2017年に発表された強化学習のアルゴリズム「PPO」を実装しながら、解説します。
PPO(Proximal Policy Optimization) は、openAIから発表された強化学習手法です。
●Proximal Policy Optimization - OpenAI Blog
Proximalは日本語にすると、「近位」という意味です。
本記事では、PPOを解説したのちに、CartPoleでの実装コードを紹介します。
※171115
tarutoさまにお気づきいただき、AgentクラスのAct関数を修正いたしました。
※180726
ykamikawaさまにお気づきいただき、minをAdvantage関数ではなく、lossに実行していたのを修正いたしました。
※180727
God_KonaBananaさまにお気づきいただき、clip部分のコード、entropyの符号を修正いたしました。
PPOアルゴリズム解説
PPOは、A3CとTRPO(Trust Region Policy Optimization)を発展させて、作られています。
そのため、まずはこの二つを理解する必要があります。
A3Cについては前回の記事で紹介していますので、こちらをご覧ください。
●【強化学習】実装しながら学ぶA3C【CartPoleで棒立て:1ファイルで完結】
TRPOについて、紹介します。
これまでの勾配法の式が以下となります。
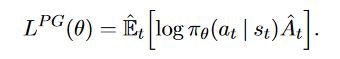
この式で困っていたのが、方策π(a|s)が更新時に、ときおり大きく変化して変になってしまうことでした。
CartPoleで例えれば、右に押すのが良い確率p(右|s)が0.3だったのに、一度の更新でp(右|s)が0.9になってしまう、というイメージです。
そこで、2015年にTRPO(Trust Region Policy Optimization) が提案されました。
Trust Regionという名前の通り、信頼のできる範囲内で方策を更新する手法です。
式では以下のように書かれます。
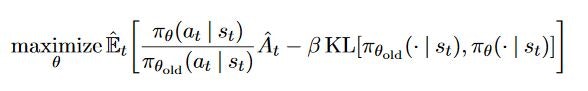
KLはカルバックライブラーダイバージェンスです。
更新前のπ_oldと、更新後のπの「変化の大きさ」を測る関数です。
罰則項にKLを与えることで、突然方策が大きく変化するのを防いでいます。
TRPOの解説としては、こちらもおすすめです。
●Trust Region Policy Optimization (日本語)
ですが、TRPOは
- 実装が複雑
- ドロップアウト手法がつかえない
- Actor-Criticに適応できない
という問題がありました。
それらを改善するために提案されたのが、PPOです。
PPOは以下の式で書かれます。

要は、r_t = π / π_old が小さすぎるときは1-εにし、大きすぎるときは1+εにし、この範囲内にr_tをクリッピングしてあげることで、方策が大きく変化するのを防ぐというアイデアです。
PPO実装方法の解説
今回は前回作成したA3Cのプログラムを流用して作成しているので、A3Cの記事を先にご覧ください。
主に大きな差分のみを解説します。
メイン関数
メイン関数を紹介します。
A3Cのときとまったく同じです。
ここでは、TensorFlowをマルチスレッドで実行します。
メイン関数はほとんどTensorFlowでマルチスレッドを走らせるときのお手本コード通りです。
Worker_threadクラスを生成し、同時に走らせています。
スレッドは、training用のスレッド複数個と、学習後に実行されるtestスレッド1つがあります
学習とテストはファイルを分割し、学習後のパラメータを保存し、別ファイルで読み込んで走らせる方が実用的ですが、今回はスレッドを2種類用意し、学習とテストをひとつのファイルで実行します。
# -- main ここからメイン関数です------------------------------
# M0.global変数の定義と、セッションの開始です
frames = 0 # 全スレッドで共有して使用する総ステップ数
isLearned = False # 学習が終了したことを示すフラグ
SESS = tf.Session() # TensorFlowのセッション開始
# M1.スレッドを作成します
with tf.device("/cpu:0"):
brain = Brain() # ディープニューラルネットワークのクラスです
threads = [] # 並列して走るスレッド
# 学習するスレッドを用意
for i in range(N_WORKERS):
thread_name = "local_thread"+str(i+1)
threads.append(Worker_thread(thread_name=thread_name, thread_type="learning", brain=brain))
# 学習後にテストで走るスレッドを用意
threads.append(Worker_thread(thread_name="test_thread", thread_type="test", brain=brain))
# M2.TensorFlowでマルチスレッドを実行します
COORD = tf.train.Coordinator() # TensorFlowでマルチスレッドにするための準備です
SESS.run(tf.global_variables_initializer()) # TensorFlowを使う場合、最初に変数初期化をして、実行します
running_threads = []
for worker in threads:
job = lambda: worker.run() # この辺は、マルチスレッドを走らせる作法だと思って良い
t = threading.Thread(target=job)
t.start()
#running_threads.append(t)
# M3.スレッドの終了を合わせます
# COORD.join(running_threads)
Worker_Thread
ローカルスレッドです。
ここもA3Cとまったく同じです。
メンバ変数として、Environmentを持ちます。
またthread_typeはlearnigかtestで、学習用スレッドか学習後に使用するテストスレッドかを指定します。
run関数の内容が分かりにくいですが、学習が終わるまではlearningスレッドを走らせ、テストスレッドはスリープさせておきます。
学習後は、learningスレッドはスリープさせ、testスレッドを走らせています。
# --スレッドになるクラスです -------
class Worker_thread:
# スレッドは学習環境environmentを持ちます
def __init__(self, thread_name, thread_type, brain):
self.environment = Environment(thread_name, thread_type, brain)
self.thread_type = thread_type
def run(self):
while True:
if not(isLearned) and self.thread_type is 'learning': # learning threadが走る
self.environment.run()
if not(isLearned) and self.thread_type is 'test': # test threadを止めておく
time.sleep(1.0)
