KaggleでGBDTを使う際のTips。
高速化の方法
1. データをpd.DataFrameではなくnp.ndarrayで渡す
これだけでも早くなる。
X = ... # pandas DataFrame
pred = model.predict(X) # そのまま渡す
pred = model.predict(X.values) # np.ndarrayにして渡す、こっちの方が早い
2. Treelite
Treelite — Treelite 4.0.0-dev documentation
Treeliteは、C++アプリケーション上でツリーベースモデルを共通のフォーマットで利用するためのツール。モデルをTreelite形式に変換することで、推論が早くなる効果も得られる。
import treelite
import treelite_runtime
bst = lightgbm.train(params, dtrain, 10, valid_sets=[dtrain], valid_names=['train'])
model = treelite.Model.from_lightgbm(bst)
X = ... # numpy array
pred = treelite.gtil.predict(model, data=X)
LightGBM以外にもXGBoostやsklearnもサポートされている(ドキュメント見る限りではCatBoostはなさそう)。
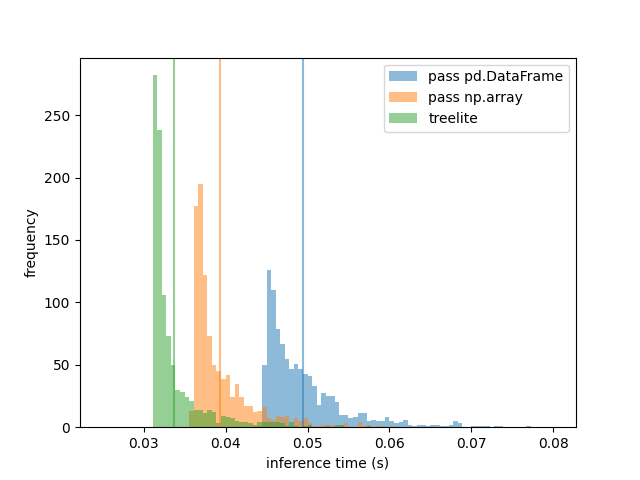
検証
適当なテストデータに対してLightGBMで1000回ずつ推論を行った際の推論時間の比較(ガイド線は平均値)。Treelite、np.ndarrayで渡す、pd.DataFrameで渡す、の順で早くなっている。