手っ取り早く実装内容をお知りになりたい方は以下からどうぞ!
こちら
はじめに
近年、MLOpsの事例が多くの国内企業でも増えてきました。
数年前ではほとんど聞かなかった言葉ですが、今や「MLOps 事例」とかでググると色々とヒットするようになっています。
そもそものMLOpsの定義の詳細は以下のような記事に任せます。
https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning#devops_versus_mlops
https://www.ashisuto.co.jp/ai-buddy/column/datarobot_mlops.html
私の所感では昨今のMLOpsは広義の意味として、以下の工程を効率化・自動化することを指すことが多い印象です。

- 要件定義や設計
- 実験
- データ取得
- 様々な分析
- 特徴量エンジニアリング
- アルゴリズムの選択(pycaret使うのか、boosted tree使うのかなどなど...)
- ローカルでの試行的な学習
- 学習
- 本番のためのMLモデルの学習
- 大容量のデータに耐えるだけのインスタンスの準備
- 学習状態の確認、エラー検知など
- 提供
- オンラインAPI予測用のAPIのデプロイ
- もしくは定期的に予測テーブルへ予測結果を投入するなど
- 精度監視
- 精度劣化検知
- ドリフト検知
- 不正なデータ
- アラート通知
- 保守対応
- 精度劣化時の原因分析
- 特徴量の見直し
- アルゴリズムの見直し
- モデル再学習
これを実現しようとすると、それなりにシステム開発工数や体制が整っていないといけません。
2022年12月現時点において銀の弾丸となりうるツールや方法論は存在せず(多分...)、各企業での人材のスキルレベルや体制、ビジネスの背景によってベストプラクティスが三者三様であるのが実態です。
本記事では、コロナの感染者調査データのような時系列データの予測を行うことを題材にし、1つの雛形としてのMLOpsワークフローをtroccoとBigQuery MLで実現してみました。
スコープ
今回対象とするスコープは以下のとおりです。

実験の部分はみなさんの組織の事情などでかなりブレがある(例えばjupyter notebookを使うのかどうかや、実験結果をチームに共有するかしないかなど)ので、本記事では省略しています。
また、保守の領域については自動化できるところにのみフォーカスを当てています。
具体的には、精度劣化時の原因分析などの自動化しづらい点はスコープ外とし、精度劣化時の自動的な再学習をスコープ内としています。
留意事項
- 本記事での内容はあくまでも1例であり、過不足はあるかと思います。
- 一部、やや乱暴な実装があり、アーキテクチャとしてキレイではない部分もあります。
- 機械学習モデルの精度の検証や評価指標についての詳しい考察などは本記事では行いません。