if isLearned and self.thread_type is 'learning': # learning threadを止めておく
time.sleep(3.0)
if isLearned and self.thread_type is 'test': # test threadが走る
time.sleep(3.0)
self.environment.run()
Environment
次に、Envrionmentクラスを紹介します。
ここから少しA3Cと異なります。
Environmentは、メンバ変数にAgentクラスを持ちます。
メソッドはrun()だけです。
CartPoleを1試行実行します。
A3Cと同じく複数のAgentが実行されますが、PPOで異なるのは、各Agentは独自のネットワークを持たず、共有したネットワークのみが存在します。
そのためA3Cよりも簡単に実装することができます。
# --CartPoleを実行する環境です、TensorFlowのスレッドになります -------
class Environment:
total_reward_vec = np.zeros(10) # 総報酬を10試行分格納して、平均総報酬をもとめる
count_trial_each_thread = 0 # 各環境の試行数
def __init__(self, name, thread_type, brain):
self.name = name
self.thread_type = thread_type
self.env = gym.make(ENV)
self.agent = Agent(brain) # 環境内で行動するagentを生成
def run(self):
global frames # セッション全体での試行数、global変数を書き換える場合は、関数内でglobal宣言が必要です
global isLearned
if (self.thread_type is 'test') and (self.count_trial_each_thread == 0):
self.env.reset()
#self.env = gym.wrappers.Monitor(self.env, './movie/PPO') # 動画保存する場合
s = self.env.reset()
R = 0
step = 0
while True:
if self.thread_type is 'test':
self.env.render() # 学習後のテストでは描画する
time.sleep(0.1)
a = self.agent.act(s) # 行動を決定
s_, r, done, info = self.env.step(a) # 行動を実施
step += 1
frames += 1 # セッショントータルの行動回数をひとつ増やします
r = 0
if done: # terminal state
s_ = None
if step < 199:
r = -1
else:
r = 1
# 報酬と経験を、Brainにプッシュ
self.agent.advantage_push_brain(s, a, r, s_)
s = s_
R += r
if done or (frames % Tmax == 0): # 終了時がTmaxごとに、parameterServerの重みを更新
if not(isLearned) and self.thread_type is 'learning':
self.agent.brain.update_parameter_server()
if done:
self.total_reward_vec = np.hstack((self.total_reward_vec[1:], step)) # トータル報酬の古いのを破棄して最新10個を保持
self.count_trial_each_thread += 1 # このスレッドの総試行回数を増やす
break
# 総試行数、スレッド名、今回の報酬を出力
print("スレッド:"+self.name + "、試行数:"+str(self.count_trial_each_thread) + "、今回のステップ:" + str(step)+"、平均ステップ:"+str(self.total_reward_vec.mean()))
# スレッドで平均報酬が一定を越えたら終了
if self.total_reward_vec.mean() > 199:
isLearned = True
time.sleep(2.0) # この間に他のlearningスレッドが止まります
Agent
AgentクラスはA3Cとほぼ同じです。
メンバ変数に共有ネットワーククラスのBrainと、メモリを持ちます。
メモリはAdvantageを考慮した、(s, a, r, s_)を格納します。
act()メソッドはε-greedy法でランダム行動と、最適行動を選択します。
最適行動は共有されたBrainのネットワークから求めます。
advantage_push_local_brain()メソッドは、メモリをBrainのキューに格納します。
このときにAdvantageを考慮した計算を行います。
工夫点は、
・行動aはone-hotcoding(もし選択肢が3つあって、2つ目なら、[0,1,0]の形)にしています
・nステップ分の割引総報酬self.Rを計算する際に、前ステップの結果を利用して計算しています(ヤロミルさんのサイト参照)
# --行動を決定するクラスです、CartPoleであれば、棒付き台車そのものになります -------
class Agent:
def __init__(self, brain):
self.brain = brain # 行動を決定するための脳(ニューラルネットワーク)
self.memory = [] # s,a,r,s_の保存メモリ、 used for n_step return
self.R = 0. # 時間割引した、「いまからNステップ分あとまで」の総報酬R
def act(self, s):
if frames >= EPS_STEPS: # ε-greedy法で行動を決定します 171115修正
eps = EPS_END
else:
eps = EPS_START + frames * (EPS_END - EPS_START) / EPS_STEPS # linearly interpolate
if random.random() < eps:
return random.randint(0, NUM_ACTIONS - 1) # ランダムに行動
else:
s = np.array([s])
p = self.brain.predict_p(s)
a = np.random.choice(NUM_ACTIONS, p=p[0])
return a
def advantage_push_brain(self, s, a, r, s_): # advantageを考慮したs,a,r,s_をbrainに与える
def get_sample(memory, n): # advantageを考慮し、メモリからnステップ後の状態とnステップ後までのRを取得する関数
s, a, _, _ = memory[0]
_, _, _, s_ = memory[n - 1]
return s, a, self.R, s_
# one-hotコーディングにしたa_catsをつくり、、s,a_cats,r,s_を自分のメモリに追加
a_cats = np.zeros(NUM_ACTIONS) # turn action into one-hot representation
a_cats[a] = 1
self.memory.append((s, a_cats, r, s_))
