はじめに
どうも皆さんこんにちは、高知工科大 Advent Calendar 2017の9日目を担当させて頂く、佐久間まゆPのstmnです。今回は、自分の好きな言語であるPythonと「佐久間まゆ」に関連させた記事を書きたいと思い、word2vecを使って佐久間まゆに類似した単語を調べてみることにしました。
word2vecとは?
ある単語の意味や文法を捉えるためにベクトル表現化を行い次元を圧縮したものらしいです。
詳しい説明は下記のサイトなどを参考にしてください。
Word2Vec:発明した本人も驚く単語ベクトルの驚異的な力
Word2Vecとは?
要は単語と単語の類似度を表現することができるという事です(らしいです)。
実際にword2vecを使ってみましょう。
word2vecを使ってみる
word2vecを使うのには学習を行ったモデルデータが必要となります。普通はWikipediaなどのデータセットに対して、文章を単語毎に分割を行い学習に掛けて......
と手間が掛かります。なので、一旦ここではAIALさんの方で用意されているモデルを使って実行してみます。
from gensim.models import word2vec
import sys
# モデルまでのパス
model_path = 'latest-ja-word2vec-gensim-model/word2vec.gensim.model'
# モデルの読み込み
model = word2vec.Word2Vec.load(model_path)
# 類似度を測りたい単語を入力
results = model.most_similar(positive=sys.argv[1], topn=10)
# 類似度の高い単語を出力
for result in results:
print(result[0], '\t', result[1])
実行結果
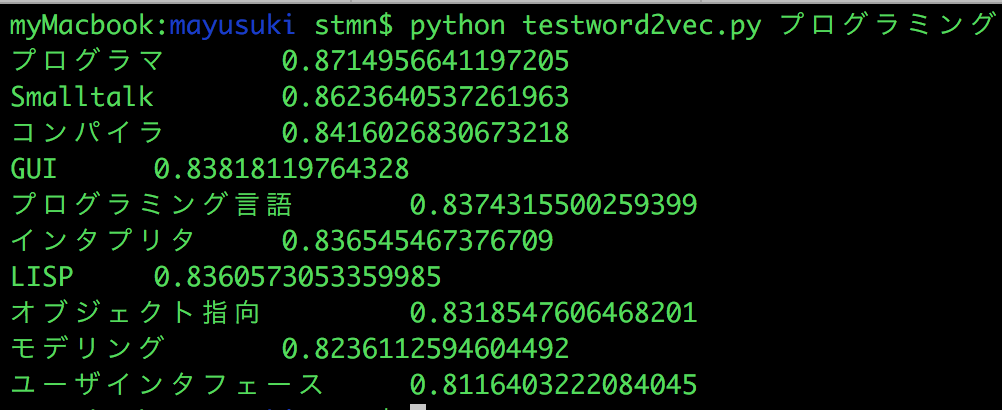
確かに関連している単語群が表示されているか感じぽいですね。他にも試してみましょう。
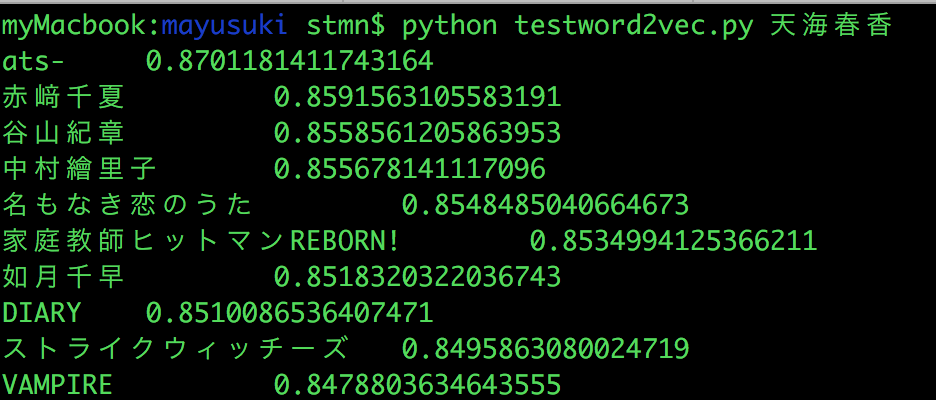
同じアイマスのキャラクタの名前やデレマス声優さん、他にもアニメや声優さんの名前と直接的な関係はなくても近いものは出てきました。
本題
それでは本題です。今回はある単語(佐久間まゆ)が含まれる文章データを集めて学習モデルの作成を行い、そのモデルを使ってある特定の単語に対して意味の近い単語の一覧を表示してみたいと思います。
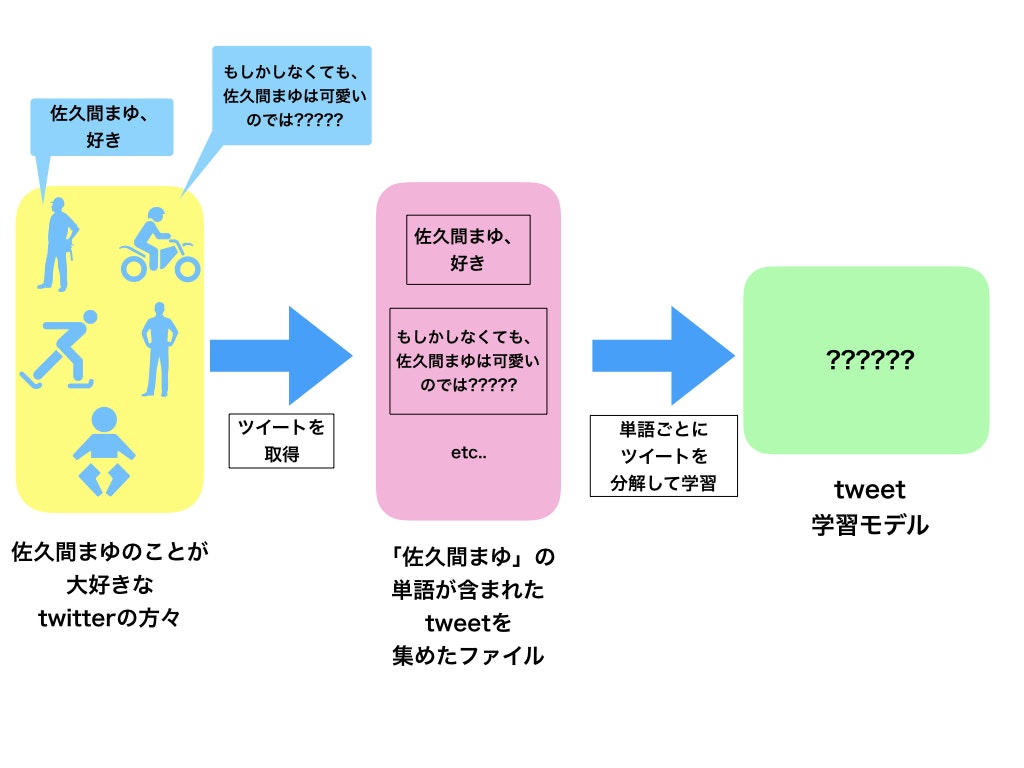
多分、一般的なword2vecの使い方と違う気が....