- troccoやBigQueryMLの基本的な操作の説明はございません。
なぜtroccoとBigQueryMLなのか
本記事ではtroccoとBigQueryMLを使用します。
他にもMLOpsを達成できるツールはいくかありますが、なぜ今回trocco x BigQueryMLなのかについてを述べていきます。
troccoの良さ
troccoはETL(もしくはELT)を含む分析基盤に必要な開発や運用を総合的に支援するSaaSです。
様々なデータベースやクラウドサービスとの連携が可能で、BigQueryやRedshift、SnowflakeなどのDWHとは特に親和性が強いです。
今回のMLOpsでは以下の点でtroccoを使うメリットがあります。
- 学習や予測に使用するデータ整形が簡単に行える。
- ワークフロー機能を用いることで、データの加工、学習、予測などをつなげたパイプラインをグラフィカルに設定・管理することができる。
- BigQueryのクエリ結果に応じてアラートを出すことができるため、運用監視がしやすい。(BigQueryチェック機能)
- 例えば「予測結果に欠損があればアラート」などが実現できる。
- 通知先もメールやslackなど自由に選べる
- カスタム変数(あとからSQLなどの諸設定項目に任意の値を埋め込む)機能があり、パイプラインの各工程(コンポーネント)を汎用化しやすい。
他にも、UIが使いやすいので学習コストが低い、技術サポートの人が丁寧に教えてくれるなど、色々な非機能側の良さもあります。
また、最近のアップデートでBigQueryなどのDWHについては、SQLの自由記述が可能になったため、CREATE MODELなどの特殊なSQLもtroccoから実行することができるようになりました。(実行自体はDWH側で行う。troccoはジョブを投げるポジション)
BigQueryMLの良さ
BigQueryMLは、BigQuery上のSQLから機械学習ができるサービスです。
GCP内で提供されているAutoMLサービスとの接続も一部可能で、比較的ローコードで機械学習モデルの構築ができます。
(近年ではRedshiftも同様の機能がリリースされているので、BigQuery独自感は薄れてきましたが、、、)
また、BigQueryがクエリエンジンとストレージエンジンをフルマネージしてくれているおかげで、機械学習の際に実行環境のスペックを気にする必要がないのも大きな利点です。
troccoとBigQueryMLの組み合わせ
先述のように
- troccoでBigQueryに対して、自由記述のSQLを発行できるため、BigQueryMLを使用できる
- troccoのBigQueryチェック機能で運用監視が楽になる
などの理由から、troccoとBigQueryの親和性が高いです。
MLOpsの各工程がtroccoとBigQueryMLで完結するという点もメリットかと思います。
ワークフローの実装
コロナの新規感染者を予測するMLOpsワークフローを作成していきます。