# 前ステップの「時間割引Nステップ分の総報酬R」を使用して、現ステップのRを計算
self.R = (self.R + r * GAMMA_N) / GAMMA # r0はあとで引き算している、この式はヤロミルさんのサイトを参照
# advantageを考慮しながら、LocalBrainに経験を入力する
if s_ is None:
while len(self.memory) > 0:
n = len(self.memory)
s, a, r, s_ = get_sample(self.memory, n)
self.brain.train_push(s, a, r, s_)
self.R = (self.R - self.memory[0][2]) / GAMMA
self.memory.pop(0)
self.R = 0 # 次の試行に向けて0にしておく
if len(self.memory) >= N_STEP_RETURN:
s, a, r, s_ = get_sample(self.memory, N_STEP_RETURN)
self.brain.train_push(s, a, r, s_)
self.R = self.R - self.memory[0][2] # # r0を引き算
self.memory.pop(0)
Brain
最後に共有されたニューラルネットワークであるBrainクラスについて説明します。
ボリュームが多くて大変ですが、PPOの中心となるクラスです。
build_model()はA3Cと同じくActor-Criticのニューラルネットワークを定義しています。
前回のA3Cと形も同じです。
model._make_predict_function() # have to initialize before threading
で、その後のメソッドが定義できる状態にします。
_build_graph()はこのネットワークに対して実行する様々なメソッドを定義している部分です。
まず、loss関数を定義しています。
PPOで提案されたCLIP損失関数をここで実装しています。
# 180726_ykamikawaさんより、Advantageをminとらないといけないのに、lossでminとっているという指摘を受けての修正
# loss関数を定義します
# advantage = tf.subtract(self.r_t , v)
# self.prob = tf.multiply(p, self.a_t) + 1e-10
# r_theta = tf.div(self.prob , self.prob_old)
# loss_CPI = -tf.multiply(r_theta , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# CLIPした場合を計算して、小さい方を使用します。
# r_clip = r_theta
# tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
# clipped_loss_CPI = -tf.multiply(r_clip , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# loss_CLIP = tf.reduce_mean(tf.minimum(loss_CPI, clipped_loss_CPI), axis=1, keep_dims=True)
# loss関数を定義します
advantage = tf.subtract(self.r_t , v)
self.prob = tf.multiply(p, self.a_t) + 1e-10
r_theta = tf.div(self.prob , self.prob_old)
advantage_CPI = tf.multiply(r_theta , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# CLIPした場合を計算して、小さい方を使用します。
r_clip = r_theta
# 180727_God_KonaBananaさんより代入忘れのご指摘いただき修正
#tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
r_clip=tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
clipped_advantage_CPI = tf.multiply(r_clip , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
loss_CLIP = -tf.reduce_mean(tf.minimum(advantage_CPI, clipped_advantage_CPI), axis=1, keep_dims=True)
CLIP損失関数以外に、価値関数Vの誤差と、エントロピー項があるのはA3Cと同じです。
また損失関数の更新方法はAdamを使用しています。
A3Cの場合はRMSPropでしたが、PPOではAdamが推奨されています。
update_parameter_serverメソッドで、キューに蓄えた(s, a, r, s_)からNステップアドバンテージの価値を計算し、損失関数を小さくする方向にネットワークのパラメータを更新しています。
PPOでは価値の計算に、GAE(generalized advantage estimator)を使用します。
GAEでは以下の式でアドバンテージ関数A()を求めます。
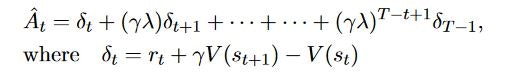
これは、λの値が0だと1step先まで考慮するアドバンテージのない計算になり、λ=1だと、通常のアドバンテージ計算になります。
GAEは一度実装するとλを変えるだけで、アドバンテージの考慮具合を変更できるため、generalized という名前がついています。
PPOの論文だとλ=0.95が使われていましたが、面倒なので、A3Cのアドバンテージ関数(つまりλ=1の場合)をそのまま使用しています。
# --各スレッドで共有するTensorFlowのDeep Neural Networkのクラスです -------
class Brain:
def __init__(self): # globalなparameter_serverをメンバ変数として持つ
with tf.name_scope("brain"):
self.train_queue = [[], [], [], [], []] # s, a, r, s', s' terminal mask
K.set_session(SESS)
self.model = self._build_model() # ニューラルネットワークの形を決定
self.opt = tf.train.AdamOptimizer(learning_rate=LEARNING_RATE) # loss関数を最小化していくoptimizerの定義です
self.prob_old = 1
self.graph = self.build_graph() # ネットワークの学習やメソッドを定義
def _build_model(self): # Kerasでネットワークの形を定義します
l_input = Input(batch_shape=(None, NUM_STATES))
l_dense = Dense(16, activation='relu')(l_input)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense)
