はじめに
前回に引き続き、PyTorch 公式チュートリアル の第8弾です。
今回は TorchVision Object Detection Finetuning Tutorial を進めます。
TorchVision Object Detection Finetuning Tutorial
このチュートリアルでは、事前トレーニング済みの Mask R-CNN を利用し、ファインチューニング、転移学習を見ていきます。
学習に利用するデータは歩行者の検出とセグメンテーションのためのPenn-Fudanデータです。このデータは、歩行者(インスタンス)が345人いる、170個の画像が用意されています。
まず、pycocotools のライブラリをインストールする必要があります。このライブラリは、「Intersection over Union」 と呼ばれる評価の計算に使用されます。
「Intersection over Union」 は、物体検知における領域の一致具合を評価する手法の1つです。
※ 2020.10.18 時点では Colaboratory に pycocotools がすでにインストールされています。以下のコード( pip install )は実行しなくても進めることができました。
%%shell
pip install cython
# pycocotoolsをインストールします。Colabのデフォルトのバージョンには、https://github.com/cocodataset/cocoapi/pull/354 で修正されたバグがあります。
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
Defining the Dataset(データセットを定義する)
データセットを定義します。
Mask R-CNN で学習されたモデルを利用するため、データセットには特定の属性が必要です。
torchvision のスクリプト (オブジェクト検出、インスタンスセグメンテーション、人物キーポイント検出のライブラリ)を利用することで必要なデータセットを作成することができます。
データセットには以下のような属性が必要です。
- image:サイズ(H、W)のPIL画像
- target:次のフィールドを含む辞書(dict)
- boxes(FloatTensor [N, 4]):[x0, y0, x1, y1]形式の N bounding box の座標。範囲は 0〜W および 0〜H
- labels(Int64Tensor [N]):各境界ボックスのラベル
- image_id(Int64Tensor [1]):画像識別子。データセット内のすべての画像間で一意である必要があり、評価中に使用されます。
- area(Tensor [N]):バウンディングボックスの領域。これは、COCOメトリックでの評価中に、小、中、大のボックス間でメトリックスコアを分離するために使用されます。
- iscrowd(UInt8Tensor [N]):iscrowd = Trueのインスタンスは評価中に無視されます。
- masks(オプション)(UInt8Tensor [N, H, W]):各オブジェクトのセグメンテーションマスク(検知する物体の領域を表します)
- keypoints(オプション)(FloatTensor [N, K, 3]):N個のオブジェクトのそれぞれについて、オブジェクトを定義する[x, y, visibility]形式のKキーポイントが含まれます。 visibility = 0は、キーポイントが表示されないことを意味します。データ拡張(Data Augmentation)の場合、キーポイントを反転する概念はデータ表現に依存することに注意してください。
(データセットをざっくり説明すると、boxes で物体を含む四角形を定義し、masks でピクセル単位で物体か否かを定義します。)
モデルが上記のメソッドを返す場合、モデルはトレーニングと評価の両方で機能し、pycocotoolsの評価スクリプトが使用されます。
Writing a custom dataset for Penn-Fudan (Penn-Fudanのカスタムデータセットの作成)
Penn-Fudanデータセットのデータセットを出力してみましょう。
まず、
https://www.cis.upenn.edu/~jshi/ped_html/PennFudanPed.zip
のzipファイルをダウンロードして解凍します。
%%shell
# download the Penn-Fudan dataset
wget https://www.cis.upenn.edu/~jshi/ped_html/PennFudanPed.zip .
# extract it in the current folder
unzip PennFudanPed.zip
データは次のような構成になっています。
PennFudanPed/
PedMasks/
FudanPed00001_mask.png
FudanPed00002_mask.png
FudanPed00003_mask.png
FudanPed00004_mask.png
...
PNGImages/
FudanPed00001.png
FudanPed00002.png
FudanPed00003.png
FudanPed00004.png
最初の画像を表示してみます。
from PIL import Image
Image.open('PennFudanPed/PNGImages/FudanPed00001.png')

