はじめに
双日テックイノベーションの安藤です。
弊社では、CData製品の販売およびインテグレーションサービスを提供を通じて、データ基盤の企画、設計、構築から運用まで、幅広くご支援しております。また、お客様のデータの可視化や分析に至るまでの一貫したサポートを行い、データ活用を包括的なご支援を行っています。
本記事では、CData Syncの強みであるあらゆるデータソースとのデータ同期を活用しながら、dbt Coreを組み合わせることで、データエンジニア、データアナリスト、データサイエンティストにとって重要となるデータカタログ、データリネージュを簡易的に構築する方法をご紹介します。
参考記事
https://www.cdata.com/jp/blog/sync-dbt
https://cdn.cdata.com/help/ASK/jp/sync/dbt-Transformations.html
<対象読者>
- ELTを活用したモダンなデータ基盤を構築したい方
- データカタログやリネージュ(データの流れ)を管理したい方
- クラウドサービスやデータソースから効率的にデータを集めたい方
<概要>
- CData Syncで多様なデータソースからノーコードでデータ同期を実現
- dbt CoreでSQLだけで煩雑なデータ加工やデータマート構築を効率化
- dbt Coreでデータカタログやデータリネージュを簡単に生成
<ETLとELTの違い>
データ基盤の構築では「ETL」と「ELT」というアプローチがあります。ここでは、それぞれの特徴を簡単に説明します。
ETL(Extract, Transform, Load)
- データソースからデータを抽出(Extract)
- データ基盤に保存する前に加工(Transform)
- 加工済みデータをデータ基盤に格納(Load)
特徴
加工済みデータのみが保存されるため、データの柔軟性は低め。
ELT(Extract, Load, Transform)
- データソースからデータを抽出(Extract)
- 加工せずにそのままデータ基盤に格納(Load)
- 必要に応じてデータ基盤内で加工(Transform)
特徴
生データを保存するため、用途に応じた柔軟な加工が可能。
この違いを料理に例えると…![]()
ELTの場合
肉屋で豚肉、八百屋でじゃがいもやにんじんを購入(データソースからデータを取得)
それらを冷蔵庫にそのまま保存(データ基盤に生データを格納)
必要に応じて、後でカレーライスや肉じゃがなど、好きな料理(用途に応じたデータ)も加工可能
ETLの場合
最初からカレーライスを作り、冷蔵庫に保存。(データ基盤に加工済みデータを保存)
後で肉じゃがを作りたくなったら、もう一度材料を肉屋と八百屋で買い直す必要があり非効率…。
冷蔵庫(データ基盤)に生の状態で食材(データ)を保存することで、後から食材(データ)を自由に活用・再利用できるのがELTの強みです。
※食材とデータの違いとして、食材は消費されますが、データは消費されない点は異なります。
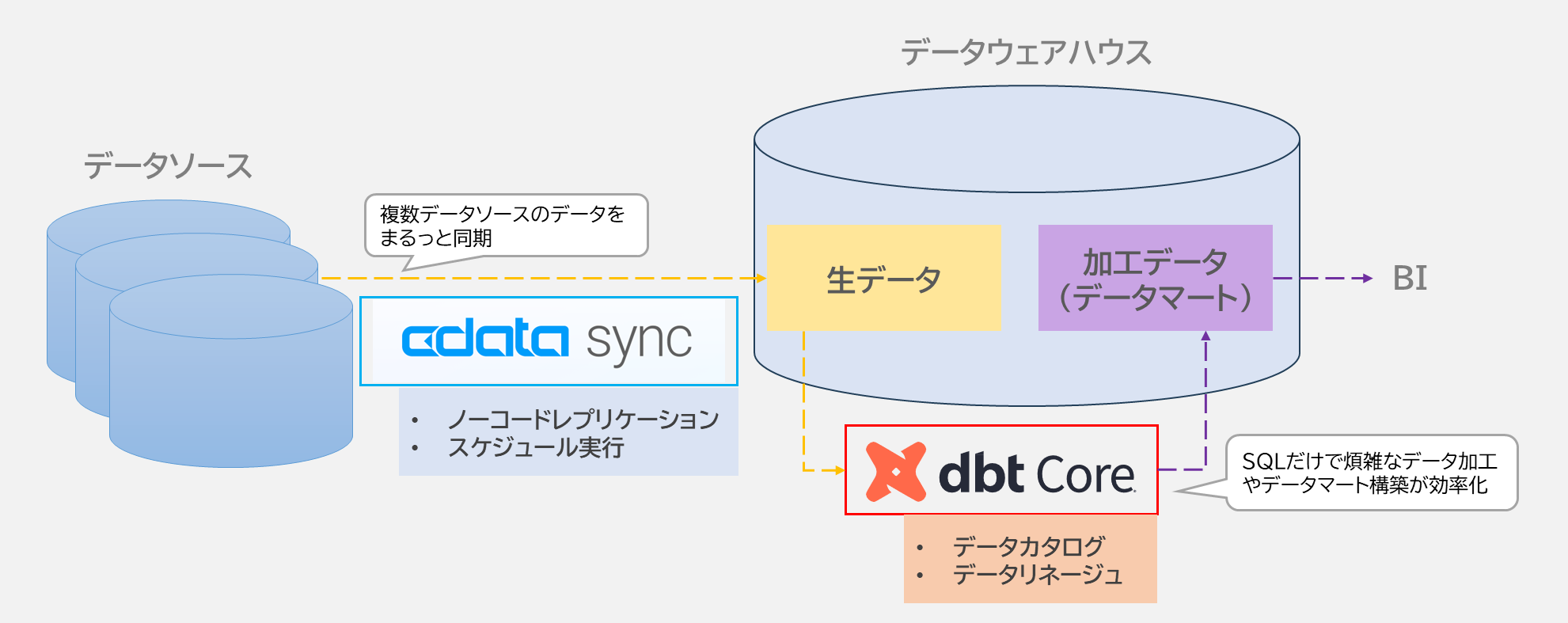
CData Sync × dbt Core を使ったモダンデータ基盤の構築
CData Sync
CData Sync は、多様なデータソース(クラウドサービス、アプリケーション、データベースなど)からデータを簡単に収集・転送できるツールです。
特徴
- ノーコードでデータ同期処理(レプリケーション)のセットアップが可能
- クラウドサービス、各種DBなど数百種類以上のデータソースに対応
- ELT形式でデータをデータ基盤に保存
dbt Core
dbt Core は、データ基盤上のデータを加工・変換するためのツールで、オープンソースのため、無料で利用可能です。
SQLベースで操作できるため、データエンジニアだけでなく、アナリストでも利用可能です。