out_value = Dense(1, activation='linear')(l_dense)
model = Model(inputs=[l_input], outputs=[out_actions, out_value])
model._make_predict_function() # have to initialize before threading
plot_model(model, to_file='PPO.png', show_shapes=True) # Qネットワークの可視化
return model
def build_graph(self): # TensorFlowでネットワークの重みをどう学習させるのかを定義します
self.s_t = tf.placeholder(tf.float32, shape=(None, NUM_STATES)) # placeholderは変数が格納される予定地となります
self.a_t = tf.placeholder(tf.float32, shape=(None, NUM_ACTIONS))
self.r_t = tf.placeholder(tf.float32, shape=(None, 1)) # not immediate, but discounted n step reward
p, v = self.model(self.s_t)
# 180726_ykamikawaさんより、Advantageをminとらないといけないのに、lossでminとっているという指摘を受けての修正
# loss関数を定義します
# advantage = tf.subtract(self.r_t , v)
# self.prob = tf.multiply(p, self.a_t) + 1e-10
# r_theta = tf.div(self.prob , self.prob_old)
# loss_CPI = -tf.multiply(r_theta , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# CLIPした場合を計算して、小さい方を使用します。
# r_clip = r_theta
# tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
# clipped_loss_CPI = -tf.multiply(r_clip , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# loss_CLIP = tf.reduce_mean(tf.minimum(loss_CPI, clipped_loss_CPI), axis=1, keep_dims=True)
# loss関数を定義します
advantage = tf.subtract(self.r_t , v)
self.prob = tf.multiply(p, self.a_t) + 1e-10
r_theta = tf.div(self.prob , self.prob_old)
advantage_CPI = tf.multiply(r_theta , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# CLIPした場合を計算して、小さい方を使用します。
r_clip = r_theta
# 180727_God_KonaBananaさんより代入忘れのご指摘いただき修正
#tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
r_clip = tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
clipped_advantage_CPI = tf.multiply(r_clip , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
loss_CLIP = -tf.reduce_mean(tf.minimum(advantage_CPI, clipped_advantage_CPI), axis=1, keep_dims=True)
loss_value = LOSS_V * tf.square(advantage) # minimize value error
entropy = LOSS_ENTROPY * tf.reduce_sum(p * tf.log(p + 1e-10), axis=1, keep_dims=True) # maximize entropy (regularization)
# 180727_God_KonaBananaさんよりentropyの符号のご指摘いただき修正
# self.loss_total = tf.reduce_mean(loss_CLIP + loss_value + entropy)
self.loss_total = tf.reduce_mean(loss_CLIP + loss_value - entropy)
minimize = self.opt.minimize(self.loss_total) # 求めた勾配で重み変数を更新する定義
return minimize
def update_parameter_server(self): # localbrainの勾配でParameterServerの重みを学習・更新します
if len(self.train_queue[0]) < MIN_BATCH: # データがたまっていない場合は更新しない
return
s, a, r, s_, s_mask = self.train_queue
self.train_queue = [[], [], [], [], []]
s = np.vstack(s) # vstackはvertical-stackで縦方向に行列を連結、いまはただのベクトル転置操作
a = np.vstack(a)
r = np.vstack(r)
s_ = np.vstack(s_)
s_mask = np.vstack(s_mask)
# Nステップあとの状態s_から、その先得られるであろう時間割引総報酬vを求めます
_, v = self.model.predict(s_)
# N-1ステップあとまでの時間割引総報酬rに、Nから先に得られるであろう総報酬vに割引N乗したものを足します
r = r + GAMMA_N * v * s_mask # set v to 0 where s_ is terminal state
feed_dict = {self.s_t: s, self.a_t: a, self.r_t: r} # 重みの更新に使用するデータ
minimize = self.graph
SESS.run(minimize, feed_dict) # Brainの重みを更新
self.prob_old = self.prob
def predict_p(self, s): # 状態sから各actionの確率pベクトルを返します
p, v = self.model.predict(s)
return p
def train_push(self, s, a, r, s_):
self.train_queue[0].append(s)
self.train_queue[1].append(a)
self.train_queue[2].append(r)
if s_ is None:
self.train_queue[3].append(NONE_STATE)
self.train_queue[4].append(0.)
