目次
1.はじめに
2.実行環境
3.データ収集と学習準備
4.学習
5.webアプリ作成
6.考察
7.さいごに
8.参考資料
1. はじめに
はじめまして。IT未経験でAidemyのAIアプリ開発講座を受講(3ヶ月)しました。
経歴
・理系大学院卒(農業系)
・農業系メーカーに就職し、生産現場や間接部門に従事
今回、教育訓練給付制度があることを知り、もともと気になっていた本講座を思い切って受講しました。
本ブログは、本講座の卒業課題である成果物です。
さて、今回作成したのは、トマトの葉の画像から病気を判定するwebアプリです。
生産現場では、ハウスの中で栽培している野菜苗を、様々な病害虫から守る対策(エアーシャワー、農薬など)を講じています。
その中で、苗の葉に病斑が発生したものはすぐに除去する必要があり、ハウスの中にある数十万本のなかから、それを見つけ出すのは大変です。
そこで、AIの画像認識によりだれでも簡単に見つけ出せるしくみをつくりたいと思い、特に生産の多いトマトに注目してwebアプリの作成を試みました。
※このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
2. 実行環境
OS Windows10 22H2
Python 3.10.4
google colabolatry
Visiual Studio Code
3. データ収集と学習準備
3-1. 使用したデータ
Kaggleから直接データをローカル環境へダウンロードして、それを用いる方法も考えましたが、google colabのGPUを使えば大きなデータも相当な速度でダウンロードできました。
下記URLを参考に、Kaggleから発行されるjsonファイルをアップロードしてデータセットをダウンロードしました。
3-2. googleドライブをマウント
まずはgoogleDriveにダウンロードしzipファイルを解凍するため、マウントを行って、データのダウンロードを行いました。
コード
from google.colab import drive
drive.mount('/content/drive')
3-3. 学習データとラベルデータを作成
画像データをリサイズし、学習で扱いやすい大きさにしたものを、numpy配列として取得し格納しました。
ラベルはフォルダごとにクラス番号を割り振ったものです。
あとでどの番号かがわかるように、割り振り後の番号とフォルダ名(クラス)を記述しました。
コード
import pandas as pd
import numpy as np
import os
import glob
import cv2
# 学習用データの作成
dirpath = "/content/image data/train/tomato"
classes = []
for dirname in os.listdir(dirpath):
classes.append(dirname)
print(classes)
print("class: ", len(classes))
total = 0
for i in range(len(classes)):
img_list = glob.glob(os.path.join(dirpath, classes[i]) + "/*.JPG")
print(classes[i], ":",len(img_list))
total += len(img_list)
resized_size = (64,64)
X = [] # 画像データ
y = [] # クラス分類。内訳は下記の分類クラス番号参照
for cls in range(len(classes)):
for i in glob.glob(os.path.join(dirpath, classes[cls]) +"/*.JPG"):
img = cv2.imread(i)
img = cv2.resize(img, resized_size)
X.append(img)
y.append(cls)
print("total:", total)
X = np.array(X)
y = np.array(y)
# 配列データをファイルとして保存したい場合
# np.save('/content/~/data_X', X)
# np.save('/content/~/data_y', y)
- 分類クラス
| 病名 | データ数 |
|---|---|
| leaf mold(半身萎ちょう病) | 686 |
| septoria leaf spot(白絹病) | 1276 |
| spider mites two-spotted spider mite(ダニ) | 1208 |
| late blight(円紋病) | 1262 |
| healthy(健康) | 1145 |
| early blight(輪状斑点病) | 720 |
| target spot(斑点病) | 1012 |
| tomato yellow leaf curl virus(黄化葉巻ウィルス病) | 3858 |
| bacterial spot(かいよう病) | 1532 |
| tomato mosaic virus(トマトモザイクウィルス病) | 269 |
| 総計 | 12968 |
トマト病害名参考資料
3-4. 画像データの確認
まずはデータの中身をざっと並べて確認してみました。
以下は画像データのうち、10サンプルを並べたものです。
分類クラスを行ごとに並べています。