dbtには、有償のプロダクトであるdbt Cloudも展開されています。これはSaaS形式で提供されており、GUIを備えた使いやすいインターフェースでdbt coreに豊富な機能を追加しています。また、CData Syncは、dbt Core、dbt Cloudの両方に対応しています。
特徴
- SQLでデータの変換を定義可能
- データリネージュ(データの流れ)を自動的に可視化
- データモデルのドキュメント生成(カタログ管理)が可能
CData Sync × dbt Coreの強力な組み合わせ
この2つを組み合わせることで、次のようなモダンなデータ基盤を実現できます
- データ収集の効率化:CData Syncで様々なデータソースからデータを簡単に取得し、データ基盤に保存。
- 柔軟なデータ加工:dbt CoreでSQLベースの加工を行い、用途に応じたデータマートを作成。
- カタログ管理:データの内容や構造をわかりやすくドキュメント化。
- リネージュ追跡:データの流れや依存関係を可視化し、透明性を確保。
やってみた
環境
- OS:Windows Server 2022 Datacenter
- CData Sync:24.3.9141.0
- Python:3.12.7
- pip:24.2
-
dbt
- dbt-core:1.8.9
- dbt-redshift:1.8.1
検証内容
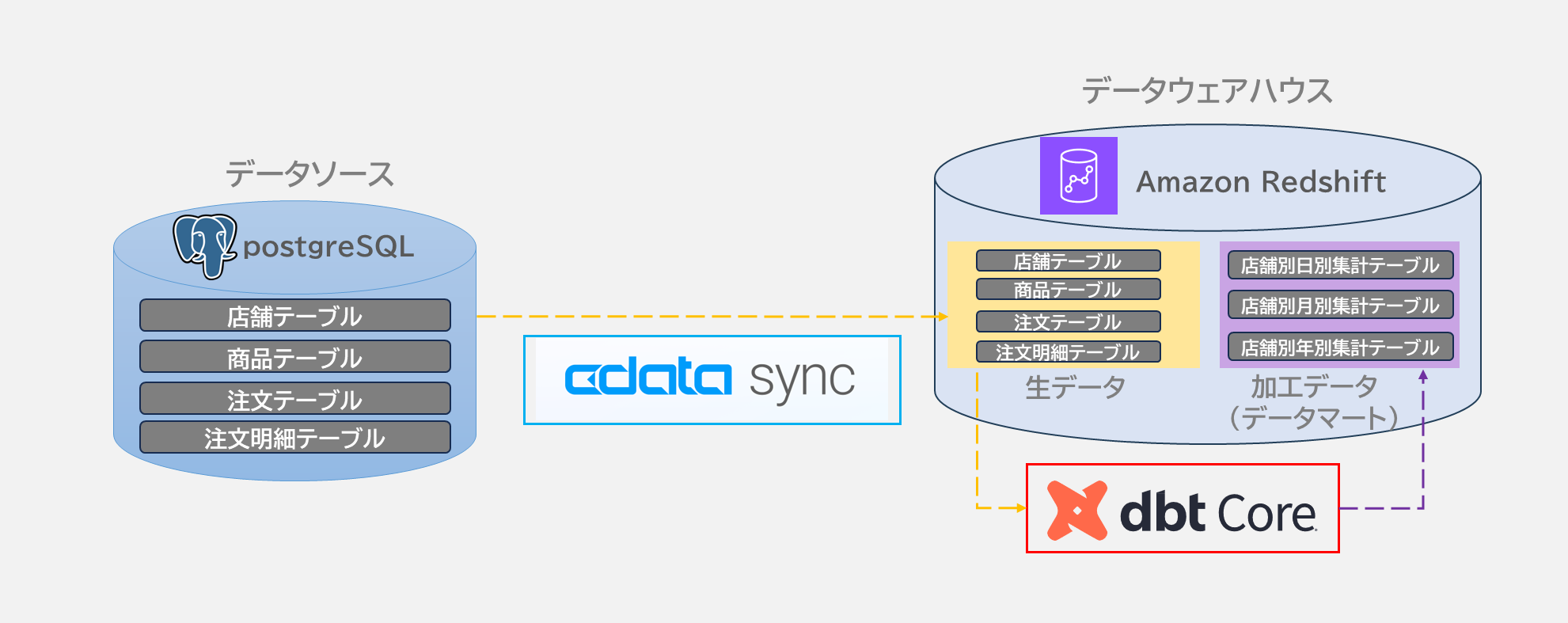
データソース:PostgresSQL
データ基盤:Amazon Redshift
元データ
| テーブル名 | 説明 | 件数 |
|---|---|---|
| Shops | 店舗情報 | 12件 |
| Products | 商品情報 | 40件 |
| Orders | 注文情報 | 約10万件 |
| Order_details | 注文明細情報 | 約30万件 |
作成するデータマート
- 店舗別日別集計テーブル
- 店舗別月別集計テーブル
- 店舗別年別集計テーブル
実施手順
事前準備
- データソース(PostgreSQL)には元データが既に存在している状態
- Amazon Redshiftは構築済みで初期状態(テーブルなし)
各種インストールおよび接続確認
-
CData Syncのインストール
-
CData Syncの接続設定を行う
- データソース:PostgreSQL
- 同期先:Amazon Redshift
-
Pythonとpipのインストール
-
dbt-core、dbt-redshiftのインストール
※
pip install dbt-core dbt-redshiftdbt-redshiftのインストール時に付随してdbt-postgresもインストールされます。
-
dbtプロジェクトの作成
例:dbt init demo_project
dbt init <任意のプロジェクト名>
-
【仮作業】dbtプロファイル設定
<ユーザーフォルダ>.dbt\profiles.yml にデータ基盤の接続情報を定義demo_project: target: dev outputs: dev: type: redshift host: <Redshiftのエンドポイント> # 例: cluster-name.XXXXXXXXXXXX.ap-northeast-1.redshift.amazonaws.com dbname: dev schema: processed # 変換後のテーブルのスキーマ port: 5439 threads: 4 user: <ユーザ名> password: <パスワード>
本ファイルは、CData Syncから実行時は使用されない定義情報となるため、本来不要な手順ですが、次の手順である「dbtとRedshiftの接続確認」にて、dbt単体での接続確認を行うため、実施しております。
-
dbtとRedshiftの接続確認
プロジェクトディレクトリで以下を実行:結果:dbt debug上記メッセージが出れば、接続完了。Connection test: [OK connection ok] All checks passed!
