Mujoco MPCとは
動画↓
Mujocoシミュレータ内でMPCを実装したデモコード群です。
そもそもMujocoといえば強化学習のイメージが強いですよね。
ロボットが何度もトライ&エラーを経験しながら、徐々に優れた方策を獲得していく手法です。
例えばロボットアームが物体を掴みそこねて落としたり、4足歩行ロボットが段差を登れずひっくり返ったり…失敗を何度も重ねながら成長していきます。
そういった挙動の再現には高度な物理シミュレーターが必要で、世界中でよくMujocoが使用されています。
Mujoco自体は物理シュミレーターですので、モデルベースの古典制御や現代制御も普通に通用します。
環境構築が恐ろしく簡単だったので、学習分野だけでなく、制御工学の教材として非常に有用であると感じました。
今回はGoogle Deep Mindの Mujoco をインストール後、 Mujoco MPC (https://github.com/google-deepmind/mujoco_mpc) をソースからコンパイルして、モデル予測制御(Model Predictive Control)のサンプルを実行する所まで説明します。
そろそろ新学期なので、研究室に配属された学部3~4年生が研究の足がかりにできるよう、最大限平易な解説を目指します。
0. 環境
- Ubuntu 20.04
- Python 3.8 (Ubuntu20.04にデフォルトで入ってるやつ)
- pip
Python3.8はUbuntu20.04をインストールした時点でデフォルトで入っていますが、pipは設定次第では入ってないかもしれません。もしpipをお持ちでない方は、以下のようにapt経由でインストールしましょう。
$ sudo apt install python3-pip
これからセットアップの過程で様々なライブラリをインストールします。ご自身の開発環境が破壊されないか慎重に検討して下さい。
(dockerやpyenvのような仮想環境は本記事では扱いません。)
参考程度に私のPCスペックを記載しておきます。PC性能によってはコンパイルの速度やシミュレータの実行速度に悪影響が出るかもしれませんね。
- CPU: intel core-i9-9900 3.6GHz×16スレッド
- GPU: RTX 2080 Super
- RAM: 94GB
1. mujocoのインストール
では最初に、ターミナルを立ち上げて、
$ pip3 install mujoco