4. 学習
4-1.学習モデル
モデル定義、データの水増し、精度評価の順でコードを書いていきました。
VGG16は16層の畳み込みニューラルネットワークで、すでに学習済みのモデルをimagenetというデータベースから読み込みます。
VGG16と特徴量を抽出する自作モデルを連結し、これを学習モデルとして定義しました。
モデルの学習方法を選定するため、最適化アルゴリズムを選定します。
今回はSGD、RMSprop、Adamという代表的な最適化アルゴリズムから、学習精度と損失を評価しました。
エポック数は20、学習率を0.0001で精度および損失比較を行いました。
以下が各アルゴリズムの結果です。
コード
from tensorflow.keras import optimizers
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
import random
random.seed(0)
# X = (X - np.mean(X, axis=(0, 1, 2), keepdims=True)) / np.std(X, axis=(0, 1, 2), keepdims=True)
# データのロード
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# MobileNetのImageNetによる学習済みモデル作成
input_tensor = Input(shape=(64, 64, 3))
learned_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 特徴量抽出部分のモデル作成
top_model = Sequential()
top_model.add(Flatten(input_shape=learned_model.output_shape[1:]))
# h5ファイルサイズを小さくするため256→128に変更
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(len(classes), activation='softmax'))
# vgg16とtop_modelを連結
model = Model(inputs=learned_model.input,
outputs=top_model(learned_model.output))
# 19層目までの重みを固定
for layer in model.layers[:16]:
layer.trainable = False
# モデル構造確認
model.summary()
# コンパイル
lr = 1e-4
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(learning_rate=lr),
metrics=['accuracy'])
# 学習
batch_size = 32 # バッチサイズ
epochs = 20 # エポック数
# データの水増し
params = {
'rotation_range': 20,
'vertical_flip': True,
'horizontal_flip': True,
'featurewise_std_normalization': True,
'zca_whitening': True,
'featurewise_center': True
}
datagen = ImageDataGenerator(**params)
train_generator = datagen.flow(X_train, y_train, batch_size=batch_size)
val_generator = datagen.flow(X_train, y_train)
history = model.fit(train_generator, validation_data=val_generator, batch_size=batch_size, epochs=epochs)
history_df = pd.DataFrame(history.history)
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 精度の評価
scores = model.evaluate(val_generator, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# モデルの保存
model.save("/content/drive/MyDrive/path/to/model.h5")
# モデルサイズの確認(githubでは100MBを超えるファイルのアップロードを制限しているため)
os.path.getsize("/content/drive/MyDrive/path/to/model.h5")/1024**2
SGD

RMSprop

Adam

精度、損失ともにAdam > RMSprop > SGDという結果になりました。
RMSpropとAdamは大きくは精度は変わらないものの、Adamのほうが損失のぶれが抑えられているようです。
今回はAdamを適用して進めていきます。
4-2. 学習モデルを用いた予測
今回の学習モデルを使って実際のデータでの有効性を確かめる為、分類結果が既知のテストデータと、予測結果を用いた精度評価を行いました。
また、各クラスの適合率、再現率、F1-scoreも評価指標としました。
コード
# テストデータで予測し、各分類クラスの誤分類の割合を算出する
y_pred = model.predict(X_test)
y_pred = [y_pred[i].argmax() for i in range(len(y_pred))]
y_t = [y_test[i].argmax() for i in range(len(y_test))]
acc = [p==t for p, t in zip(y_pred,y_t)]
df = pd.DataFrame({'pred': y_pred, 'test': y_t, 'bool': acc})
# 誤分類結果をクロス集計する
cross = pd.crosstab(index=df['pred'], columns=df['test']).apply(lambda r: r/r.sum(), axis=1)
# クロス集計表をヒートマップにして可視化する
import seaborn as sns
sns.heatmap(cross, cmap='Reds', annot=True, fmt="0.2f")
for i in range(len(classes)):
img_list = glob.glob(os.path.join(dirpath, classes[i]) + "/*.JPG")
print(i, ":", classes[i], "…", len(img_list))
# plt.savefig("/content/drive/MyDrive/misclassification_heatmap.jpg")
# 各クラスの適合率(pred_score)、再現率(recall_score)、F値(F1_score)
for i in range(len(classes)):
pred_score = cross.iloc[i, i] / sum(cross.iloc[i, :])
recall = cross.iloc[i, i] / sum(cross.iloc[:, i])
f1 = 2 * pred_score * recall / (pred_score + recall)
print("---", pred_class, "---")
print("適合率:", f"{pred_score*100:.2f}%")
print("再現率:", f"{recall*100:.2f}%")
print("F値:", f"{f1*100:.2f}%")

