EmbeddingモデルやLLMも含め、外部サービスを使わず、すべてローカル環境でRAGアプリを実装してみました。
社内情報など機密性の高いデータを生成AIと組み合わせて活用する場合、やはりセキュリティが課題となります。
本記事のように外部サービスを使わず実装できると、そういった課題が払拭でき、より簡単にRAGを使った生成AIアプリを試せます。
なお今回はEmbeddingモデルとLLMの稼働には LangChain を使いました。
また LangChain で稼働させた各モデルを LangServe を使ってREST APIアクセス可能にし、Oracle APEXのアプリから利用できるようにしました。
検証環境
- VM: OCI VM.Standard3.Flex (3 OCPU、48GB RAM)
- OS: Oracle Linux Server release 8.9
※すべて1つのサーバで実行します。
事前準備
Oracle Database 23ai + APEXによるRAGアプリの作成
まずはOracle Database 23ai + APEXでRAGアプリを実装する必要があります。
一から実装頂いても良いですが、作業数が多いため、アプリのexportファイルを以下に置いています。
https://github.com/mago1chi/apex/blob/main/ragapp_local_llm.sql
importするにあたり、以下記事の作業を事前に行う必要がありますのでご注意ください。
-
Oracle Database 23ai FreeとAPEXでRAGを使った生成AIアプリをローコード開発してみた (事前準備編)
- 外部サービスを使わずDB内Embeddingを行うため「Cohere向け資格証明の設定」の作業は不要です
- 代わりにオプションとして記載している下記作業の実施が必要です
- (オプション) ONNX利用のためのOML4Pyのセットアップ
- (オプション) ONNXのexport/import
-
Oracle Database 23ai FreeとAPEXでRAGを使った生成AIアプリをローコード開発してみた (アプリ実装 前編)
- 「ワークスペースの作成」までを実施します。
一から実装したい方は以下の記事にまとめた手順を参照してください。
-
Oracle Database 23ai FreeとAPEXでRAGを使った生成AIアプリをローコード開発してみた (事前準備編)
- 外部サービスを使わずDB内Embeddingを行うため「Cohere向け資格証明の設定」の作業は不要です
- 代わりにオプションとして記載している下記作業の実施が必要です
- (オプション) ONNX利用のためのOML4Pyのセットアップ
- (オプション) ONNXのexport/import
-
Oracle Database 23ai FreeとAPEXでRAGを使った生成AIアプリをローコード開発してみた (アプリ実装 前編)
- 「PL/SQLを使ったデータ保存処理の実装」で使うPL/SQLのコードは、ONNXモデルを使うため「(参考) EmbeddingにONNX形式でimportしたモデルを使う場合」に記載しているコードを使用してください
- Oracle Database 23ai FreeとAPEXでRAGを使った生成AIアプリをローコード開発してみた (アプリ実装 後編)
OSパッケージ、Pythonパッケージのインストール
LangChainやEmbeddingモデル、LLMの利用に必要な各インストール作業は、以下記事の「パッケージのインストール」を参照してください。
Oracle Database 23ai + LangChainを使いローカル環境のみでRAGを試してみた
上記に加え LangServe をインストールします。
対象のPython仮想環境を activate した状態で以下を実行します。
$ pip install langserve[server] pydantic==1.10.13
LangServeの実装
LangChain を使ってローカル環境でLLMを稼働させ、それを LangServe でREST APIとして公開します。
from fastapi import FastAPI
from langchain_community.llms.llamacpp import LlamaCpp
from langserve import add_routes
# REST API公開するアプリを定義
app = FastAPI(
title="LangServe",
version="1.0",
description="LangChain Server",
)
# ダウンロード済みLLMの絶対パス
model_path = "/home/oracle/llm/vicuna-13b-v1.5.Q4_K_M.gguf"
# モデルの読み込み
llm = LlamaCpp(
model_path=model_path,
n_ctx=2048,
max_tokens=4096
)
# REST API公開するURLパス、機能を定義
add_routes(
app,
llm,
path="/vicuna",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app)
上記を例えば「serve.py」というファイル名で保存した場合、以下のように実行します。
正常に稼働すればプロンプトは戻ってきません。
$ python serve.py
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
...(略)...
