本記事では、NVIDIAから発表されているPyTorchでのディープラーニングを高速化するコツ集を紹介します。
【※NEW】22年6月新記事:スクラム関連の研修・資格のまとめ & おすすめの研修受講方法
本記事について
本記事は、NVIDIAのArun Mallyaさんの発表、
「PyTorch Performance Tuning Guide - Szymon Migacz, NVIDIA」
に、説明やプログラムを追加して、解説します。

本記事のポイントは、Andrej KarpathyがTwitterで呟いている通りとなります。
good quick tutorial on optimizing your PyTorch code ⏲️: https://t.co/7CIDWfrI0J
— Andrej Karpathy (@karpathy) August 30, 2020
quick summary: pic.twitter.com/6J1SJcWJsl
これを分かりやすく、解説します。
※Andrej Karpathy
ImageNetを整えたフェイフェイ・リー先生のところで博士号を取得
現在はテスラのAI部門のディレクター
ImageNetで人の性能はエラー率5%とあるが、あの結果を出すために、ヒト代表でやったImageNetに挑戦した人
本記事の内容
0. 内容の注意点
1. DataLoaderについて(num_workers、pin_memory)
2. torch.backends.cudnn.benchmark = True について
3. ミニバッチサイズを大きくしよう(AMP、LARSやLAMB)
4. Multi-GPUの設定
5. テンソルの変換関数はJITに
6. その他のTips
7. non_blocking=True
0. 内容の注意点
本記事で説明する内容は使用しているGPU環境に依存します。
ご自身の環境でどれが有効かを確かめてみてください。
本記事のプログラムは全て、
https://github.com/YutaroOgawa/Qiita/tree/master/pytorch_performance
で公開しています。
Jupyter Notebook形式となっています。
本記事では【性能変化】を、「MNISTの訓練1epoch」の時間で簡単に確認します。
1. DataLoaderについて
PyTorchのDataLoaderには2点、デフォルト設定であまりよくない点があります。
https://pytorch.org/docs/stable/data.html
1.1 num_workers
まず、引数がデフォルトでは num_workers=0となっている点です。
その結果、ミニバッチの取り出しがSingle processになっています。
num_workers=2などに設定することで、multi-process data loadingとなり、処理が高速化されます。
CPUのコア数は以下で確認できます。
# CPUのコア数を確認
import os
os.cpu_count() # コア数
コア数については2あれば1GPUに対しては十分な印象があります。
DataLoaderを以下のように作成します。
# デフォルト設定のDataLoaderの場合
train_loader_default = torch.utils.data.DataLoader(dataset1,batch_size=mini_batch_size)
test_loader_default = torch.utils.data.DataLoader(dataset2,batch_size=mini_batch_size)
# データローダー:2
train_loader_nworker = torch.utils.data.DataLoader(
dataset1, batch_size=mini_batch_size, num_workers=2)
test_loader_nworker = torch.utils.data.DataLoader(
