どうも、taikiです。
執筆背景
エンジニア界隈のみなさんなら、調査でQiitaのような技術ブログを使うことは頻繁にあるかと思いますが、同様に書籍をじっくり読む機会もあるかと思います。
技術ブログであれば内容が整理されており記憶もしやすく、困ったときにパッと手に取れるかと思いますが、これが本となると読み返すのが煩わしく感じることも多いと思います。
当記事では、そんな課題を解消すべく、AWSや生成AIを活用しながら、書籍内容を検索できるアプリを作りたいと思います。
※ 絶賛学習中のため、多めに見ていただけると助かります。
実現したいこと
今回作成するアプリでは、以下を実現できればと思います。
※ Part1では、インフラレベルでの動作検証までを書けたらと思います。
※ Part2では、アプリレベルの実装を行い、全体の動作検証までを書きたいです。
※ 最初はMVPを開発し、Part3では追加機能の実装やセキュリティ等の非機能面を検討できればベターかと思います。
1. Webアプリケーション経由で画像をアップロード
2. アップロードされた画像をS3に格納
3. S3に格納された画像をテキストに変換し、DBに格納
4. 書籍の内容について、アプリから検索
5. DBを検索し、AIが回答を返す
また、今回は個人開発を想定しており、コストを最小限に抑えるため、S3に格納された画像はすぐに削除したり、AIは格安モデルにするなど工夫していきたいと思います。
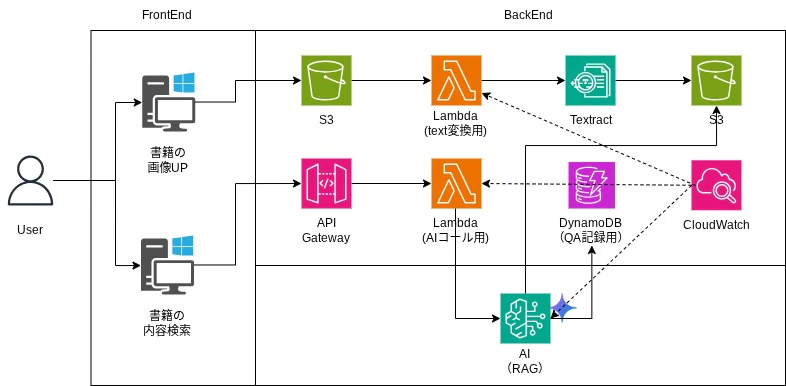
アーキテクチャ(Ver.1.0)
Part1時点での想定アーキテクチャは以下の通りです。
まずは、画像アップロード→OCR→テキスト保存→質問→AI回答、という一連の流れを動かすことを目標にします。
書籍の内容検索時、現時点ではS3のtxtファイルを見に行く構成としています。
将来的には、2回目以降はDynamoDBに格納されたやり取りを見に行くことで、過去の回答を再利用可能としたいと考えています。
AWSの設定など
インフラ(AWS)の設定や権限、課金させないための工夫などを以下に整理しました。
| リソース名 | 設定概要 | 課金回避のための工夫 | 必要な権限設定 |
|---|---|---|---|
| S3 | パブリックアクセス遮断 / CORS設定 | ライフサイクルで1日後に画像削除 |
s3:PutObject, s3:GetObject
|
| Lambda | メモリ128MB / arm64アーキテクチャ | タイムアウト設定 (30秒〜1分) | AWSLambdaBasicExecutionRole |
| DynamoDB | オンデマンドモード / Standardクラス | TTL設定による古い履歴の自動削除 |
dynamodb:PutItem, dynamodb:Query
|
| API Gateway | HTTP APIタイプを選択 | 月100万リクエストの無料枠活用 | lambda:InvokeFunction |
| Textract | 同期API (DetectDocumentText) を使用 |
まずは少量検証で利用量を抑制 | textract:DetectDocumentText |
| CloudWatch | ロググループを個別に設定 | 保持期間を1日〜3日に短縮 |
logs:CreateLogStream, logs:PutLogEvents
|
| IAM Role | 最小権限の原則 (Least Privilege) を意識 | 不要な管理ポリシーの付与を避ける | 上記各サービスの操作権限を統合 |
| AWS Budgets | 1ドルのアラートしきい値設定 | 予算超過時の即時メール通知 |
budgets:ViewBudgets (参照用) |
| Gemini API | Lambda環境変数にAPIキーを格納 | Google AI Studioの無料枠を利用 | (AWS外のためIAM不要) |
AWSアカウントの発行
まずは、AWSアカウントを発行します。こちらの公式手順が参考になりました。
また、AWSアカウントのルートユーザー(AWSアカウント作成時に作成されるユーザー)を使うことは推奨されておりませんので、IAMユーザーを作成・利用します。こちらの手順が参考になりました。
S3の作成
AWSアカウントの発行が完了したら、早速AWSリソースの作成に移ります。
まずは、S3を作成します。当サービスの機能として、①フロントアプリから画像をアップロード ②Textractで抽出した文字列データを格納することが求められるため、一つのS3バケットに2つのプレフィックスを作成します。
| S3バケット名 | 設定概要 | プレフィックス |
|---|---|---|
| (例) book-chat-project-sample | ・バケットタイプ:汎用 ・ACL無効 ・パブリックアクセス:すべてブロック ・バージョニング:無効 ・デフォルト暗号化:SSE-S3 ・オブジェクトロック:無効 |