データパイプラインジョブの設定(レプリケーション/トランスフォーメーション)
-
CData Syncのジョブ作成
- データソース:PostgreSQL
- 同期先:Amazon Redshift
- タスク:同期するテーブルを指定
-
CData Syncのジョブ実行
- 一度、手動実行を行うことで、Amazon Redshift上に同期テーブルを作成
ジョブ実行後のRedshiftの状態

RedshiftのPUBLICスキーマに生データ(元データ)のテーブル群が生成されます。
-
dbtでのモデル定義
以下のような構造で階層ごとにデータを整理しておくのが推奨されている。
| 層 | 説明 | 推奨形式 |
|---|---|---|
| Source | 元データをそのまま取り込んだデータセット | テーブル |
| Staging | 元データをクレンジング・標準化したデータ ※本検証では使用していない
|
ビュー |
| intermediate | 複数のテーブルを結合し、分析や集計で利用しやすい形に整えたデータ | ビュー |
| Marts | ダッシュボードや特定用途向けに最適化されたデータセット | テーブル |
プロジェクトフォルダ内のmodelsの配下に上記と対応したsource、staging、intermediate、martsの各層にフォルダを作成し、定義ファイルを作成します。
-
dbtによるSourceレイヤの定義
Sourceでは、sourceフォルダの直下に以下のようなsource.ymlを作成し、既にデータ基盤上に存在している元データの内容を記載します。source.ymlversion: 2 sources: - name: demo_source schema: public tables: - name: shops description: "店舗情報を格納するテーブル。" - name: products description: "商品の情報を格納するテーブル。" - name: orders description: "注文情報を格納するテーブル。" - name: order_details description: "注文の明細情報を格納するテーブル。"カラム単位の詳細設定も可能
上記は、リネージュを行うための最低限の定義で、各カラムの説明やテストなども定義することで、カタログ管理やデータの品質の担保に役立つ定義の記載も可能です。
source.ymlversion: 2 sources: - name: demo_source schema: public tables: - name: shops description: "店舗情報を格納するテーブル。" columns: - name: shop_id description: "各店舗のユニークな識別子。" data_tests: - not_null - unique - name: shop_name description: "店舗の名前。" - name: location description: "店舗の所在地。" - name: created_at description: "店舗が作成された日時。" - name: products ・・・以下省略・・・