dataset2, batch_size=mini_batch_size, num_workers=2)
# データローダー:フル
train_loader_nworker = torch.utils.data.DataLoader(
dataset1, batch_size=mini_batch_size, num_workers=os.cpu_count())
test_loader_nworker = torch.utils.data.DataLoader(
dataset2, batch_size=mini_batch_size, num_workers=os.cpu_count())
【性能変化】
MNISTの訓練1epochで性能変化を確認します。
# GPUの確認
!nvidia-smi
で使用環境のGPUが確認できます。
今回は、
●ケース1:p3.2xlarge(NVIDIA® VOLTA V100 Tensor Core GPU)
●ケース2:Google Colaboratory(Tesla Turing T4 Tensor Core GPU )
となります。Google Colaboratoryは毎回GPUの種類が異なるので注意が必要です。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒
【num_workers=os.cpu_count()の場合】
●ケース1:p3.2xlarge:3.47秒
●ケース2:Google Colaboratory:9.43秒
どちらも早くなりましたが、ケース1は1/3程度までと、非常に高速化されました。
なお、p3.2xlargeはCPUコア数が8で、Goole ColaboratoryはCPUコア数が2です。
ただ、コア数は2でnum_workers=2で十分な印象があります。
元の発表でも2以上はそれほど差はないようです。

1.2 pin_memory
PyTorchのDataLoaderは引数pin_memory=Falseがデフォルトです。
pin_memory=Trueにすることで、automatic memory pinningが使用できます。
CPUのメモリ領域がページングされないようになり、高速化が期待されます。
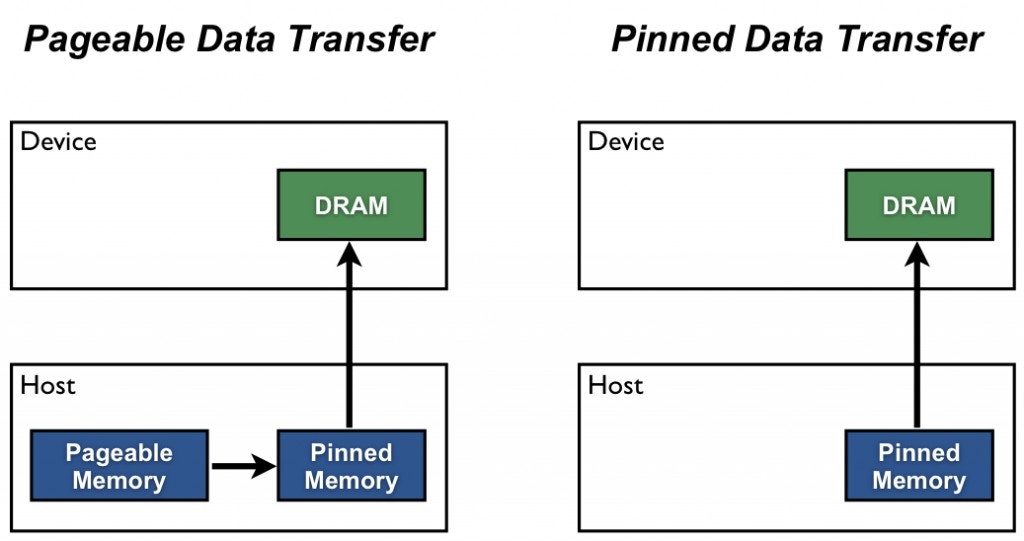
(参考)
https://pytorch.org/docs/stable/data.html#memory-pinning
https://zukaaax.com/archives/301
https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
(メモリのページングについて解説)
https://wa3.i-3-i.info/word13352.html
実装は以下の通りです。
# デフォルト設定のDataLoaderの場合
train_loader_default = torch.utils.data.DataLoader(dataset1,batch_size=mini_batch_size)
test_loader_default = torch.utils.data.DataLoader(dataset2,batch_size=mini_batch_size)
# データローダー pin memory
train_loader_pin_memory = torch.utils.data.DataLoader(
dataset1, batch_size=mini_batch_size, pin_memory=True)
test_loader_pin_memory = torch.utils.data.DataLoader(
dataset2, batch_size=mini_batch_size, pin_memory=True)
先ほどと同じく、MNISTの訓練1epochで性能変化を確認します。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒
