概要
本記事では、PostgreSQL・MySQL・Redis・MongoDB の4種類のデータベースにおける ID生成方式の性能比較 を行った結果を紹介します。
比較対象は以下の4方式です:
- UUID4:完全ランダムなUUID
- UUID7:時間順序性を持つUUID
- Auto Increment:連番(シーケンシャルID)
- Snowflake:Twitterが開発した分散ID生成アルゴリズム
各方式について、CRUD操作性能・I/O特性・メモリ局所性・ID生成コストを測定し、データスケールと分散性の両立をどの方式が最も実現できるかを評価しました。
実験は Docker Compose によって構築されたローカル環境で実施し、データ規模を 10万件・100万件 として、各測定を 3回繰り返し中央値を採用しています。
背景
分散システムにおけるID生成は、性能・スケーラビリティ・一意性・順序性といったシステム設計上の主要要素に直結します。
- Auto Increment は単一DBで効率的ですが、分散環境では重複や競合が発生します。
- UUID4 は分散性に優れる一方、ランダム性が高くインデックス断片化を引き起こしやすいです。
- UUID7 と Snowflake は時間順序性を考慮して設計されており、分散性と性能のバランスが取れています。
本記事では、これらのID方式が異なるデータベースエンジンでどのように挙動・性能に影響するかを詳細に比較します。
実験環境
| 項目 | 内容 |
|---|---|
| データベース | PostgreSQL, MySQL, Redis, MongoDB |
| ID生成方式 | UUID4 / UUID7 / Auto Increment / Snowflake |
| データ規模 | 100,000行, 1,000,000行 |
| 測定回数 | 各3回(中央値採用) |
| 環境構築 | Docker Compose |
| 実装言語 | Python(SQLAlchemy, Redis-py, PyMongo) |
実験方法
- 各データベースサービスをDocker Composeで起動
- 各ID方式ごとに専用テーブルまたはコレクションを作成
- 指定された件数のデータを挿入
- 挿入スループットおよびレイテンシを測定
- I/O特性、メモリ局所性、ID生成コストを評価
挿入スループット性能分析