$ pip3 install -U scipy
を実行してください。
物理演算シミュレーターmujocoのインストールが完了します。
2行目のscipyのアップグレードは飛ばしても行けるかもしれませんが、念の為。私は必須でした。
2. Mujoco MPCに必要なライブラリのインストール
mujocoシミュレータ自体は上記だけでセットアップ完了ですが、MPCのデモには他にもソフトウェアが必要です。
以下のコマンドを実行して、依存ライブラリをインストールして下さい。
$ sudo apt install libgl1-mesa-dev libxinerama-dev libxcursor-dev libxrandr-dev libxi-dev ninja-build clang-12
aptはコンパイル済みのライブラリをダウンロードするコマンドです。
ソフトウェアを簡単に入手できる一方、ソースコードは入手しないため、機能を書き換えることが出来ないデメリットがあります。
一方で、肝心のMPCはコードを書き換えながら勉強・開発・研究することが目的のため、ソースコードをダウンロードし、手元でビルドします。
3. Mujoco MPCのソースコードの入手から、cmakeとninja build
次に、githubからソースコードをダウンロードします。
ソースコードを保存したいディレクトリに移動して、そこでgit cloneです。
$ cd ~/src
$ git clone https://github.com/google-deepmind/mujoco_mpc.git
今度はmujoco_mpcの中にビルドディレクトリを作り、その中でcmakeします。
この辺から公式のREADMEには一切書いてない、初心者殺しの暗黙テクになります。
通常のgccコンパイラではなく、clang-12とninja buildを使用します。
$ cd mujoco_mpc
$ mkdir build
$ cd build
$ cmake .. -G Ninja -DCMAKE_C_COMPILER:STRING=clang-12 -DCMAKE_CXX_COMPILER:STRING=clang++-12 -DMJPC_BUILD_GRPC_SERVICE:BOOL=ON
$ cmake --build .
最後の2行は結構時間がかかります。
ビルドが成功すると画面はこんな感じです。
2024年2月現在、warningが1件出ましたがデモは実行できました。
