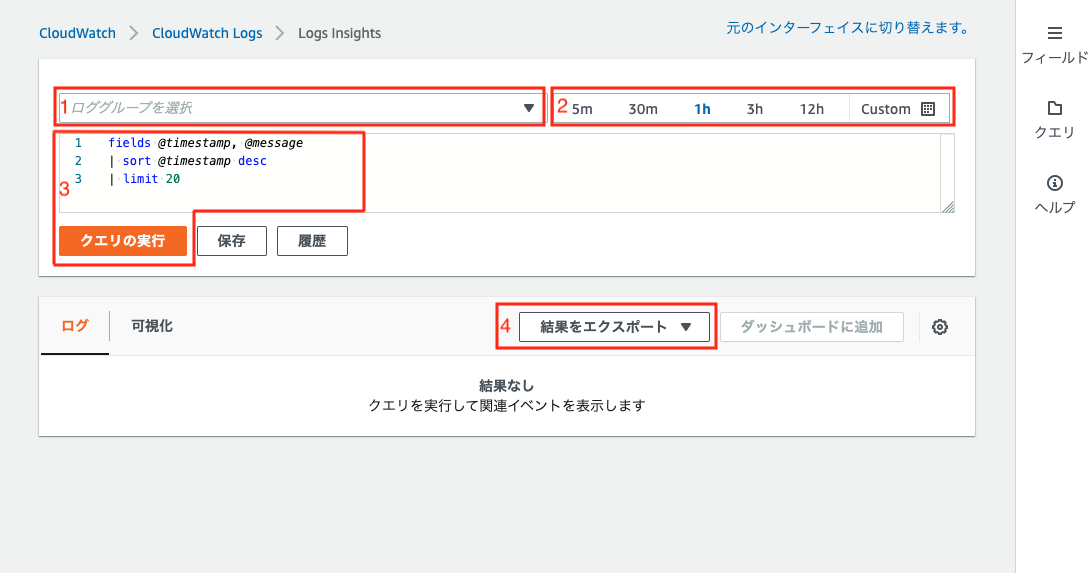
1.検索対象のロググループの選択
「ロググループを選択」から検索対象のロググループを選択します。
複数のロググループを一度に選択することも可能です。
2.検索対象期間の設定(任意)
検索対象期間が決まっている場合は指定しておきます。
(1時間以内、特定の日時など)
3.データを抽出する
テキストエリアにクエリを入力して、「クエリの実行」を押下するとクエリが実行されて結果が表示されます。
詳しいクエリの書き方や意味については「クエリ構文について」の章で解説します。
デフォルトで以下のクエリが入力されているので、
とりあえずどんな感じで抽出できるか見たい場合は、そのまま実行すれば抽出可能です。
fields @timestamp, @message
| sort @timestamp desc
| limit 20
4.必要に応じて結果をエクスポート(任意)
「結果をエクスポート」から以下の形式で抽出結果をエクスポートすることができます。
- クリップボードにコピー(マークダウン)
- クリップボードにコピー(csv)
- ダウンロード(csv)
クエリ構文について
独自のクエリコマンドが用意されていて、それらをパイプ(|)でつなげて使用することができます。
基本的なものと個人的に使ったコマンドについて解説します。
fields
取得するフィールドを指定するコマンドです。
SQLでいうとselect column1, column2のイメージです。
fields @timestamp, @message
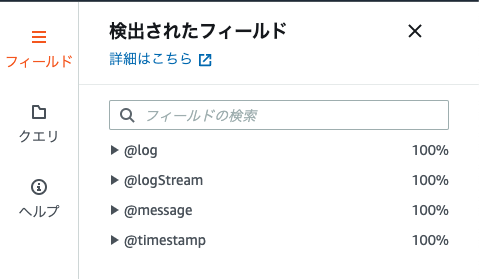
デフォルトで、以下のフィールドを指定できるようです。
@log
@logstream
@timestamp
@message
JSON形式のログだと、JSONのキーがそのままフィールドとして指定できます。
集計対象のログで使えるフィールドを知りたい場合は、
ロググループを指定して、画面右側のサイドメニュー「フィールド」を開くと
使用できるフィールドの一覧が表示されます。
filter
抽出条件を指定するコマンドです。
部分文字列一致で検索するには、likeを使用します。
SQLでいうと where column1 like '%error%' のイメージです。
filter @message like /error/
inを使用するとSQLと同じようにリストで比較することもできます。
filter status in[400, 500]
sort
ソート順を指定するコマンドです。
SQLでいうとorder byのイメージです。
sort @timestamp asc
asc/descが指定できます。
display
表示するフィールドを指定するコマンドです。
fieldsと似ていますが、displayは結果に表示するフィールドを指定する場合のみ使用します。
limit
取得するレコード数を指定するコマンドです。
SQLでいうとlimitのイメージです。
limit 20
stats
集計を行うためのコマンド。avg()、sum()、count()、min()、max()などが使用できます。
ここでは自分が使ったものをいくつか紹介してますが、
その他集計関数については、公式ドキュメントに詳しい解説があります。
| コマンド | 内容 |
|---|---|
| count() | ログイベント件数をカウントします。 |
| earliest(fieldName: LogField) | クエリを実行した結果のうち、最も早いタイムスタンプがあるものから、fieldNameの値を返します。 |
| latest(fieldName: LogField) | クエリを実行した結果のうち、最も遅いタイムスタンプがあるものから、fieldNameの値を返します。 |
