Deep3D: Fully Automatic 2D-to-3D Video Conversion with Deep Convolutional Neural Networks
この論文は、2次元画像から3次元画像を生成するものです。ここで結果とコードが見れます。
3次元画像は3D映画やVRなどで必要とされています。3次元画像を生成する方法としては、「Stereo Cameraを使用」するものと「2D画像から3D画像を生成」する2つあります。Stereo Cameraを使用する方法には、コストの問題や特殊な撮影(force perspective)をするときはMulti ViewのCameraが使えないなど問題があり、その場合には2D画像から3D画像を生成する技術が代替案として必要とされます。プロによる映像の2D、3D変換は、depth artistによる手作業のMapに頼っています。2D、3D変換は人手によるMapに頼っており、3D映像産業の発展の障害になっています。
2D、3D変換問題は"under constrained"な問題で解くのに条件がたりないため、Depthは曖昧になります。さらに隠れている部分はInpaintingアルゴリズムでHullucinationしなければならないという問題もあります。
学習によりDepthMapを生成する場合は正解データが必要になりますが、室内とか一般的ではない屋外のシーンなど数が少ないと問題もあります。
この論文ではすでに存在する3D Stereo movieを利用して学習を行い、確率的なDisparity Mapを推定します。
従来の2D、3D変換は、2つのステップからなります。
1.左目画像からDepth Mapを推定する
2.Depth Image Based Renderingによって右目画像をRenderingする
Pixel単位で右目画像を推定すると精度がよくないので、論文では右目画像は左目画像をshiftしてcopyしたものとしてDIBR処理を利用しています。従来手法とは異なり、正確なDepth Mapを生成する仕組みはいらないし、学習のために正確なDepth Mapも必要ない。そのかわり、確率的なDisparity likeなMapを推定し、そこからDIBR処理をつかって左目画像と結合して右目画像を生成しています。
学習中は、Modelによって生成されたDisparity likeなMapは本物のDisparity Mapとは直接比較せず、水平方向のDisparityとinpainting処理に使われます。
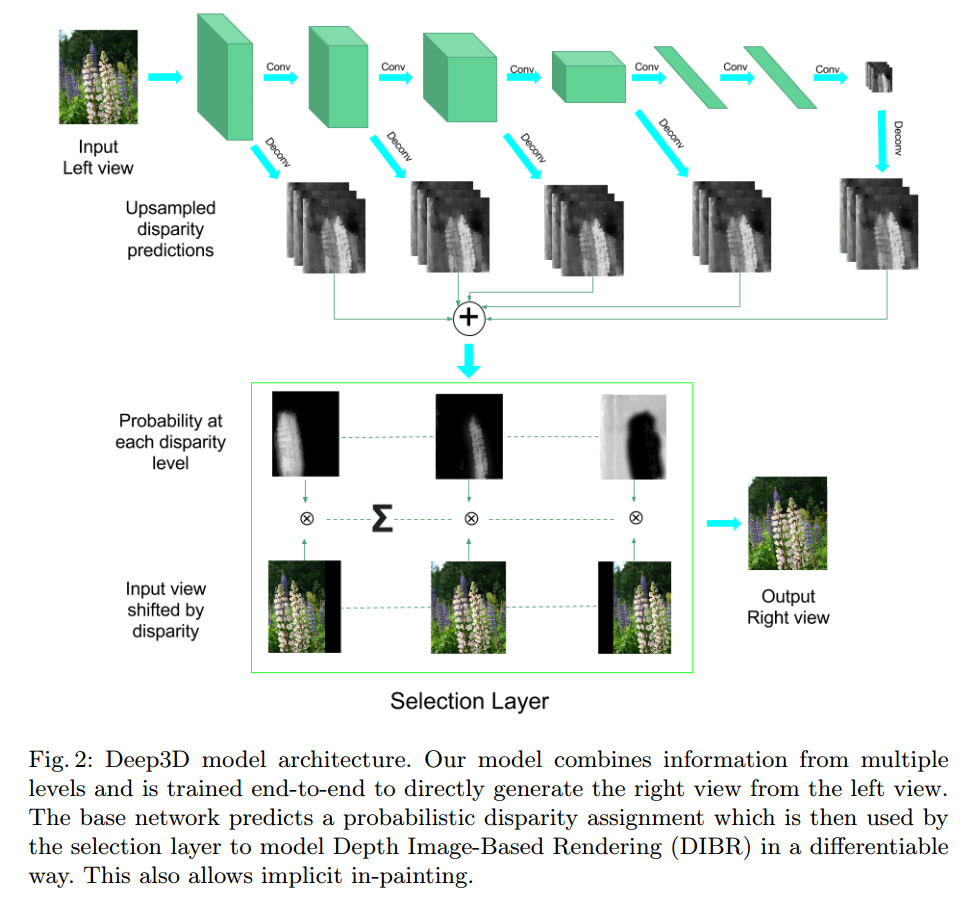
Model Architecture
下図がArchitectureになります。Pooling Layerの後に2つに分かれてDeconvolution(Convolution transpose) によって入力画像と同じサイズにします。その後、すべてのFeature Mapが加算されます。それをさらにConvolution処理を行って、得られたFeature MapのChannel方向に対してSoftmaxを出して確率にします。このSoftmax値が確率的Disparity Mapになります。その後に左目画像と確率的Disparity Mapから右目画像を生成します。
Deconvolutionは、Convolutionのforwardとbackwardを入れ替えたものです。bilinear interpolationと等しくなるようにDeconvolutional layerを初期化すると学習が容易になることがわかったとのことです。初期化の式は下記の通りです。
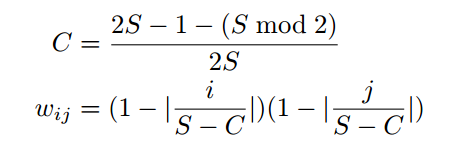
Reconstruction with Selection Layer
2D-to-3D 変換の一般的な式は下記の通りです。
