なにこれ?
単眼Depth推定をWebアプリで認識できる簡単なツールです。
エンジニアじゃない人でも簡単に認識器を試してもらえるようにエイヤで作ってみました!
改造すればいろいろ拡張できるかな~と思います。
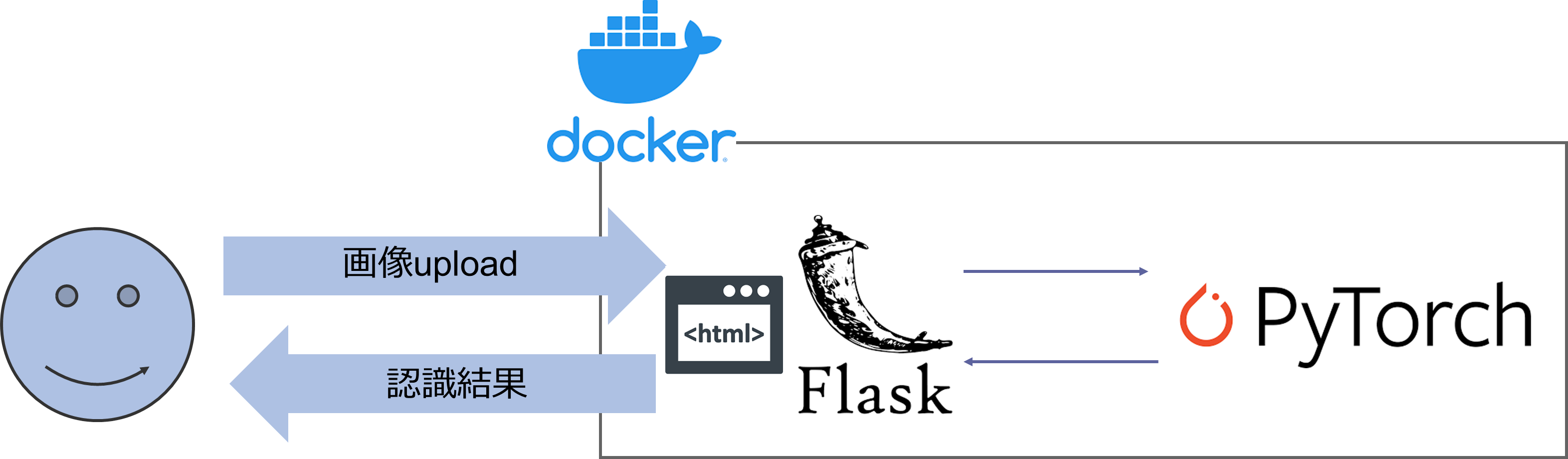
どうやってるの?
dockerでサーバーを立ててます。
フロントエンドはflask、バックエンドはpytorchです。
動作環境
- OS: Ubuntu PC 18
- GPU: GTX 3090
ソースコード ツリー構成
こんな感じのツリーで作成していきます。
各ソースコードは下の方にすべて記載してます。
├── app.py
├── docker
│ ├── Dockerfile
│ └── build.sh
├── results
│ └── <ここに認識結果のデータを格納します。>
├── run_docker.sh
├── run_server.sh
├── src
│ ├── configs.py
│ ├── dnn
│ │ └── MiDaS.py
│ └── recognizer.py
├── static
│ └── <ここにアップロードされた画像が格納されます>
└── templates
└── index.html
使い方はこんな感じになります。
- ./run_docker.shでdocker起動。
- ./run_server.sh [GPU No]で起動。
- ブラウザで44444にアクセス。
参考にしたHP
ソースコードすべて(gitにアップしなくてごめんなさい。。)
- こだわり:
- いろんな認識器を差し替えられるように拡張性を持たせてます。
- configの値を変えると、モデルを差し替えられるようにしています。
- recognizer classで、MiDaSのモデルをロードしています。
- MODELをtestにすると、ただのグレースケール化する処理が走ります。
- ラジオボタンでセグメンテーションに切り替えられるようにとかしたいなぁ
app.py
from flask import Flask, request, redirect, url_for,flash, render_template
from flask import send_from_directory
from werkzeug.utils import secure_filename
import os
import argparse
from src.configs import configs
from src.recognizer import recognizer_class
######
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = configs.UPLOAD_FOLDER
recognizerClass = recognizer_class(configs.MODEL , configs)
######
def allwed_file(filename):
# .があるかどうかのチェックと、拡張子の確認
# OKなら1、だめなら0
return '.' in filename and filename.rsplit('.', 1)[1].lower() in configs.ALLOWED_EXTENSIONS
#####
@app.route('/', methods=['GET', 'POST'])
def uploads_file():
# リクエストがポストかどうかの判別
if request.method == 'GET':
return render_template("index.html")
elif request.method == 'POST':
# ファイルがなかった場合の処理
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
# データの取り出し
file = request.files['file']
# ファイル名がなかった時の処理
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
# ファイルのチェック
if file and allwed_file(file.filename):
# 危険な文字を削除(サニタイズ処理)
filename = secure_filename(file.filename)
filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)
# ファイルの保存
file.save(filepath)
# 認識
resultpath = recognizerClass.recognize(filepath)