使用するデータ
今回は、Googleから一般公開されているAbout COVID-19 Public Datasetsにあるコロナのエリア別新規感染者数を用います。
- テーブルのパス:
bigquery-public-data.covid19_open_data.covid19_open_data - SQLの取得例
BigQuery
SELECT place_id , date , new_confirmed FROM `bigquery-public-data.covid19_open_data.covid19_open_data` WHERE country_name = "Japan"
クエリにはスキャン料金がかかります。
また、他の国のデータもあり、クエリのたびにそこそこのデータサイズをスキャンしちゃうので、
上記の結果を別のご自身のテーブルにエクスポートするなどをしたほうが良いかもしれません。
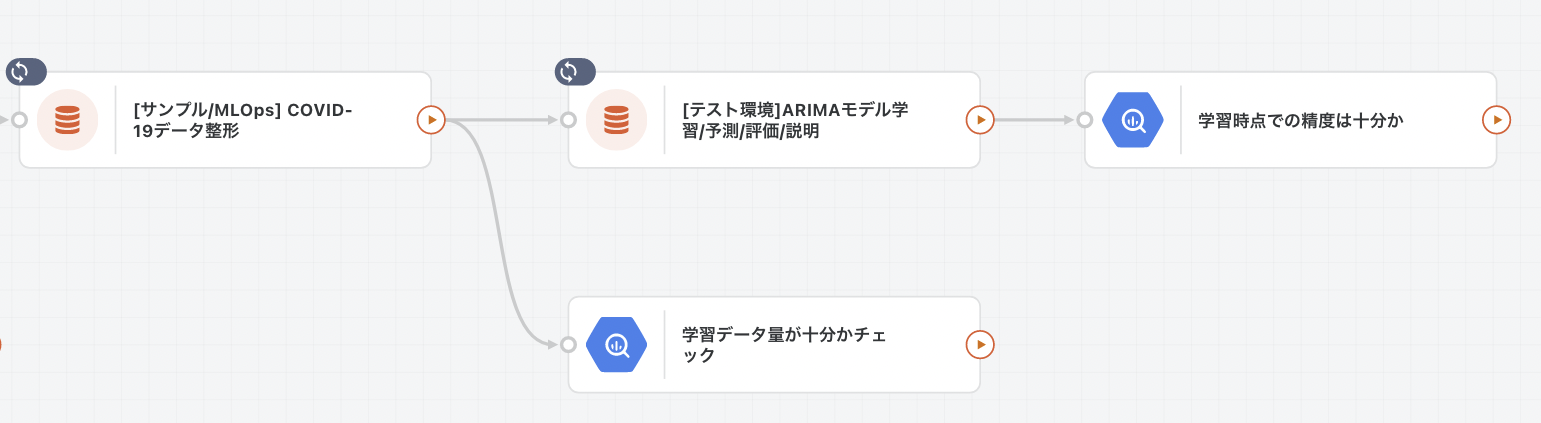
ワークフローの全体像
troccoにはワークフロー機能があり、全体の流れをグラフィカルに設定・管理することが可能です。
以下に今回の概要を共有します。

ワークフローの流れ
詳細は後述しますが、まずは上記のワークフローの各ステップを説明します。
-
ステップ1: 過去の実績から精度を評価する。

- 上記のワークフローはすでにモデルが学習されている状態であることが前提です(初回のモデル学習については後述)
- 検証用に切り出した実績データの数が少なすぎる場合は十分な評価ができない恐れがあるので、BigQueryチェック機能を用いて監視・アラート運用をします。
- 精度が悪かった場合も検知できるよう、BigQueryチェック機能で監視します。
-
ステップ2: 学習と予測、他各種評価指標などを計算する。
- 過去のデータを使用して、学習と予測を行います。
- 学習データに必要なデータ量が十分でない場合はモデルの精度が悪くなる恐れがあるので、これも監視します。
- 学習時点のAICなどの指標を見て、精度が悪い場合も監視します。
- 今回は時系列予測としてポピュラーなARIMAを使用します。
- 学習と予測を同じデータマート内部で実行しています。
- 要件によっては学習と予測をそれぞれ別タイミングで実施する必要があるかと思いますが、その際は別のワークフローに切り出すことをおすすめします。
- 予測用のオンラインAPIの提供はしていません。
- 予測テーブルへ予測結果を定期的に挿入することで、MLモデルの提供としています。
- 外部のシステムはこのテーブルにアクセスすることで予測結果を利用できます。
... 評価が先にステップ1に来て、その後にステップ2の学習・予測というのは不自然に感じられるかもですが、再学習のトリガーとして精度に基づく実行可否を制御したいので、このようなステップの並びになっています。(詳細は後述)
各コンポーネントの説明
