モチベーション
chainerでtrainerを使って回帰問題を解きたいけど中身が分からなくてモヤモヤする、mnistのexampleとかだとmodelがL.Classifierでラップされてるけど何をやっているのかよく分からない、と思ったのでこの辺のソースを読み解いてみました。
自分の中で読み解いた時系列順にそのまま書いてるので、あんまり綺麗にまとまってはいません。すみません。
dataset、iteratorに関する説明は省略しています。
class MLP(chainer.Chain):
def __init__(self, n_units=100, n_out=10):
super(MLP, self).__init__()
with self.init_scope():
self.l1 = L.Linear(None, n_units)
self.l2 = L.Linear(None, n_units)
self.l3 = L.Linear(None, n_out)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
return y
このモデルを、誤差関数をF.mean_squared_errorとかにして、updaterやtrainerを用いて学習したい。結論から言うと、ラッパクラスを自分で定義すれば良いのですが、一つずつ見ていきます。
Trainerについて
trainer.run()が何をしているのか見てみる。
def run(self):
# 中略
# invoke initializer of each extension
for _, entry in extensions:
initializer = getattr(entry.extension, 'initialize', None)
if initializer:
initializer(self)
update = self.updater.update
reporter = self.reporter
stop_trigger = self.stop_trigger
# main training loop
try:
while not stop_trigger(self):
self.observation = {}
with reporter.scope(self.observation):
update()
for name, entry in extensions:
if entry.trigger(self):
entry.extension(self)
finally:
for _, entry in extensions:
finalize = getattr(entry.extension, 'finalize', None)
if finalize:
finalize()
self.updater.finalize()
どうやら、whileループごとにupdater.update()が呼び出され、そのあと各extensionの処理を行なっているようです。updater.update()を見ていきます。
Updaterについて
def update(self):
"""Updates the parameters of the target model.
This method implements an update formula for the training task,
including data loading, forward/backward computations, and actual
updates of parameters.
This method is called once at each iteration of the training loop.
"""
self.update_core()
self.iteration += 1
def update_core(self):
batch = self._iterators['main'].next()
in_arrays = self.converter(batch, self.device)
optimizer = self._optimizers['main']
loss_func = self.loss_func or optimizer.target
if isinstance(in_arrays, tuple):
optimizer.update(loss_func, *in_arrays)
elif isinstance(in_arrays, dict):
optimizer.update(loss_func, **in_arrays)
else:
optimizer.update(loss_func, in_arrays)
batchはiterator.next()が返すミニバッチ
self.converterはデフォルトではchainer.dataset.convert.concat_examplesとなっている。in_arraysの中身をipythonで確認してみる。
In [86]: in_arrays[0].shape
Out[86]: (500, 100) # batch_size * input_dim
In [87]: in_arrays[1].shape
Out[87]: (500, 10) # batch_size * output_dim
In [88]: type(in_arrays)
Out[88]: tuple
なるほど。この場合in_arraysはtupleなので
optimizer.update(loss_func, in_array[0], in_array[1])が呼び出される。
loss_func = self.loss_func or optimizer.targetとあるから、updaterのコンストラクタでloss_funcを指定すればその関数が呼び出され、指定しなければoptimizer.targetが呼び出されます。
In [89]: optimizer.target
Out[89]: <train2.MLP at 0x10fcf65c0>
targetはMLPのインスタンスを表すので、MLP.__call__()が呼び出されるわけである。
つまりMLP.__call__()はtrain時にはlossを返すような関数にするとupdaterに自然に入るというわけですね。多分。
こんな風に書き換えてみる。
class MLP(chainer.Chain):
def __init__(self, n_units, n_out):
super(MLP, self).__init__()
with self.init_scope():
self.l1 = L.Linear(None, n_units)
self.l2 = L.Linear(None, n_units)
self.l3 = L.Linear(None, n_out)
def __call__(self, x, t=None):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
if t is None:
return y
else:
return self.lossfun(t, y)
これでupdater.update_core()が動くようになったはず。
L.Classifierについて
mnistのサンプルとかにある、model = L.Classsifier(MLP())は何をしているのか。見ていきます。
class Classifier(link.Chain):
# 中略
def __call__(self, *args):
# 中略
assert len(args) >= 2
x = args[:-1]
t = args[-1]
self.y = None
self.loss = None
self.accuracy = None
self.y = self.predictor(*x)
self.loss = self.lossfun(self.y, t)
reporter.report({'loss': self.loss}, self)
if self.compute_accuracy:
self.accuracy = self.accfun(self.y, t)
reporter.report({'accuracy': self.accuracy}, self)
return self.loss
何かをreportしている。L.Classifierというラッパーの役割は、この__call__メソッドの返り値をlossにして、lossとaccuracyをreporterにreportすることだったのだ。納得。
ということで、reporterにreportするようにMLPを書き換える。
class MLP(chainer.Chain):
def __init__(self, n_units, n_out):
super(MLP, self).__init__()
with self.init_scope():
self.l1 = L.Linear(None, n_units)
self.l2 = L.Linear(None, n_units)
self.l3 = L.Linear(None, n_out)
def __call__(self, x, t=None):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
if t is None:
return y
else:
self.loss = self.lossfun(t, y)
reporter.report({'loss': self.loss}, self)
return self.loss
Reporterについて
再びtrainer.runの中身を見てみましょう。学習ループの始まりでwith reporter.scope(self.observation)と宣言しています。この宣言により学習ループ内で呼び出したchainer.reporter.report({'name': value_to_report})の呼び出しはすべてself.observationに格納されるようになります。
def run(self):
....