images/ |
| 同バケット内で作成 | - | texts/ |
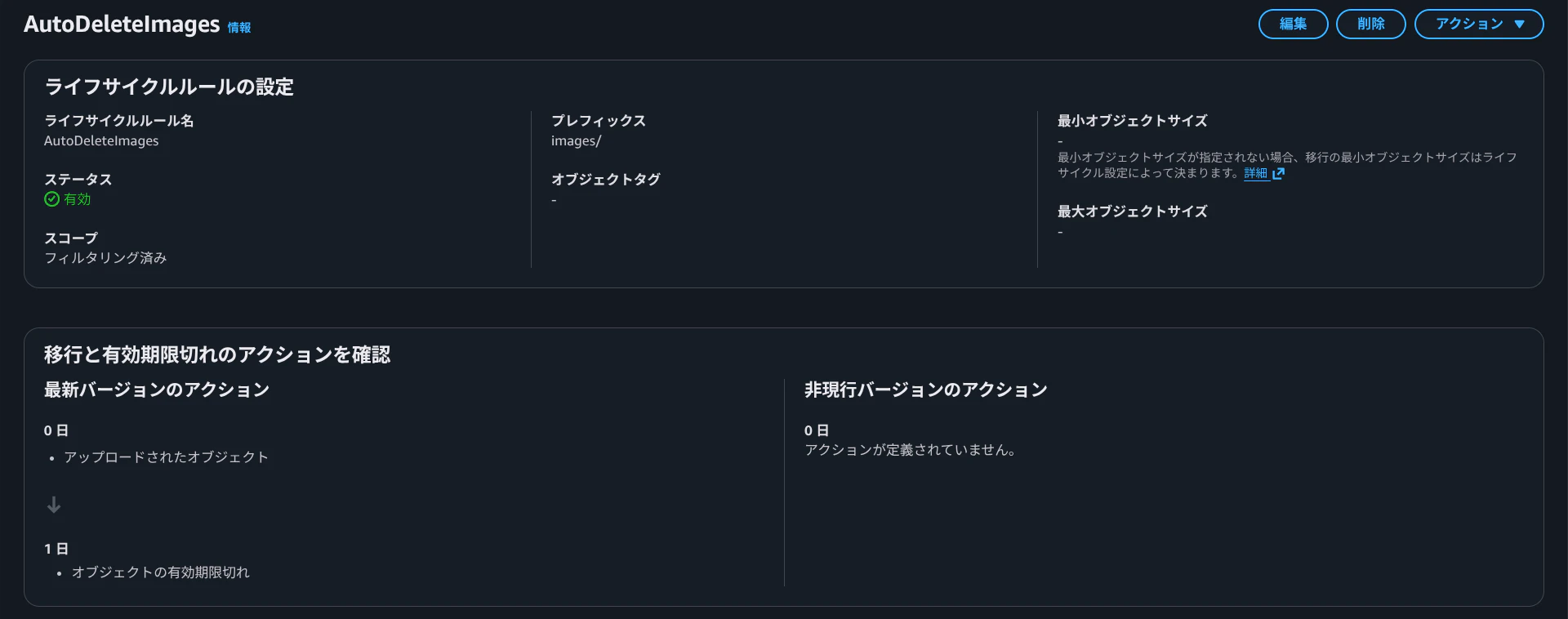
Webアプリ経由でアップロードされた画像がS3で長期間保存されると課金が発生するため、ライフサイクルルールで1日後に画像が削除されるように設定しておく。
OCR後のテキストを長期保存したい場合は、images/ と texts/ で別ルールにしておくと運用しやすいです。
ご参考:
https://qiita.com/miyuki_samitani/items/cbea495fb116b5bf5db6
DynamoDBの作成
続いて、データベースを作成します。今回は、サーバーレス構成との相性が良く、小さく始めやすいという理由から、DynamoDBを選定しました。基本設定は以下の通りです。
| テーブル名 | 設定概要 |
|---|---|
| (例)BookChatHistory | ・パーティションキー:userId(String) ・ソートキー:timestamp (Number) ・キャパシティモード:オンデマンド ・TTL属性名:expiresAt |
プロビジョニング(予約制)と違い、オンデマンドではリクエスト毎に課金されるため、基本料金を0円に抑えやすいです。
TTL(有効期限)の expiresAt を設定することで、AWS側でテーブル内のデータを自動削除してくれます。テキストデータのチリツモでの課金を防いだり、AIの回答鮮度を高めることにつながると考えています。
IAMロールの作成
Lambdaに他リソースへの権限を付与するため、IAMロールを作成します。
基本設定は以下の通りです。
冒頭の構成図の通り、S3やTextract、DynamoDB、CloudWatch(ログ出力用)のためのポリシー追加が必要となります。
まずは学習・疎通確認を優先し、動くことを確認した上で、後から最小権限化していく想定です。
| IAMロール名 | 許可ポリシー |
|---|---|
| (例)BookChatProjectRole | ・AWSLambdaBasicExecutionRole ・AmazonS3FullAccess ・AmazonTextractFullAccess ・AmazonDynamoDBFullAccess |
本番運用や継続運用を前提とする場合、FullAccess 系ポリシーは避け、対象バケット・対象テーブル・必要操作に絞った最小権限ポリシーへ置き換えることを推奨します。
Lambdaの作成
本システムの心臓部であるLambdaを作成していきます。
コスト節約のため、「必要なときに最小限動作する」ことを意識しました。
| Lambda名 | 説明 | ランタイム名 | アーキテクチャ名 | 備考 |
|---|---|---|---|---|
| (例)book-ocr-processor | OCR用Lambda。S3に画像が置かれた瞬間に、Textractへ文字起こしを依頼。 | Python 3.12 | arm64 | ・トリガー設定: S3の images/ プレフィックスに限定して無限ループを防止 |
| (例)book-chat-engine | Chat用Lambda。API Gateway経由で質問を受け、S3の知識とDynamoDBの履歴をGeminiに渡す | Python 3.12 | arm64 | ・タイムアウト: Geminiの回答待ちを考慮し 60秒 に延長 ・環境変数: GEMINI_API_KEY を安全に格納 |
OCR用Lambda(book-ocr-processor)
以下は、S3に画像がアップロードされたらTextractで文字起こしし、その結果を texts/ 配下へ保存するLambdaです。
OCR用Lambda(book-ocr-processor)のコード
import boto3
import urllib.parse
import os
s3 = boto3.client('s3')
textract = boto3.client('textract')
def lambda_handler(event, context):
key = None
try:
record = event['Records'][0]
bucket = record['s3']['bucket']['name']
# S3キー例: images/堅牢なシステム_p12.png
key = urllib.parse.unquote_plus(record['s3']['object']['key'], encoding='utf-8')
# 1. Textractで解析
response = textract.detect_document_text(