-
dbtによるIntermediateレイヤの定義
Sourceのデータから直接データマートを作ることが可能ですが、以下の理由でintermediateレイヤを利用するのが推奨されます:-
再利用性の向上:複数のデータマートで同じ結合ロジックを使用可能。
-
保守性の向上:カラムの追加や変更にintermediateレイヤを修正するだけで済む。
今回は、
intermediateフォルダ内に以下のようなdetailed_order_data.sqlを作成し、各種データソースのテーブルを結合したSELECT文を記載します。
detailed_order_data.sqlWITH detailed_order_data AS ( SELECT od.order_detail_id, o.order_id, o.shop_id, s.shop_name, od.product_id, p.product_name, o.order_date, od.quantity, od.price, -- 注文明細ごとの小計を計算 od.quantity * od.price AS subtotal FROM {{ source('demo_source', 'order_details') }} od JOIN {{ source('demo_source', 'orders') }} o ON od.order_id = o.order_id JOIN {{ source('demo_source', 'products') }} p ON od.product_id = p.product_id JOIN {{ source('demo_source', 'shops') }} s ON o.shop_id = s.shop_id ) SELECT order_detail_id, order_id, shop_id, shop_name, product_id, product_name, order_date, quantity, price, subtotal FROM detailed_order_data ORDER BY order_date, shop_id, product_idポイント
- dbt特有の記法で、
{{ source('<source名>', '<テーブル名>') }}と記述します。 - 実行時にこのSELECT文がビューとして、データ基盤上に作成され、ビュー名はファイル名に基づきます。(今回の例では、
detailed_order_data)
従って、通常のSQLのようにCREATE VIEW文は使うことなく、ビューを作成できます。 - 本ビューの生成先のスキーマは、後述の手順である「CData Syncによる変換の実行」にて、CData Sync上で設定をします。今回は、スキーマ名を