【pin_memory=Trueの場合】
●ケース1:p3.2xlarge:13.65秒
●ケース2:Google Colaboratory:9.82秒
【num_workers=os.cpu_count()の場合】
●ケース1:p3.2xlarge:3.47秒
●ケース2:Google Colaboratory:9.43秒
【num_workers=os.cpu_count() & pin_memory=Trueの場合】
●ケース1:p3.2xlarge:3.50秒
●ケース2:Google Colaboratory:9.35秒
デフォルト設定と比較すると、高速化されているのが分かります。
num_workersを設定していると、今回のMNISTでは規模が小さすぎるのか、pin_memoryの効果は見えません。
1.3 DataLoaderの作り方の結論
[1] PyTorchでDataLoaderを作成する場合は、引数num_workersとpin_memoryを変更し、以下のように実装すること。
# デフォルト設定
train_loader_default = torch.utils.data.DataLoader(dataset1,batch_size=mini_batch_size)
test_loader_default = torch.utils.data.DataLoader(dataset2,batch_size=mini_batch_size)
# データローダー 推奨
train_loader_pin_memory = torch.utils.data.DataLoader(
dataset1, batch_size=mini_batch_size, num_workers=os.cpu_count(), pin_memory=True)
test_loader_pin_memory = torch.utils.data.DataLoader(
dataset2, batch_size=mini_batch_size, num_workers=os.cpu_count(), pin_memory=True)
# もしくはデータローダー num_workers=2
train_loader_pin_memory = torch.utils.data.DataLoader(
dataset1, batch_size=mini_batch_size, num_workers=2, pin_memory=True)
test_loader_pin_memory = torch.utils.data.DataLoader(
dataset2, batch_size=mini_batch_size, num_workers=2, pin_memory=True)
2. torch.backends.cudnn.benchmark = True について
2.1 解説
訓練を実施する際には、torch.backends.cudnn.benchmark = Trueを実行しておきましょう。
これは、ネットワークの形が固定のとき、GPU側でネットワークの計算を最適化し高速にしてくれます。
通常のCNNのようにデータの入力サイズが最初や途中で変化しない場合はTrueにします。
ただし、計算の再現性がなくなるのでその点は注意が必要です。
(PyTorchの計算再現性について)
https://pytorch.org/docs/stable/notes/randomness.html
実装は例えば次の通りとなります。
def MNIST_train_cudnn_benchmark_True(optimizer, model, device, train_loader, test_loader):
# デフォルトで訓練
epochs = 1
# 追加
torch.backends.cudnn.benchmark = True
# 処理
for epoch in range(1, epochs+1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
