定番のoptimizerであるSGD, RMSProp, Adamに続いて新しい学習アルゴリズムが次々提案されています。そのうち、以下の3つはtensorflow.addonsを使えばtensorflow.kerasでも使うことができます。
- SGDW, AdamW
- cosine annealing (SGDR, AdamRなど)
- RAdam
Decoupled Weight Decay Regularization
https://arxiv.org/abs/1711.05101
On the Variance of the Adaptive Learning Rate and Beyond
https://arxiv.org/pdf/1908.03265.pdf
この記事の内容
本記事はとりあえず動くコードをペタペタ貼ってるだけです。
インストール
pipで入ります
pip install tensorflow-addons
1. 準備
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import tensorflow as tf
import tensorflow_addons as tfa
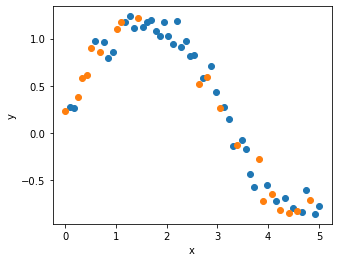
N = 60
x = np.linspace(0, 5, N)
y = np.sin(x) + 0.2 + np.random.normal(0, 0.1, N)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33, random_state=42)
plt.figure(figsize=(5, 4))
plt.scatter(x_train, y_train)
plt.scatter(x_test, y_test)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
2. Adamで学習
def make_model(activation, optimizer):
inputs = tf.keras.layers.Input(1)
network = tf.keras.layers.Dense(20, activation=activation)(inputs)
network = tf.keras.layers.Dense(20, activation=activation)(network)
outputs = tf.keras.layers.Dense(1, activation='linear')(network)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer=optimizer)
return model
def plot_history(hist):
plt.plot(hist.history['loss'], label='loss')
plt.plot(hist.history['val_loss'], label='val_loss')
plt.yscale('log')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()
def plot_result(x_train, y_train, x_test, y_test, x, y_pred):
plt.figure(figsize=(5, 4))
plt.scatter(x_train, y_train, label='train')
plt.scatter(x_test, y_test, label='test')
plt.plot(x, y_pred, label='pred')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
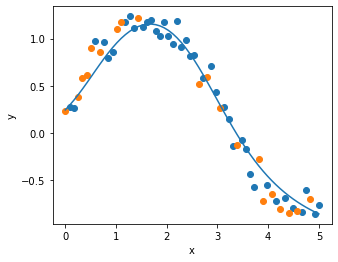
optimizer = tf.keras.optimizers.Adam(learning_rate=0.05)
activation = 'sigmoid'
model = make_model(activation, optimizer)
hist = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=130, verbose=False)
plot_history(hist)
y_pred = model.predict(x).reshape(-1)
plot_result(x_train, y_train, x_test, y_test, x, y_pred)
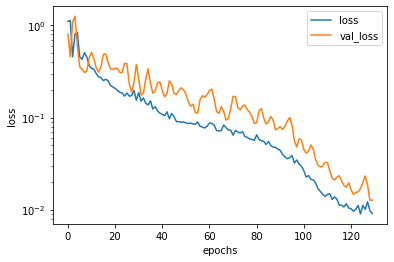
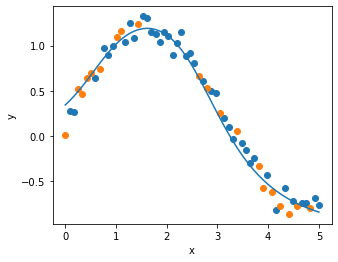
3. SGDWで学習
tensorflow_addons document
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/SGDW