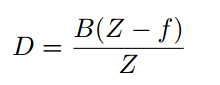
B ... 2つのカメラ間の距離
I ... 左目画像
O ... 右目画像
Y ... 右目画像(正解データ)
Z ... Depth Map
D ... Disparity Map (負の時Focus Planeより物体が手前、正の時Focus Planeより物体が奥)
f ... カメラからfocus 面までの距離

この論文では、右目画像は左目画像を水平方向にずらしたものいう条件を使っています。なので関係式は下記のようになります。
ここでOは右目画像で$D_{i,j}$は位置$(i,j)$のDisparity(ずれ量)です。
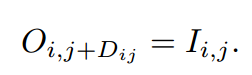
しかしながらこれは$D$に関して微分可能ではないので、deep neural networkでは学習できません。ネットワークでは、それぞれの画素位置でDisparityの値がdである可能性の確率値$D^d_{i,j}$を推定します。ここで左目画像をdずらしたものを$I^d_{i,j}$とします。
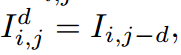
右目画像$O_{i,j}$は左目画像をdずらしたもの$I^d_{i,j}$とその確率$D^d_{i,j}$をかけてそれぞれの$d$を加算したものとして表現されます。
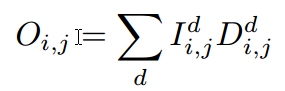
これは$D^d_{i,j}$に関して微分可能なので、Loss functionをL1 normとすると下記のようになります。ここで$Y$は右目画像の正解データです。
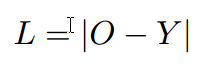
映像データ$1920\times 1080$を1/4に縮小$432\times 180$にして確率的Disparity Mapを推定し、それを原画ザイズまで拡大して右目画像生成に使用します。
Experiments
Implementation Details
実装の詳細情報
・Network構造はVGG16ベース
・VGG16のParameterを初期化値として使用
・VGG16以外で使いした部分のParameterの初期値はnormal distributionで標準偏差が0.01を使用
・Pooling Layerの後で枝分かれして、Batch Normalizationして3x3のConvolutionをしてDeconvolutionをします。
・Deconvolutionの初期値はbilinear upsamplingになるような値にします。
・2つの4096 unitのfully connected layerをConvolutionの後に行います。(論文は4096と書いてありますが、最後のfully connected layerは1980unitのようです。そうでないと次のReshapeで33channel 12x5のサイズにした時に余ってしまいます。)
・最後にReshapeで33channelの12x5のサイズにします。
・33channelの12x5をDeconvolutionで入力と同じサイズにします。
・Deconvolutionの出力を全部足します。
・画素毎に全部たしたものをDeconvolutionで33channelにし、さらにConvolutionします
・Convolutionで得られた結果をSoftmaxで確率にします
・Selection Layerでは-15~16までのDisparityと確率的Disparity Mapをかけたものをたして右目画像を生成します。
※-15~16トータル33channelと書いてありますが、これだと32channelしかない気がするのですがどういうことかな?