# アップロード後のページに転送
return render_template("index.html", filepath=filepath, resultpath=resultpath, result =True)
####
@app.route('/results/<filename>')
# ファイルを表示する
def uploaded_file(filename):
return send_from_directory(configs.RESULTS_FOLDER, filename)
####
if __name__ == "__main__":
if not os.path.exists("static"):
os.makedirs("static")
if not os.path.exists("results"):
os.makedirs("results")
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', '-g', default=0, type=int,
help='GPU ID (negative value indicates CPU)')
args = parser.parse_args()
if args.gpu==-2:
multigpuFlag=True
else:
os.environ["CUDA_VISIBLE_DEVICES"] = str(args.gpu)
app.run(host="0.0.0.0", port=5000, debug=True)
templates/index.html
<html>
<head>
<meta charset="utf-8">
<title>flask recognizer</title>
</head>
<body>
<h1>
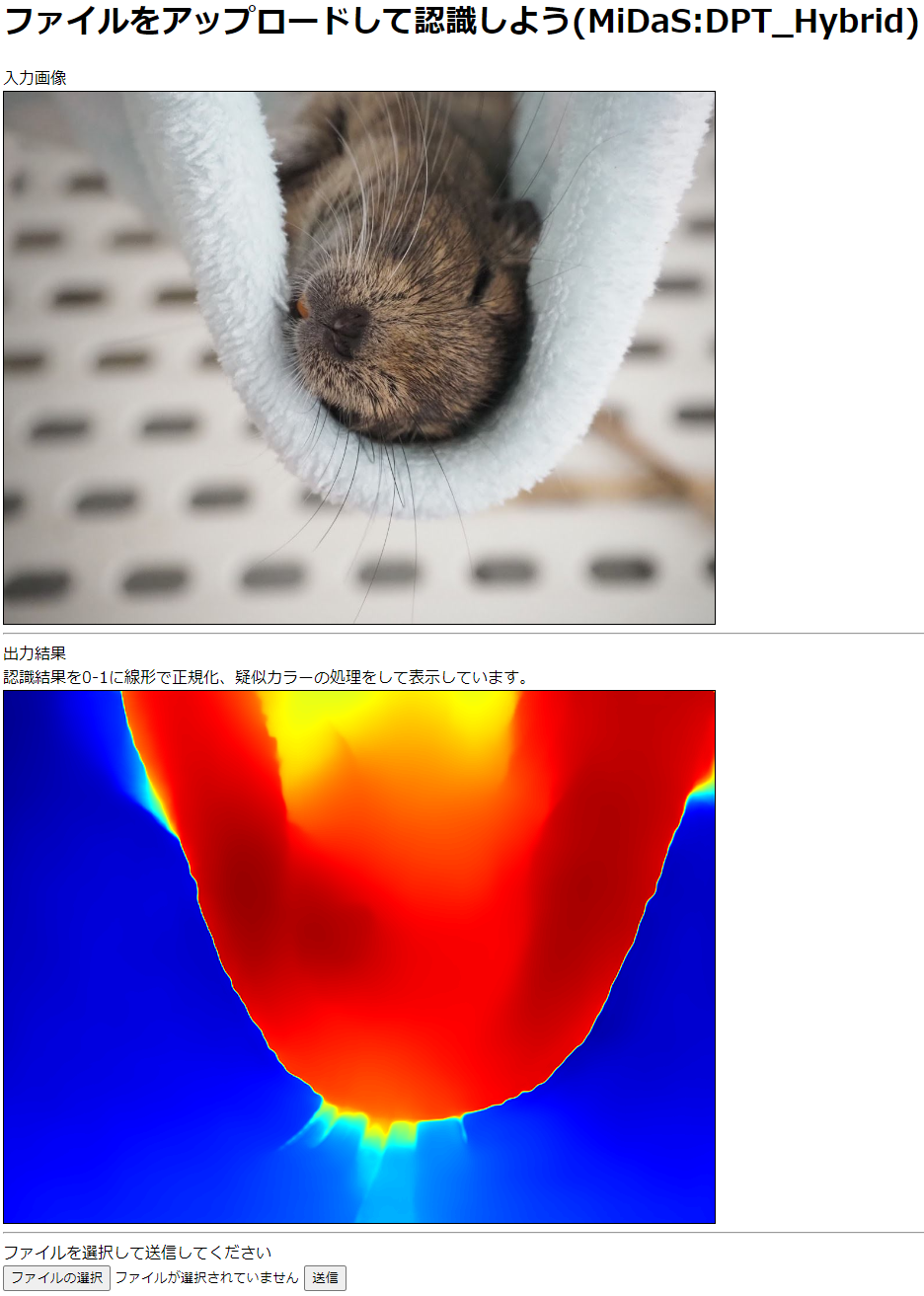
ファイルをアップロードして認識しよう(MiDaS:DPT_Hybrid)
</h1>
Created by sugupoko
<BR>
{% if result %}
入力画像 <BR>
<IMG SRC="{{filepath}} " BORDER="1"> <BR>
<HR>
出力結果 <BR>
認識結果を0-1に線形で正規化、疑似カラーの処理をして表示しています。<BR>
<IMG SRC="{{resultpath}} " BORDER="1"> <BR>
<HR>
{% endif %}
ファイルを選択して送信してください<BR>
<form action = "./" method = "POST" enctype = "multipart/form-data">
<input type = "file" name = "file" />
<input type = "submit"/>
</form>
</body>
</html>
src/config.py
class configs():
#PATH ===============
ROOT="./"
MODEL = "MiDaS"
# 画像のアップロード先のディレクトリ
UPLOAD_FOLDER = ROOT + 'static/'
# 結果が収納される場所
RESULTS_FOLDER = ROOT + "results/"
# HTMLの場所(デフォルト変更するには、要調査)
HTML_FOLDER = ROOT + 'templates/'
# アップロードされる拡張子の制限
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'gif'])
src/recognizer.py
import os
import cv2
from src.dnn.MiDaS import MiDaS
class recognizer_class:
def __init__(self,mode, configs):
print("init ==================================")
self.mode = mode
self.configs = configs
if self.mode == "MiDaS":
print("run MiDaS")
self.model_class = MiDaS()
self.func = self.model_class.run
elif self.mode == "test":
print("run test")
self.func = eval("rgb2gray")
def __del__(self):
print("del class ==================================")
def some_function(self):
print(self.mode)
def recognize(self, filepath):
filename = os.path.basename(filepath)
