BeautifulSoup4 を使用したウェブスクレイピング
このbeautifulsoup4アプリケーションは、指定されたURLから画像をスクレイピングし、事前に定義されたキーワードに基づいてユーザーが特定の画像を無視できるようにし、画像をZIPファイルとしてダウンロードするオプションを提供します。
Features
- 指定されたウェブページからすべての画像を抽出します。
- ユーザーは無視するキーワードを追加で指定できます。
- 抽出した画像を含むダウンロード可能なZIPファイルを提供します。
- 無視された画像用に別のZIPファイルを作成するオプションもあります。
要件
- Python 3.x
- streamlit
- requests
- beautifulsoup4
インストール
-
アプリケーションを実行します。
python app.py -
ウェブブラウザを開き、ローカルサーバーのアドレス(通常は http://127.0.0.1:5000)にアクセスしてください。
または以下のリンクをクリックしてください。ウェブサイトに移動します! ^_^
https://webscrapp-lcfhxdvwcvadycsp9ff9fy.streamlit.app/
使用方法
- 入力欄に、スクレイピングしたいウェブページのURLを入力してください。
- 必要に応じて、スクレイピング中に無視したい画像に関連するキーワードを(1行に1つずつ)入力してください。
- 「スクラップ」ボタンをクリックしてください。アプリケーションは以下の処理を実行します。
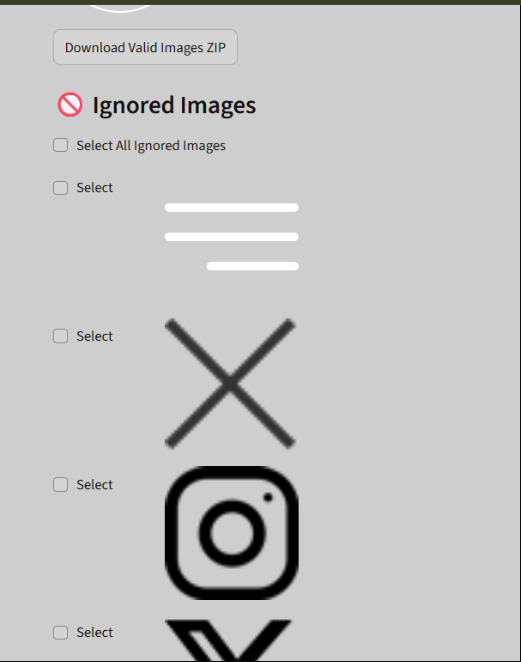
- 無視された画像を表示します。
- 有効な画像を含むzipファイルをダウンロードするためのリンクを提供してください。
- 無視された画像を選択し、それらをまとめたZIPファイルを作成できます。
- 指定されたURLに画像が見つからない場合、アプリケーションはユーザーに通知します。
- URLが無効な場合、またはスクレイピング中にエラーが発生した場合は、エラーメッセージが表示されます。
OUTPUT

このアプローチについてのご意見をお聞かせください。ご提案も歓迎いたします!
私の作品を気に入ってくれると嬉しいです 👈(゚ヮ゚👈)