BinaryConnect: Training Deep Neural Networks with binary weights during propagations
この論文は、二値化(binarization)によってNeural Networkの高速化と省メモリ化を図るというものです。
binarizationの対象は、weightのみです。
これにより乗算器の数が2/3になり、training time が3倍高速化され、memory量は1/16(weightに関してのみ)になっています。
この論文の著者は、BinaryNetの著者です。
著者による実装がここにあります。
今日のDeep Learningの成功の要因
・GPU
・large model
・big data
これらはすべて計算能力に関係するもので、今日では計算能力の限界がネットワーク構造やアプリケーションに影響を及ぼすこともある。
Low Power Deviceの分野ではDeep Network用のH/Wへの関心が高まっている。
Deep Networkの演算のほとんどはweightとactivationの乗算が占めている。
この論文ではこのweightの乗算にFocusして、forward propagationとback propagation中のweightを2値化することで掛け算の量を減らす試みを行っている。
BinaryConnectが扱う2つのItem
1.計算精度
勾配の積算や平均では十分な計算精度が必要です。
weightの微妙な変動は、gradientの積算によって平均化され影響が薄れます。
それ故に積算の精度を維持することは重要とされています。
精度に関しては、Randomized rounding、weightの精度を6bit〜8bitにする方法、dynamic fixed pointで12bitにする方法などが提案されています。
また脳のシナプスは6〜12bitの精度という推定もある論文によってされています。
Noisy weight
Weightの変動は、汎化性能を高めるための正則化の役目を果たします。例えばDropoutはRandomにNeuronをOn/Offをすることによって汎化性能を高めるという手法です。DropConnectはNeuron間の結合をOn/Offするという手法です。これらの手法はactivationやweightにnoiseを加えていると考えることができます。特にDropConnectはweightに対してrandomな処理を行うという点でBinaryConnectと近いと言えます。
BinaryConnect
weightのbinarization手法として「Deterministic」と「Stochastic」という2つの手法を提案しています。
Deterministic
処理は非常に単純で下記の通りです。
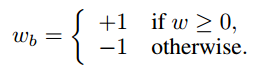
Stochastic
こちらも単純で下記の通りです。
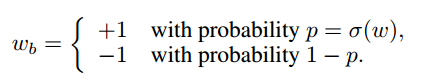
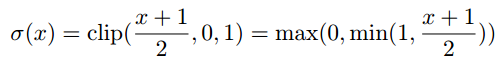
これは要約すると下記のようになります。
w_b =
\begin{cases}
+1 & w \ge 1/2\\
-1 & w \le -1/2\\
random & -1/2 \lt w \lt 1/2\\
\end{cases}
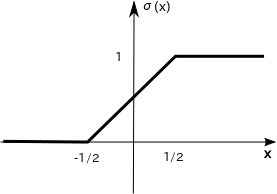
randomの時の確率が$\sigma(x)$です。この確率によって+1か-1が決まります。
確率はx=0で50%, 1/2に近づくほど+1になりやすくなります。逆に-1/2に近づくと-1になりやすくなります。
Algorithm
学習の処理をforward propagation, backward propagation, updateと分類すると、forward propagationとbackward propagationではweightをbinarizationし、updateでは実数を使用します。updateを実数で行う理由は、parameterの変化量は非常に小さいためです。

clipping
weightを一定範囲に収まるようにするためにclippingをします。
実際のbinarizationのコード
def hard_sigmoid(x):
return T.clip((x+1.)/2.,0,1)
# The binarization function
def binarization(W,H,binary=True,deterministic=False,stochastic=False,srng=None):
# (deterministic == True) <-> test-time <-> inference-time
if not binary or (deterministic and stochastic):
# print("not binary")
Wb = W
else:
# [-1,1] -> [0,1]
Wb = hard_sigmoid(W/H)
# Stochastic BinaryConnect
if stochastic:
# print("stoch")
Wb = T.cast(srng.binomial(n=1, p=Wb, size=T.shape(Wb)), theano.config.floatX)
# Deterministic BinaryConnect (round to nearest)
else:
# print("det")
Wb = T.round(Wb)
# 0 or 1 -> -1 or 1
Wb = T.cast(T.switch(Wb,H,-H), theano.config.floatX)
return Wb
その他
・学習の収束を速くするためと、weightのscaleを揃えるためにBatch Normalization使用
・ADAM
・Learning rateはexponential decayを使用
・Nesterov Momentum使用
Test Time Inference
weightの使い方に関しては3つの方法が考えられる
- 推定時にbinary weightを使用する
- 学習だけbinary weightを使用し、推定時は実数weightを使用する
- stochastic binarizationを使用して複数のNetworkを構築し、最終出力は個々のnetworkの出力の平均にする
BinaryConnectでは1の手法を使った。
Benchmark results
MNIST
・training data 60000, test data 10000
・image size 28x28
・3 hidden layer 1024 ReLU
・L2-SVM
・Batch Normalization
・minbatch size 200
・exponentially decaying learning rate
・data augmentation & preprocessing なし
・training dataのうち10000個をvalidation setとして使用
CIFAR-10
・training data 50000, test data 10000
・image size 32x32
・Network architecture
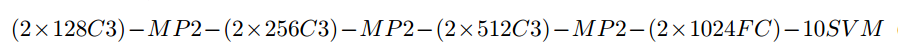
C3 ... 3x3 ReLU convolutional layer
MP2 ... 2x2 max pooling layer
FC ... fully connected layer
SVM ... L2-SVM
・Batch Normalization
・minbatch size 50
・exponentially decaying learning rate
・data augmentation & preprocessing なし
・epoch 500
SVHN
・training data 604K, test data 26K
・image size 32x32
・CIFAR-10と同じ。
違う箇所は
・ hidden layerのunit数が半分
・epoch 200
結果
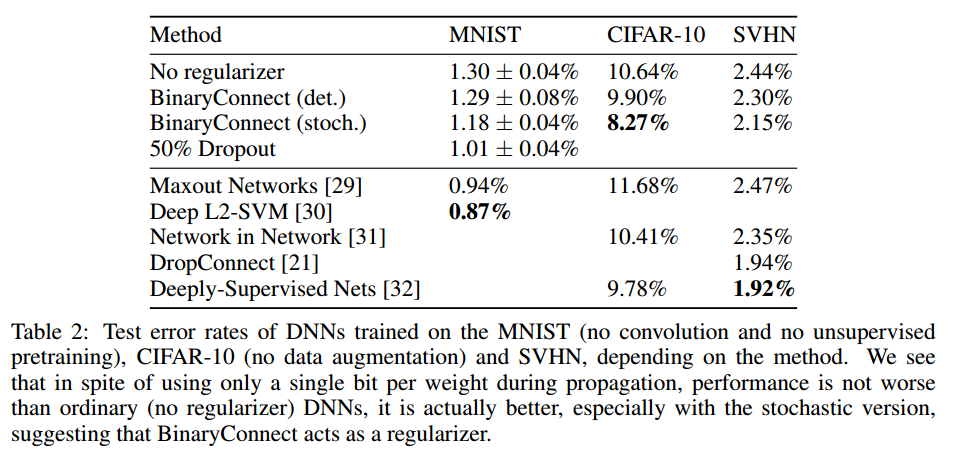
・一般的な構造のNo regularizationと比較してbinarizationによる性能の劣化は見られない
・CIFAR-10の結果ではBinaryConnectの(Stochastic binarization)のerror rateが一番低くなっている。No regularizerより性能がよくなっているのでbinarizationにより汎化性能が上がっていることがわかる。
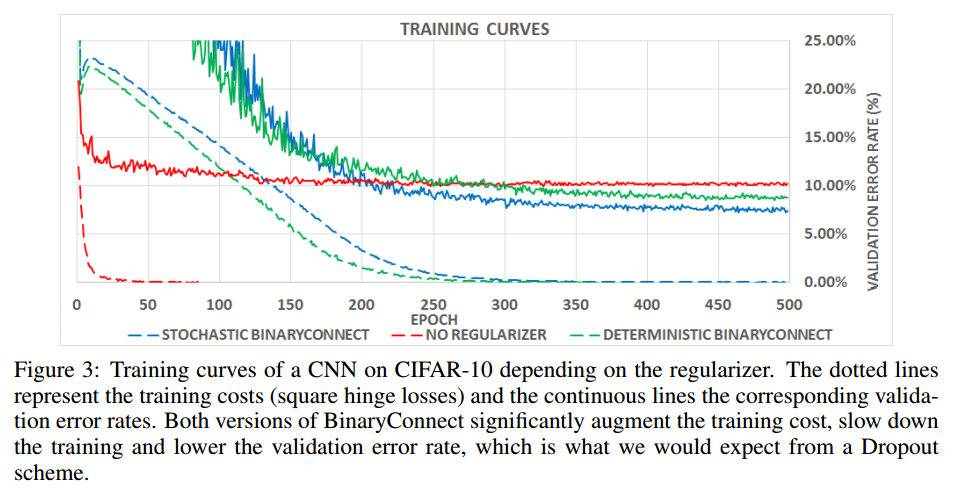
・dashed ... training data, solid ... validation data
・red ... no regularizer, blue ... stochastic BinaryConnect, green ... deterministic BinaryConnect
・No regularizerよりerror rateが低くなっていて、こちらのグラフからもbinarizationにより汎化性能が上がっていることがわかる。
最後に
基本的には重みが正ならば+1, 負ならば-1にすると言うことのようです。Stochasticでは、0のところで急激に+1/-1にbinarizationするのではなく、確率的に+1/-1になるようにしています。この部分は計算コスト削減だけでなく、汎化性能向上にも役立っているようです。
DropConnectはNeuronの結合をrandomにcutするものですが、実装としてはweightとrandomに決めたmaskとの要素ごとの積なので、maskの部分がBinaryConnectで言うところのStochasticな部分というイメージなのかもしれません。