resultpath = os.path.join(self.configs.RESULTS_FOLDER, filename)
img = cv2.imread(filepath)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_out = self.func(img)
cv2.imwrite(resultpath, img_out)
return resultpath
def rgb2gray(image):
img_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return img_gray
src/dnn/MiDaS.py
from glob import glob
from PIL import Image
import numpy as np
from torchvision import transforms
import torch
import timm
import cv2
class MiDaS:
def __init__(self):
self.model_type = "DPT_Hybrid"
self.model = torch.hub.load("intel-isl/MiDaS", self.model_type)
self.device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
self.model.to(self.device)
self.model.eval()
midas_transforms = torch.hub.load("intel-isl/MiDaS", "transforms")
if self.model_type == "DPT_Large" or self.model_type == "DPT_Hybrid":
self.transform = midas_transforms.dpt_transform
else:
self.transform = midas_transforms.small_transform
def __del__(self):
print("del")
def run(self, input_image):
input_batch = self.transform(input_image).to(self.device)
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
self.model.to('cuda')
with torch.no_grad():
prediction = self.model(input_batch)
prediction = torch.nn.functional.interpolate(
prediction.unsqueeze(1),
size=input_image.shape[:2],
mode="bicubic",
align_corners=False,
).squeeze()
result = prediction.cpu().numpy()
result = normalize_depth(result, bits=1)
result = cv2.applyColorMap(result, cv2.COLORMAP_JET)
del prediction, input_batch
return result
def normalize_depth(depth, bits):
depth_min = depth.min()
depth_max = depth.max()
max_val = (2**(8*bits))-1
if depth_max - depth_min > np.finfo("float").eps:
out = max_val * (depth - depth_min) / (depth_max - depth_min)
else:
out = np.zeros(depth.shape, dtype=depth.type)
if bits == 1:
return out.astype("uint8")
elif bits == 2:
return out.astype("uint16")
docker/Dockerfile
FROM nvidia/cuda:11.4.2-cudnn8-devel-ubuntu20.04
ARG use_cudnn=1
ENV DEBIAN_FRONTEND=noninteractive
ENV HOME=/root \
DEBIAN_FRONTEND=noninteractive \
LANG=ja_JP.UTF-8 \
LC_ALL=${LANG} \
LANGUAGE=${LANG} \
TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && \
echo $TZ > /etc/timezone