else:
self.train_queue[3].append(s_)
self.train_queue[4].append(1.)
実行
以上で、コードは完成です(ただし定数宣言部分を除く)。
全コードは記事の最後に掲載しています。
このPPOを実行すると、8つのlearningスレッドが実行され、およそ各スレッド250試行ほどで学習が終わります。
学習終了の条件設定などがちょっと良くないので、学習後も挙動が微妙なときがありますが、概ね200step立ちつづけてくれます。
こんな感じの挙動をします。
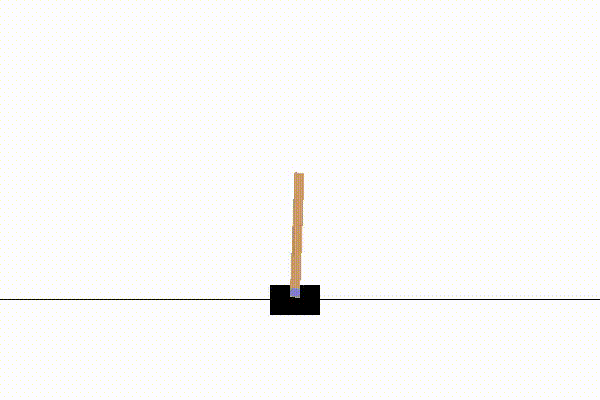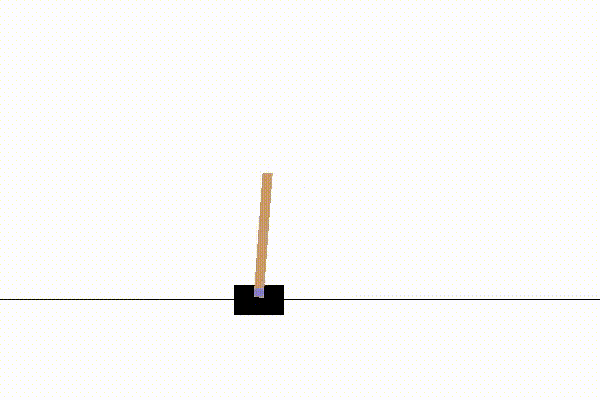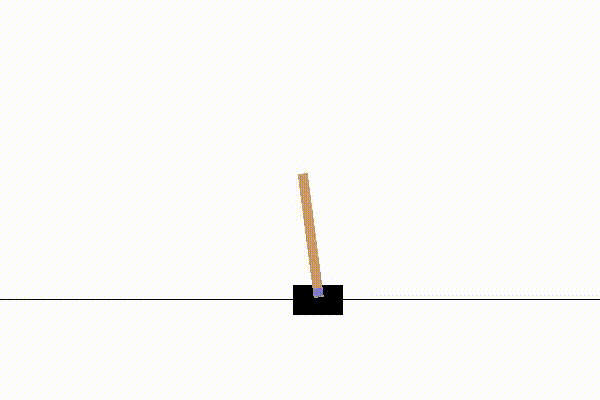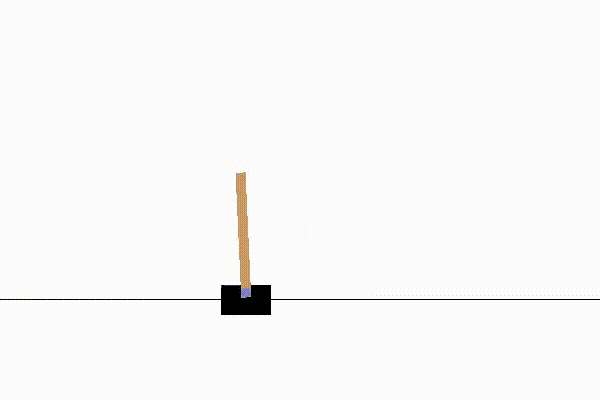