Tweet取得
それではまずはデータセットを集めるところからです。一定時間ごとにTwitterのAPIを叩いて、「佐久間まゆ」と単語の入っているツイートの取得を行い、CSVファイルに出力します。今回のこのスクリプトでは重複したツイートやRTやURLも取り除かず取ってみます。
アクセストークンについては、下記のサイトをみると分かりやすいと思います。
Twitter REST APIの使い方
# アクセトークンの設定ファイル
CONSUMER_KEY = "************"
CONSUMER_SECRET = "************"
ACCESS_TOKEN = "************"
ACCESS_TOKEN_SECRET = "************"
from requests_oauthlib import OAuth1Session
import csv
import json
import time
import setting
twitter = OAuth1Session(setting.CONSUMER_KEY, setting.CONSUMER_SECRET, setting.ACCESS_TOKEN, setting.ACCESS_TOKEN_SECRET)
count = 0
# ツイッター上の「佐久間まゆ」と入ったツイートを100個取得する
def get_target_ward(ward):
url = "https://api.twitter.com/1.1/search/tweets.json"
params = {'q':ward,
'count':100
}
req = twitter.get(url, params = params)
timeline = json.loads(req.text)
tweet_list = []
for tweet in timeline['statuses']:
tweet_list.append(tweet["text"])
tweet_list = list(set(tweet_list))
for (i,tweet) in enumerate(tweet_list):
print(str(i) + " : " + tweet)
return tweet_list
# csvファイルを作成
def write_csv(tweet_list):
with open("mamayu_tweet" + str(count) + ".csv","w") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(tweet_list)
if __name__ == '__main__':
all_list = []
# 検索対象の単語を設定
ward = "佐久間まゆ"
while True:
tweet_list = get_target_ward(ward)
write_csv(tweet_list)
time.sleep(60)
count = count + 1
単語分割
先ほど取得した各tweetを単語ごとに分割を行っていきます。単語分割はmecabで単語分割を行い、その際にはmecabのシステム辞書の一つmecab-ipadic-neologdを使います。
mecab-ipadic-neologdの導入にはこのページを参考にしました。
import MeCab
import csv
import sys
# mecab-ipadic-neologdを利用する
m = MeCab.Tagger('-Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
# 単語分割を行うファイルを記載する
fo = open('split.txt', 'w')
fo.close()
# 作成したファイル数を引数として渡す
count = int(sys.argv[1])
for num in range(count):
fi = open('mamayu_tweet' + str(num) +'.csv', 'r')
fo = open('split.txt', 'a')
for tweet in fi:
print(m.parse(tweet))
sprit_tweet = m.parse(tweet)
fo.write(sprit_tweet)
fi.close()
fo.close()
学習
単語分解を行って作成したsplit.txtを元に学習を行いモデルデータの作成を行います。
from gensim.models import word2vec
import logging
import sys
# 学習中のログを表示
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 単語分割したファイルを参照
sentences = word2vec.Text8Corpus('split.txt')
# 学習の設定はお任せで
model = word2vec.Word2Vec(sentences,
sg=1,
size=100,
min_count=1,
window=10,
hs=1,
negative=0)
# 作成したいモデル名を第1引数で渡す
model.save(sys.argv[1])
学習結果
それでは学習モデルが作成できたので、佐久間まゆにどんな単語が類似しているのか見てみましょう!
確認を行うソースコードは以下の通りです。
from gensim.models import word2vec
import sys
# 作成したモデルを第一引数と入力
model = word2vec.Word2Vec.load(sys.argv[1])
# 類似度を確認したい単語を第二引数として入力
results = model.most_similar(positive=sys.argv[2], topn=10)
for result in results:
print(result[0], '\t', result[1])
 かなり雑で荒いデータセットで学習を行いましたが、結果の中に「佐久間まゆ」の中の人である、牧野由依さんが出てきています!
ある程度、類似度を表現できていそうです。
ただし、類似具合を表す値は全部小さいです......
かなり雑で荒いデータセットで学習を行いましたが、結果の中に「佐久間まゆ」の中の人である、牧野由依さんが出てきています!
ある程度、類似度を表現できていそうです。
ただし、類似具合を表す値は全部小さいです......
まとめ
割と大雑多にword2vecを使ってみたのですが、それなりの結果が出ていたので凄い技術だと感じました。今回の記事を書くにあたって、データセット自体の総量が少なかったので、もっとたくさんのデータセットで学習させて結果を見てみても良さそうだと思いました。あと、学習前のデータセット自体から明らかに必要なノイズデータ(RT, @など)を取り除くなどの作業をしてみてもいいかと思いました。
本文中の内容に間違いなどありましたら、教えていただけたら幸いです。