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
sudo \
cmake \
git \
wget \
libatlas-base-dev \
libboost-all-dev \
libgflags-dev \
libgoogle-glog-dev \
libhdf5-serial-dev \
libleveldb-dev \
liblmdb-dev \
libprotobuf-dev \
libsnappy-dev \
protobuf-compiler \
python3-dev \
python3-pip \
python3-setuptools \
python3-tk \
python3-matplotlib \
less \
aptitude \
software-properties-common \
ssh \
unzip \
qt5-default \
qttools5-dev-tools \
libqt5widgets5 \
glew-utils \
libglew-dev \
libglm-dev \
tcsh \
aptitude \
freeglut3-dev \
libqt5opengl5-dev \
libcanberra-gtk-dev \
libcanberra-gtk-module \
libgtest-dev \
emacs \
spyder \
valgrind && \
rm -rf /var/lib/apt/lists/*
# cmake
RUN pip3 install numpy==1.18.2
RUN pip3 install pillow==7.1.1 ipython==7.13.0 matplotlib==1.5.1
WORKDIR /workspace
# for python profiling
RUN pip3 install line_profiler==3.0.2 && \
pip3 install pyprof2calltree==1.4.4
RUN pip3 install scipy==1.4.1
RUN pip3 install --upgrade pip==20.0.2 setuptools==46.1.3
RUN pip3 install tensorflow-gpu==2.7.0
RUN pip3 install keras==2.7.0
RUN pip3 install opencv-python
RUN pip3 install opencv-contrib-python
RUN pip install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio===0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
RUN pip install pandas
RUN pip install tqdm
RUN pip install albumentations
RUN pip install sklearn
RUN pip install seaborn
RUN pip install tensorboard
RUN pip install hydra-core
RUN pip install tensorflow-model-optimization
RUN pip install timm
# ===============================================================
WORKDIR /app
RUN pip install Flask
docker/build.sh
nvidia-docker build --no-cache -t flask_dnn .
run_docker.sh
# !/bin/bash
SCRIPT_DIR=$(cd $(dirname $0); pwd)
DOCKSHARE=${SCRIPT_DIR}
DOCKIMG="flask_dnn:latest"
INITDIR="/home/dockshare"
docker run -it --runtime=nvidia \
-p 44444:5000 \
-w ${INITDIR} --rm - \
-v ${DOCKSHARE}:${INITDIR} ${DOCKIMG} bash
run_server.sh
if [ $# -ne 1 ]; then
echo "usage $0 [GPU_ID]"
exit 1
fi
GPU_ID=$1
if [ $GPU_ID != -2 ]; then
echo "GPU : $GPU_ID"
export CUDA_VISIBLE_DEVICES=$GPU_ID
else
echo "multi GPU train"
fi
python3 ./app.py -g $GPU_ID