なお、ここで関数train()は以下のような形です。
def train(model, device, train_loader, optimizer, epoch):
model.train() # 訓練モードに
for batch_idx, (data, target) in enumerate(train_loader):
# データ取り出し
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# 伝搬
output = model(data)
# 損失計算とバックプロパゲーション
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
速度を比較します。DataLoaderはデフォルト設定にしておきます。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒
【torch.backends.cudnn.benchmark = Trueの場合】
●ケース1:p3.2xlarge:14.47秒
●ケース2:Google Colaboratory:9.66秒
今回はMNISTを解いているだけなので、ネットワークも小さいため、この効果が薄いですが、少し高速化されました。
2.2 結論
プログラム実行時に、torch.backends.cudnn.benchmark = Trueを入れましょう
3. ミニバッチサイズを大きくしよう
ミニバッチサイズが大きい方が学習が安定します。
そのため、ミニバッチサイズは大きくしましょう。
PyTorchのAMP(Automatic Mixed Precision)機能により、実際には想定計算以上のミニバッチサイズが可能なケースがあります。
3.1 AMP(Automatic Mixed Precision)機能について
AMP(Automatic Mixed Precision)とは、混合精度を意味します。
通常、FP32(32ビット浮動小数点)で計算されますが、半分のFP16(16ビット浮動小数点)で精度を落とさずにメモリの使用量を節約し、計算速度も向上させる機能です。
さらに、TensorコアがあるGPUであれば、2倍以上の8倍から16倍程度高速化されます。
(訓練で最大12倍、推論で最大6倍程度)
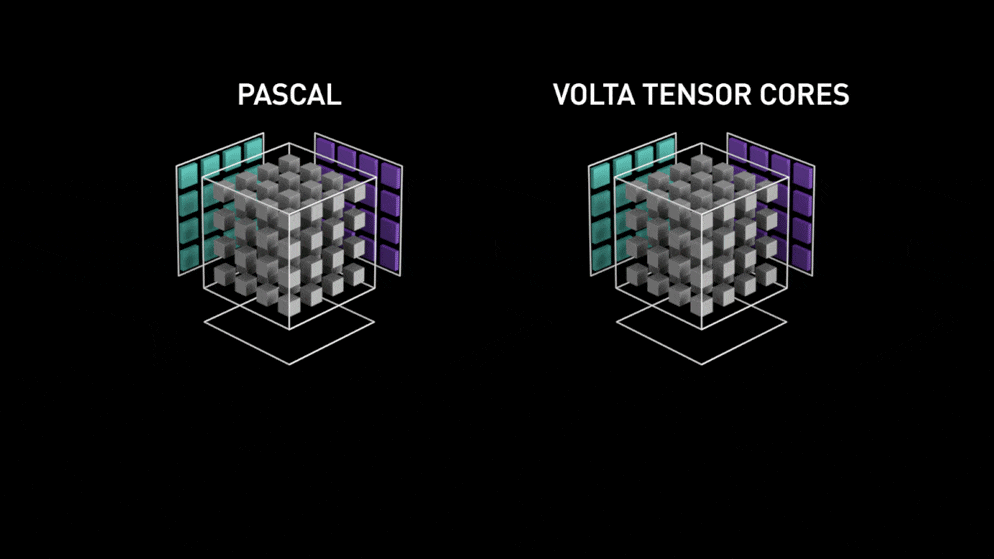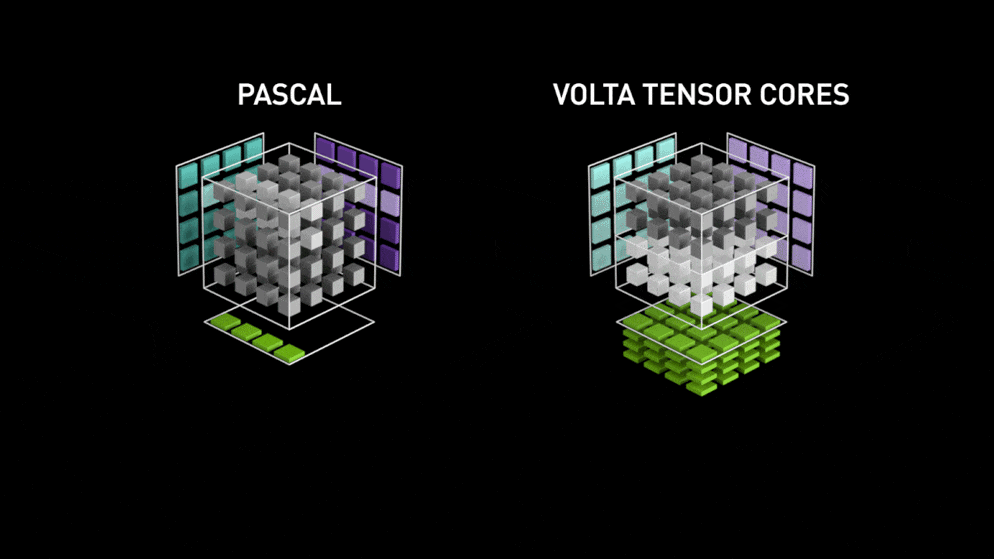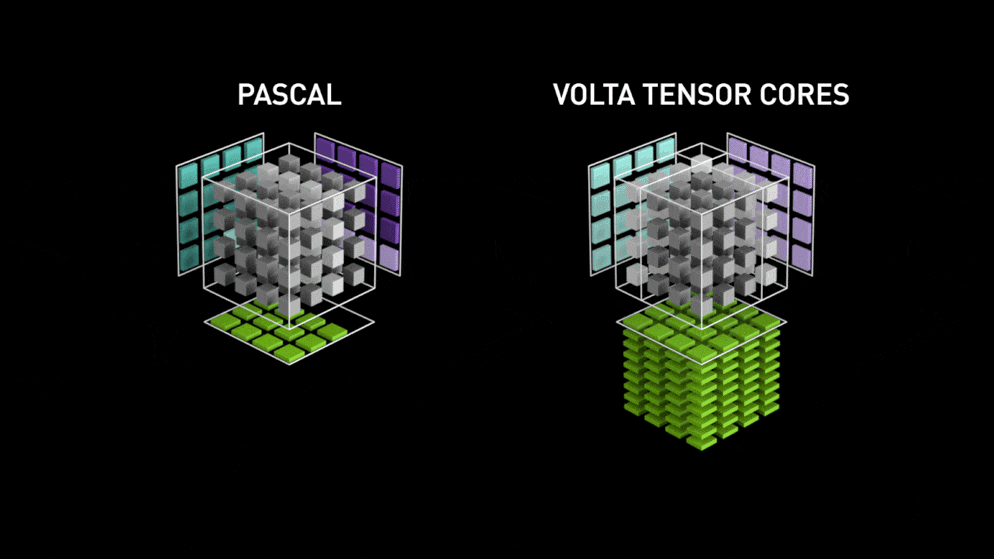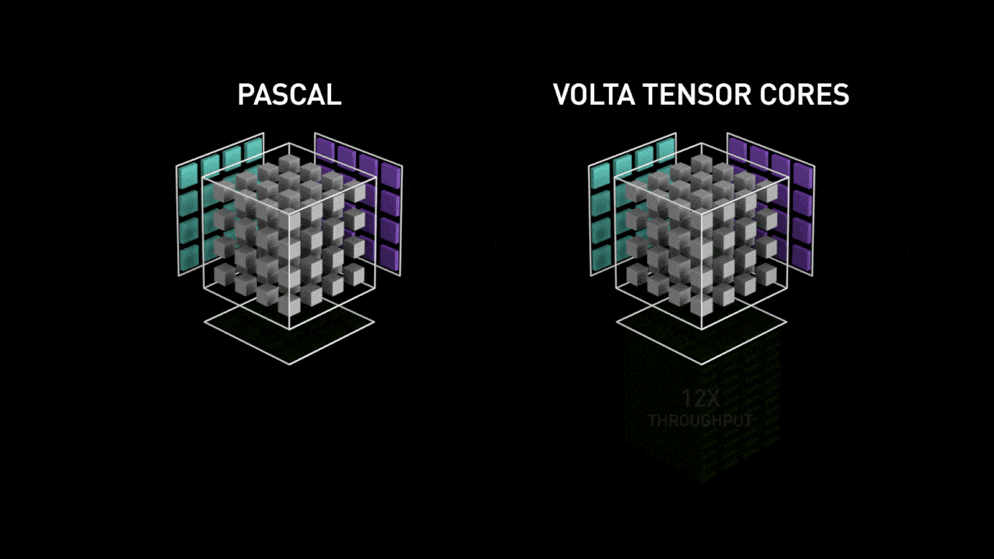
(参考)
https://www.nvidia.com/ja-jp/data-center/tensor-cores/
なお、V100のVoltaには、TENSORコア第1世代が搭載されており、
TシリーズにはTURING TENSORコア第2世代が搭載されています。
TURING TENSORコア第2世代は、第1世代よりさらに2倍程度早くなるそうです。

3.2 AMP(Automatic Mixed Precision)を使用する
使用方法などの解説はこちらです。
(参考)
https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/
https://pytorch.org/docs/stable/notes/amp_examples.html
上記のexamplesに従って実装します。
先ほどの関数test()を書き換えます。
def train_PyTorchAMP(model, device, train_loader, optimizer, epoch):
model.train() # 訓練モードに
scaler = torch.cuda.amp.GradScaler()
for batch_idx, (data, target) in enumerate(train_loader):