(解凍した readme.txt に記載がありますが、マスク画像は 背景が「0」、歩行者ごとに 1 以上のラベルを付けた画像です。)
mask = Image.open('PennFudanPed/PedMasks/FudanPed00001_mask.png')
# 各マスクインスタンスは、ゼロからNまでの異なる色を持っています。
# ここで、Nはインスタンス(歩行者)の数です。視覚化を容易にするために、
# マスクにカラーパレットを追加しましょう。
mask.putpalette([
0, 0, 0, # black background
255, 0, 0, # index 1 is red
255, 255, 0, # index 2 is yellow
255, 153, 0, # index 3 is orange
])
mask

今回のデータは、各画像と歩行者を識別したマスクがあり、マスクの各色は個々の歩行者に対応します。
このデータセットのtorch.utils.data.Datasetクラスを作成しましょう。
import os
import numpy as np
import torch
import torch.utils.data
from PIL import Image
class PennFudanDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
# すべての画像ファイルをロードし、並べ替えます
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def __getitem__(self, idx):
# 画像とマスクを読み込みます
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = Image.open(img_path).convert("RGB")
# 各色は異なるインスタンスに対応し、0が背景であるため、
# マスクをRGBに変換していないことに注意してください
mask = Image.open(mask_path)
mask = np.array(mask)
# インスタンスは異なる色としてエンコードされます
obj_ids = np.unique(mask)
# 最初のIDは背景なので、削除します
obj_ids = obj_ids[1:]
# split the color-encoded mask into a set
# of binary masks
# 色分けされたマスクをバイナリマスクのセットに分割します
masks = mask == obj_ids[:, None, None]
# get bounding box coordinates for each mask
# 各マスクのバウンディングボックス座標を取得します
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
# クラスは1つだけです
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
# すべてのインスタンスが混雑していないと仮定します
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
データセットは以上です。このデータセットの出力がどのように構成されているかを見てみましょう
dataset = PennFudanDataset('PennFudanPed/')
dataset[0]
(<PIL.Image.Image image mode=RGB size=559x536 at 0x7FC7AC4B62E8>,
{'area': tensor([35358., 36225.]), 'boxes': tensor([[159., 181., 301., 430.],
[419., 170., 534., 485.]]), 'image_id': tensor([0]), 'iscrowd': tensor([0, 0]), 'labels': tensor([1, 1]), 'masks': tensor([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)})
データセットはPIL.Imageと、boxes、labels、masksなどのいくつかのフィールドを含む辞書を返すことがわかります。
チュートリアルにはありませんが、以下のコードで boxes と mask を図示できます。
boxes はインスタンス(人)を含んだ四角形で、masks がインスタンスそのものです。
import matplotlib.pyplot as plt
import matplotlib.patches as patches
fig, ax = plt.subplots()
target = dataset[0][1]
# 1番目のインスタンスの masks
masks_0 = target['masks'][0,:,:]
# 1番目のインスタンスの boxes
boxes_0 = target['boxes'][0]
# mask を出力します
ax.imshow(masks_0)
# boxes を出力します
ax.add_patch(
patches.Rectangle(
(boxes_0[0], boxes_0[1]),boxes_0[2] - boxes_0[0], boxes_0[3] - boxes_0[1],
edgecolor = 'blue',
facecolor = 'red',
fill=True,
alpha=0.5
) )
plt.show()

Defining your model
このチュートリアルでは、FasterR-CNNをベースにしたMaskR-CNNを使用します。 Faster R-CNNは、物体検出アルゴリズムの1つで、画像内の潜在的なオブジェクトの境界ボックスとクラススコア(物体を含む四角形と、物体が何か)の両方を予測するモデルです。(下の画像は Faster R-CNN の処理イメージです)