上記のワークフローの各コンポーネントについて概要の説明をします。
データ整形
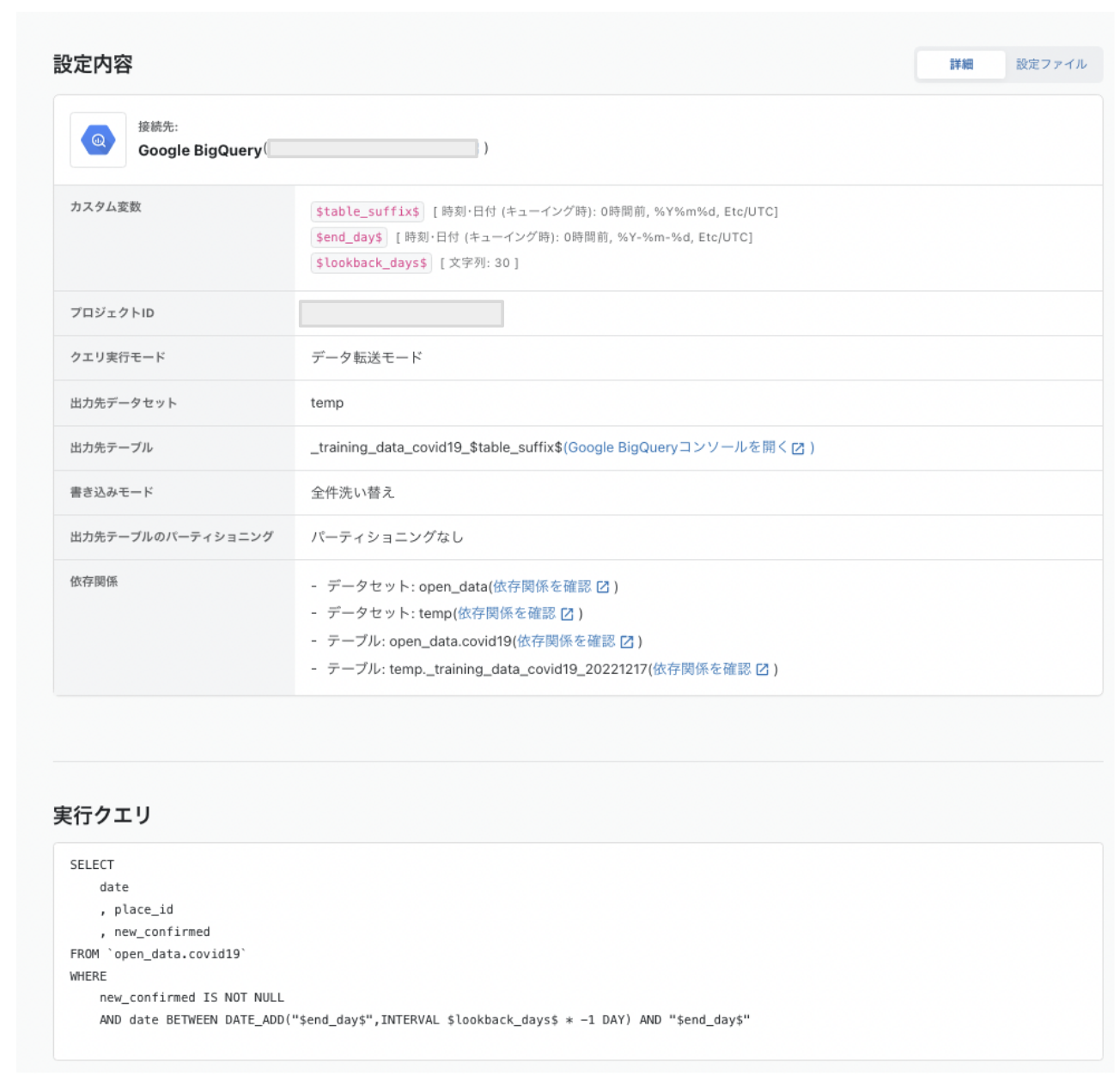
上記のワークフローでの「[サンプル/MLOps]COVID-19データ整形」にあたるデータマート設定です。
任意の期間のデータを取得して、最低限のクレンジングを行います。
カスタム変数で期間を制御できるので、学習用や評価用などそれぞれのケースに対応できます。
データマート設定
SELECT
date
, place_id
, new_confirmed
FROM `open_data.covid19`
WHERE
new_confirmed IS NOT NULL
AND date BETWEEN DATE_ADD("$end_day$",INTERVAL $lookback_days$ * -1 DAY) AND "$end_day$"
出力先データセット: temp
出力先テーブルのパス: _training_data_covid19_$table_suffix$
書き込みモード: 全件洗い替え
table_suffix: キューイング時の時刻を'%Y%m%d'でフォーマットしたもの : 出力先のテーブルの末尾になる
end_day: キューイング時の時刻を'%Y-%m-%d'でフォーマットしたもの : データ取得の終了時刻を表す
lookback_days: end_dayから何日前までを見るか
ワークフロー上での設定
上記のデータマート設定をワークフローに配置することで、ワークフロー実行時にこのデータマート設定が実行されます。
その際にカスタム変数に投入する値をワークフローから設定できます。
今回は、下記のように「Google BigQueryのクエリ結果でループ」を使用し、柔軟性の高い値投入を行います。
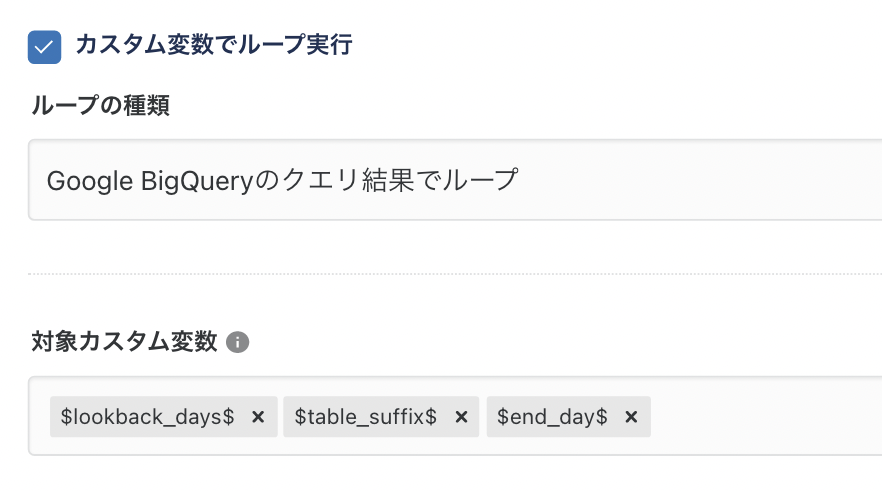
「ループ」とありますが、今回は任意の値を1回入れたいだけなので、1ループのみ実行するようにクエリを工夫します。
ステップ1部分での設定
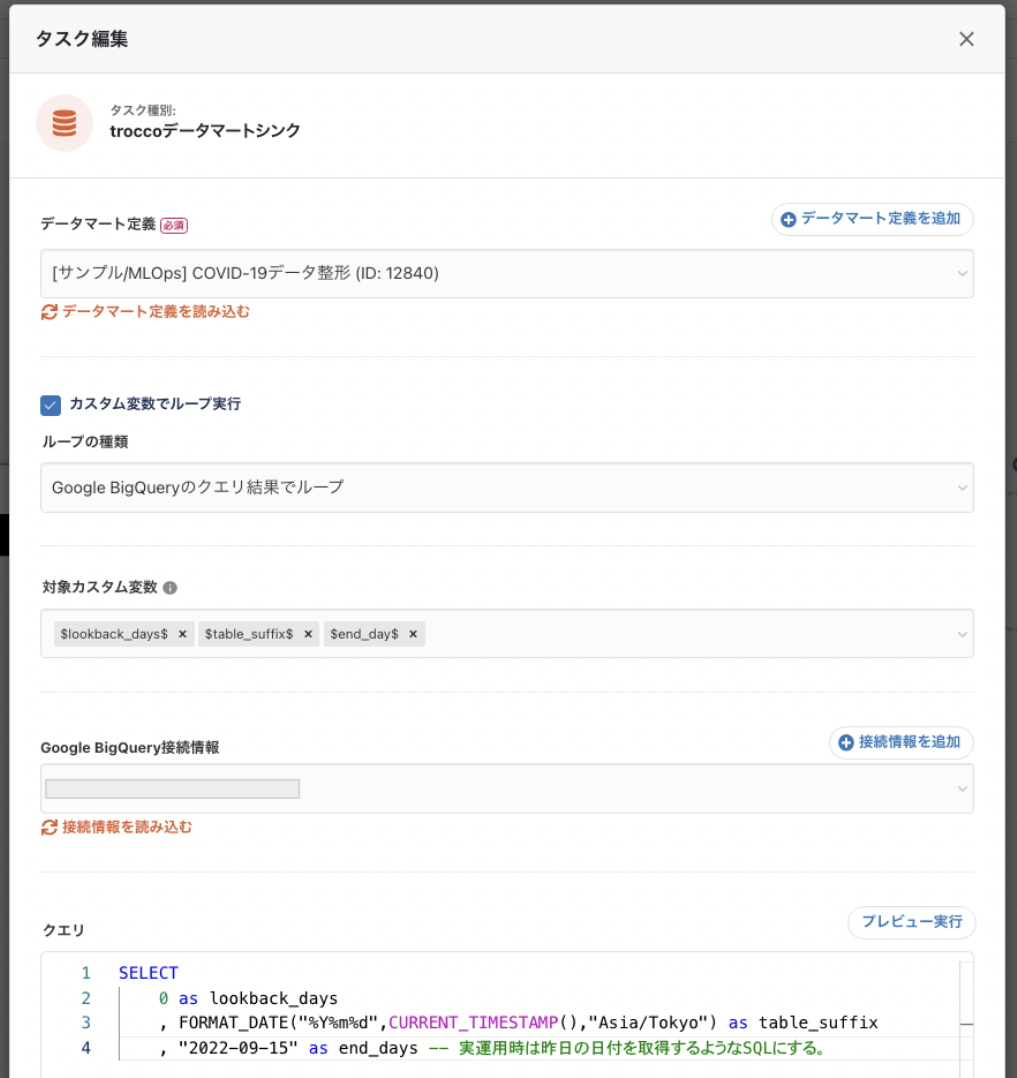
SELECT
0 as lookback_days
, FORMAT_DATE("%Y%m%d",CURRENT_TIMESTAMP(),"Asia/Tokyo") as table_suffix
, "2022-09-15" as end_days -- 実運用時は昨日の日付を取得するようなSQLにする。
ステップ2部分での設定
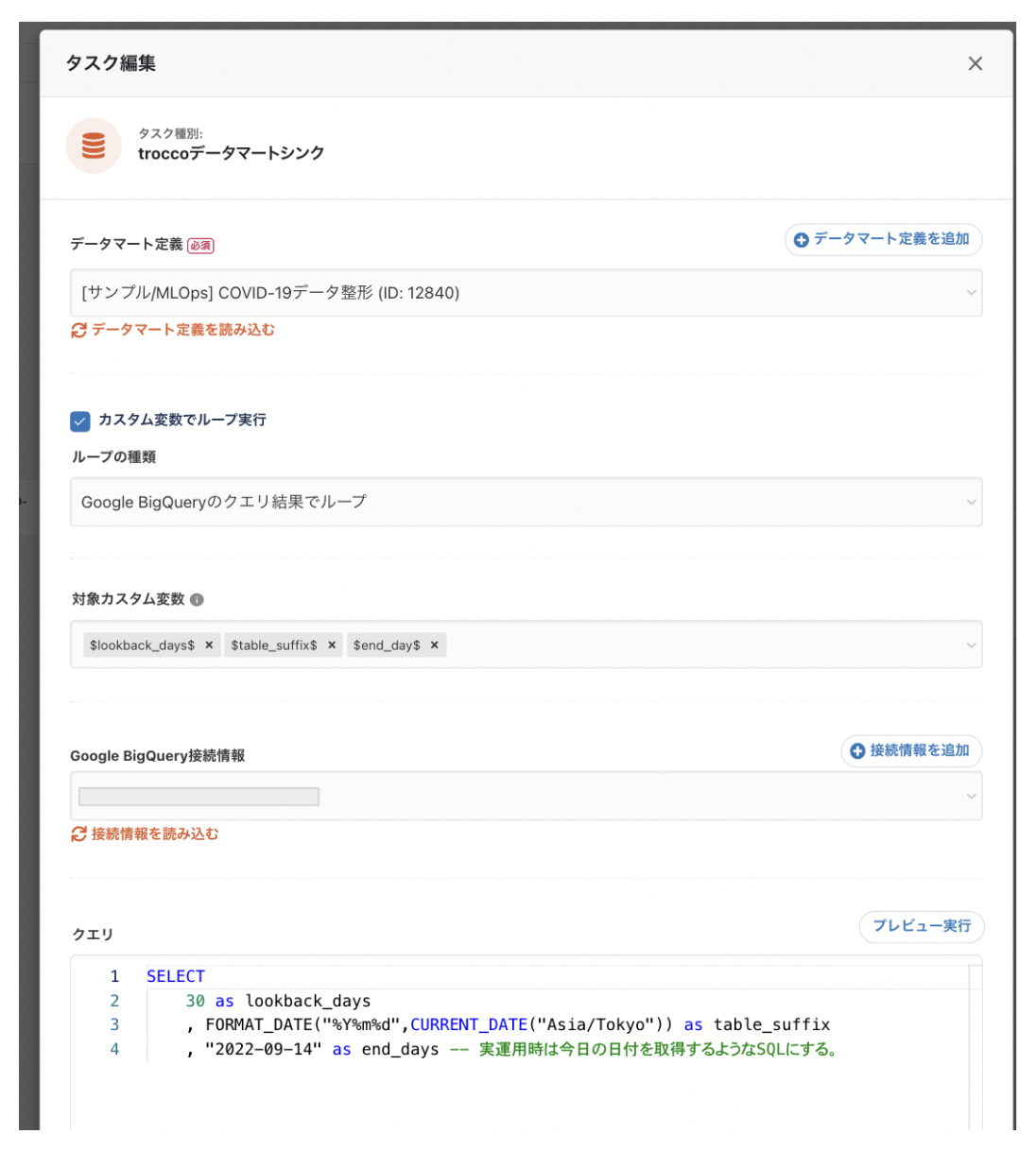
SELECT
30 as lookback_days
, FORMAT_DATE("%Y%m%d",CURRENT_DATE("Asia/Tokyo")) as table_suffix
, "2022-09-14" as end_days -- 実運用時は今日の日付を取得するようなSQLにする。