processedとし、データ基盤上に当スキーマが無い場合は、スキーマも自動で作成します。
-
dbt単体で実行する場合、生成先のスキーマは、profiles.ymlで定義したスキーマとなります。
本記事において、「【仮作業】dbtプロファイル設定」で設定した通り、スキーマ名はprocessedとなります。
-
dbtのMacroの活用
Martsレイヤの作成にあたり、今回の例ですと、最終形となるデータマートは、店舗ごとの集計など共通処理が多いため、Macroを使用して、SQLコードを共通化します。
プロジェクトフォルダ内のmacrosの配下にファイルを作成します。
Macroは、繰り返し使用されるSQLコードを関数化し、効率的かつ再利用可能な形で定義できます。
これにより、プロジェクト全体の柔軟性、保守性、可読性を向上させることができます。- SQLコードの重複を削減:共通部分を関数化し、記述量を減らす。
- 柔軟性の向上:動的な部分はパラメータを設定することで、呼び出し時に値を設定可能。
- 保守性の向上:共通コードを変更が必要な場合、Macrosを修正するだけで対応可能。
具体的には、先ほど用意した
Intermediateレイヤで定義したdetailed_order_dataを店舗ごとの集計処理を共通化した上で、粒度(日/月/年)の設定はパラメータ{{grain}}で設定できるようにします。aggregate_sales_by_period.sql{% macro aggregate_sales_by_period(grain) %} SELECT shop_id, shop_name, DATE_TRUNC('{{ grain }}', order_date) AS period, --粒度を動的に指定 SUM(subtotal) AS total_sales FROM {{ ref('detailed_order_data') }} -- 中間ビューを参照 GROUP BY shop_id, shop_name, DATE_TRUNC('{{ grain }}', order_date) --粒度を動的に指定 ORDER BY period, shop_id {% endmacro %}ポイント
- macroは、パラメータ化が可能で、モデル内での呼び出しが可能です。
今回の例では、パラメータとして、{{grain}}を定義し、
モデル内{{aggregate_sales_by_period('year')}}のように呼び出し可能。 - dbt特有の記法でモデルは
{{ ref('<モデル名>'}}で別モデルを参照します。
今回の例では、Intermediateレイヤで定義したdetailed_order_dataを参照しています。
-
dbtによる
Martsレイヤの定義
最終的にMartsレイヤにビジネスユーザーが直接利用するデータマートを作成します。
このレイヤは、ユーザーのニーズに応じた最終形のデータセットを提供する事を目的としています。