Using fallback chat format: llama-2
INFO: Started server process [200552]
INFO: Waiting for application startup.
__ ___ .__ __. _______ _______. _______ .______ ____ ____ _______
| | / \ | \ | | / _____| / || ____|| _ \ \ \ / / | ____|
| | / ^ \ | \| | | | __ | (----`| |__ | |_) | \ \/ / | |__
| | / /_\ \ | . ` | | | |_ | \ \ | __| | / \ / | __|
| `----./ _____ \ | |\ | | |__| | .----) | | |____ | |\ \----. \ / | |____
|_______/__/ \__\ |__| \__| \______| |_______/ |_______|| _| `._____| \__/ |_______|
LANGSERVE: Playground for chain "/vicuna/" is live at:
LANGSERVE: │
LANGSERVE: └──> /vicuna/playground/
LANGSERVE:
LANGSERVE: See all available routes at /docs/
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
これで LangServe の準備が完了し、ローカル環境のLLMをREST APIを使って利用できるようになりました。
生成AIによる回答生成のPL/SQLコード
アプリをimportせず、一から実装した方は、APEX向け事前準備の「PL/SQLを使ったベクトル検索、生成AI連携の実装」のPL/SQLコードを、以下のコードで置き換えます。
DECLARE
l_rest_url VARCHAR2(4000) := 'http://127.0.0.1:8000/vicuna/invoke';
l_context CLOB;
l_prompt CLOB;
l_response_json CLOB;
l_body CLOB;
l_citation CLOB;
CURSOR C1 IS
SELECT jt.*
FROM JSON_TABLE(l_response_json, '$'
COLUMNS (output VARCHAR2(4000) PATH '$.output' )) jt;
BEGIN
-- 引用元の情報を格納する変数を用意
l_citation := '<table><tr><th>ファイル名</th><th>該当テキスト</th></tr>';
-- ベクトル検索を実行し、RAGに使用するコンテキストを取得
IF :P4_CATEGORY IS NULL THEN
IF :P4_DOCNUM IS NULL THEN
-- カテゴリ、保証ドキュメント数の指定がない場合のクエリ
FOR rec IN (SELECT doc.doc_filename doc_filename, em.embed_data embed_data
FROM documents doc, embed em
WHERE doc.id = em.doc_id AND TRUNC(doc.doc_lastupd) BETWEEN :P4_BEGIN_DATE AND :P4_END_DATE
ORDER BY VECTOR_DISTANCE(em.embedding, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING :P4_QUESTION as data)), COSINE)
FETCH EXACT FIRST :P4_NUM ROWS ONLY)
LOOP
-- プロンプトに埋め込むコンテキストを追記
l_context := l_context || rec.embed_data;
-- 引用元情報を追記
l_citation := l_citation || '<tr><td>' || rec.doc_filename || '</td><td>' || rec.embed_data || '</td></tr>';
END LOOP;
ELSE
-- カテゴリの指定がなく、保証ドキュメント数の指定がある場合のクエリ
FOR rec IN (SELECT doc.doc_filename doc_filename, em.embed_data embed_data
FROM documents doc, embed em
WHERE doc.id = em.doc_id AND TRUNC(doc.doc_lastupd) BETWEEN :P4_BEGIN_DATE AND :P4_END_DATE
ORDER BY VECTOR_DISTANCE(em.embedding, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING :P4_QUESTION as data)), COSINE)
FETCH EXACT FIRST :P4_DOCNUM PARTITIONS BY doc.id, :P4_NUM ROWS ONLY)
LOOP
-- プロンプトに埋め込むコンテキストを追記