4. 犬のデモの実行
実行ファイルは mjpc という名前で、 build/bin ディレクトリ内に作成されています。
binディレクトリに移動し、実行コマンド(./)をしてみましょう。
$ cd bin
$ ./mjpc
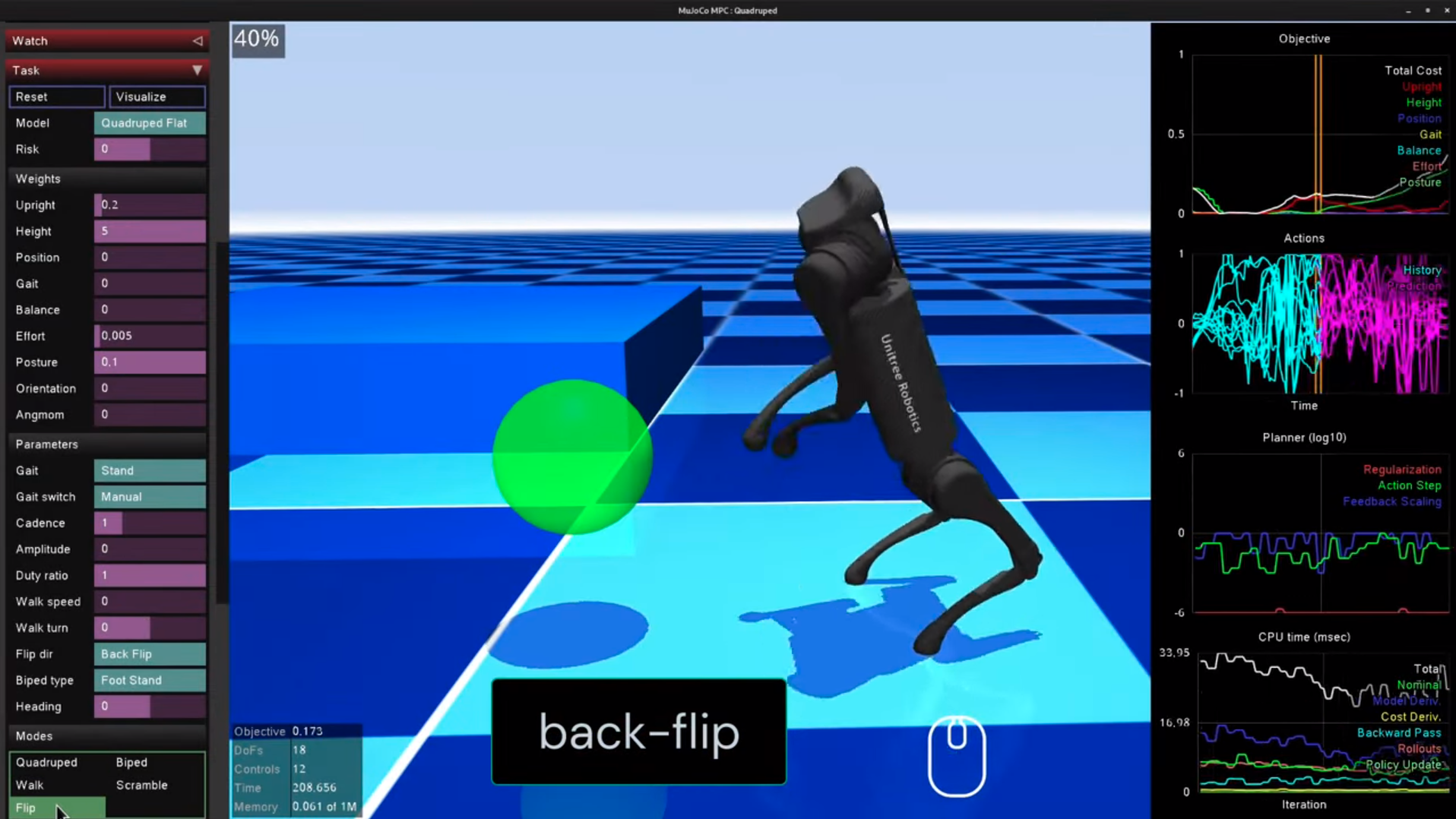
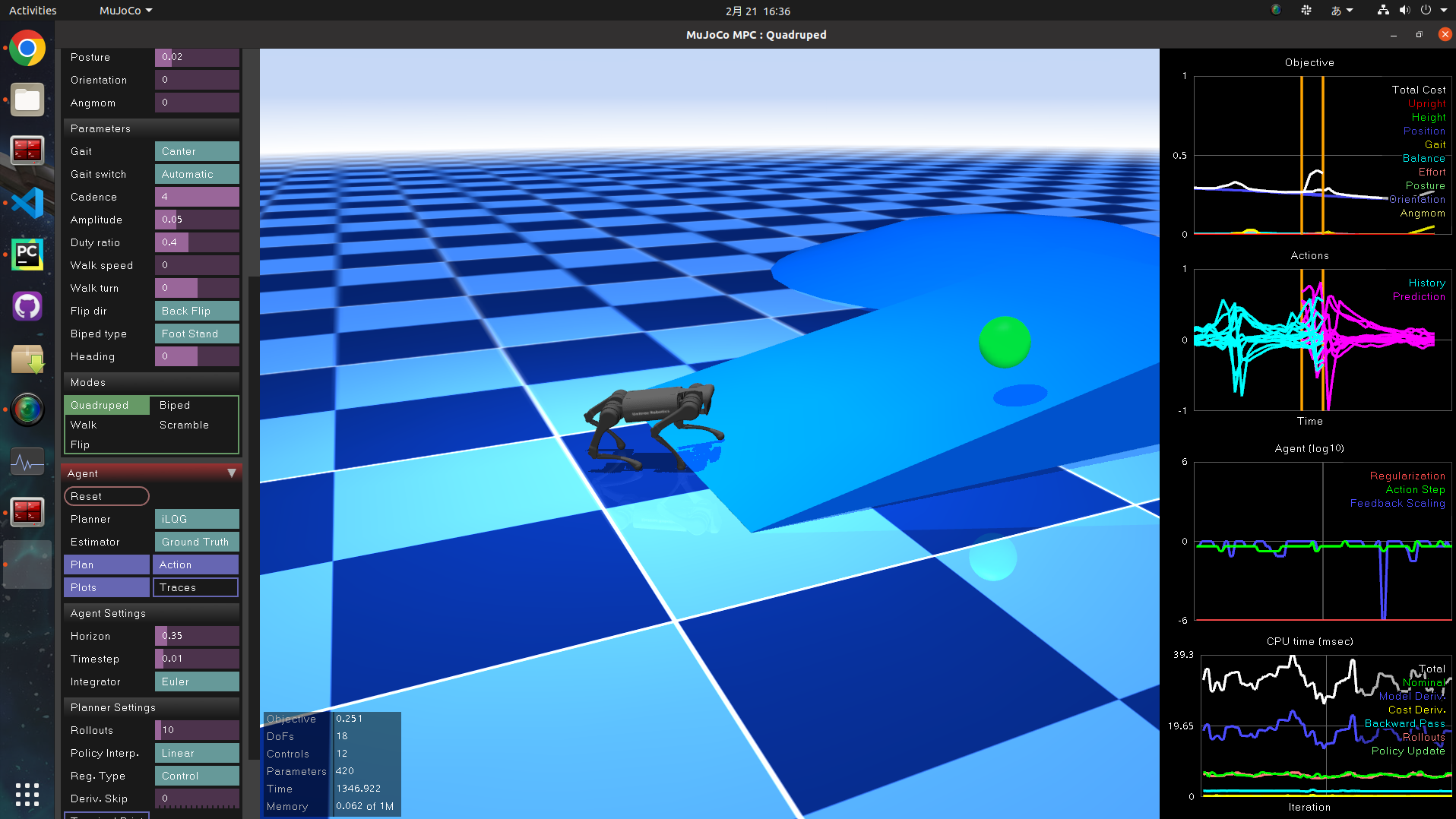
シミュレータの画面が現れ、Unitree A1が現れます。
が、立っていません。
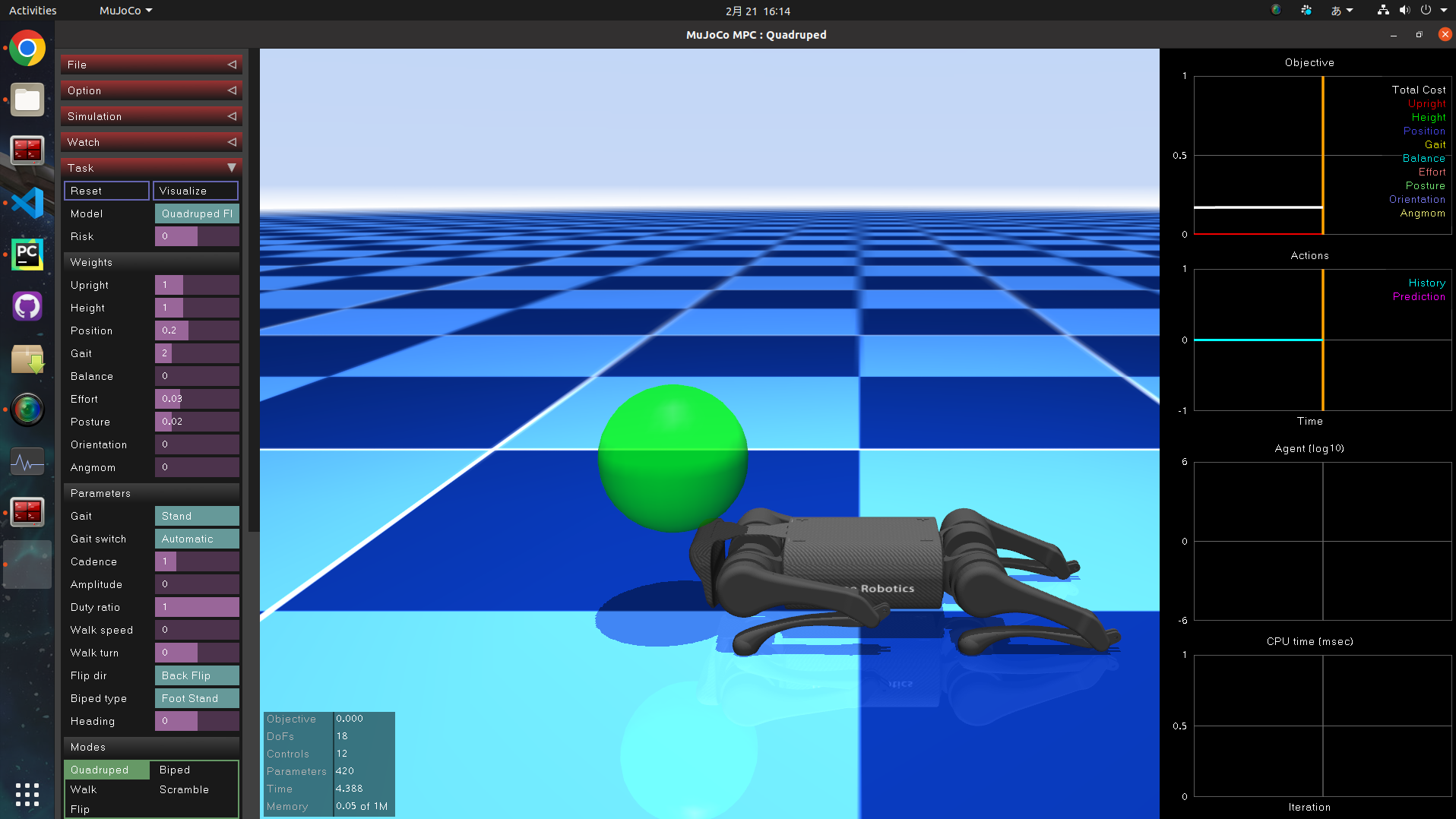
そこで、左の列の中から Agent タブの Plan ボタンを押します。
すると下の画像のようにピョコンと立ち上がります。
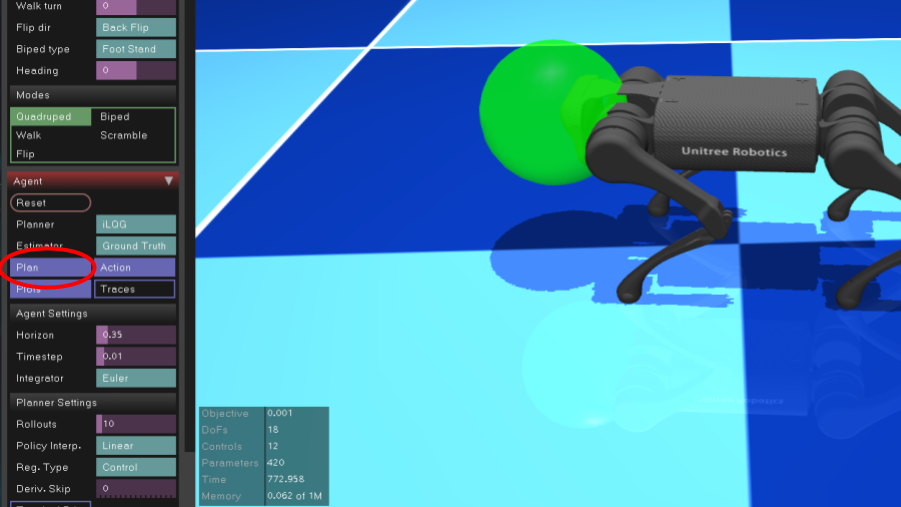
緑のマーカーがゴールとなっており、ロボットは頭部をここに合わせるよう歩きます。このマーカーはマウスで直接操作でき、リアルタイムでロボット犬と戯れることができます。これだけで幸せ。
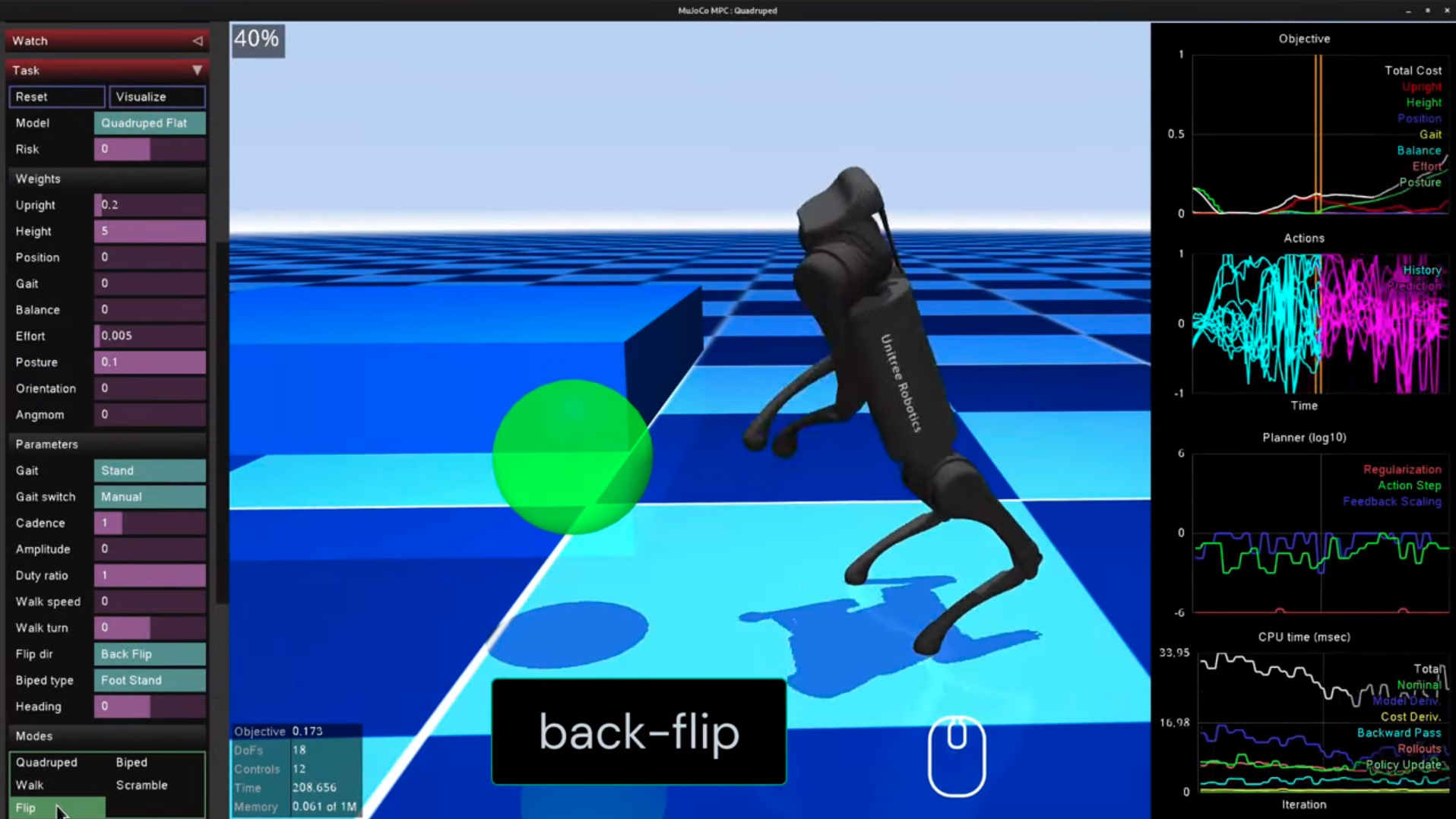