optimizer = tfa.optimizers.SGDW(learning_rate=0.02,
weight_decay=0.0001)
activation = 'sigmoid'
model = make_model(activation, optimizer)
hist = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=1000, verbose=False)
plot_history(hist)
y_pred = model.predict(x).reshape(-1)
plot_result(x_train, y_train, x_test, y_test, x, y_pred)
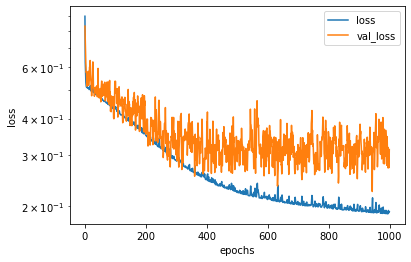
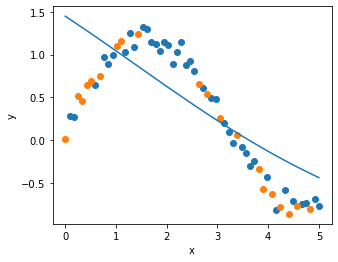
4. AdamWで学習
tensorflow_addons document
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/AdamW
optimizer = tfa.optimizers.AdamW(learning_rate=0.05,
weight_decay=0.001)
activation = 'sigmoid'
model = make_model(activation, optimizer)
hist = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=200, verbose=False)
plot_history(hist)
y_pred = model.predict(x).reshape(-1)
plot_result(x_train, y_train, x_test, y_test, x, y_pred)
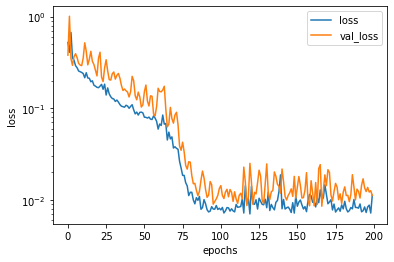
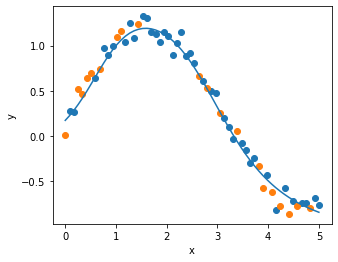
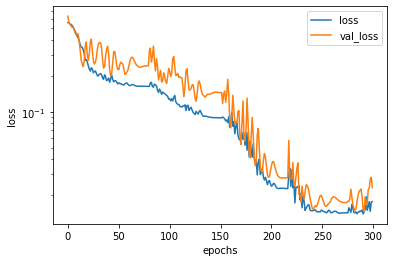
5. RAdamで学習
tensorflow_addons document
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/RectifiedAdam
optimizer = tfa.optimizers.RectifiedAdam(learning_rate=0.1,
weight_decay=0.001)
activation = 'sigmoid'
model = make_model(activation, optimizer)
hist = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=300, verbose=False)
plot_history(hist)
y_pred = model.predict(x).reshape(-1)
plot_result(x_train, y_train, x_test, y_test, x, y_pred)
6. cosine annealing
cosine annealingはtensorflowのCosineDecayRestarts()がやってくれます。optimizerの引数にlearning_rateの代わりに与えるだけです。
条件の内訳は以下のようになっています。
- learning_rate
- 最初のlearning rate
- first_decay_steps
- 最初のdecayが終わるまでのepoch数
- t_mul
- 次のdecayのepoch数が前のdecayのepoch数の何倍になるか
- m_mul
- learning rateを前のdecayの最初のlearning rate
- alpha
- learning rateの下限を初期値の何倍にするか
tensorflow document
https://www.tensorflow.org/api_docs/python/tf/keras/experimental/CosineDecayRestarts
def plot_learning_rate(learning_rate):
plt.plot(epochs, learning_rate(epochs))
plt.xlim(0, 500)
plt.ylim(-0.005, 0.105)
plt.xlabel('epochs')
plt.ylabel('learning rate')
plt.show()
learning_rate = 0.1
learning_rate = tf.keras.experimental.CosineDecayRestarts(learning_rate,
first_decay_steps=200,
t_mul=0.5,
m_mul=0.8,
alpha=0.1.)