Document={'S3Object': {'Bucket': bucket, 'Name': key}}
)
# 2. テキスト抽出
text_content = "\n".join(
item['Text'] for item in response['Blocks'] if item['BlockType'] == 'LINE'
)
# 3. 命名規則に従ってテキスト用フォルダへ保存
# images/xxx_p12.png -> texts/xxx_p12.txt
output_key = key.replace('images/', 'texts/')
output_key = os.path.splitext(output_key)[0] + ".txt"
s3.put_object(
Body=text_content.encode('utf-8'),
Bucket=bucket,
Key=output_key,
ContentType='text/plain; charset=utf-8'
)
print(f"Successfully processed {key} to {output_key}")
return {"status": "success", "file": output_key}
except Exception as e:
print(f"Error processing {key if key else 'unknown key'}: {str(e)}")
raise
Chat用Lambda(book-chat-engine)
現時点では、質問時にS3上のOCR済みテキストを読み込み、AIに渡して回答を生成するシンプルな構成としています。
DynamoDBには会話履歴の保存のみを行い、過去回答の再利用は今後の改善項目です。
Chat用Lambda(book-chat-engine)のコード
import json
import os
import boto3
import time
import requests
s3 = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('BookChatHistory')
def lambda_handler(event, context):
try:
body = json.loads(event.get('body', '{}'))
user_id = body.get('userId', 'default_user')
book_title = body.get('bookTitle', '') # UIから入力された書籍名
query = body.get('query', '') # 「調べたい内容」
if not book_title or not query:
return create_response(400, {"message": "書籍名と検索内容は必須です"})
# 1. S3から該当書籍のテキストを全取得 (RAGの簡易実装)
# texts/書籍名_p*.txt に一致するものを探す
prefix = f"texts/{book_title}"
response_s3 = s3.list_objects_v2(
Bucket=os.environ['BUCKET_NAME'],
Prefix=prefix
)
combined_text = ""
found_pages = []
if 'Contents' in response_s3:
for obj in response_s3['Contents']:
content = s3.get_object(
Bucket=os.environ['BUCKET_NAME'],
Key=obj['Key']
)['Body'].read().decode('utf-8')
page_info = obj['Key'].split('_p')[-1].replace('.txt', '')
combined_text += f"\n--- Page {page_info} ---\n{content}"
found_pages.append(page_info)
if not combined_text:
return create_response(404, {"message": f"書籍 '{book_title}' のデータが見つかりませんでした"})
# 2. Gemini API プロンプト構成
prompt = f"""あなたは技術書籍の専門アシスタントです。
提供された以下の【書籍の内容】に基づいて、ユーザーの質問に回答してください。
不明な場合は、不明と回答してください。
回答の末尾には、参照したページ番号を記載してください。
【書籍の内容】
{combined_text}
【質問】
{query}
"""
# 3. Gemini API 呼び出し
api_key = os.environ['GEMINI_API_KEY']