Mask R-CNNは、Faster R-CNN の改良版で 物体検知を四角形(box)で判断するだけではなく、ピクセル単位(mask)で判定します。
(下の画像は Mask R-CNN の処理イメージです)

torchvision でモデルをカスタマイズする場合、主な理由は2つあります。
1つ目は、事前にトレーニングされたモデルを利用し、最後のレイヤーを微調整する場合です。
もう1つは、モデルのバックボーンを別のバックボーンに置き換えたい場合です。(例えば、より高速な予測のため)
具体例で説明します。
1. Finetuning from a pretrained model(事前トレーニング済みモデルのファインチューニング)
事前にトレーニングされたモデルを利用して、自分が識別したいクラスに合わせてファインチューニングする方法は次のとおりです。
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
# COCOで事前トレーニング済みのモデルをロードする
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# 分類器を、ユーザー定義の num_classes を持つ新しい分類器に置き換えます
num_classes = 2 # 1 class (person) + background : 1クラス(人)+背景
# 分類器の入力特徴数を取得します
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 事前にトレーニングされた HEAD を新しいものと交換します
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
2. Modifying the model to add a different backbone(モデルを変更して別のバックボーンを追加する)
もう一方のケースは、モデルのバックボーンを別のバックボーンに置き換えたい場合です。例えば、現在のデフォルトのバックボーン(ResNet-50)は、状況によっては大きすぎる可能性があり、より小さなモデルを利用したい場合があります。
以下に、torchvision を活用してバックボーンを変更する方法を記します。
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 分類のために事前にトレーニングされたモデルをロードし、機能のみを返します
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# FasterRCNNは、バックボーン内の出力チャネルの数を知る必要があります。
# mobilenet_v2の場合は1280なので、ここに追加する必要があります
backbone.out_channels = 1280
# RPNに、5つの異なるサイズと3つの異なるアスペクト比で、
# 空間位置ごとに5 x3のアンカーを生成させましょう。
# 各フィーチャマップのサイズとアスペクト比が異なる可能性があるため、
# Tuple [Tuple [int]]があります。
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 関心領域のトリミングを実行するために使用するフィーチャマップと、
# 再スケーリング後のトリミングのサイズを定義しましょう。
# バックボーンがTensorを返す場合、featmap_namesは[0]であると予想されます。
# より一般的には、バックボーンはOrderedDict [Tensor]を返す必要があり、
# featmap_namesで使用するフィーチャマップを選択できます。
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
# FasterRCNNモデル内にピースをまとめます
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
An Instance segmentation model for PennFudan Dataset(PennFudanデータセットのインスタンスセグメンテーションモデル)
今回のケースでは、データセットが非常に小さいため、事前にトレーニングされたモデルを微調整します。従って、アプローチ番号 1 に従います。
ここでは、インスタンスのセグメンテーションマスクも計算するため(人物の領域をピクセル単位で判定するため)、Mask R-CNNを使用します。
※このチュートリアルで利用するモデルは、torchvision の maskrcnn_resnet50_fpn です。
maskrcnn_resnet50_fpn は 公式ドキュメント で説明されていますが、ResNet-50-FPNをカスタマイズしたモデルです。
maskrcnn_resnet50_fpn は COCO train2017 のデータセットで事前学習されています。
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_instance_segmentation_model(num_classes):
# COCOで事前トレーニングされたインスタンスセグメンテーションモデルをロードする
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# 分類器の入力特徴数を取得します
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 事前にトレーニングされた HEAD を新しいものと交換します
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# mask 分類器の入力特徴数を取得します
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
# and replace the mask predictor with a new one
# マスク予測器を新しいものと交換します
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model
これで、今回のデータセットでモデルをトレーニングおよび評価する準備が整いました。
(今回のモデルと torchvision.models.detection.maskrcnn_resnet50_fpn を比較してみると、以下の箇所 の次元が変わっていることが確認できます。)
(roi_heads): RoIHeads(
・・・
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=2, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=8, bias=True)
)
・・・
(mask_predictor): MaskRCNNPredictor(
・・・
(mask_fcn_logits): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))
)
)
Training and evaluation functions (トレーニングおよび評価関数)
torchvision の vision/references/detection/ には、物体検出モデルのトレーニングと評価を簡素化するための多数のヘルパー関数があります。ここでは、references/detection/engine.py, references/detection/utils.py , references/detection/transforms.pyを使用します。
これらのファイル(と関連するファイル)をコピーして、使用できるようにします。
%%shell
# Download TorchVision repo to use some files from
# references/detection
git clone https://github.com/pytorch/vision.git
cd vision
git checkout v0.3.0
cp references/detection/utils.py ../
cp references/detection/transforms.py ../
cp references/detection/coco_eval.py ../
cp references/detection/engine.py ../
cp references/detection/coco_utils.py ../
コピーした refereces/detection を利用して、データの拡張/変換用のヘルパー関数をいくつか作成しましょう。
from engine import train_one_epoch, evaluate
import utils
import transforms as T
def get_transform(train):
transforms = []
# 画像を Tensor に変換します
transforms.append(T.ToTensor())
if train:
# トレーニングの場合、ランダムに画像と教師データを水平方向に反転します。(鏡に映すイメージ)
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