plot_learning_rate(learning_rate)
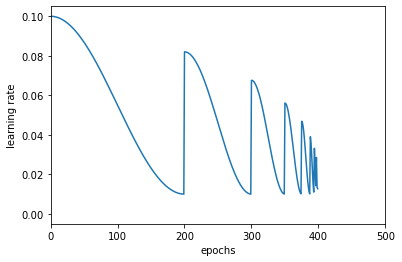
条件によっては早めにlearning rateがなくなってweightがNaNになってしまうので、パラメーターチューニングするときは範囲に注意が必要です。
7. SGDWRで学習
learning_rate
learning_rate = 0.1
learning_rate = tf.keras.experimental.CosineDecayRestarts(learning_rate,
first_decay_steps=150,
t_mul=0.8,
m_mul=0.8,
alpha=0.)
optimizer = tfa.optimizers.SGDW(learning_rate=learning_rate,
weight_decay=0.0001)
activation = 'sigmoid'
model = make_model(activation, optimizer)
hist = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=300, verbose=False)
plot_history(hist)
y_pred = model.predict(x).reshape(-1)
plot_result(x_train, y_train, x_test, y_test, x, y_pred)
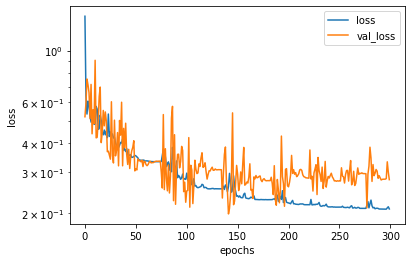
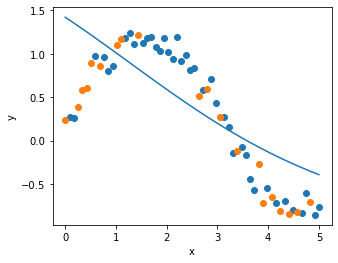
8. AdamWRで学習
learning_rate = 0.1
learning_rate = tf.keras.experimental.CosineDecayRestarts(learning_rate,
first_decay_steps=160,
t_mul=0.9,
m_mul=0.8,
alpha=0.)
optimizer = tfa.optimizers.AdamW(learning_rate=learning_rate,
weight_decay=0.001)
activation = 'sigmoid'
model = make_model(activation, optimizer)
hist = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=400, verbose=False)
plot_history(hist)
y_pred = model.predict(x).reshape(-1)
plot_result(x_train, y_train, x_test, y_test, x, y_pred)
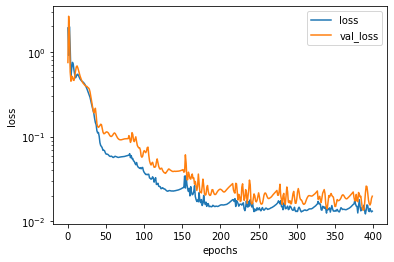
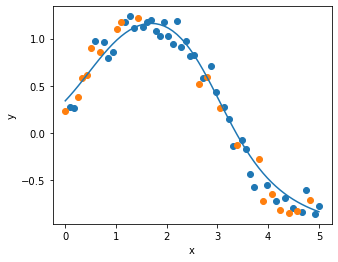
9. RAdamRで学習
learning_rate = 0.1
learning_rate = tf.keras.experimental.CosineDecayRestarts(learning_rate,
first_decay_steps=160,
t_mul=0.9,
m_mul=0.8,
alpha=0.)
optimizer = tfa.optimizers.RectifiedAdam(learning_rate=learning_rate,
weight_decay=0.001)
activation = 'sigmoid'
model = make_model(activation, optimizer)
hist = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=300, verbose=False)
plot_history(hist)
y_pred = model.predict(x).reshape(-1)
plot_result(x_train, y_train, x_test, y_test, x, y_pred)