また、Modesの中のflipボタンを押すと、その場でバックフリップします。
5. 倒立振子のデモの実行
左側のメニューの Task タブの中で、Model という項目を切り替えると、シミュレーション世界が変わります。
Cartpoleを選択してみました。
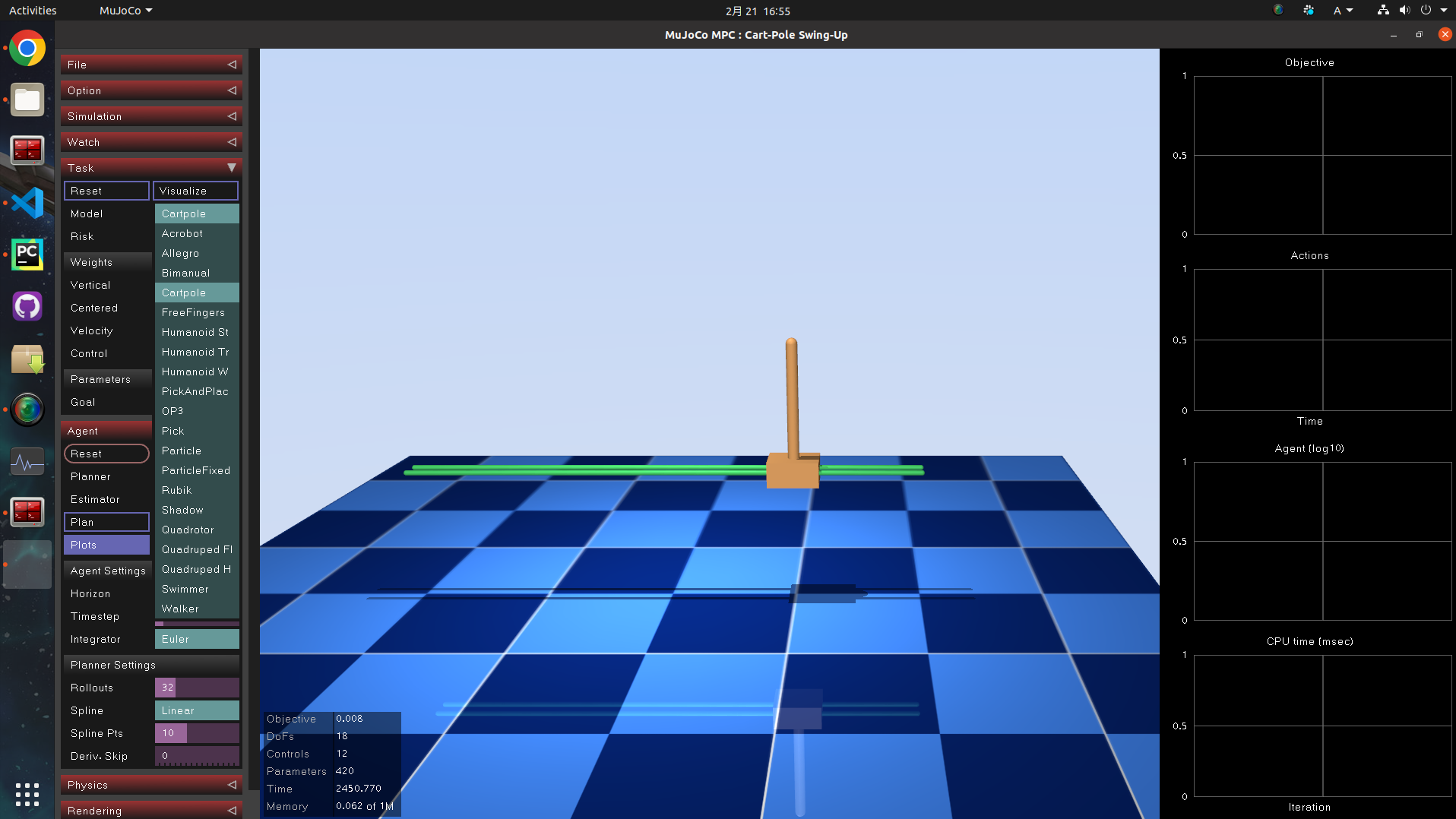
台車と振り子が現れました。先ほどの犬のデモ同様、Planボタンを押すと、制御が始まります。
犬のデモはマーカーのマウス操作でしたが、今回はTaskタブ内のGoalの値を操作することで、振り子の目標位置をリアルタイムで操作できます。
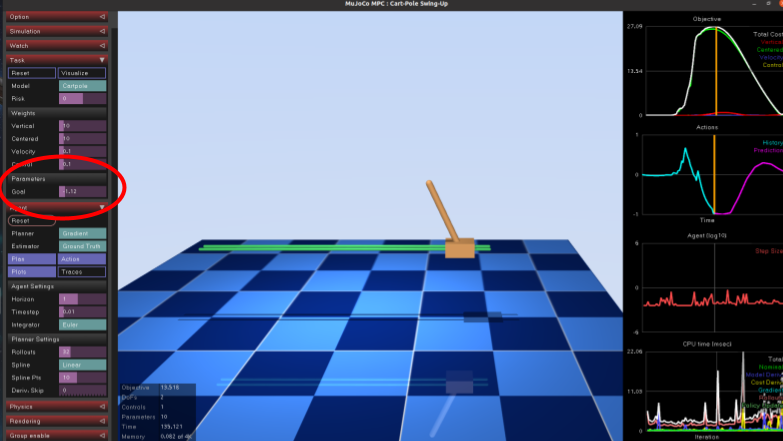
振り子の動作をよく観察すると、左にゴールが設定された場合は最初に一瞬右に台車が動き、振り子部分を慣性で左に傾けた後、その振り子をすくい上げるように台車が左に移動します。
時系列的に未来の振り子の動きを予測計算して、最適な動作を選択しているんですね。MPCの視覚化として非常に面白いです。
6. その他のデモ
以下、同様に Task タブの中で Model をいろいろ切り替えてみました。
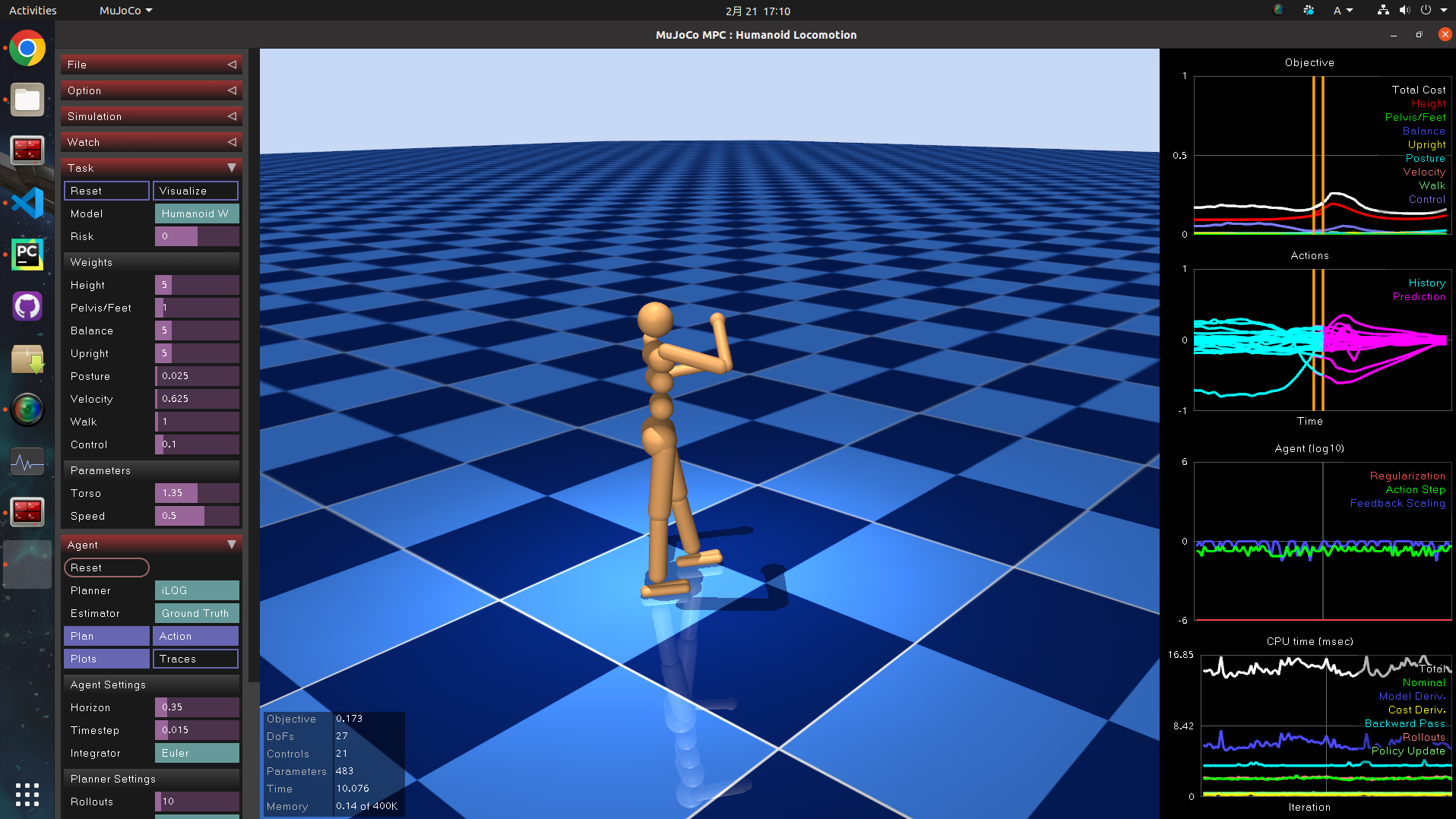