実績からの精度評価
上記のワークフローでの「[テスト環境]MLモデルオンライン評価」にあたるデータマート設定です。
データマート設定
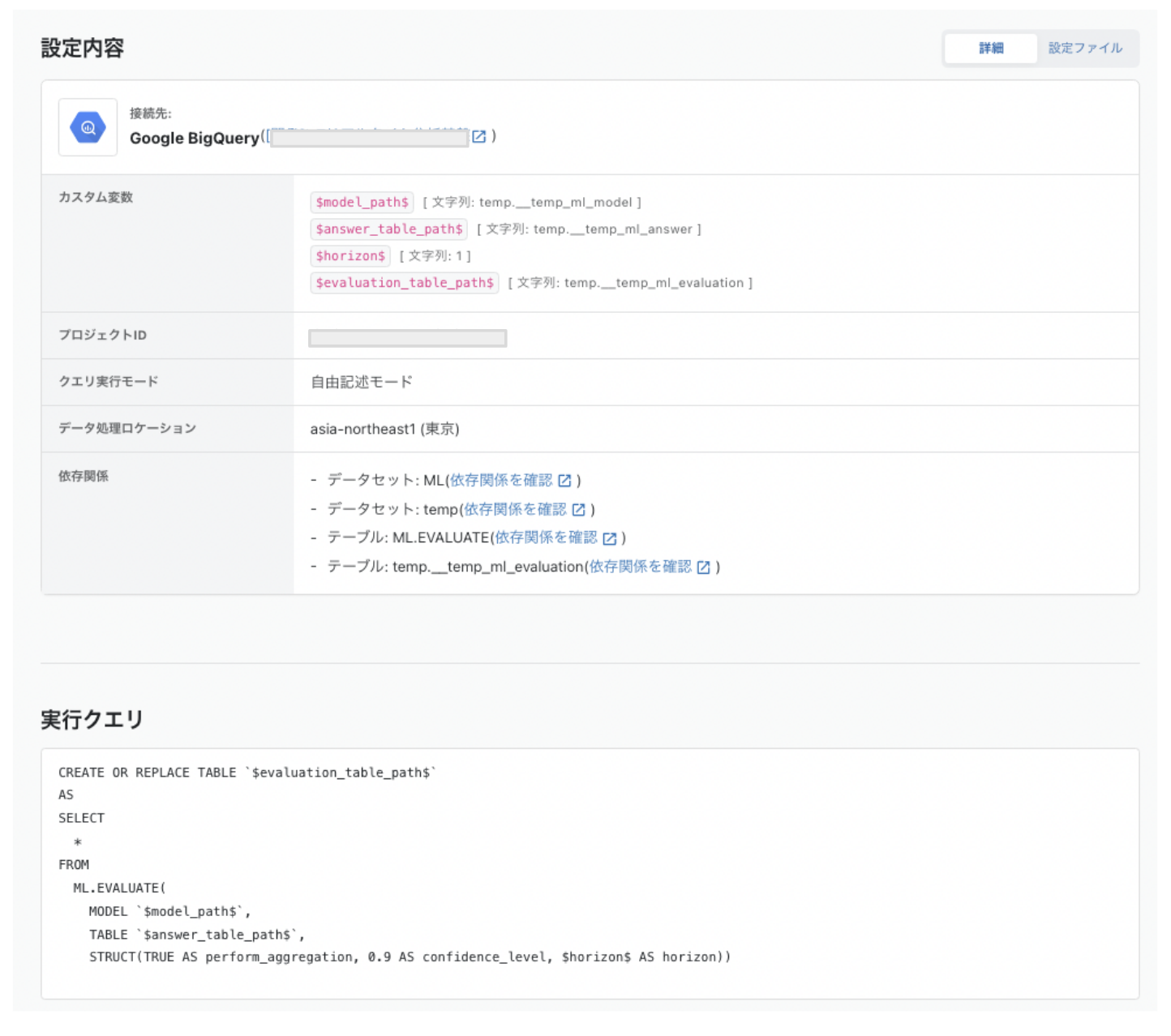
CREATE OR REPLACE TABLE `$evaluation_table_path$`
AS
SELECT
*
FROM
ML.EVALUATE(
MODEL `$model_path$`,
TABLE `$answer_table_path$`,
STRUCT(TRUE AS perform_aggregation, 0.9 AS confidence_level, $horizon$ AS horizon))
model_path: モデル出力先のパス
answer_table_path: 答えがわかっているデータが保存されているテーブル
horizon: モデルの予測日数
evaluation_table_path: 評価結果を保存する先のテーブルパス
注意
ARIMAモデルは学習時にその最新時刻から、$horizon$点数分だけ未来を予測します。
例えば$horizon$=1とした場合、今回では学習時の最新日の翌日の予測値が、$answer_table_path$で指定したテーブルの答えと比較されます。
この時間の関係がズレないように注意が必要です。
ワークフロー上での設定
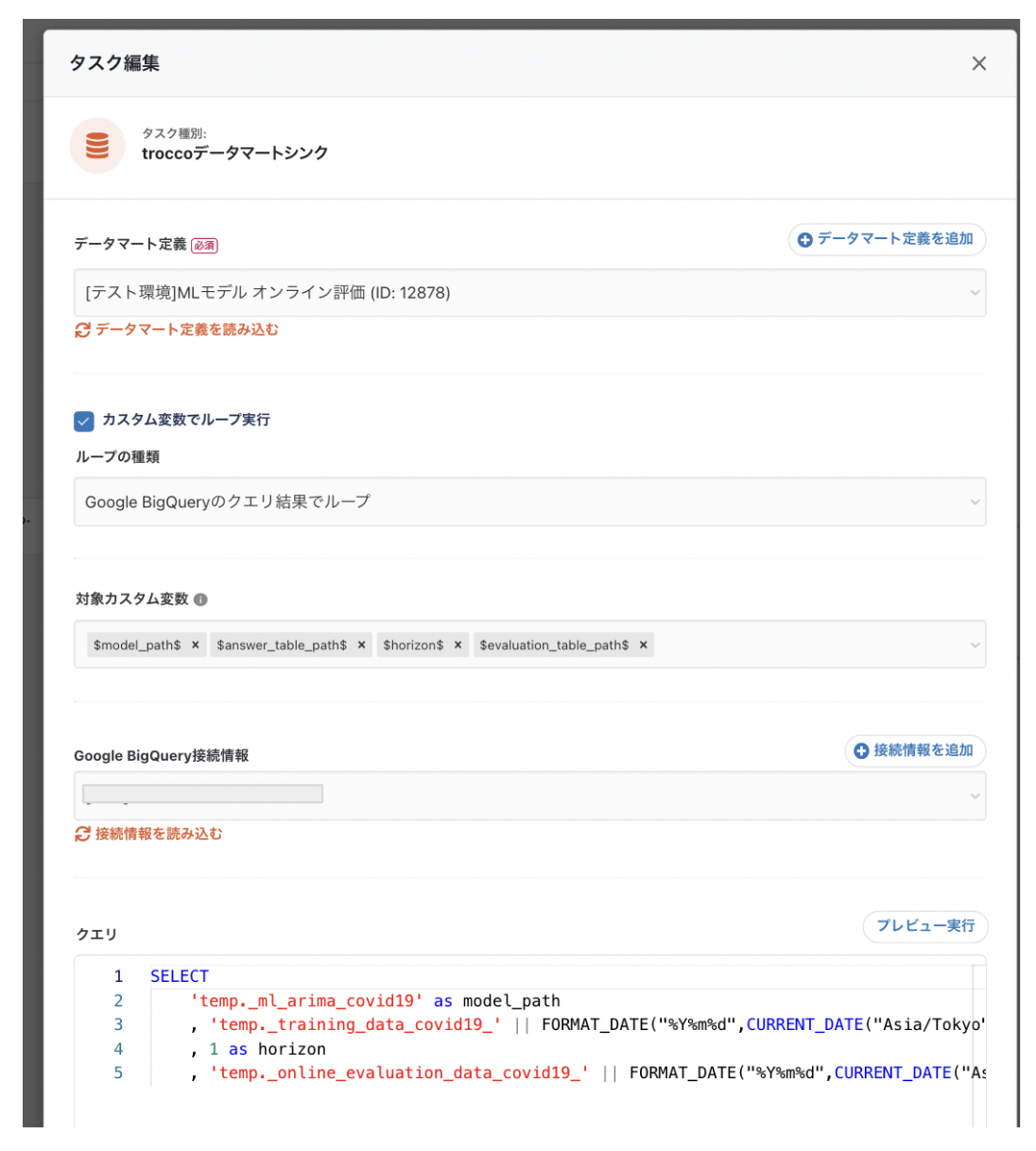
SELECT
'temp._ml_arima_covid19' as model_path
, 'temp._training_data_covid19_' || FORMAT_DATE("%Y%m%d",CURRENT_DATE("Asia/Tokyo")) as answer_table_path
, 1 as horizon
, 'temp._online_evaluation_data_covid19_' || FORMAT_DATE("%Y%m%d",CURRENT_DATE("Asia/Tokyo")) as evaluation_table_path
各種テーブルパスにはTABLE_SUFFIXを利用しています。
データ保管コストがかかりますが、過去の状況をログのように残しておくことが可能です。
MLの学習・予測・評価・説明
上記のワークフローでの「[テスト環境] ARIMAモデル学習/予測/評価/説明」にあたるデータマート設定です。
データマート設定
BigQueryMLでARIMAによる学習・予測・評価・説明を行います。
仕様上、学習がされた時にすでに予測結果などがモデル内部に生成されているので、すべてを1つのSQLで実行しています。
常にモデルや予測などの出力先テーブルなどは上書きされるので注意が必要です。
テーブルについてバージョニングを取りたい場合は、カスタム変数で指定するテーブル名をワークフローのBigQueryループなどで工夫してください。