以上、PPO実装の解説でした。
最終的なコード
最後に全コードを掲載します。
# coding:utf-8
# -----------------------------------
# OpenGym CartPole-v0 with PPO on CPU
# -----------------------------------
#
# A3C implementation with TensorFlow multi threads.
#
# Made as part of Qiita article, available at
# https://??/
#
# author: Sugulu, 2017
import tensorflow as tf
import gym, time, random, threading
from gym import wrappers # gymの画像保存
from keras.models import *
from keras.layers import *
from keras.utils import plot_model
from keras import backend as K
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TensorFlow高速化用のワーニングを表示させない
# -- constants of Game
ENV = 'CartPole-v0'
env = gym.make(ENV)
NUM_STATES = env.observation_space.shape[0] # CartPoleは4状態
NUM_ACTIONS = env.action_space.n # CartPoleは、右に左に押す2アクション
NONE_STATE = np.zeros(NUM_STATES)
# -- constants of LocalBrain
MIN_BATCH = 5
EPSILON = 0.2 # loss_CPIをCLIPする範囲を決めます
LOSS_V = 0.2 # v loss coefficient
LOSS_ENTROPY = 0.01 # entropy coefficient
LEARNING_RATE = 2e-3
# -- params of Advantage-ベルマン方程式
GAMMA = 0.99
N_STEP_RETURN = 5
GAMMA_N = GAMMA ** N_STEP_RETURN
N_WORKERS = 8 # スレッドの数
Tmax = 3*N_WORKERS # 各スレッドの更新ステップ間隔
# ε-greedyのパラメータ
EPS_START = 0.5
EPS_END = 0.0
EPS_STEPS = 200*N_WORKERS
# --各スレッドで共有するTensorFlowのDeep Neural Networkのクラスです -------
class Brain:
def __init__(self): # globalなparameter_serverをメンバ変数として持つ
with tf.name_scope("brain"):
self.train_queue = [[], [], [], [], []] # s, a, r, s', s' terminal mask
K.set_session(SESS)
self.model = self._build_model() # ニューラルネットワークの形を決定
self.opt = tf.train.AdamOptimizer(learning_rate=LEARNING_RATE) # loss関数を最小化していくoptimizerの定義です
self.prob_old = 1
self.graph = self.build_graph() # ネットワークの学習やメソッドを定義
def _build_model(self): # Kerasでネットワークの形を定義します
l_input = Input(batch_shape=(None, NUM_STATES))
l_dense = Dense(16, activation='relu')(l_input)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense)
out_value = Dense(1, activation='linear')(l_dense)
model = Model(inputs=[l_input], outputs=[out_actions, out_value])
model._make_predict_function() # have to initialize before threading
plot_model(model, to_file='PPO.png', show_shapes=True) # Qネットワークの可視化
return model
def build_graph(self): # TensorFlowでネットワークの重みをどう学習させるのかを定義します
self.s_t = tf.placeholder(tf.float32, shape=(None, NUM_STATES)) # placeholderは変数が格納される予定地となります
self.a_t = tf.placeholder(tf.float32, shape=(None, NUM_ACTIONS))
self.r_t = tf.placeholder(tf.float32, shape=(None, 1)) # not immediate, but discounted n step reward
p, v = self.model(self.s_t)
# 180726_ykamikawaさんより、Advantageをminとらないといけないのに、lossでminとっているという指摘を受けての修正
# loss関数を定義します
# advantage = tf.subtract(self.r_t , v)
# self.prob = tf.multiply(p, self.a_t) + 1e-10
# r_theta = tf.div(self.prob , self.prob_old)
# loss_CPI = -tf.multiply(r_theta , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# CLIPした場合を計算して、小さい方を使用します。
# r_clip = r_theta
# tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
# clipped_loss_CPI = -tf.multiply(r_clip , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# loss_CLIP = tf.reduce_mean(tf.minimum(loss_CPI, clipped_loss_CPI), axis=1, keep_dims=True)
# loss関数を定義します
advantage = tf.subtract(self.r_t , v)
self.prob = tf.multiply(p, self.a_t) + 1e-10
r_theta = tf.div(self.prob , self.prob_old)
advantage_CPI = tf.multiply(r_theta , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