6.1 ヒューマノイドの歩行
ちゃんと歩きます。
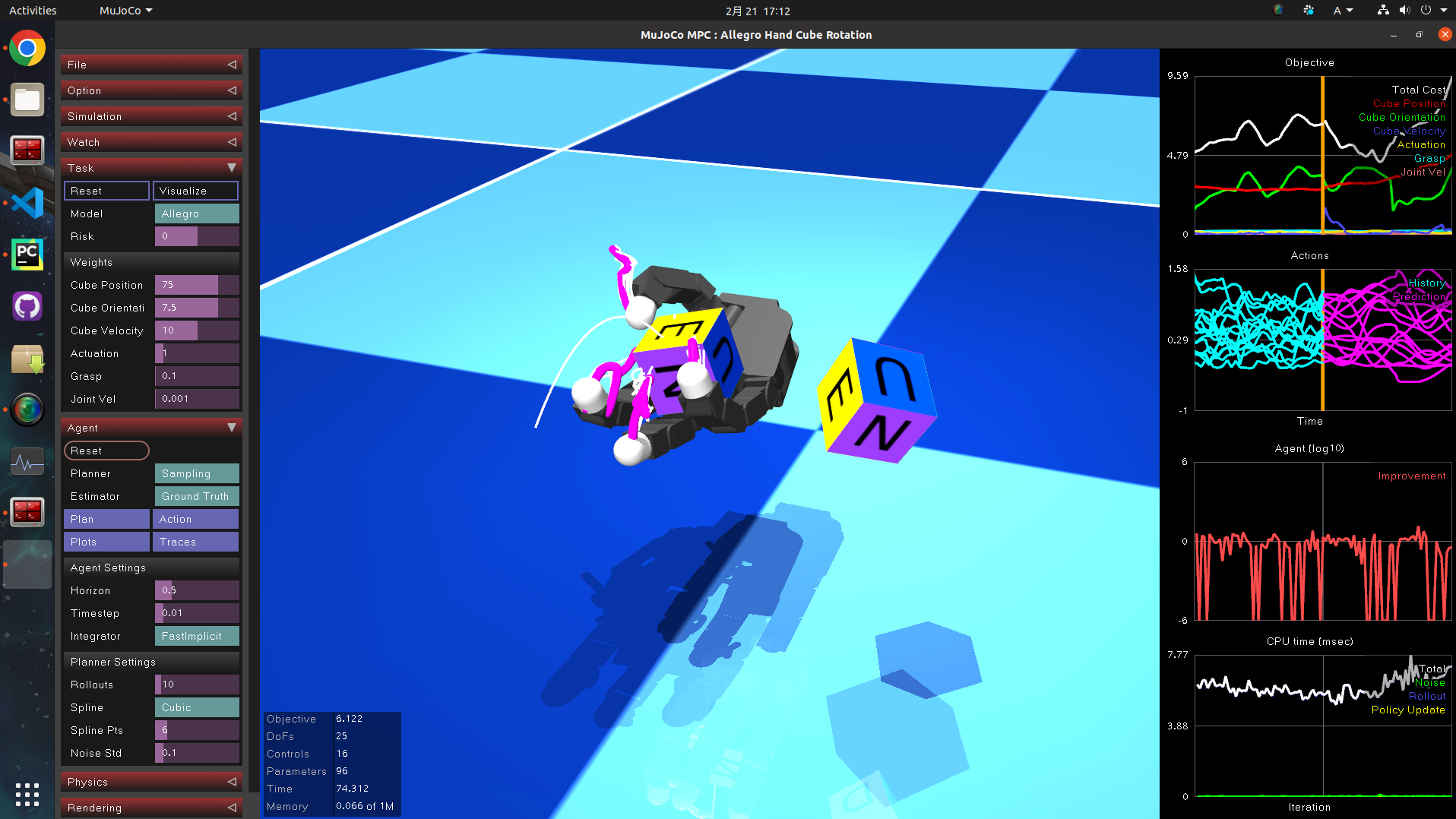
6.2 インハンド・マニピュレーション
右側の立方体をマウスで回転させると、ロボットハンドが掌の上でキューブを回転させます。
正直MPCで解けることに驚きました。モデル化の記述としては、質点+外力でしょうか。後でコード読んでみます。
ピンクのマーカーは直近の制御ステップでMPCが算出した、制御ホライゾンまでの指先の軌道かと思われます。
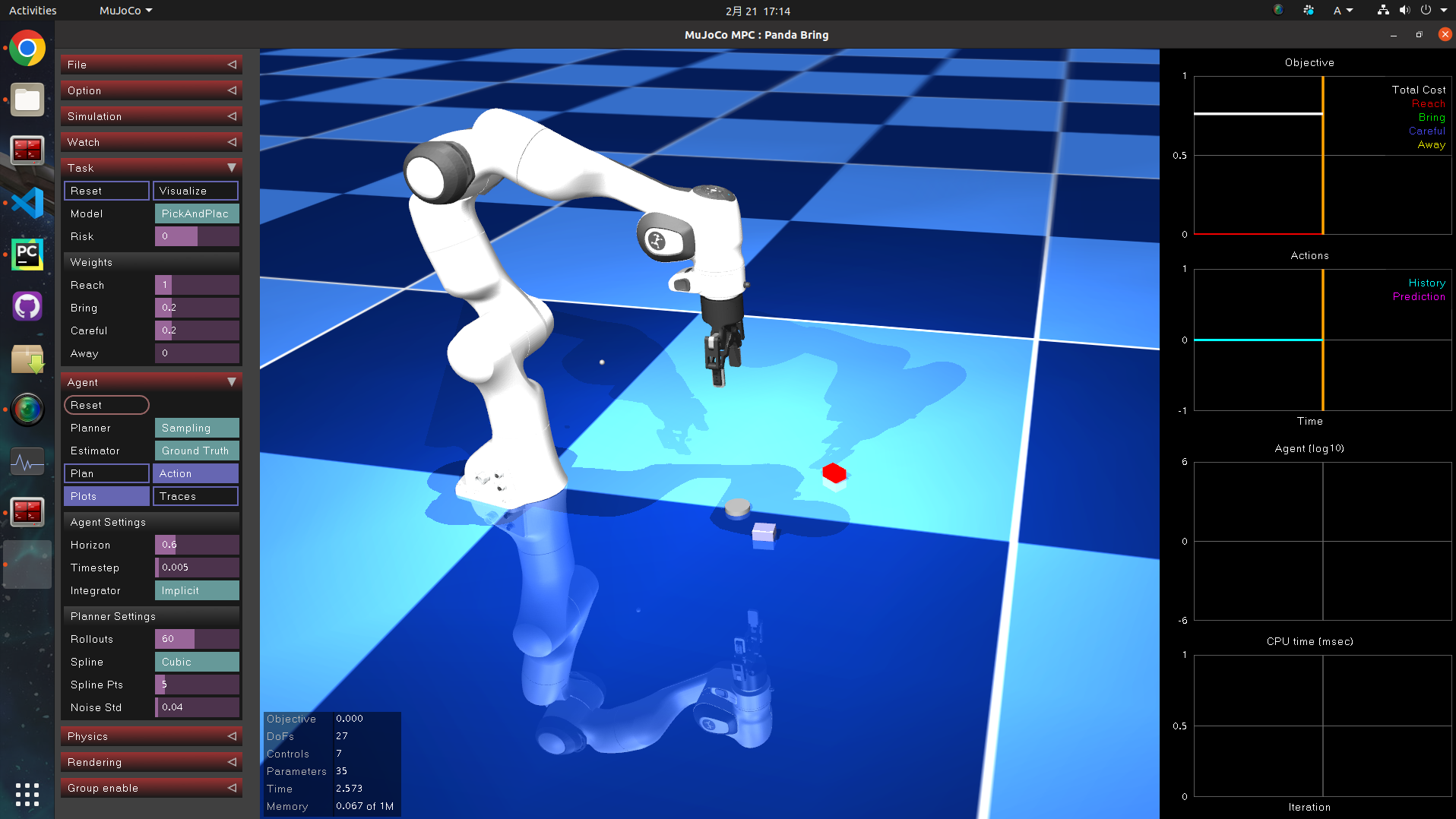
6.3 単腕マニピュレータ
Pick and Place の勉強に良さそうですね。
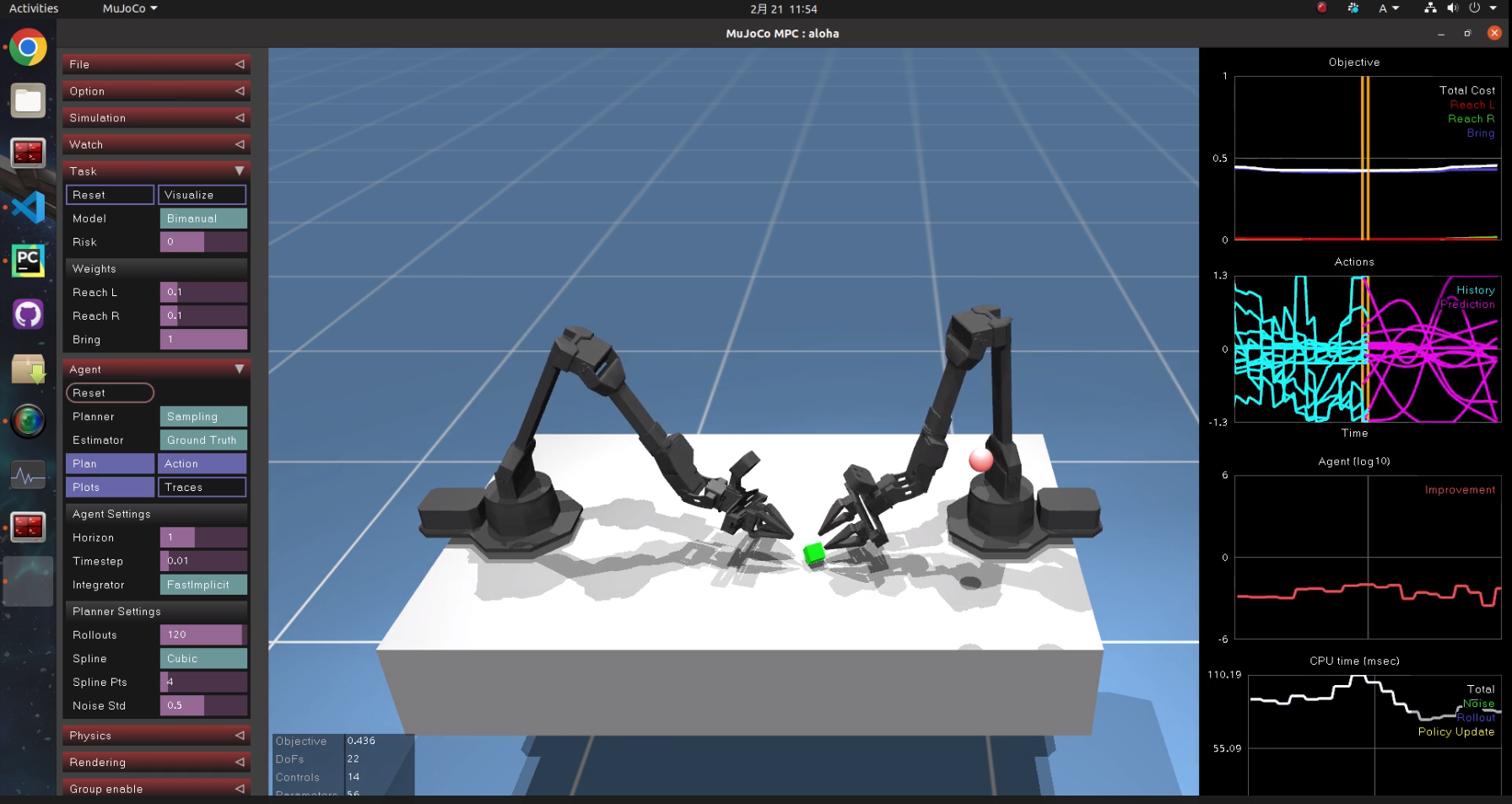
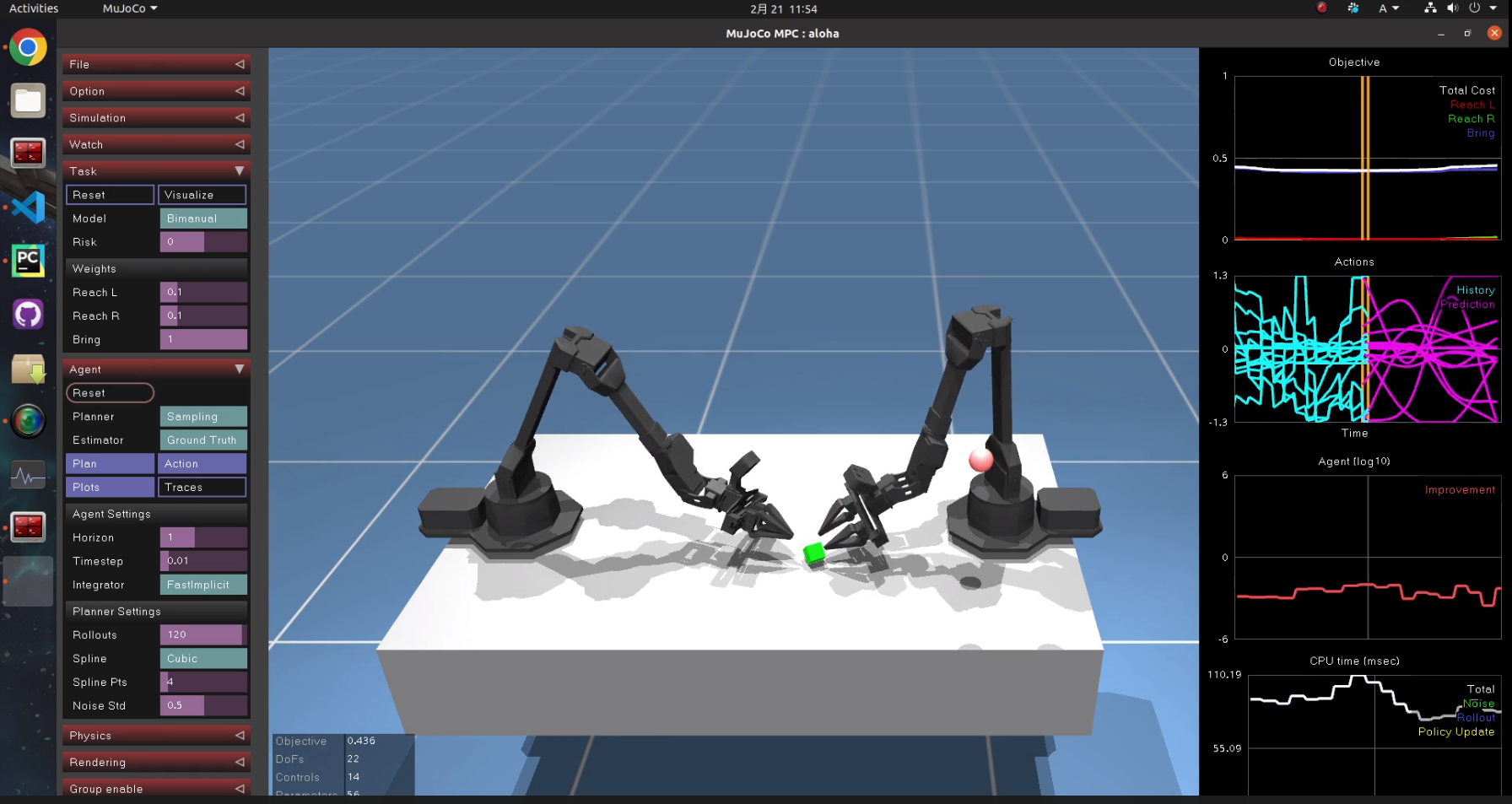
6.4 双腕ロボットアーム
机の上の緑色のキューブを赤いマーカーに合わせるタスクです。
関節変位に対するペナルティ項(重み)が小さいのか、遠い側のアームも常にフニャフニャ動きます。無駄に見えて、それがどこか生命を感じさせて、個人的には一番面白かったです。是非お試し下さい。