各種SQLの説明については以下をご確認ください
- 学習: https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create-time-series
- 予測: https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-forecast
- 評価: https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-arima-evaluate
- 説明: https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-explain-forecast
--- 学習
IF $do_train$ = 1 THEN
CREATE OR REPLACE MODEL $model_path$
OPTIONS(
model_type = 'ARIMA_PLUS'
, time_series_timestamp_col = '$timestamp_col$'
, time_series_data_col = '$label_col$'
, time_series_id_col = '$item_col$'
, horizon = $horizon$
)
AS
SELECT
$timestamp_col$
, $item_col$
, $label_col$
FROM
$train_table_path$
;
ELSE
SELECT NULL
;
END IF
;
--- 予測
CREATE OR REPLACE TABLE $prediction_table_path$
AS
SELECT
*
FROM
ML.FORECAST(MODEL `$model_path$`,struct($horizon$ as horizon))
;
--- 評価
CREATE OR REPLACE TABLE $evaluation_table_path$
AS
SELECT
*
FROM
ML.ARIMA_EVALUATE(MODEL `$model_path$`, STRUCT(FALSE AS show_all_candidate_models))
;
--- 説明
CREATE OR REPLACE TABLE $explanation_table_path$
AS
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `$model_path$`, STRUCT($horizon$ AS horizon, 0.8 AS confidence_level))
;
model_path: モデルの保存先
timestamp_col: データの時刻を表す列名
label_col: データの予測対象を表す列名