今回の例では、martsフォルダ内に先ほどの定義したMacroを活用し、店舗別売上を日・月・年単位で集計するテーブルを作ります。店舗別日別集計テーブル
shop_daily_sales.sql{{ config(materialized='table') }} {{aggregate_sales_by_period('day')}}店舗別月別集計テーブル
shop_monthly_sales.sql{{ config(materialized='table') }} {{aggregate_sales_by_period('month')}}店舗別年別集計テーブル
shop_yearly_sales.sql{{ config(materialized='table') }} {{aggregate_sales_by_period('year')}}必須ではありませんが、データカタログ用に各テーブルの各カラムの説明するための
schema.ymlもmartsフォルダ内に作成します。schema.ymlversion: 2 models: - name: shop_daily_sales description: "店舗ごとの日単位の売上を集計したテーブル。" columns: - name: shop_id description: "店舗のユニークな識別子。" - name: shop_name description: "店舗の名前。" - name: period description: "集計対象の日付(各日の開始時刻を示す)。" - name: total_sales description: "指定された日の売上合計額。" - name: shop_monthly_sales description: "店舗ごとの月単位の売上を集計したテーブル。" columns: - name: shop_id description: "店舗のユニークな識別子。" - name: shop_name description: "店舗の名前。" - name: period description: "集計対象の月(各月の開始日を示す)。" - name: total_sales description: "指定された月の売上合計額。" - name: shop_yearly_sales description: "店舗ごとの年単位の売上を集計したテーブル。" columns: - name: shop_id description: "店舗のユニークな識別子。" - name: shop_name description: "店舗の名前。" - name: period description: "集計対象の年(各年の開始日を示す)。" - name: total_sales description: "指定された年の売上合計額。"ポイント