上記のコードは、データの下処理です。
画像を Tensor に変換し、学習データの場合はランダムに反転します。
データの標準化や画像の再スケーリングは不要です。Mask R-CNN モデルが内部でやってくれます。
Putting everything together (すべてをまとめる)
これで、データセット、モデル、およびデータ下処理が準備できました。それらをインスタンス化しましょう。
# データセットと定義された変換を使用します
dataset = PennFudanDataset('PennFudanPed', get_transform(train=True))
dataset_test = PennFudanDataset('PennFudanPed', get_transform(train=False))
# トレーニングデータとテストデータでデータセットを分割します
torch.manual_seed(1)
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-50])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:])
# トレーニングと検証のデータローダーを定義します
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=4,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=4,
collate_fn=utils.collate_fn)
モデルをインスタンス化します。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# 教師データは、背景と人の2クラスのみです
num_classes = 2
# ヘルパー関数を使用してモデルを取得します
model = get_instance_segmentation_model(num_classes)
# モデルを適切なデバイスに移動します
model.to(device)
# オプティマイザを構築します
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# 学習率を3エポックごとに10分の1に減らす学習率スケジューラ
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
10エポックでトレーニングします。
各エポックで evaluate 関数で評価します。
(Colaboratory の GPU 環境だと学習に8分程度かかります。None GPU だと実行時エラーが発生します。)
# 10エポックでトレーニング
num_epochs = 10
for epoch in range(num_epochs):
print(epoch)
# 1エポックのトレーニング
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# 学習率を更新する
lr_scheduler.step()
# テストデータセットで評価する
evaluate(model, data_loader_test, device=device)
...
Averaged stats: model_time: 0.1179 (0.1174) evaluator_time: 0.0033 (0.0051)
Accumulating evaluation results...
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.831
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.990
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.955
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.543
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.841
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.386
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.881
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.881
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.787
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.887
IoU metric: segm
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.760
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.990
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.921
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.492
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.771
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.345
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.808
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.808
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.725
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.814
※ 評価として上記が出力されます。
evaluate(テストデータの評価)は、以下に解説があるようですので機会があれば調べてみたいと思います。
https://cocodataset.org/#detection-eval
トレーニングが終了したので、テストデータセットでどのような結果になるか見てみましょう。
# テストセットから1つの画像を選択します
img, _ = dataset_test[4]
# モデルを評価モードにします
model.eval()
with torch.no_grad():
prediction = model([img.to(device)])
予測(prediction)を出力すると、辞書のリストになっています。
テストデータを1つ指定したため、下の例ではリストの要素は1つです。
辞書には、画像の予測が含まれています。
この場合、boxes、labels、masks、score が含まれていることが分かります。
prediction
[{'boxes': tensor([[173.1167, 27.6446, 240.8375, 313.0114],
[325.5737, 64.3967, 453.1539, 352.3020],
[222.4494, 24.5255, 306.5306, 291.5595],
[296.8205, 21.3736, 379.0592, 263.7513],
[137.4137, 38.1588, 216.4886, 276.1431],
[167.8121, 19.9211, 332.5648, 314.0146]], device='cuda:0'),
'labels': tensor([1, 1, 1, 1, 1, 1], device='cuda:0'),
'masks': tensor([[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]], device='cuda:0'),
'scores': tensor([0.9965, 0.9964, 0.9942, 0.9696, 0.3053, 0.1552], device='cuda:0')}]
画像と予測結果を確認します。
画像(img)は [ 色 , 縦 , 横 ] の Tensor です。
色は 0 - 1 のため 0 - 255 にスケーリングし、 [ 縦 , 横 , 色 ] に入れ替えます。
Image.fromarray(img.mul(255).permute(1, 2, 0).byte().numpy())
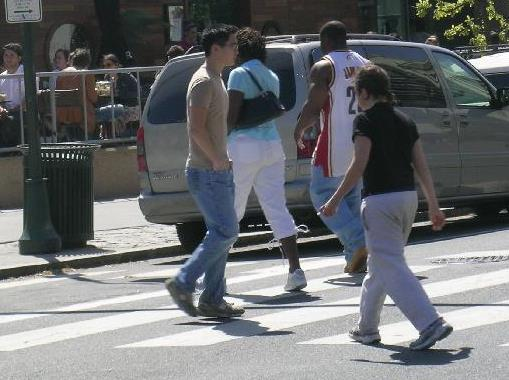
次に、予測したマスクを可視化します。masksは [N、1、H、W]として予測されます。ここで、 Nは予測したインスタンス(人)の数です。
mask の各値には、ピクセル単位で「人」と判断した度合いの確率が 0-1 で格納されています。
Image.fromarray(prediction[0]['masks'][0, 0].mul(255).byte().cpu().numpy())