item_col: データの時系列を識別する列名
horizon: 何点先を予測するか
train_table_path: 学習データが保存されているテーブルパス
do_tarin: 1であるとき学習を実行します。
prediction_table_path: 予測結果のテーブル
evaluation_table_path: 評価結果のテーブル
explanation_table_path: 説明結果のテーブル
ワークフロー上での設定
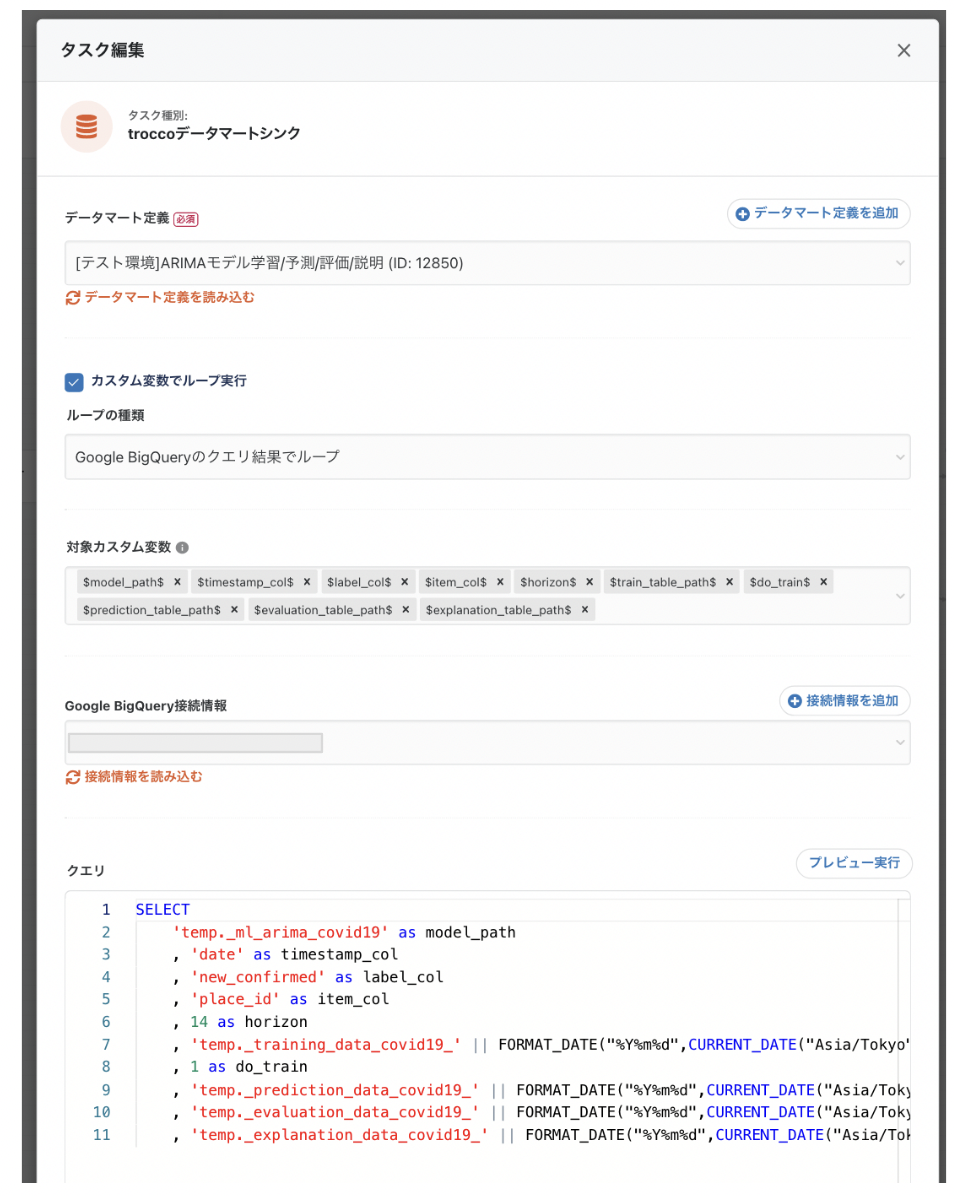
SELECT
'temp._ml_arima_covid19' as model_path
, 'date' as timestamp_col
, 'new_confirmed' as label_col
, 'place_id' as item_col
, 14 as horizon
, 'temp._training_data_covid19_' || FORMAT_DATE("%Y%m%d",CURRENT_DATE("Asia/Tokyo")) as train_table_path
, 1 as do_train
, 'temp._prediction_data_covid19_' || FORMAT_DATE("%Y%m%d",CURRENT_DATE("Asia/Tokyo")) as prediction_table_path
, 'temp._evaluation_data_covid19_' || FORMAT_DATE("%Y%m%d",CURRENT_DATE("Asia/Tokyo")) as evaluation_table_path
, 'temp._explanation_data_covid19_' || FORMAT_DATE("%Y%m%d",CURRENT_DATE("Asia/Tokyo")) as explanation_table_path
再学習のトリガーを制御する
カスタム変数$do_tarin$は再学習のトリガーとして機能させることが可能です。
ワークフローでの設定時に単に1とすれば、ワークフローが実行されるたびに再学習されます。
コストの観点から「精度が悪くなった時にだけ再学習したい」という場合は、ワークフロー設定時のカスタム変数でループ実行>BigQueryでのクエリ結果でループでのSQLを工夫して、精度が悪くなった時に$do_train$=1となるように設定すると良いです。
以下は1例です。各エリアの予測結果のMAPEが50%を超えた場合に再学習します。
SELECT
...(中略)...
, (SELECT IF(AVG(mean_absolute_percentage_error)>50,1,0) FROM `temp._online_evaluation_data_covid19_20221217`) as do_train
...(中略)...
BigQueryチェックの説明