| クラス | 病名(英語) | 病名(日本語) | 適合率 | 再現率 | F値 |
|---|---|---|---|---|---|
| 0 | healthy | 健康 | 98.77% | 97.11% | 97.94% |
| 1 | septorialeafspot | 白絹病 | 74.19% | 93.01% | 82.54% |
| 2 | leafmold | 半身萎ちょう病 | 89.39% | 90.94% | 90.16% |
| 3 | bacterialspot | かいよう病 | 95.52% | 86.06% | 90.54% |
| 4 | targetspot | 斑点病 | 83.45% | 86.35% | 84.88% |
| 5 | lateblight | 円紋病 | 93.81% | 82.29% | 87.67% |
| 6 | spidermitestwo-spottedspidermite | ダニ | 82.68% | 86.94% | 84.76% |
| 7 | tomatomosaicvirus | トマトモザイクウィルス病 | 77.78% | 100% | 87.5% |
| 8 | tomatoyellowleafcurlvirus | 黄化葉巻ウィルス病 | 99.56% | 77.09% | 86.9% |
| 9 | earlyblight | 輪状斑点病 | 79.33% | 82.14% | 80.71% |
いずれのクラスでも90%程度の高い値を出しました。
精度評価に関する参考資料
https://zenn.dev/hellorusk/articles/46734584386c49057e1b
5. webアプリ作成
pythonのwebフレームワークの一つであるflaskで、簡易的な画像分類用webアプリを作成しました。
また、web上への公開はRenderで設定しました。
5-1. ディレクトリ構造
flaskr
├─static
│ ├─stylesheet.css
│ └─uploads
└─templates
│ └─index.html
├─main.py
└─model.h5
5-2. コード
コード(Python)
# coding: utf_8
import os
from flask import Flask, request, redirect, render_template, flash, url_for
from werkzeug.utils import secure_filename
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ['healthy', 'septoria leaf spot', 'leaf mold', 'bacterial spot', 'target spot', 'late blight', 'spider mites two-spotted spider mite', 'tomato mosaic virus', 'tomato yellow leaf curl virus', 'early blight']
UPLOAD_FOLDER = "uploads"
# UPLOAD_FOLDER = os.path.join(UPLOAD_IMG)
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif', 'JPG', 'PNG'])
app = Flask(__name__)
# app.config["UPLOAD_FOLDER"] = UPLOAD_FOLDER
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5', compile=False)#学習済みモデルをロード
resized_size = 64
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, target_size=(resized_size, resized_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)
predicted = result[0].argmax()
pred_answer = "これは " + classes[predicted] + " です。"
result = [i for i in result]
return render_template("index.html",
answer=pred_answer,
img_path="ファイル名: " + filename,
pred_result=zip(classes, np.round(result[0]*100, 2)),
)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
コード(HTML)
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>トマトの病気判別します</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">トマトの病気判別します</a>
</header>
<div class="main">
<h2> AIが送信されたトマト画像の病気を識別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer_img">
<p>{{img_path}}</p>
</div>
<div class="answer">
{{answer}}
{% if answer %}
<table class="table_center">
<tr>
<th>class name</th>
<th>prediction rate</th>
</tr>
{% for class_name, rate in pred_result %}
<tr>
<th class="rate_result">{{class_name}}</td>
<td class="rate_result">{{rate}}%</td>
</tr>
{% endfor %}
</table>
{% endif %}
</div>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>
コード(CSS)
header {
background-color: #76B55B;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
/* height: 370px; */
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer_img {
margin-top: 30px;
text-align: center;
}
.answer {
color: #444444;
margin: 30px 0px 30px 0px;
text-align: center;
}
.table_center {
margin: auto;
}
form {
text-align: center;
}
table {
border-collapse: collapse;
border: 2px solid rgb(200, 200, 200);
letter-spacing: 1px;
font-family: sans-serif;
font-size: 0.8rem;
}
td,
th {
border: 1px solid rgb(104, 94, 94);
padding: 5px 10px;
}
td {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
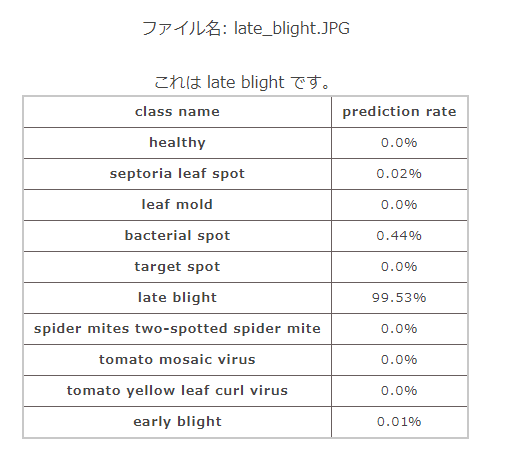