(以下のように N の値を変えることで他の予測したインスタンス(人)も可視化できます。)
Image.fromarray(prediction[0]['masks'][1, 0].mul(255).byte().cpu().numpy())

Image.fromarray(prediction[0]['masks'][2, 0].mul(255).byte().cpu().numpy())

Image.fromarray(prediction[0]['masks'][3, 0].mul(255).byte().cpu().numpy())

うまく予測できています。
Wrapping up (まとめ)
このチュートリアルでは、自分で定義したデータセットを利用し、物体検知モデルのトレーニングを行う処理を学びました。
データセットは、物体検知特有のデータセットを定義するため、box, maskを保持する torch.utils.data.Datasetクラスを作成しました。
また、この新しいデータセットで転移学習を実行するために、COCOtrain2017で事前トレーニングされたMaskR-CNNモデルを活用しました。
マルチマシン/マルチGPUトレーニングの詳しい例を知りたい方は、torchvision GitHub repoにある references/detection/train.py を確認してください。
終わりに
このチュートリアルでは、事前学習済みのモデルを利用する「転移学習」「ファインチューニング」を学びました。(今回はどうやらファインチューニングと呼ばれるもので、転移学習とファインチューニングの違いは次回で説明されています)
チュートリアルでは、学習データ120、検証データ50で試していましたが、学習データが40ほどでも、まあまあ正しく予測できていました。
これほど少ないテストデータで学習できるとは、転移学習はすごいですね。
次回は「Transfer Learning for Computer Vision Tutorial」を進めてみたいと思います。
履歴
2020/11/15 初版公開
2020/11/29 次回のリンク追加