# データ取り出し
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# 伝搬
# Runs the forward pass with autocasting.
with torch.cuda.amp.autocast():
output = model(data)
loss = F.nll_loss(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
scaler = torch.cuda.amp.GradScaler()でscalerを作成し、scalerでforward計算、loss計算、バックプロパゲーション、パラメータ更新をラップします。
DataLoaderをデフォルト設定にして、AMPを利用し、速度を比較します。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒
【AMPの場合】
●ケース1:p3.2xlarge:14.21秒
●ケース2:Google Colaboratory:11.97秒
今回のMNISTでは1回の計算量なども少ないので、あまり効果は感じられませんでした。
なお、このAMPを利用することで、想定以上にミニバッチサイズを大きくすることが可能になりますが、
ミニバッチサイズを大きくした場合の注意点としては以下を意識します。
[1] 学習率の値の調整
[2] weight decay(重み減衰)の調整:optimizerの罰則項の大きさ
[3] 学習にウォームアップ(warmup)を取り入れる:学習の初期は学習率を0から線形に徐々に大きくして一定のところまで上げる
[4] 学習に学習率減衰(learning rate decay)を取り入れる:学習の終盤は学習率を徐々に小さくしていく
3.3 LARSやLAMBについて
また、大規模なミニバッチの場合には、OptimizerにLARSやLAMB、NVIDIAのLAMBであるNVLAMBなどの使用も検討します。
大規模なミニバッチの場合、
同じ時間をかけても、ミニバッチサイズが小さいときよりもtotalのepoch数が少なくなります。それを補うために単純に学習率を大きくすると、今度は高すぎる学習率で訓練が安定しづらい
という問題が発生します。
そこで、学習率に“trust ratio”と呼ばれる、勾配に応じた係数をかける手法がLARS(Layerwise Adaptive Rate Scaling)です。
また、LAMB(Layer-wise Adaptive Moments optimizer for Batch training)は、LARSに各ウェイトパラメータの1epochごとの変化の速度も考慮した最適化手法となります。
LAMBを使うことで、通常81時間かかるBERTの学習を、76分と、100倍程度高速化できます。
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
https://arxiv.org/abs/1904.00962
(NVIDIAのA Guide to Optimizer Implementation for BERT at Scaleより)
(参考)
https://medium.com/nvidia-ai/a-guide-to-optimizer-implementation-for-bert-at-scale-8338cc7f45fd
https://developer.nvidia.com/blog/pretraining-bert-with-layer-wise-adaptive-learning-rates/
https://postd.cc/optimizing-gradient-descent/
https://towardsdatascience.com/an-intuitive-understanding-of-the-lamb-optimizer-46f8c0ae4866
3.4 NVIDIAでLAMBなどを使用する方法
まず、以下のNVIDIAのAPEX (A PyTorch Extension)のページを参考にapexをインストールします。
https://github.com/NVIDIA/apex
https://nvidia.github.io/apex/
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
実装は以下の通りです。
まずtrain()を書き換えます。
from apex import amp
def trainAMP(model, device, train_loader, optimizer, epoch):
model.train() # 訓練モードに
for batch_idx, (data, target) in enumerate(train_loader):