上記のワークフローでの運用監視部分を担うのBigQueryチェック機能を説明します。
BigQueryチェック機能では、特定のクエリ結果の1行目1列目の値に対してXXX以上or以下ならエラーを出すという設定ができます。
(※ 後述のSQLに埋め込まれたカスタム変数$table_suffix$はキューイング時刻を'%Y%m%d'でフォーマットしたものです。)
検証用データ量が十分かチェック
SELECT
count(*)
FROM `temp._training_data_covid19_$table_suffix$`
アラート条件: クエリ結果が10以下ならエラー
検証用のデータは1日分のみ使用するため、レコードが10程度あればOKという緩めのしきい値で設定しています。
昨日は十分な精度であったかチェック
SELECT
AVG(mean_absolute_percentage_error)
FROM `temp._online_evaluation_data_covid19_$table_suffix$`
アラート条件: クエリ結果が50以上ならエラー
MAPEが50%を超えるようならエラーを出すようにしています。
学習データ量が十分かチェック
SELECT
count(*)
FROM `temp._training_data_covid19_$table_suffix$`
アラート条件: クエリ結果が300以下ならエラー
学習用のデータは30日分を使用するため、レコードが数百程度なければエラーを出すようにしています。
学習時点での精度は十分かチェック
SELECT AVG(AIC)
FROM `temp._evaluation_data_covid19_$table_suffix$`
アラート条件: クエリ結果が500以上ならエラー
今回はAICに対してしきい値を設定していますが、状況に応じて適切に設定してください。
運用開始までの手順
上記のようにワークフローおよび各コンポーネントを設定することで準備は整いました。
以下の手順で運用を開始します。
- 以下のコンポーネントを手動実行し、最初のモデルを作成します。
- ワークフローのスケジュールや通知を設定する

最後に
文面に落とし込むと結構複雑のように思えますが、実際に設定してみると案外楽でした。
今回は説明を簡単にするために、比較的シンプルなワークフロー&BigQueryチェックでしたが、業務の都合に応じて様々な監視を行うと良いでしょう。
ワークフローではもし何かBigQueryチェックでエラーが起これば、アラート通知はもちろんのこと、どこでエラーが起こっているかがわかるので保守もしやすいです。

↑エラーが起こっている場所が赤くハイライトされる
trocco x BigQueryMLによる快適なMLOpsライフをお楽しみください😊
その他雑記
dbtで実現するとテーブルパスなどもスマートに指定できたりするので、いつかtrocco dbt版の記事を投稿したいです...