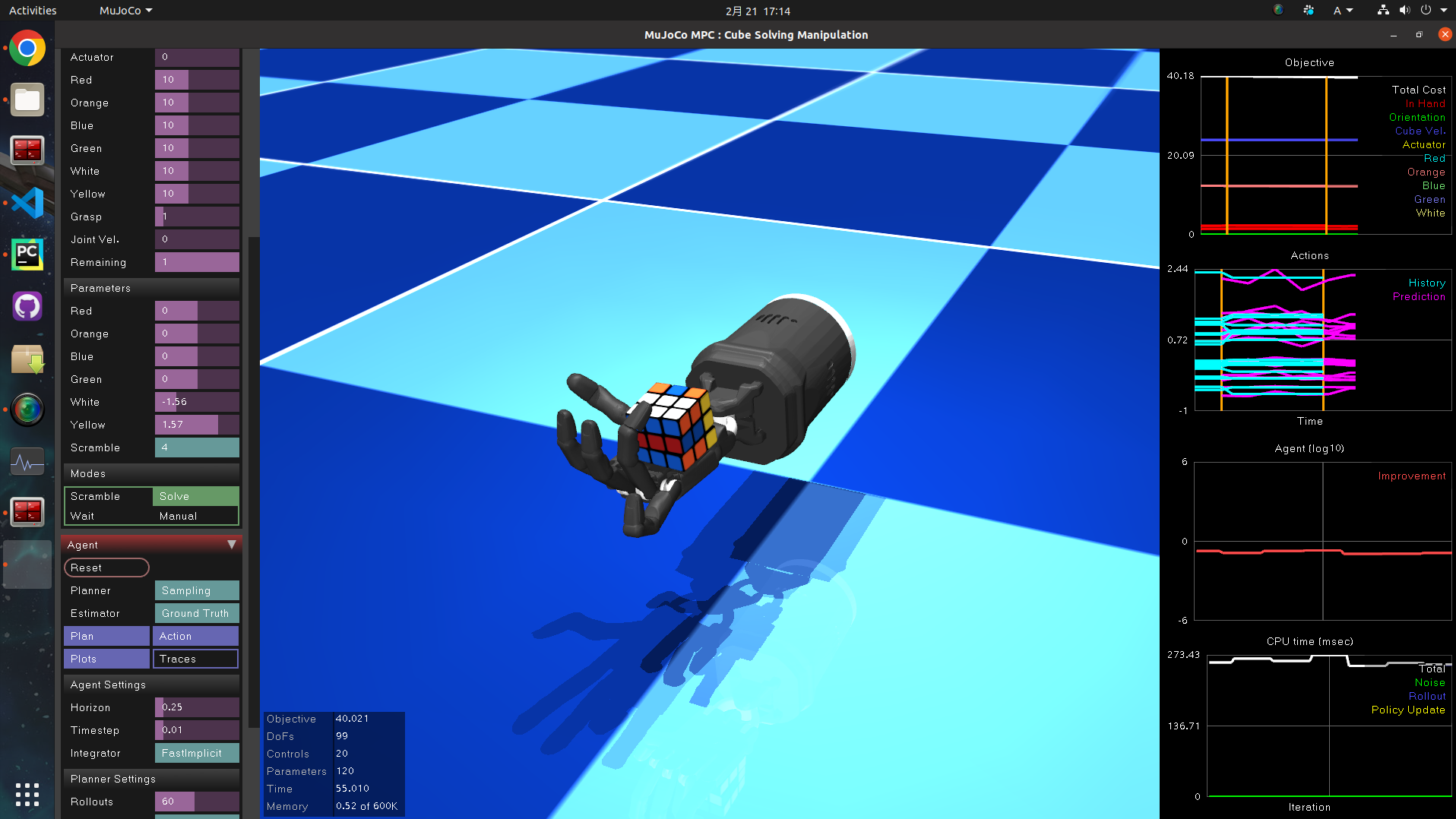
6.5 ルービックキューブ
流石にMPCでは解けないようで、MPCが1ステップ計算するのに270msも要しています。
これは強化学習の出番でしょうか…。
終わりに
MPCって本当にすごいのでは。
CNNに始まりLLMが人類を倒しつつある2024年ですが、改めて現代制御の強さを見ました。
CNNにしろ強化学習にしろ、学習系手法は必ず事前学習プロセスで時間が掛かります。1回あたり20時間とか。
しかもネットワークの構造や報酬関数の設定でかなり試行錯誤と微調整が必要で、調整→20時間→失敗→調整→20時間→…とか正直しんどいと思います。
もちろんモデル予測制御を使うだけでは研究にはなりませんから、多くの学生~研究者が未開拓の領域を日々掘削しているわけですし、Unitree H1なんかは強化学習で凄まじいロバスト性を獲得しています。
一方で今回は理想的なシミュレーション環境内でのデモなので、実世界でこれほどロバストかは未検証です。
まずはこれで勉強を積み、実機に搭載して検証でたいです。
学習系手法もモデルベースの制御も、どちらも大事だと感じました。