# データ取り出し
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# 伝搬
output = model(data)
# 損失計算とバックプロパゲーション
loss = F.nll_loss(output, target)
# AMP Train your model
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
そして、trainAMP()を用いた訓練関数を書きます。
def MNIST_trainAMP(optimizer, model, device, train_loader, test_loader):
epochs = 1
start = time.time()
torch.backends.cudnn.benchmark = True
# 処理
for epoch in range(1, epochs+1):
trainAMP(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
# かかった時間
print("=======かかった時間========")
print(time.time() - start)
optimizerをapex.optimizers.FusedLAMBに設定します。
NVIDIAのLAMBAはNVLAMBと呼ばれます。
import apex
# モデル、学習率とoptimizerを設定
model = Net().to(device)
lr_rate = 0.1
optimizer = apex.optimizers.FusedLAMB(model.parameters(), lr=lr_rate)
# Initialization
opt_level = 'O1'
model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)
AMPでモデルとoptimizerを初期化します。
最後に訓練を実施します。
MNIST_trainAMP(optimizer, model, device,
train_loader_pin_memory, test_loader_pin_memory)
以上が、大規模なミニバッチに対する、NVIDIAのLAMB optimizerの使用方法となります。
4. Multi-GPUの設定
Multi-GPUで訓練する場合は、
DATAPARALLELのtorch.nn.DataParallelではなく、
DISTRIBUTEDDATAPARALLELのtorch.nn.parallel.DistributedDataParallel
を使用します。
これは以下の講演スライドのように、
DATAPARALLELだとCPUの1コアしか使用してくれないからです。
DISTRIBUTEDDATAPARALLELであれば、1GPUに対して、1CPUコアが割り当てられます。
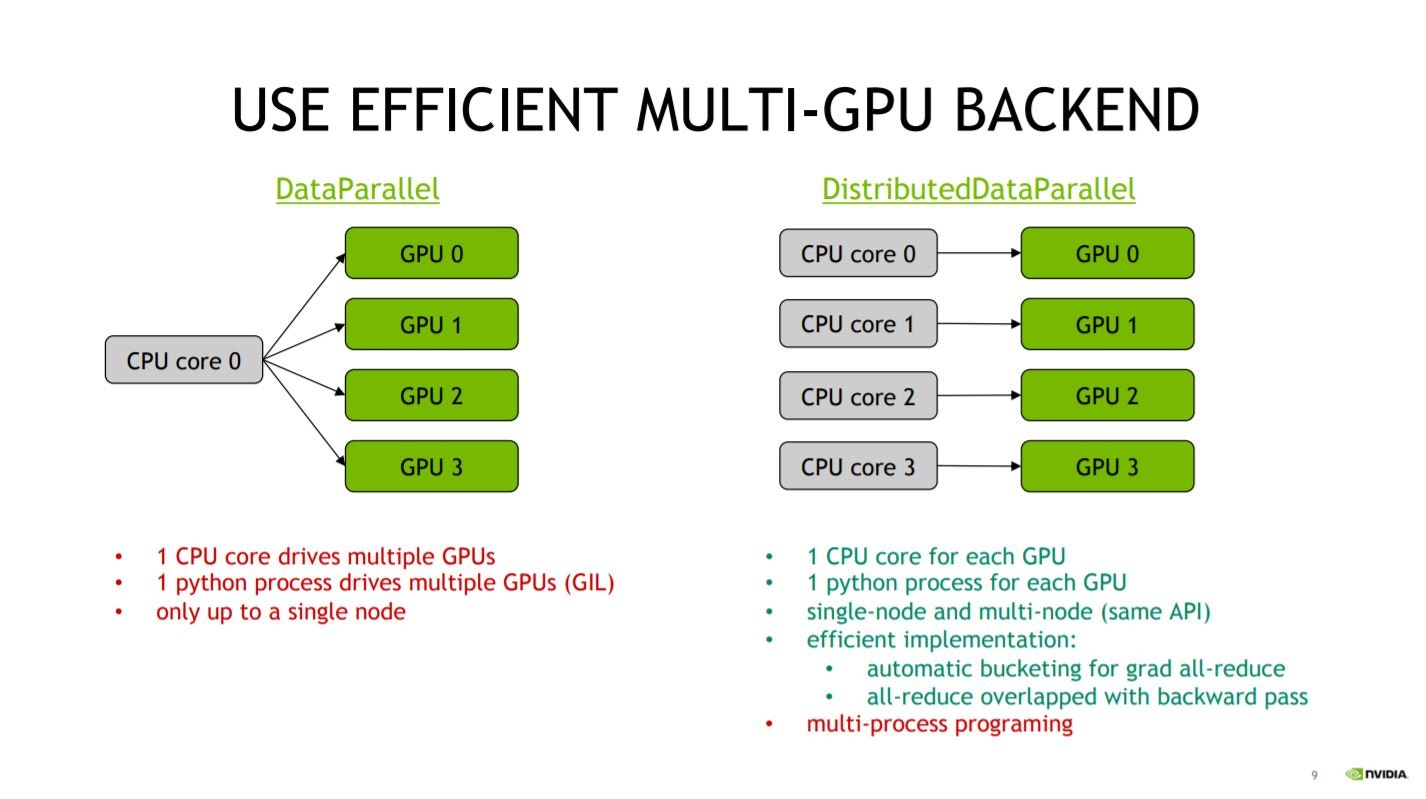
また、NVIDIAのAPEXのapex.parallel.DistributedDataParallelは、torch.nn.parallel.DistributedDataParallelと同じように使用できますが、利点があります。
それは、NVIDIAのapex.parallel.DistributedDataParallelが、Synchronized Batch Normalizationになっている点です。
PyTorchのバッチノーマライゼーション層はMulti-GPUの場合、各GPUごとに割り当てられたミニバッチ内でバッチノーマライゼーションを実施し、各GPUごとに平均と標準偏差を求め、それらを平均して、バッチノーマライゼーションの平均、標準偏差を学習させていきます。
これは、各GPUごとにバッチノーマライゼーションを行うので、Asynchronized Batch Normalizationと呼びます。
Multi-GPUに分散された全データでのバッチノーマライゼーションと計算結果が変わってしまいます。
PyTochの場合、torch.nn.SyncBatchNormを使う作戦もあるのですが、結構実装が面倒です。
NVIDIAのAPEXのapex.parallel.DistributedDataParallelを使用し
sync_bn_model = apex.parallel.convert_syncbn_model(model)
でモデルを変換するだけで、*Synchronized Batch Normalization**になります。
(参考)
https://nvidia.github.io/apex/parallel.html
https://github.com/NVIDIA/apex/tree/master/apex/parallel
