RAGを用いた履歴書検証システムの構築
この記事では、バックエンドにFastAPI、フロントエンドにReactを使用したフルスタックの履歴書検証システムについて解説します。バックエンドは、Retrieval-Augmented Generation(RAG)を活用して、履歴書から構造化された情報をインテリジェントに抽出、検証、生成します。
RAGとは?
Retrieval-Augmented Generation(RAG)は、以下の要素を組み合わせたものです。
- 検索:データセット(ドキュメント、テキストチャンク、ベクトルストアなど)から関連情報を検索します。
- 生成:検索された情報に基づいて、大規模言語モデル(LLM)を使用して出力を生成します。
簡単に言うと、LLMに「すべてを記憶させる」のではなく、RAGはまず関連データを検索させることで、より正確で文脈に沿った応答を可能にします。
バックエンドアーキテクチャ
バックエンドは以下の主要コンポーネントを使用します。
- 履歴書のアップロードとテキスト抽出
システムはAPIエンドポイント経由でPDF形式の履歴書を受け付けます。
@app.post("/api/verify-resume")
async def verify_resume(file: UploadFile = File(...), role: str = Form("Python Developer")):
if not file.filename.endswith('.pdf'):
raise HTTPException(status_code=400, detail="Only PDF files are allowed")
temp_file_path = save_temp_file(file)
text = extract_text_from_pdf(temp_file_path)
lines = split_into_lines(text)
• extract_text_from_pdfはPyPDF2を使用してPDFページからテキストを読み取ります。
• テキストは処理しやすいように行ごとに分割されます。 ________________________________________
2. ベクトルストアの作成(検索コンポーネント)
履歴書のテキストはチャンクに分割され、埋め込みに変換されます。
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_text(text)