parse
ログから、globや正規表現を用いて、
一時フィールドとしてデータを抜き出すことができます。
例えば、以下のように、リクエストIDが括弧で括られ、ログ内容がその後ろに出ているログで、
リクエストIDとログ内容を分けて処理したい場合。
(request-id-1) start.
(request-id-1) success.
(request-id-2) start.
PARSE @message "(*) *" as requestID, message
とすることで、以下のようにデータを抽出することが可能です。
| requestID | message |
|---|---|
| request-id-1 | start. |
| request-id-1 | success. |
| request-id-2 | start. |
使い方例
個人的に調査で使用したクエリを、一例ですが紹介します。
@messageに文字列「error」が含まれるログを、タイムスタンプの順に20件取得する
fields @timestamp, @message
| filter @message like /error/
| sort @timestamp
| limit 20
statusごとの件数を集計する
ログがJSON形式で出力されていて、「status」というキーにレスポンスのステータスを出力している前提で、
statusフィールドの値ごとに件数を集計します。
{
"requestId": "request-id-1",
"ip": "XXX.XXX.XX.XX",
"requestTime": "08/Apr/2020:04:00:59 +0000",
"httpMethod": "GET",
"resourcePath": "/api/hoge/",
"status": "200"
}
fields @timestamp, @message
| stats count(*) by status
リクエストIDごとに、処理にかかった時間を集計する
以下のような前提のログで、リクエストIDごとに処理時間を求めます。
- リクエストごとの処理時間をログ側で出力していない(出力していれば楽なのですが)
- リクエスト開始時と終了時にそれぞれログを出力している
- 以下のログ例のようにリクエストIDとログ内容を出力している
(request-id-1) start.
(request-id-1) success.
(request-id-2) start.
fields @timestamp, @message
| PARSE @message "(*) *" as requestID, message
| filter requestID in ["request-id-1", "request-id-2", "request-id-3"]
| stats earliest(@timestamp) as startTime, latest(@timestamp) as endTime by requestID
| display requestID, abs(endTime - startTime)
やっていることとしては以下の通りです。
1.parseで@messageからリクエストIDを抜き出す
2.リクエストIDごとに、最も早いログイベントのタイムスタンプ (=startTime)、最も遅いログイベントのタイムスタンプ(=endTime)を集計する
3.リクエストIDと、処理時間(endTime-startTime)を表示する
まとめ
簡単に使い始められて、便利な機能だと思いました。
クエリの結果をダッシュボードに追加したり、クエリを保存したりもできるようなので、
今後の調査や運用に活用していきたいです。
最後までお読みいただきありがとうございました!