・mini batch size 64
・学習回数は100,000回
・learning rate初期値が0.002で20000毎に1/10
・Weight decayなし
・dropout rate 0.5で場所はfully connected layerの後
Result
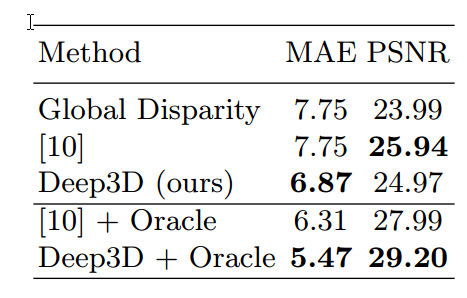
下記は性能比較結果です。
比較はMean Absolute ErrorとPSNRで行っています。
Global Disparityは、全画面で一つのDisparity値を使ったもので、値はMAEが最小の時ものです。
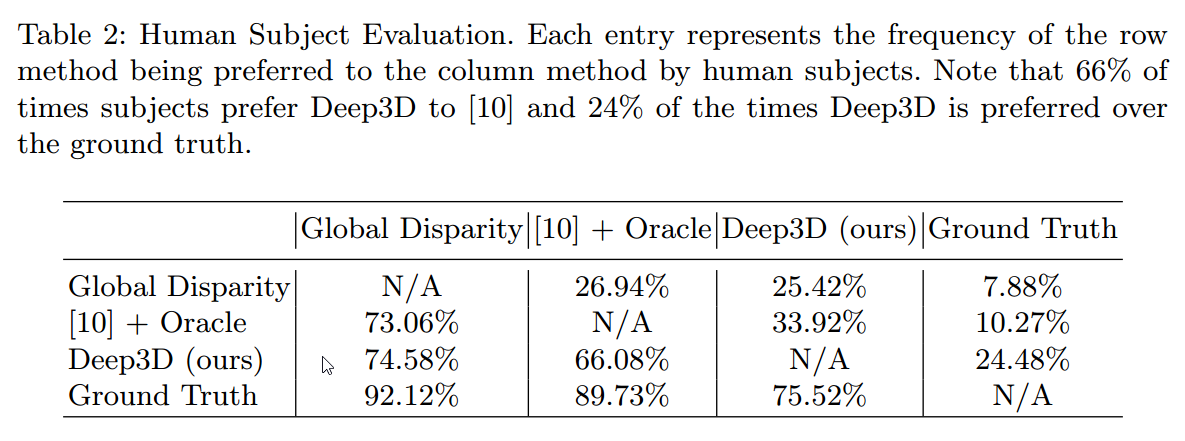
下は主観評価の結果です。
主観評価は2つのアルゴリズムの結果を提示して、どちらがいいか又はわからないを選んで評価するというものです。
値は行の方に書いてあるAlgorithmの方がいいと言った割合です。
例えばDeep3Dと論文[10]のアルゴリズムでは総質問回数のうち66.08%でDeep3Dの方がいいという回答を得たということになります。
Ablation Study
low level featureとselection layerの有り無しの性能比較の結果です。

lower level featureなしは、下層のConvolutional Layerからの枝分かれなしで、単純に5つのconvolutional Layerとpoolingさらに2つのfully connected layerで構成されたfeed forwardのネットワークです。
Selection layerなしは、論文に詳細が書かれていませんが、Probability Disparity Mapの部分がない場合ということだと思われます。
当然ですがすべて使ったほうが性能は良くなっています。(ただPSNRだけselection layerなしの方がいいのですが、これがどのくらいの差なのかわからないです。)
Temporal Information
こちらは時間方向の情報を使った時の性能の向上をチェックしたものです。
時間方法の情報は、(1)単純に入力を5frameにしたものと(2)入力を1frameでかつ5 frame のoptical flowを使ったものの2つの方法で試しています。下記が結果になりますが、思ったほど性能は上がっていません。著者はもう少しネットワーク構造を変えたり、パラメータを調整したりすれば性能がでるだろうと言っています。

感想
左目画像と確率的Disparity Mapをかけて足したものから右目画像を作ろという手法だが、これで隠れている部分が推定できるのか不明。
ただし、DatasetのDepthデータはkinectで取得できるような室内ばかりで屋外はほとんどない。Stereo画像を使うというのはDatasetの問題を解決できる方法の一つかと思う。