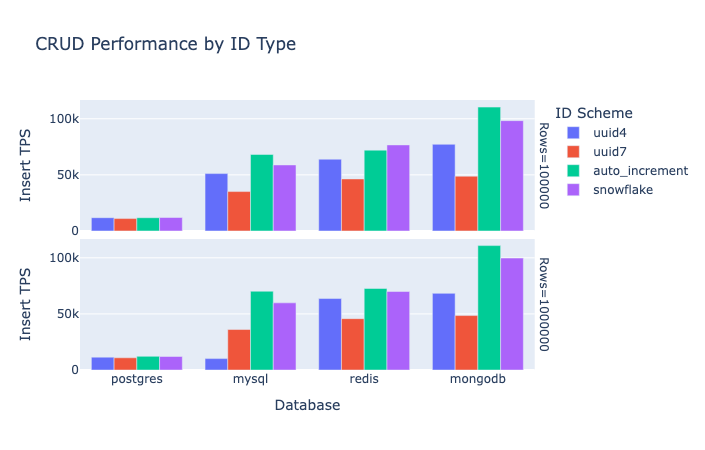
PostgreSQL、MySQL、Redis、MongoDB の各データベースにおいて、ID方式別に挿入スループットをベンチマークし、データ規模の拡大に伴う性能傾向を整理した。
UUIDv4 はランダム性が高く、B-Tree のノード分割やページミスを誘発するため、PostgreSQL・MySQL いずれの環境でもスループットが顕著に低下した。
一方、時系列性を持つ UUIDv7 や Snowflake は 右端挿入(rightmost insertion) に近いアクセスパターンを形成し、ページ分割や書き込み増幅(write amplification)を抑制する傾向を示した。
MySQL では AUTO_INCREMENT が最も高速であり、クラスタ化インデックス構造との親和性が高い結果となった。
I/O統計分析
PostgreSQL では pg_stat_statements、MySQL では performance_schema を用いて、各 ID 方式における I/O 負荷を詳細に収集した。
Redis および MongoDB は I/O メトリクスが軽量であり、影響が限定的なため本節では除外している。
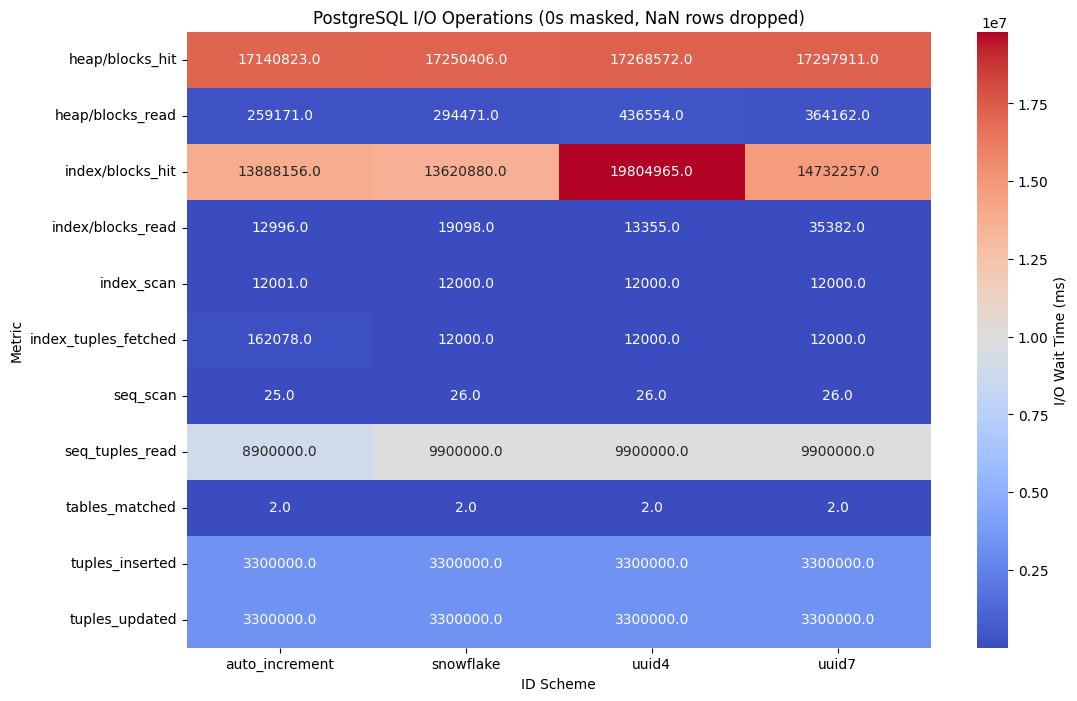
PostgreSQL の I/O 統計
UUIDv4 は共有バッファ読み込み量および一時ブロック書き込みを押し上げ、ランダム挿入によるヒープおよびインデックス構造の断片化を引き起こす。
これによりキャッシュヒット率が低下し、I/O 増幅が顕著となる。
UUIDv7 はこの傾向を緩和し、より安定した I/O パターンを示した。
対策としては、autovacuum のチューニング、インデックス再編、fillfactor 調整が有効である。
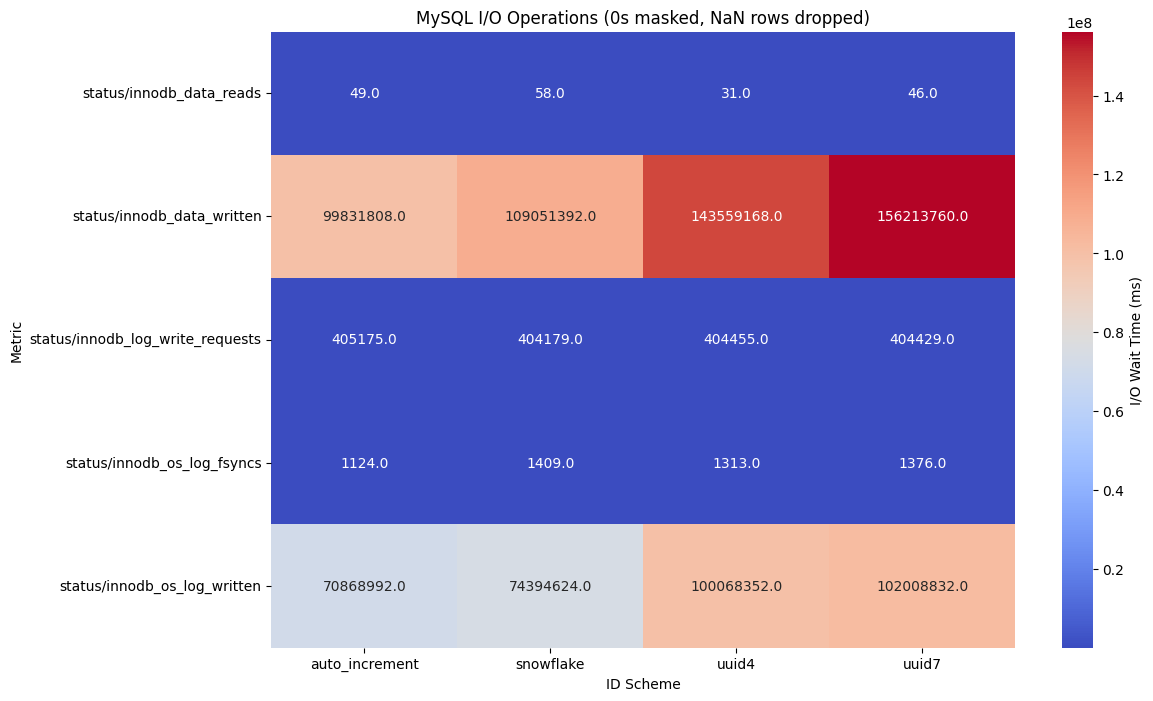
MySQL / InnoDB の I/O 統計
ランダムな ID(UUIDv4)は wait/io/file/innodb/innodb_log_file などの待機イベントを増加させ、Redo ログ競合やページ分割に起因する待機時間を増大させた。
一方、時系列性を持つ ID(AUTO_INCREMENT, UUIDv7, Snowflake)はクラスタ化インデックスとの整合性が高く、連続領域への書き込みが行われるため、I/O 待機が大幅に低減された。