https://github.com/NVIDIA/apex/tree/master/examples/simple/distributed
5. テンソルの変換関数はJITに
テンソルへの個別操作の関数には、デコレエータ@torch.jit.scriptをつけて、PyToch JIT(C++実行形式)にしておき、
高速化します。
JIT(Just-In-Time Compiler)とは、ソフトウェアの実行時にコードのコンパイルを行い実行速度の向上を図るコンパイラのことです。
TensorflowやKerasはdefine and runで、コンパイルしてから実行します(その分、コード記述が面倒であった)
PyTorchはdefine by runで、データを流しながら計算を構築します。
ただ、決まりきった計算関数については先にコンパイルしておいた方が良いので、JITでC++実行形式(操作上はPythonから実行する)にします。
例えば、活性化関数のgeluを定義したいとき、通常の定義と、JITでの定義は以下のようになります。
def gelu(x):
return x * 0.5 * (1.0 + torch.erf(x / 1.41421))
@torch.jit.script
def fused_gelu(x):
return x * 0.5 * (1.0 + torch.erf(x / 1.41421))
PyTorch JITにするにはデコレータ@torch.jit.scriptを関数につけます。
これの実行速度を比較すると、
import time
x = torch.randn(2000, 3000)
start = time.time()
for i in range(200):
gelu(x)
# かかった時間
print("=======かかった時間========")
print(time.time() - start)
と
import time
x = torch.randn(2000, 3000)
start = time.time()
for i in range(200):
fused_gelu(x)
# かかった時間
print("=======かかった時間========")
print(time.time() - start)
では、
●ケース1:p3.2xlarge(NVIDIA® VOLTA V100 Tensor Core GPU)
で、9.8秒→6.6秒
●ケース2:Google Colaboratory(Tesla Turing T4 Tensor Core GPU )
で、13.94秒→13.91秒
でした。
Google Colaboratoryでは変化がほとんどないのですが、AWSのp3.2xlargeでは6割ほどまで時間が短縮されています。
6. その他のTips
6.1 バックプロパゲーションが不要なモデルの設定
GANの計算などで、バックプロパゲーションが不要なモデルを全体の一部に使用する場合、
model.zero_grad()
ではなく、
for param in model.parameters():
param.grad = None
で勾配計算をNoneにします。これは、model.zero_grad()だと実際にはメモリ領域を消費するためです。

6.2 バッチノーマライゼーションの前の層はバイアスパラメータをFalseに
バッチノーマライゼーションで標準化して、平均0にするのであれば、その前の層にバイアスパラメータがあると、それを打ち消すようにバッチノーマライゼーションも定数項を学習することになります。
計算時間も、計算量ももったいないので、バッチノーマライゼーションの前の層はバイアスパラメータはFalseに設定し、バイアス項を使用しないようにしておきます。
7. non_blocking=True
7.1 asynchronous GPU copiesを実施
- DataLoaderについて(num_workers、pin_memory)
で、pin_memoryの活用について説明しました。
PyTorchのDataLoaderは引数pin_memory=Falseがデフォルトですが、pin_memory=Trueにすることで、automatic memory pinningが使用できます。
CPUのメモリ領域がページングされないようになり、高速化が期待されます。
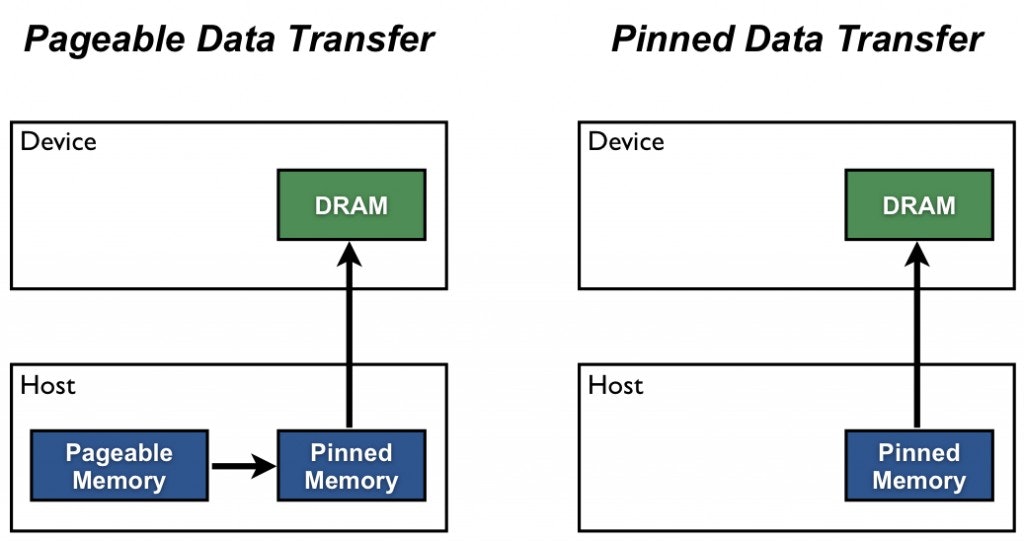
この際の実装は以下の通りでした。
# データローダー 推奨
train_loader_pin_memory = torch.utils.data.DataLoader(
dataset1, batch_size=mini_batch_size, num_workers=os.cpu_count(), pin_memory=True)