# CLIPした場合を計算して、小さい方を使用します。
r_clip = r_theta
# 180727_God_KonaBananaさんより代入忘れのご指摘いただき修正
#tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
r_clip = tf.clip_by_value(r_clip, r_theta-EPSILON, r_theta+EPSILON)
clipped_advantage_CPI = tf.multiply(r_clip , tf.stop_gradient(advantage)) # stop_gradientでadvantageは定数として扱います
loss_CLIP = -tf.reduce_mean(tf.minimum(advantage_CPI, clipped_advantage_CPI), axis=1, keep_dims=True)
loss_value = LOSS_V * tf.square(advantage) # minimize value error
entropy = LOSS_ENTROPY * tf.reduce_sum(p * tf.log(p + 1e-10), axis=1, keep_dims=True) # maximize entropy (regularization)
# 180727_God_KonaBananaさんよりentropyの符号のご指摘いただき修正
# self.loss_total = tf.reduce_mean(loss_CLIP + loss_value + entropy)
self.loss_total = tf.reduce_mean(loss_CLIP + loss_value - entropy)
minimize = self.opt.minimize(self.loss_total) # 求めた勾配で重み変数を更新する定義
return minimize
def update_parameter_server(self): # localbrainの勾配でParameterServerの重みを学習・更新します
if len(self.train_queue[0]) < MIN_BATCH: # データがたまっていない場合は更新しない
return
s, a, r, s_, s_mask = self.train_queue
self.train_queue = [[], [], [], [], []]
s = np.vstack(s) # vstackはvertical-stackで縦方向に行列を連結、いまはただのベクトル転置操作
a = np.vstack(a)
r = np.vstack(r)
s_ = np.vstack(s_)
s_mask = np.vstack(s_mask)
# Nステップあとの状態s_から、その先得られるであろう時間割引総報酬vを求めます
_, v = self.model.predict(s_)
# N-1ステップあとまでの時間割引総報酬rに、Nから先に得られるであろう総報酬vに割引N乗したものを足します
r = r + GAMMA_N * v * s_mask # set v to 0 where s_ is terminal state
feed_dict = {self.s_t: s, self.a_t: a, self.r_t: r} # 重みの更新に使用するデータ
minimize = self.graph
SESS.run(minimize, feed_dict) # Brainの重みを更新
self.prob_old = self.prob
def predict_p(self, s): # 状態sから各actionの確率pベクトルを返します
p, v = self.model.predict(s)
return p
def train_push(self, s, a, r, s_):
self.train_queue[0].append(s)
self.train_queue[1].append(a)
self.train_queue[2].append(r)
if s_ is None:
self.train_queue[3].append(NONE_STATE)
self.train_queue[4].append(0.)
else:
self.train_queue[3].append(s_)
self.train_queue[4].append(1.)
# --行動を決定するクラスです、CartPoleであれば、棒付き台車そのものになります -------
class Agent:
def __init__(self, brain):
self.brain = brain # 行動を決定するための脳(ニューラルネットワーク)
self.memory = [] # s,a,r,s_の保存メモリ、 used for n_step return
self.R = 0. # 時間割引した、「いまからNステップ分あとまで」の総報酬R
def act(self, s):
if frames >= EPS_STEPS: # ε-greedy法で行動を決定します 171115修正
eps = EPS_END
else:
eps = EPS_START + frames * (EPS_END - EPS_START) / EPS_STEPS # linearly interpolate
if random.random() < eps:
return random.randint(0, NUM_ACTIONS - 1) # ランダムに行動
else:
s = np.array([s])
p = self.brain.predict_p(s)
a = np.random.choice(NUM_ACTIONS, p=p[0])
return a
def advantage_push_brain(self, s, a, r, s_): # advantageを考慮したs,a,r,s_をbrainに与える
def get_sample(memory, n): # advantageを考慮し、メモリからnステップ後の状態とnステップ後までのRを取得する関数
s, a, _, _ = memory[0]
_, _, _, s_ = memory[n - 1]
return s, a, self.R, s_
# one-hotコーディングにしたa_catsをつくり、、s,a_cats,r,s_を自分のメモリに追加
a_cats = np.zeros(NUM_ACTIONS) # turn action into one-hot representation
a_cats[a] = 1
self.memory.append((s, a_cats, r, s_))
# 前ステップの「時間割引Nステップ分の総報酬R」を使用して、現ステップのRを計算
self.R = (self.R + r * GAMMA_N) / GAMMA # r0はあとで引き算している、この式はヤロミルさんのサイトを参照
# advantageを考慮しながら、LocalBrainに経験を入力する
if s_ is None:
while len(self.memory) > 0:
n = len(self.memory)
s, a, r, s_ = get_sample(self.memory, n)
self.brain.train_push(s, a, r, s_)
self.R = (self.R - self.memory[0][2]) / GAMMA
self.memory.pop(0)
self.R = 0 # 次の試行に向けて0にしておく
if len(self.memory) >= N_STEP_RETURN:
s, a, r, s_ = get_sample(self.memory, N_STEP_RETURN)
self.brain.train_push(s, a, r, s_)
self.R = self.R - self.memory[0][2] # # r0を引き算
self.memory.pop(0)
# --CartPoleを実行する環境です、TensorFlowのスレッドになります -------
class Environment:
total_reward_vec = np.zeros(10) # 総報酬を10試行分格納して、平均総報酬をもとめる
count_trial_each_thread = 0 # 各環境の試行数
def __init__(self, name, thread_type, brain):
self.name = name
self.thread_type = thread_type
self.env = gym.make(ENV)
self.agent = Agent(brain) # 環境内で行動するagentを生成
def run(self):
global frames # セッション全体での試行数、global変数を書き換える場合は、関数内でglobal宣言が必要です
global isLearned
if (self.thread_type is 'test') and (self.count_trial_each_thread == 0):
self.env.reset()
#self.env = gym.wrappers.Monitor(self.env, './movie/PPO') # 動画保存する場合
s = self.env.reset()
R = 0
step = 0
while True:
if self.thread_type is 'test':
self.env.render() # 学習後のテストでは描画する
time.sleep(0.1)
a = self.agent.act(s) # 行動を決定
s_, r, done, info = self.env.step(a) # 行動を実施
step += 1
frames += 1 # セッショントータルの行動回数をひとつ増やします
r = 0
if done: # terminal state
s_ = None
if step < 199:
r = -1
else:
r = 1
# 報酬と経験を、Brainにプッシュ
self.agent.advantage_push_brain(s, a, r, s_)
s = s_
R += r
if done or (frames % Tmax == 0): # 終了時がTmaxごとに、parameterServerの重みを更新
if not(isLearned) and self.thread_type is 'learning':
self.agent.brain.update_parameter_server()
if done:
self.total_reward_vec = np.hstack((self.total_reward_vec[1:], step)) # トータル報酬の古いのを破棄して最新10個を保持
self.count_trial_each_thread += 1 # このスレッドの総試行回数を増やす
break
# 総試行数、スレッド名、今回の報酬を出力
print("スレッド:"+self.name + "、試行数:"+str(self.count_trial_each_thread) + "、今回のステップ:" + str(step)+"、平均ステップ:"+str(self.total_reward_vec.mean()))
# スレッドで平均報酬が一定を越えたら終了
if self.total_reward_vec.mean() > 199:
isLearned = True
time.sleep(2.0) # この間に他のlearningスレッドが止まります
# --スレッドになるクラスです -------
class Worker_thread:
# スレッドは学習環境environmentを持ちます
def __init__(self, thread_name, thread_type, brain):
self.environment = Environment(thread_name, thread_type, brain)
self.thread_type = thread_type
def run(self):
while True:
if not(isLearned) and self.thread_type is 'learning': # learning threadが走る
self.environment.run()
if not(isLearned) and self.thread_type is 'test': # test threadを止めておく
time.sleep(1.0)
if isLearned and self.thread_type is 'learning': # learning threadを止めておく
time.sleep(3.0)
if isLearned and self.thread_type is 'test': # test threadが走る
time.sleep(3.0)
self.environment.run()
# -- main ここからメイン関数です------------------------------
# M0.global変数の定義と、セッションの開始です
frames = 0 # 全スレッドで共有して使用する総ステップ数
isLearned = False # 学習が終了したことを示すフラグ
SESS = tf.Session() # TensorFlowのセッション開始
# M1.スレッドを作成します
with tf.device("/cpu:0"):
brain = Brain() # ディープニューラルネットワークのクラスです
threads = [] # 並列して走るスレッド
# 学習するスレッドを用意
for i in range(N_WORKERS):
thread_name = "local_thread"+str(i+1)
threads.append(Worker_thread(thread_name=thread_name, thread_type="learning", brain=brain))
# 学習後にテストで走るスレッドを用意
threads.append(Worker_thread(thread_name="test_thread", thread_type="test", brain=brain))
# M2.TensorFlowでマルチスレッドを実行します
COORD = tf.train.Coordinator() # TensorFlowでマルチスレッドにするための準備です
SESS.run(tf.global_variables_initializer()) # TensorFlowを使う場合、最初に変数初期化をして、実行します
running_threads = []
for worker in threads:
job = lambda: worker.run() # この辺は、マルチスレッドを走らせる作法だと思って良い
t = threading.Thread(target=job)
t.start()
#running_threads.append(t)
# M3.スレッドの終了を合わせます
# COORD.join(running_threads)