正しく出力できました。
しかし、あの高い精度でも正しく分類できない場合もありました。




6. 考察
人でもこれがどの病気にあたるかを判断するのは非常に難しく、特に葉が黄化する症状は比較的どの病気でも発生しうる兆候のため、病害虫の特定には遺伝子解析や、化学的手法を用いることもあります。
ただ、実際の生産現場では毎度そのようなことはやってられないことのほうが多く、多少の発生であれば、おおよその原因をつきとめ(細菌か、虫か…)、それに応じて殺菌剤や殺虫剤を散布し防除することのほうが多いようです。
また、今回掲載していませんが、web上から拾った別の画像を当てた場合、誤判定が発生することが多かったです。
学習するデータのバラエティーや色調の範囲を広げるなどの工夫が必要であると思います。
実際の現場で使う際は、葉を採取せず、生きた状態で撮影することのほうが多いため、植物体全体で学習モデルデータセットを作成し、より汎用性の高いモデルを作ることを今後の展望としていきたいと思います。
7. さいごに
Aidemyではslackを使ってチューターの方々とやりとりしたり、バーチャル学習室でいつでも簡単な質問や相談ができる環境を提供していただけます。
また、選択した講座だけでなく、他の講座も受けることができる学び放題プランもあるので、早く学習を終えた人は他のAIに関する学習も可能です。
さらに、特に私が良いと感じたところは、他の受講者の方々や実際の現場で働く方々とのオンライン座談会や見学会、勉強会が定期的に開催されていることです。
オンラインの為、どうしても学習に対して孤独になりがちなところを、そういった場を設けていただけるのは、モチベーション維持につながります。
私は在職の職場が理解ある会社だったため、業務時間の一部を学習時間に割いててもいいように配慮いただいたのもあり、一人でコツコツと進められましたが、このようなコミュニティがあるのとないのとでは、おそらく今くらいのモチベーション維持はできなかったかと思います。
予定より早く卒業制作を進められたので、残りの時間は、画像認識スキルをブラッシュアップするか、データ分析や自然言語処理にもチャレンジしてみたいと思います。
8. 参考資料
Renderにアップロードした際、Adamがunknownとなったので、load_modelの際、compile=Falseとしました。