reporter = self.reporter
stop_trigger = self.stop_trigger
# main training loop
try:
while not stop_trigger(self):
self.observation = {}
with reporter.scope(self.observation):
update()
for name, entry in extensions:
if entry.trigger(self):
entry.extension(self)
reporter.pyを見ると、docに例として以下のようなクラスがあります。
class MyRegressor(chainer.Chain):
def __init__(self, predictor):
super(MyRegressor, self).__init__(predictor=predictor)
def __call__(self, x, y):
# This chain just computes the mean absolute and squared
# errors between the prediction and y.
pred = self.predictor(x)
abs_error = F.sum(F.abs(pred - y)) / len(x.data)
loss = F.mean_squared_error(pred, y)
# Report the mean absolute and squared errors.
report({'abs_error': abs_error, 'squared_error': loss}, self)
return loss
この例の場合、reporterにabs_errorとsquared_errorを送っています。標準出力したい時には
trainer.extend(extensions.PrintReport(['main/abs_error', 'main/squared_error']))
などとすれば良いというわけです。
L.Classifierと上記のMyRegressorの例から、modelの__call__メソッドはpredictorとして定義しておいて、それを使いたい誤差関数と値でラップするクラスを定義するというのが綺麗な実装なのかもしれないです。
僕の求めていたものはこれだった(完)
実装
再びコードを整理すると、以下のようになります。
class MLP(chainer.Chain):
def __init__(self, n_units, n_out):
super(MLP, self).__init__()
with self.init_scope():
self.l1 = L.Linear(None, n_units)
self.l2 = L.Linear(None, n_units)
self.l3 = L.Linear(None, n_out)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
class MyRegressor(chainer.Chain):
def __init__(self, predictor):
super(MyRegressor, self).__init__(predictor=predictor)
def __call__(self, x, y):
pred = self.predictor(x)
loss = F.mean_squared_error(pred, y)
report({'loss': loss}, self)
return loss
学習部分は以下。
def main():
train_size, test_size = 10000, 1000
train_set = chainer.datasets.TupleDataset(
np.random.rand(train_size, 100).astype(np.float32),
np.random.rand(train_size, 10).astype(np.float32)
)
test_set = chainer.datasets.TupleDataset(
np.random.rand(test_size, 100).astype(np.float32),
np.random.rand(test_size, 10).astype(np.float32)
)
batchsize = 500
model = MyRegressor(MLP())
train_iter = iterators.SerialIterator(train_set, batchsize)
test_iter = iterators.SerialIterator(test_set, batchsize, repeat=False, shuffle=False)
optimizer = optimizers.AdaDelta()
optimizer.setup(model)
updater = training.StandardUpdater(train_iter, optimizer)
trainer = training.Trainer(updater, (20, 'epoch'))
trainer.extend(extensions.Evaluator(test_iter, model))
trainer.extend(extensions.dump_graph('main/loss'))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.snapshot(), trigger=(10, 'epoch'))
trainer.extend(extensions.PlotReport(['main/loss', 'validation/main/loss'], file_name='loss.png'))
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss', 'elapsed_time']))
trainer.extend(extensions.ProgressBar())
trainer.run()
動いた!
epoch main/loss validation/main/loss elapsed_time
1 0.111665 0.0918025 0.453329
2 0.0900478 0.0896638 1.24878
3 0.0887397 0.0906177 1.71692
4 0.0902516 0.0878279 2.16807
5 0.0884294 0.0881803 2.61994
6 0.0886923 0.0895866 3.10758
7 0.0865186 0.0874809 3.548
8 0.0859189 0.0875912 3.98337
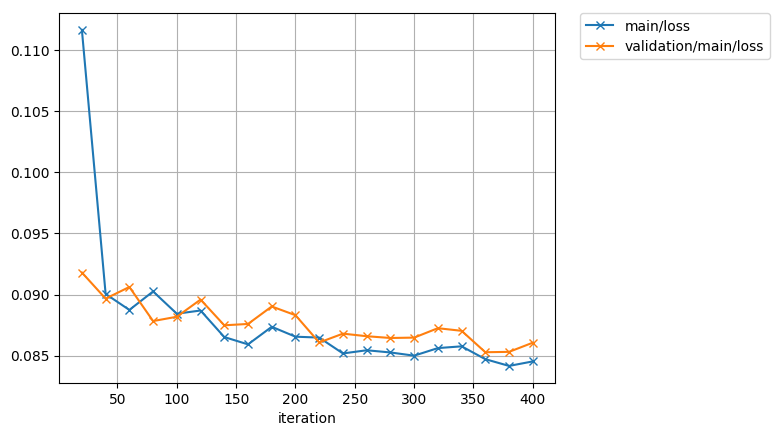
まとめ
- updaterは、iteratorからデータを受け取り、optimizerに
optimizer.updateさせる役割を持つ - updaterのコンストラクタで指定しなければoptimizerにset_upしたmodelの
__call__()がloss関数となりこれの返り値が逆伝播される - extensionsでPlotとかPrintしたければ、reporterにreportする
- modelをpredictorとして定義し、L.Classifierに対応するラッパを作ると良い
- extensionは便利なので、積極的にtrainerを使いましょう