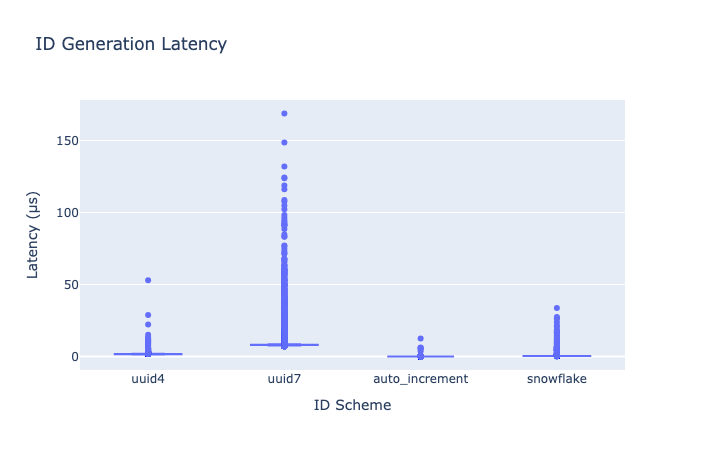
ID生成コスト比較
Python 側で各 ID 方式を 100 万回生成し、生成レイテンシの分布を計測した。
暗号学的乱数を使用する UUIDv4 は生成コストが高く、遅延分布の右裾が長い(high-tail latency)。
一方、UUIDv7 と Snowflake は時刻ベースで再現性のある ID を構成するため、CPU のみでナノ秒〜マイクロ秒単位の高速生成が可能であり、分布も安定している。
- UUIDv4:暗号乱数生成のため最も高コスト。分布のばらつきが大きい。
- UUIDv7 / Snowflake:時間情報を埋め込みつつ、軽量演算で一意IDを生成可能。レイテンシは極めて安定。
- AUTO_INCREMENT:生成自体は最小コストだが、分散構成では衝突回避・重複防止のための外部制御コストが別途発生する。
🧭 補足
この結果から、ID生成のオーバーヘッドは挿入性能だけでなく、I/O効率やキャッシュ局所性の最適化にも直結することが示唆される。
特に UUIDv7 と Snowflake は、生成・挿入・検索のすべてにおいてバランスが取れた設計である。
メモリ局所性の考察
時間順序性を持つIDは、近接した値が連続的に挿入されるため、キャッシュヒット率が向上する。
これにより、メモリアクセスの局所性が改善され、検索や更新処理の平均レイテンシを低減できる。
UUID4 のようなランダムIDはこの特性を持たないため、キャッシュ効率が低下する傾向にある。
ID方式の選択指針
| シナリオ | 推奨ID方式 |
|---|---|
| 単一DBで高性能重視 | Auto Increment |
| 分散環境で順序性を重視 | UUID7 |
| 完全分散で衝突回避を重視 | UUID4 |
| 高スループット分散処理が必要 | Snowflake |
結論
本ベンチマークにより、ID生成方式がデータベース性能に与える影響を定量的に明らかにした。
システム要件(分散性・性能・順序性・実装容易性)に応じて、適切な方式を選択することが重要である。
特に UUID7 は、UUID4 の分散性と Auto Increment の性能を両立しており、
現代の分散アプリケーションにおける最も実用的な選択肢のひとつといえる。