docs = [Document(page_content=chunk) for chunk in chunks]
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en")
vectorstore = FAISS.from_documents(docs, embeddings)
• チャンク:履歴書をより小さなセグメントに分割することで、関連する部分を効率的に取得できます。
• FAISS:埋め込みに対するセマンティック検索を可能にするベクトルデータベース。
- LLMと検索の連携(RAGの動作)
取得したテキストチャンクはLLM(ChatGroq)に送信され、構造化されたJSON出力が生成されます。
from langchain_groq import ChatGroq
from langchain_classic.chains import RetrievalQA
llm = ChatGroq(
model="llama-3.1-8b-instant",
groq_api_key=GROQ_API_KEY,
temperature=0
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
• RetrievalQA:リトリーバー(FAISS)とLLMを組み合わせて、取得したコンテンツに基づいてプロンプトに回答します。
• プロンプト:履歴書のテキストと抽出指示を渡します。
prompt = f"""
この履歴書から「実績」と「資格」のセクションを抽出してください。
有効なJSONのみを返してください。
{text}
"""
sections = qa_chain.run(prompt)
主な機能
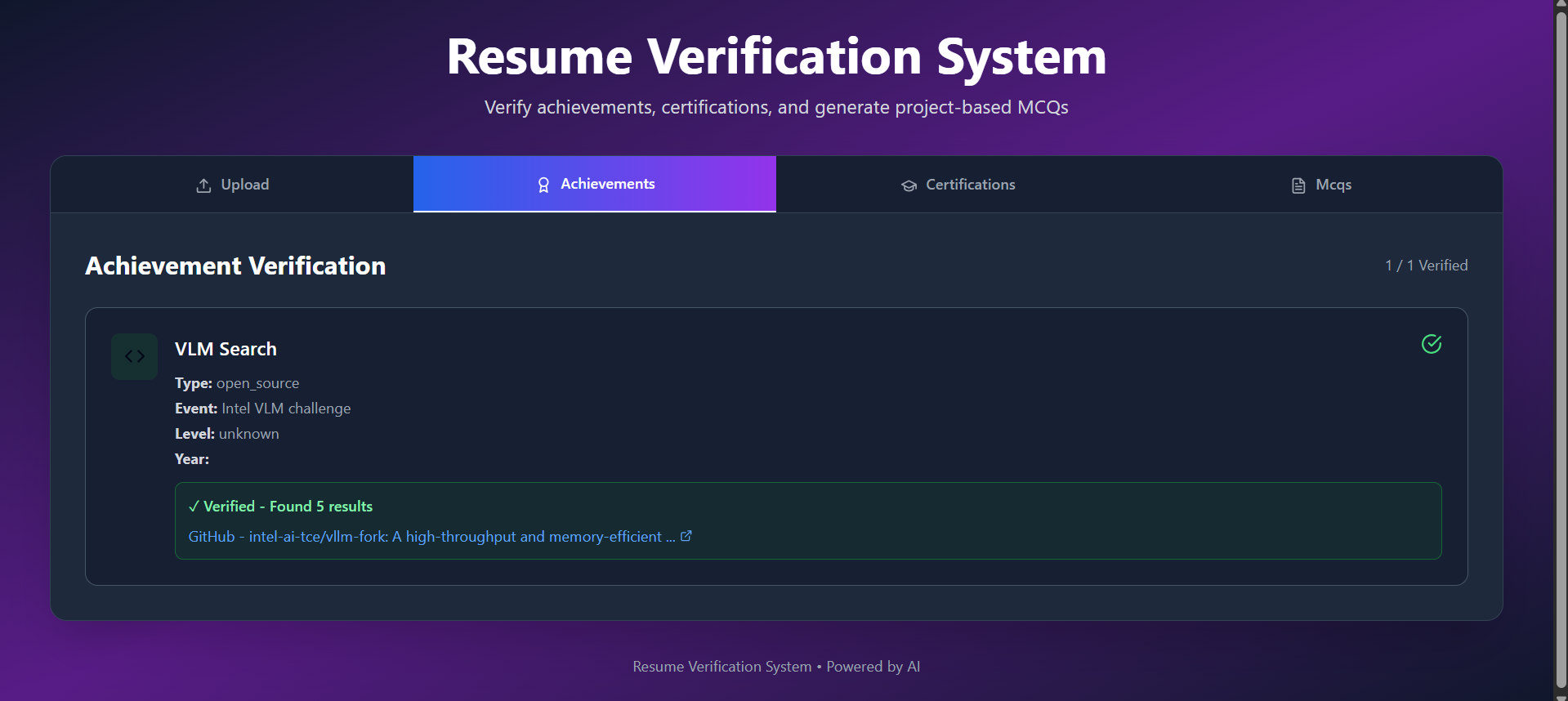
- 実績の検証
• システムは実績(ハッカソン、論文など)を特定し、オンラインで検証します。
verification = verify_achievement_online(achievement)
• DuckDuckGo検索を使用し、BeautifulSoupで結果を解析してオンラインでの存在を確認します。 ________________________________________ - 資格情報抽出
• 資格情報とコースは抽出され、PDF内のハイパーリンクと照合されます。
certs_with_links, certs_without_links = match_certifications_with_links(certifications_data, extracted_links)