- {{ config(materialized='table') }}を設定することで、ビューではなく、物理テーブルを作成します。ビューで構築してしまうと、毎回結果を得るのに集計処理が必要となるため、Martsレイヤでは、高速なクエリ応答を得るために物理テーブル化するのが推奨されます。
- 実行時にこのSELECT文がテーブルとして、データ基盤上に作成され、テーブル名はファイル名に基づきます。従って、通常のSQLのようにCREATE TABLE文は書く必要がなく、テーブルを作成できます。
-
CData Syncによる変換の実行
CData Syncの変換機能を用いて、同期ジョブの完了後にdbt runコマンドを自動で実行する事ができます。
このコマンドによって、先ほど定義したSQLの依存関係を整理され、データ基盤であるAmazon Redshift上にビューやテーブルを生成されます。
<設定手順>
変換を追加
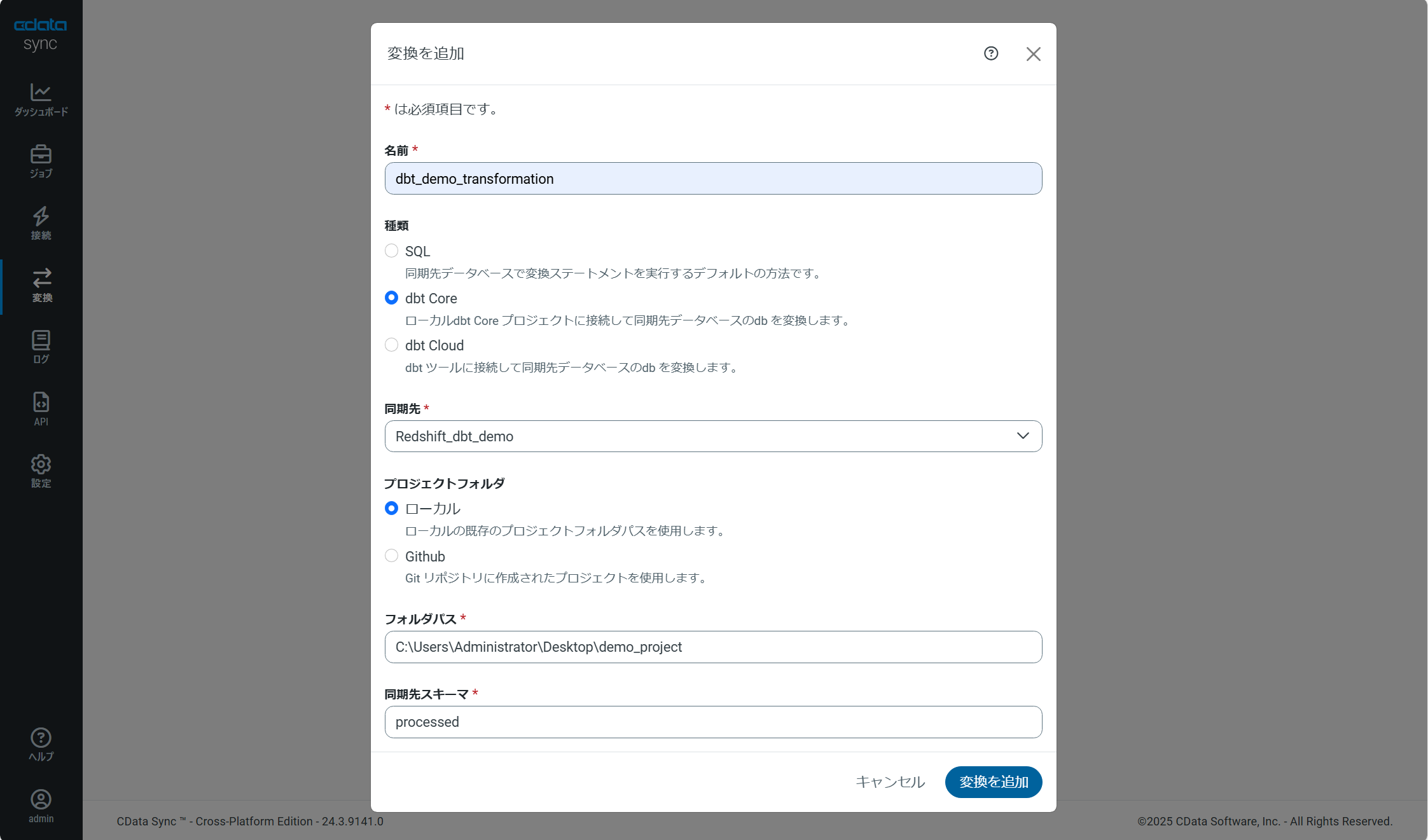
- 名前:任意
- 種類:dbt Core
- 同期先:事前にCData Syncの接続設定で定義したAmazon Redshiftを指定
- プロジェクトフォルダ:今回はローカルを選択
- フォルダパス:dbtプロジェクトのフォルダパスを指定
-
同期先スキーマ:生成するビューやテーブルのスキーマ名を指定
トリガーの編集
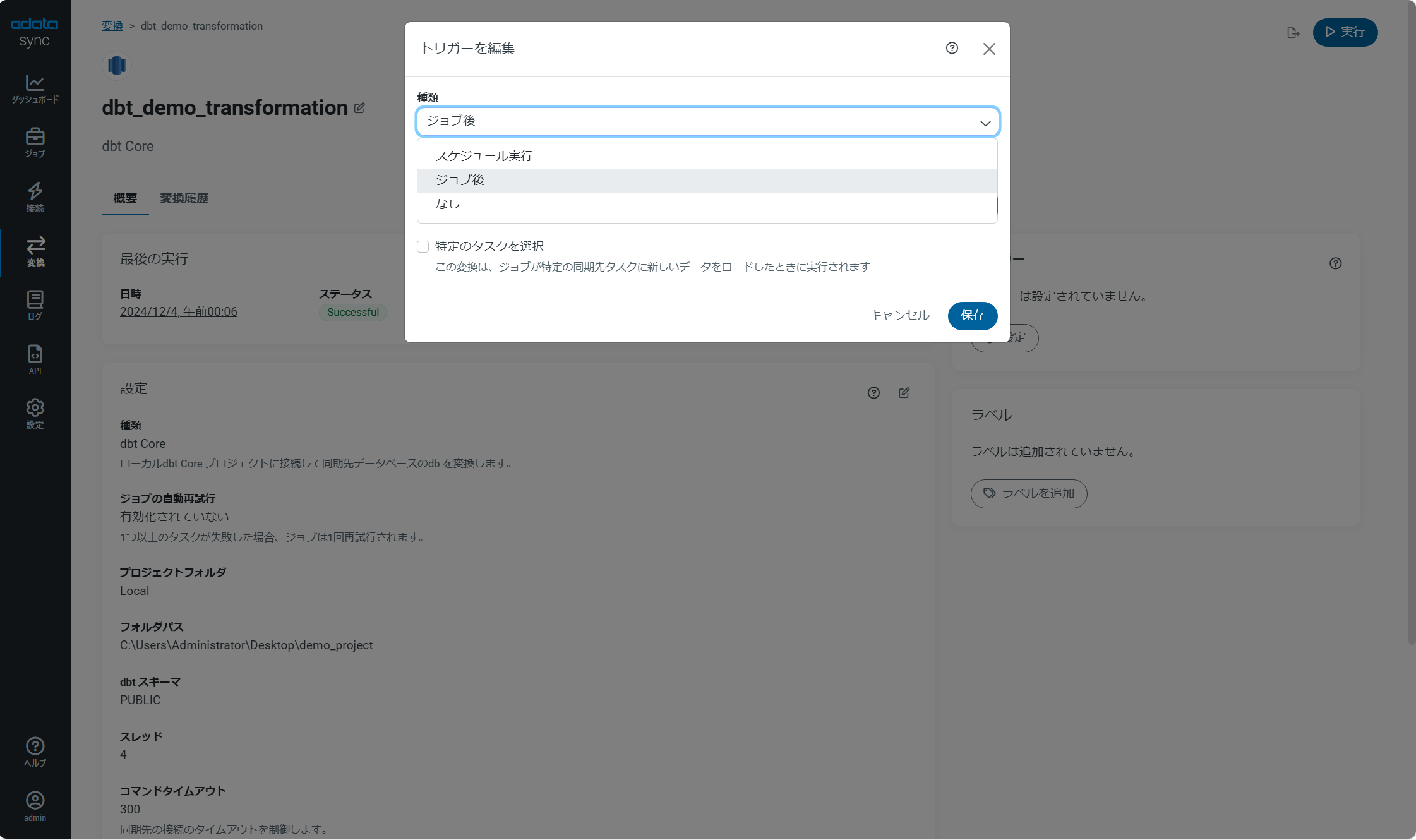
スケジュール実行や特定のジョブ後に自動で起動させる事が可能
変換を実行する
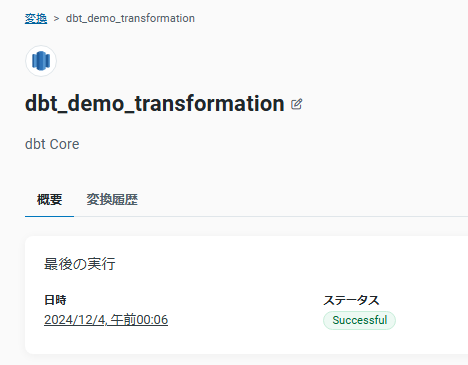
変換実行後のRedshiftの状態
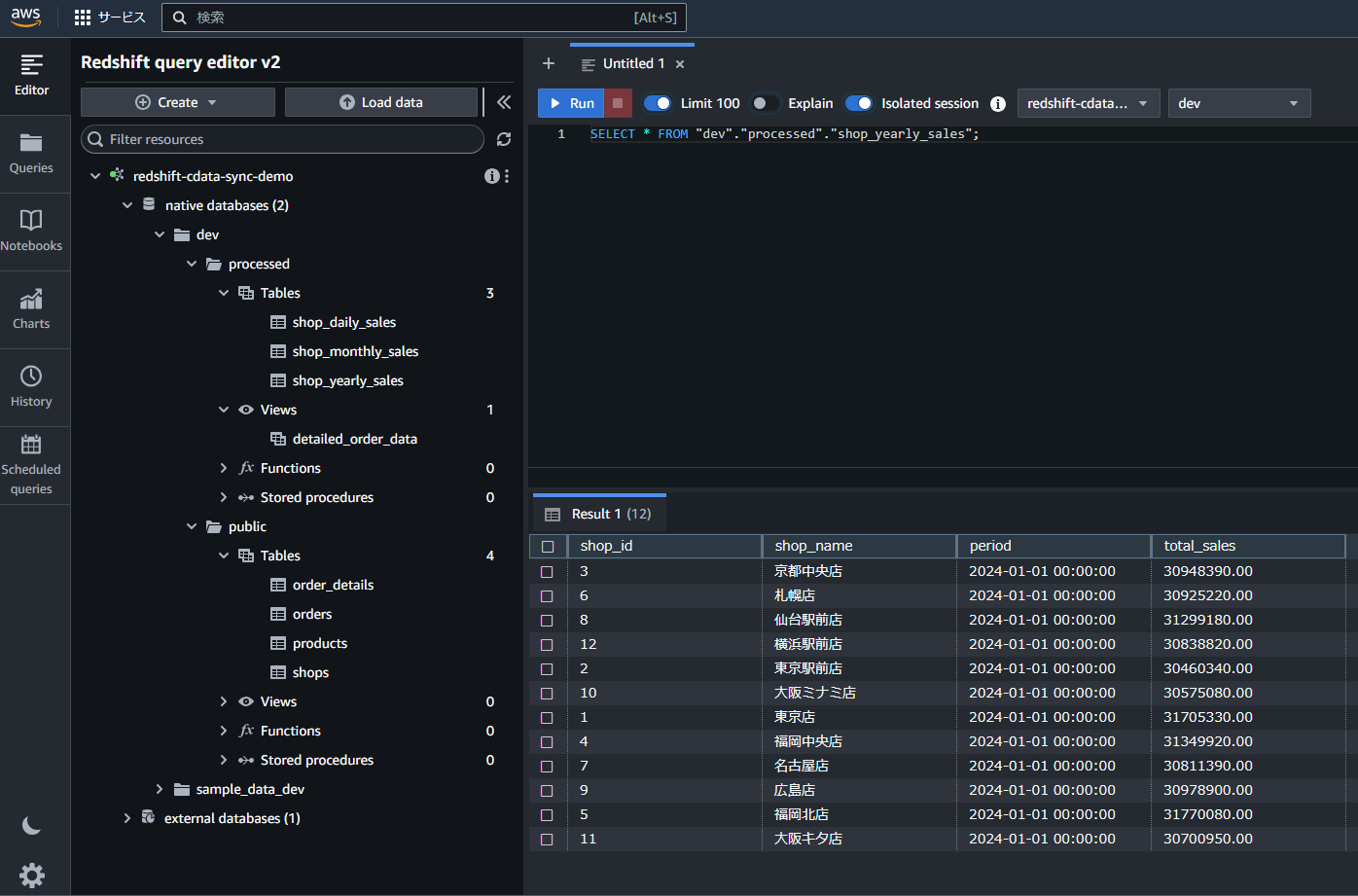
processedスキーマが作成および下記のビューやテーブルが作成されている。 -
detailed_order_dataのビュー -
shop_daily_salesテーブル -
shop_monthly_salesテーブル -
shop_yearly_salesテーブル
-
dbtでドキュメントの生成
変換実行後、以下のコマンドでデータモデルのドキュメントを生成し、Webブラウザ上でデータカタログやリネージュ(データの流れ)を可視化できます。プロジェクトディレクトリで以下のコマンドを実行します:
dbt docs generate dbt docs serveコマンド実行後、以下のようなメッセージが表示されます:
Serving docs at 8080 To access from your browser, navigate to: http://localhost:8080 Press Ctrl+C to exit. 127.0.0.1 - - [04/Dec/2024 07:58:18] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [04/Dec/2024 07:58:19] "GET /manifest.json?cb=1733266699085 