url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={api_key}"
gemini_res = requests.post(
url,
json={"contents": [{"parts": [{"text": prompt}]}]},
timeout=50
)
gemini_res.raise_for_status()
answer = gemini_res.json()['candidates'][0]['content']['parts'][0]['text']
# 4. 履歴をDynamoDBに保管
now = int(time.time())
table.put_item(Item={
'userId': user_id,
'timestamp': now,
'bookTitle': book_title,
'query': query,
'answer': answer,
'pagesReferenced': found_pages,
'expiresAt': now + (30 * 86400)
})
return create_response(200, {"answer": answer})
except Exception as e:
print(f"Error: {str(e)}") # CloudWatchに出力される
return create_response(500, {"error": "システムエラーが発生しました"})
def create_response(status_code, body):
return {
'statusCode': status_code,
'headers': {
'Access-Control-Allow-Origin': '*',
'Content-Type': 'application/json'
},
'body': json.dumps(body, ensure_ascii=False)
}
今回はコスト効率を重視し、x86より安価な arm64 (AWS Graviton系) アーキテクチャを採用しています。
Lambda Layer作成時も、必ず arm64 を選択しないと、実行時にバイナリ互換性のエラーが出るため注意してください。
Lambda Layerの導入
外部API利用のために「requests」というライブラリをインストールする必要があります。今回は、Lambda Layerで共通関数として用意し、Chat用Lambdaから呼び出される構成にしています。
まず、Layerの構成イメージは以下の通りです。
requests用 Lambda Layer 構成
requests_layer.zip
└─ python/
├── requests/ # インストールされたライブラリ本体
├── urllib3/ # requestsの依存ライブラリ
└── ... (その他依存関係)
Lambda Layer導入手順
まず、ローカル環境などでZipファイルを作成します。
ローカル環境でのZip化手順
1. フォルダ作成 mkdir python-
フォルダ内にライブラリをインストール
--target (-t) を使うのがポイントです
pip install requests -t python/ -
pythonフォルダごとzip化
zip -r requests_layer.zip python
※ 注意
zipコマンドが通らない場合、aptコマンドなどでインストール後にコマンドを再実行する
その後、ローカル環境で作成したrequestsのZipファイルをLambda Layerに登録し、対象の関数に適用します。
Lambda Layerを登録
Lambdaコンソール 左メニューの「レイヤー」をクリック
「レイヤーの作成」ボタンをクリック
名前: requests-layer
アップロード: 作成した requests_layer.zip を選択
アーキテクチャ: arm64 をチェック
ランタイム: Python 3.12 を選択
その後、「作成」をクリック
Lambda Layerを適用
対象のLambda関数(book-chat-engine)を開く
画面最下部までスクロールし、「レイヤー」セクションの「レイヤーの追加」をクリック
「カスタムレイヤー」を選択し、作成した requests-layer とそのバージョンを選択して「追加」
Lambda Layerを採用するメリットは、外部ライブラリを分離することで、関数本体を軽量に保ちAWSコンソール上で直接コード編集・テストしやすくなることです。
また、共通ライブラリを一元管理できるため、複数関数のメンテナンス効率も向上します。
API Gatewayの設定
続いて、Chat用Lambdaを外部から呼び出せるように、API Gatewayを設定します。