test_loader_pin_memory = torch.utils.data.DataLoader(
dataset2, batch_size=mini_batch_size, num_workers=os.cpu_count(), pin_memory=True)
ここで、さらに高速化をするために、asynchronous GPU copiesを可能に設定します。
というのも、このままでは、
CPUのPinned MemoryからGPUにデータを転送している間、CPUが動作できないからです。
そこで、non_blocking=Trueの設定を使用します。
すると、Pinned MemoryからGPUに転送中もCPUが動作でき、高速化が期待されます。
実装は単純で、cudaにデータを送る部分を書き換えます。
for batch_idx, (data, target) in enumerate(train_loader):
# データ取り出し
data, target = data.to(device), target.to(device)
を
# non_blocking=True
for batch_idx, (data, target) in enumerate(train_loader):
# データ取り出し
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
と、to( ) の中で引数non_blocking=Trueを与えます。
参考
https://stackoverflow.com/questions/55563376/pytorch-how-does-pin-memory-works-in-dataloader
https://pytorch.org/docs/stable/notes/cuda.html#use-pinned-memory-buffers
https://discuss.pytorch.org/t/should-we-set-non-blocking-to-true/38234
https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
7.2 速度差の比較
non_blocking=Trueの場合とそうでない場合(pin_memory=Trueだけ)とで比較します。
●ケース1:p3.2xlarge(NVIDIA® VOLTA V100 Tensor Core GPU)
で、13.126秒→13.125秒
●ケース2:Google Colaboratory(Tesla P100-PCIE Tensor Core GPU )※追記でやり直したのでGPUが少し変わっています。同じTeslaですが。
で、8.370秒→8.298秒
と少しだけ早くなりました。
上記は、DataLoaderのnum_workers=0で実施したので、num_workers=2で実施すると、
●ケース1:p3.2xlarge
で、6.843秒→6.776秒
●ケース2:Google Colaboratory
で、8.059秒→7.935秒
こちらも少し早くなりました。
MNISTと規模が小さいので恩恵が見えにくいですが、CPU負担が大きい複雑な処理や大きなデータでは顕著に効果が出るかもしれません。
まとめ
以上、PyTorchでの学習・推論を高速化するコツを紹介しました。
いくつかの手法は、Google Colaboratoryの場合、
「裏側で何か起こっているのか、機能しない?もしくは自動で機能している?」ような感じを受けました。
一方で、普通にクラウドでGPUインスタンスを立ててPyTorchでディープラーニングをする際には、本記事は使える点も多いかと思います。
ぜひご活用いただければ幸いです♪
備考
**【執筆者】**電通国際情報サービス(ISID)AIトランスフォーメーションセンター 開発Gr
小川 雄太郎(主書「つくりながら学ぶ! PyTorchによる発展ディープラーニング」 、その他「自己紹介詳細」)
【Twitter】
IT・AI関連やビジネス・経営系を中心に、私が面白いと思った記事や最近読んだ新刊書籍の感想などを発信しています。これらの分野の情報を収集したい方はぜひフォローしてみてください♪(海外情報が多めです)
【その他】
私がリードする、「AIトランスフォーメーションセンター 開発チーム」ではメンバを募集中です。ご興味、ご関心をお持ちの方は、こちらのページから、応募をお待ちしております。
【そくめん君】
いきなり応募は・・・という方は、カジュアル面談を「そくめん君」で行わせていただいております。
こちらもぜひご利用ください♪
https://sokumenkun.com/2020/08/17/yutaro-ogawa/
【免責】本記事の内容そのものは著者の意見/発信であり、著者が属する企業等の公式見解ではございません