HTTP/1.1" 200 - 127.0.0.1 - - [04/Dec/2024 07:58:19] "GET /catalog.json?cb=1733266699085 HTTP/1.1" 200 - 127.0.0.1 - - [04/Dec/2024 07:58:19] code 404, message File not found 127.0.0.1 - - [04/Dec/2024 07:58:19] "GET /$%7Brequire('./assets/favicons/favicon.ico')%7D HTTP/1.1" 404 -上記のメッセージが表示されたら、Webブラウザで以下のlocalhostのURLにアクセスできます:
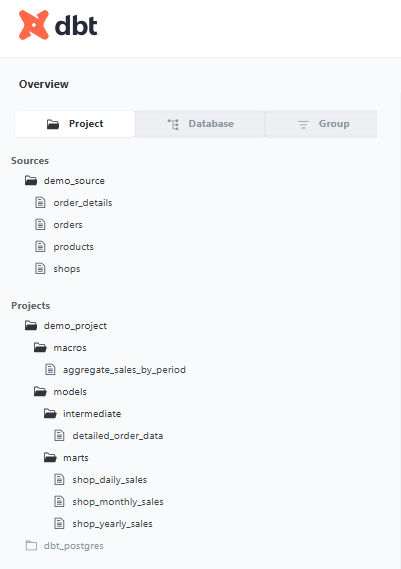
※コマンド実行後、Webブラウザが自動で起動されます。http://localhost:8080プロジェクト構造の確認
「Project」タブを開くと見るとdbtで定義した各モデルの階層構造が確認できます。
※dbt_postgresフォルダは自動で生成されていました。
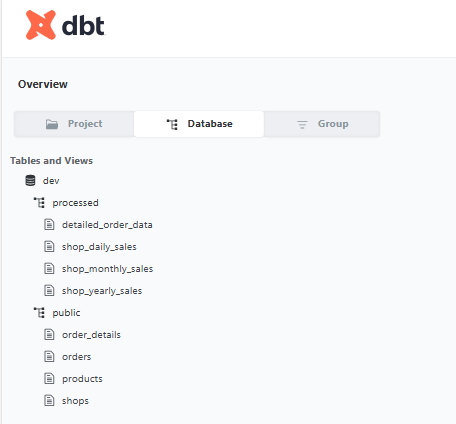
データベース構造の確認
「Database」タブでは、Redshift上に構築されたテーブルやビューの構成が確認できます、を見るとソースおよびモデルの実体であるRedshift上の構成も確認できます。
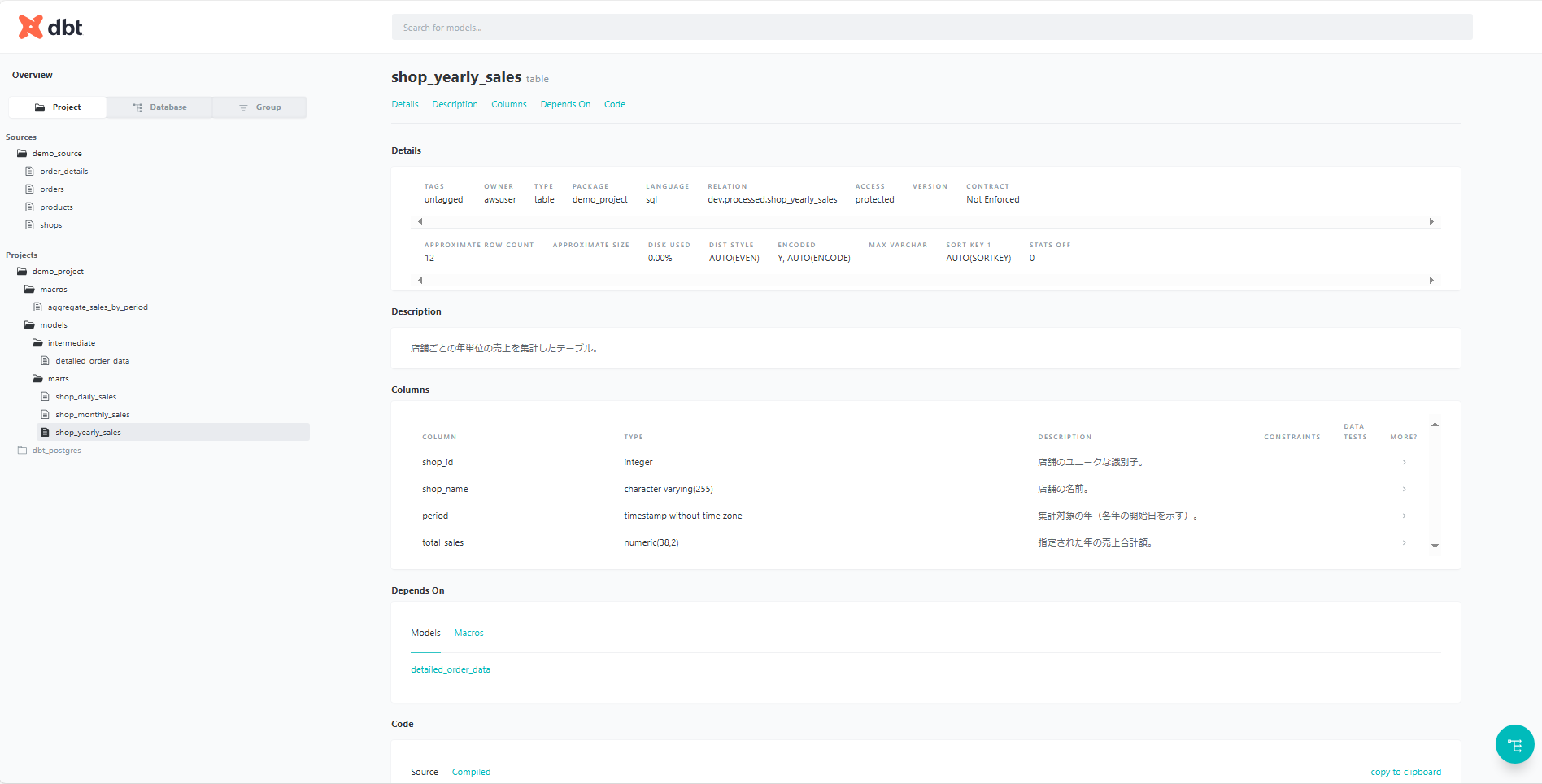
データカタログの確認
任意のテーブルを選択すると、schema.ymlに定義したでカラム説明が表示されます。
データリネージュ
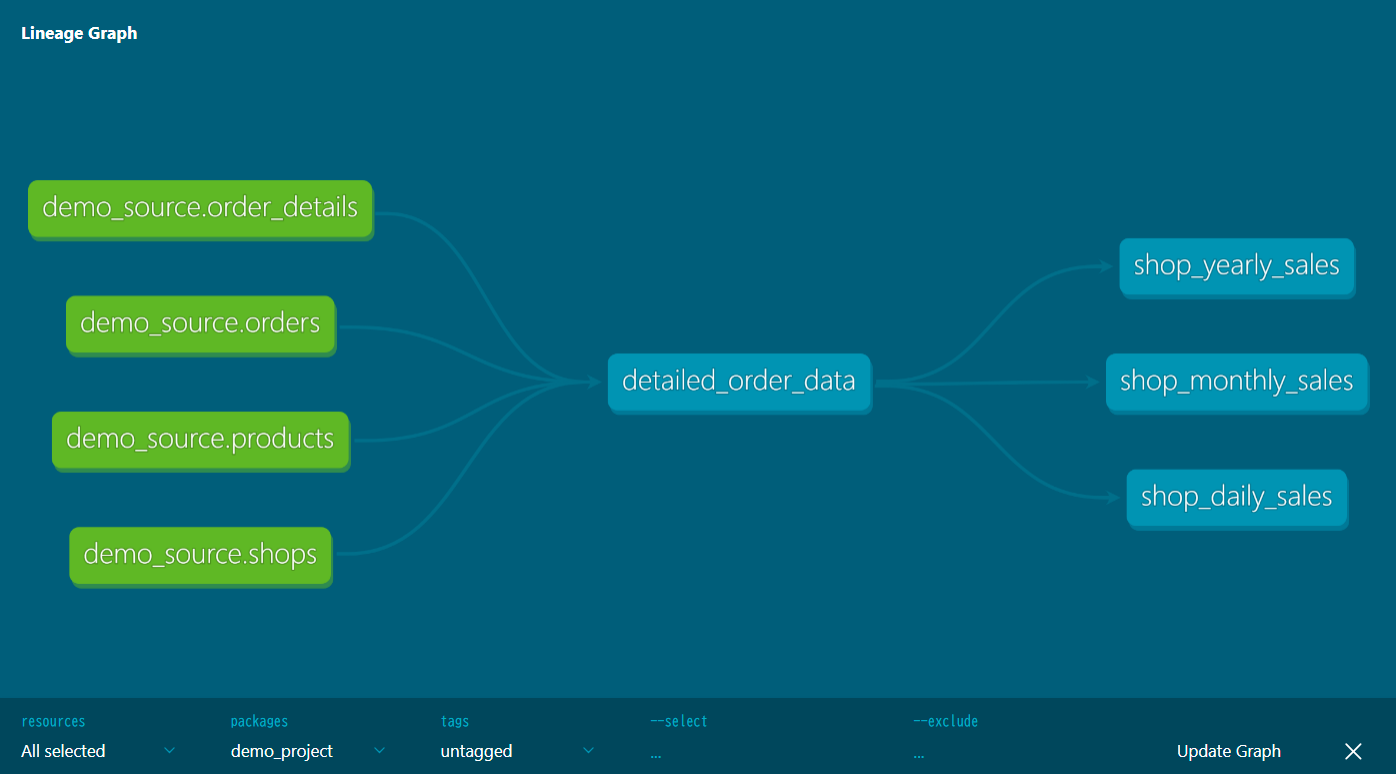
画面右下の緑色の丸いボタンをクリックすると、データリネージュを確認できます。
モデル間の依存関係が視覚的に表示され、データフローを把握できます。
今回の例では、以下のようにデータフローが視覚的に確認できます。-
生データ(Sourceレイヤ)
-
shops、products、orders、order_detailsの4つのテーブルが「データの出発点」として表示されます。
-
-
中間データ(Intermediateレイヤ)
-
detailed_order_dataビューが、生データから作成されていることが分かります。
-
-
データマート(Martsレイヤ)
-
shop_daily_sales、shop_monthly_sales、shop_yearly_salesの3つのデータマートテーブルが、中間データから作成されていることが分かります。
-
-
生データ(Sourceレイヤ)
まとめ
今回の手順により、CData SyncによるPostgreSQLからAmazon Redshiftへのデータ同期、dbtを活用した効率的なデータモデル構築、データリネージュの可視化、ドキュメント生成までを実現できました。