今回はシンプルに扱いやすい HTTP API を採用しました。
基本設定は以下の通りです。
| IAMロール名 | 許可ポリシー |
|---|---|
| 項目 | 設定内容 |
| APIタイプ | HTTP API |
| API名 | (例)book-chat-api |
| 統合先 | book-chat-engine Lambda |
| ルート | POST /chat |
| ステージ | $default または任意名称 |
| CORS | 有効化 |
設定手順のイメージは以下の通りです。
※ 今回は、フロントエンドや curl からJSONをPOSTする想定のため、POST /chat というシンプルな構成にしています。
1. AWSコンソールで API Gateway を開く
2. 「APIを作成」→「HTTP API」を選択
3. 統合先として book-chat-engine Lambda を指定
4. ルートに POST /chat を作成
5. CORSを有効化
6. 作成後、発行されたエンドポイントURLを控える
REST API ではなく HTTP API を選定した理由は、まずは安価かつシンプルに疎通確認を行いたかったためです。個人開発のMVPとしては十分だと考えています。
Amazon Textractの設定
Textractについては、今回は専用の事前リソース作成は行わず、OCR用Lambdaから DetectDocumentText API を直接呼び出す構成にしました。
基本的な考え方は以下の通りです。
| 項目 | 設定内容 |
|---|---|
| 利用API | DetectDocumentText |
| 呼び出し元 | OCR用Lambda |
| 入力 | S3上の画像ファイル |
| 出力 | 抽出された文字列(Lambda内で整形し、S3へ保存) |
DetectDocumentText は、まず文字列抽出を試すには扱いやすく、今回のMVPには十分でした。
一方で、以下のような注意点もあると感じています。
・ 画像の解像度や傾きによってOCR精度が変わる
・ 見開きページや複雑なレイアウトでは精度が下がる場合がある
・ 利用量が増えると従量課金が効いてくる
そのため、まずは単純な書籍ページ画像を対象として、少量で検証することにしました。
Amazon CloudWatchの設定
CloudWatchは、Lambdaの実行ログ確認用として利用します。
今回のようなサーバーレス構成では、処理がどこで失敗したかを追えることが重要になるため、最低限のログ確認環境を整えておきます。
基本設定の考え方は以下の通りです。
| 項目 | 設定内容 |
|---|---|
| 対象 | OCR用Lambda / Chat用Lambda |
| 用途 | 実行ログ確認、エラー確認 |
| 保持期間 | 1日〜3日程度(短め推奨) |
特に以下の流れはCloudWatchで確認できるようにしておくと便利です。
・ S3アップロード
・ OCR用Lambda起動
・ Textract実行
・ texts/ への保存
・ Chat用Lambda起動
・ Gemini API呼び出し
・ DynamoDB保存
CloudWatch Logsも保存期間が長いと少額ながらコストが積み上がるため、学習・検証用途では保持期間を短くしておくのがおすすめです。
Lambdaの送信元(トリガー)および送信先(アクション)の設定
今回の構成では、主に以下2系統の連携を設定します。
| Lambda名 | 送信元(トリガー) | 送信先(アクション) |
|---|---|---|
| book-ocr-processor | S3 (images/ へのオブジェクト作成) | Textract実行 → S3 (texts/) へ保存 |
| book-chat-engine | API Gateway (POST /chat) | S3参照 → Gemini API呼び出し → DynamoDB保存 |
OCR用Lambdaのトリガー設定
OCR用Lambdaは、S3の images/ プレフィックス配下に画像がアップロードされた時だけ起動するよう設定します。
設定イメージは以下の通りです。
イベントソース: S3
バケット: 作成した対象バケット
イベントタイプ: PUT
プレフィックス: images/
これにより、texts/ 配下へ保存した .txt ファイルには反応せず、無限ループを防止できます。
Chat用Lambdaのトリガー設定
Chat用Lambdaは、API Gatewayから起動する構成にします。
イベントソース: API Gateway
メソッド: POST
パス: /chat
アプリや curl から以下のようなJSONを送る想定です。
{
"userId": "test-user",
"bookTitle": "堅牢なシステム",
"query": "この本でいう冪等性とは何ですか?"