• 採用担当者は手動で照合することなく、資格情報を迅速に確認できます。
- プロジェクト抽出と多肢選択式問題(MCQ)生成
• 履歴書からプロジェクトが特定され、最大5つの主要プロジェクトが抽出されます。
• システムは以下を生成します。
o コアスキルをテストするための役割ベースのMCQ。
o プロジェクトの技術に基づいたプロジェクト固有のMCQ。
o 実践的な評価のためのシステム設計MCQ。
RAGの利点
• コンテキストを考慮した抽出:関連するセクションのみが分析されます。
• スケーラビリティ:さまざまな形式の複数の履歴書を処理できます。
• 正確性:検索により、LLMが関連性のないデータを生成しないことが保証されます。
• 拡張性:スキルや学歴などの新しいセクションの追加は簡単です。
フローの概要
[PDF履歴書]
↓
[テキスト抽出]
↓
[チャンク化と埋め込み]
↓
[FAISSベクトルストア] <-- セマンティック検索
↓
[LLM (ChatGroq)] <-- 拡張生成
↓
[JSON出力] <-- 実績、資格情報、プロジェクト、MCQ
結論
このバックエンドは、実用的なRAG(Retrieval Augmented Generation)アプリケーションの例を示しています。
• 入力:履歴書PDFファイル
• 処理:テキストをチャンクに分割し、埋め込みベクトルを作成、関連テキストを検索し、大規模言語モデル(LLM)を介して構造化された出力を生成します。
• 出力:検証可能な実績、資格証明書のリンク、プロジェクト情報の抽出、自動生成された多肢選択式問題(MCQ)
これにより、履歴書選考がより迅速、自動化され、検証可能になるため、採用担当者や人事チームの時間を大幅に節約できます。
コード実行プロセス:
2つのコマンドプロンプトを開き、1つでフロントエンドコードを実行します。
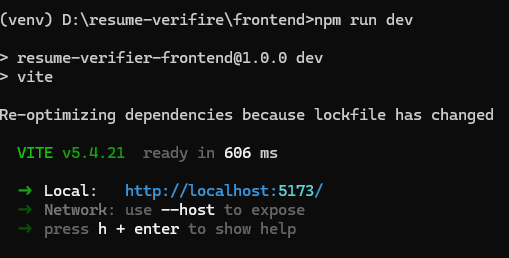
もう1つでバックエンドコードを実行します。

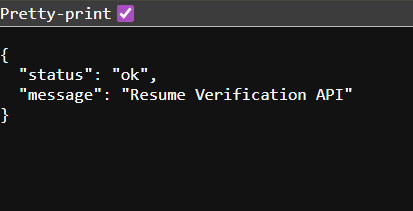
バックエンドコードから以下のような確認メッセージが表示されたら、
実際の出力ウェブサイト(私の場合は http://localhost:5173/ でした)を以下に示すように使用できます。
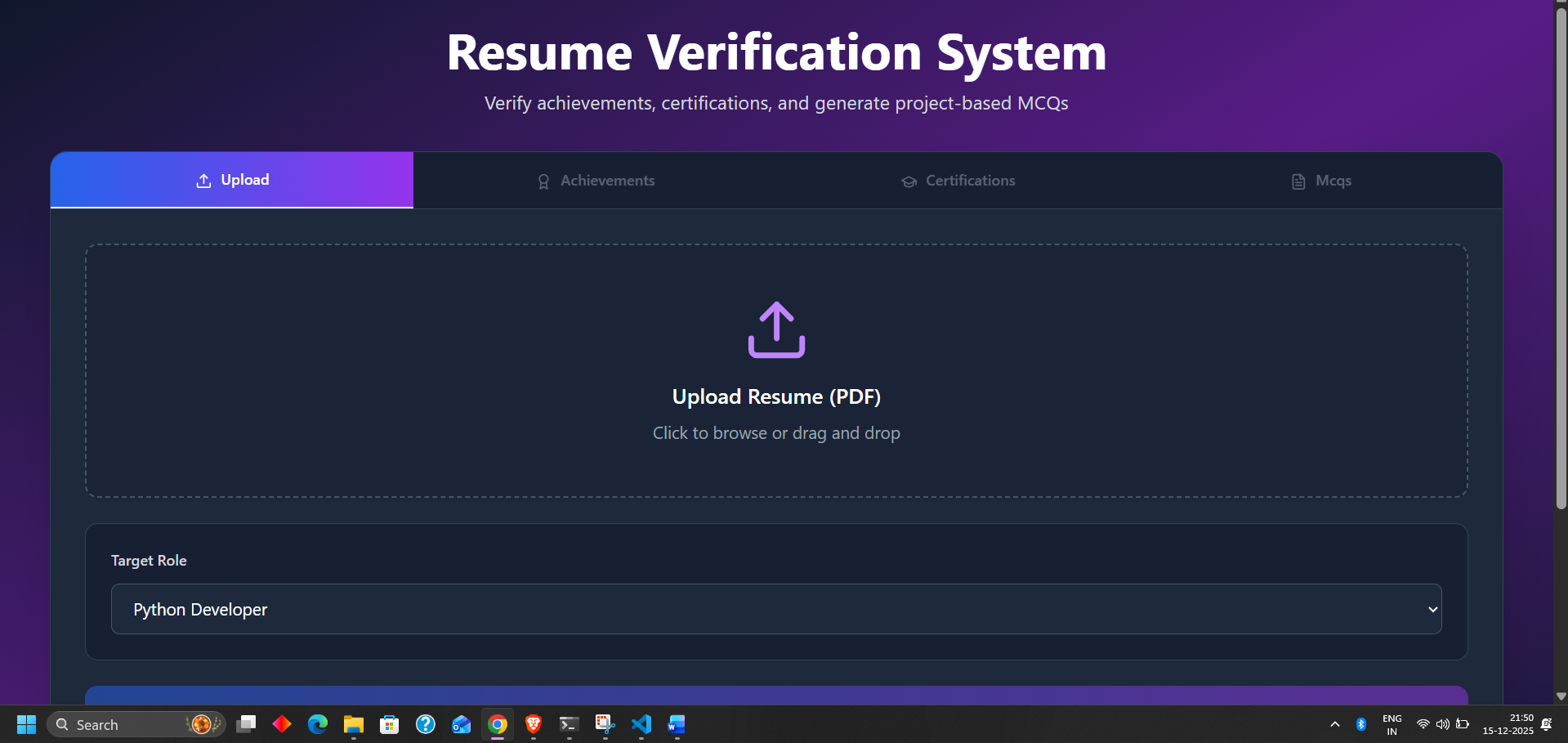
出力