}
CORS設定
フロントエンドからS3やAPI Gatewayへアクセスする場合、CORS設定が必要になります。
今回はMVP段階のため、まずは疎通確認をしやすい設定とし、本番では必要最小限に絞る前提で進めます。
API Gateway側のCORS
API Gatewayでは、以下を許可する設定としました。
| 項目 | 設定例 |
|---|---|
| Allowed Methods | POST, OPTIONS |
| Allowed Headers | Content-Type |
| Allowed Origins | 開発環境のURL(例: http://localhost:3000) |
S3側のCORS
フロントエンドから画像を直接アップロードする場合、S3バケットにもCORS設定が必要です。
設定例は以下の通りです。
[
{
"AllowedHeaders": ["*"],
"AllowedMethods": ["GET", "PUT", "POST"],
"AllowedOrigins": ["http://localhost:3000"],
"ExposeHeaders": []
}
]
開発段階では localhost を許可しておくと便利ですが、本番環境では必ず実際のデプロイ先ドメインに絞るようにしたいです。
疎通確認(インフラレイヤー)
ここまで設定できたら、最低限以下の流れで疎通確認を行えます。
確認手順
1 S3の images/ 配下に画像をアップロード
2 OCR用Lambdaが起動していることをCloudWatchで確認
3 texts/ 配下に .txt ファイルが生成されていることを確認
4 API Gateway経由でChat用Lambdaへリクエスト送信
5 AIから回答が返ってくることを確認
6 DynamoDBに履歴が保存されていることを確認
疎通確認用の curl 例は以下です。
curl -X POST "https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/chat" \
-H "Content-Type: application/json" \
-d '{
"userId": "test-user",
"bookTitle": "堅牢なシステム",
"query": "この本でいう冪等性とは何ですか?"
}'
ここで確認したい観点は以下の通りです。
・ OCR用Lambdaが正常終了しているか
・ texts/ 配下に期待通りのファイル名で保存されているか
・ Chat用Lambdaが対象書籍のテキストを読めているか
・ Gemini APIからレスポンスが返ってきているか
・ DynamoDBに履歴が残っているか
現時点では、質問時にS3上のOCR済みテキストを都度読み込むシンプルな構成としています。
DynamoDBは履歴保存用途が中心であり、過去回答の再利用は今後の改善項目です。
今後について
今回は、書籍検索アプリのMVPに向けて、まずはAWSインフラの構築と疎通確認までを整理しました。
今回の構成でも最低限の動作確認はできますが、今後改善したいポイントも多くあります。
・ 質問のたびにS3上のテキストを都度読み込むため、ページ数が増えると遅くなる
・ 類似質問に対する回答キャッシュは未実装
・ OCR結果の品質は画像の解像度や傾きに依存する
・ 書籍名とファイル名の命名規則に依存している
・ IAM権限は現時点では検証優先のため、後続で最小権限化したい
Part2では、以下の通り進めたらと考えています。
・ フロントエンドからの画像アップロード実装
・ API Gatewayとアプリの接続
・ 書籍検索UIの実装
・ 回答結果の見せ方の調整
・ DynamoDBの履歴再利用ロジックの検討
まずは「動くものを小さく作る」ことを優先しつつ、少しずつ使いやすさや運用性を高めていければと思います。