l_context := l_context || rec.embed_data;
-- 引用元情報を追記
l_citation := l_citation || '<tr><td>' || rec.doc_filename || '</td><td>' || rec.embed_data || '</td></tr>';
END LOOP;
END IF;
ELSE
-- カテゴリの指定があり、保証ドキュメント数の指定がない場合のクエリ
IF :P4_DOCNUM IS NULL THEN
FOR rec IN (SELECT doc.doc_filename doc_filename, em.embed_data embed_data
FROM documents doc, embed em
WHERE doc.id = em.doc_id AND
doc.category IN (SELECT column_value FROM APEX_STRING.SPLIT(:P4_CATEGORY,':')) AND
TRUNC(doc.doc_lastupd) BETWEEN :P4_BEGIN_DATE AND :P4_END_DATE
ORDER BY VECTOR_DISTANCE(em.embedding, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING :P4_QUESTION as data)), COSINE)
FETCH EXACT FIRST :P4_NUM ROWS ONLY)
LOOP
-- プロンプトに埋め込むコンテキストを追記
l_context := l_context || rec.embed_data;
-- 引用元情報を追記
l_citation := l_citation || '<tr><td>' || rec.doc_filename || '</td><td>' || rec.embed_data || '</td></tr>';
END LOOP;
ELSE
-- カテゴリ、保証ドキュメント数の指定がある場合のクエリ
FOR rec IN (SELECT doc.doc_filename doc_filename, em.embed_data embed_data
FROM documents doc, embed em
WHERE doc.id = em.doc_id AND
doc.category IN (SELECT column_value FROM APEX_STRING.SPLIT(:P4_CATEGORY,':')) AND
TRUNC(doc.doc_lastupd) BETWEEN :P4_BEGIN_DATE AND :P4_END_DATE
ORDER BY VECTOR_DISTANCE(em.embedding, TO_VECTOR(VECTOR_EMBEDDING(doc_model USING :P4_QUESTION as data)), COSINE)
FETCH EXACT FIRST :P4_DOCNUM PARTITIONS BY doc.id, :P4_NUM ROWS ONLY)
LOOP
-- プロンプトに埋め込むコンテキストを追記
l_context := l_context || rec.embed_data;
-- 引用元情報を追記
l_citation := l_citation || '<tr><td>' || rec.doc_filename || '</td><td>' || rec.embed_data || '</td></tr>';
END LOOP;
END IF;
END IF;
-- プロンプト生成
-- ベクトル検索結果をコンテキストとして埋め込むことでRAGを実装
l_prompt := '次の文脈を利用して、最後の質問に簡潔に答えてください。文脈: ' || l_context || ' 質問: ' || :P4_QUESTION || ' 回答(日本語): ';
-- LLMにPOSTリクエストするためのBody設定
l_body := '{ "input": "'|| APEX_ESCAPE.JSON(l_prompt) ||'" }';
-- LLMにPOSTリクエストするためのHeader設定
APEX_WEB_SERVICE.G_REQUEST_HEADERS.DELETE;
APEX_WEB_SERVICE.G_REQUEST_HEADERS(1).NAME := 'Content-Type';
APEX_WEB_SERVICE.G_REQUEST_HEADERS(1).VALUE := 'application/json';
-- LLMにREST API発行
l_response_json := APEX_WEB_SERVICE.MAKE_REST_REQUEST
(p_url => l_rest_url,
p_http_method => 'POST',
p_body => l_body,
p_transfer_timeout => 600);
-- LLMからの応答を回答表示用アイテムに格納
FOR row_1 IN C1 LOOP
:P4_ANSWER := row_1.output;
END LOOP;
-- 引用元情報を引用元表示用アイテムに格納
:P4_CITATION := l_citation || '</table>';
END;
LangServe 向けに修正した点ですが、まず2行目が該当します。
l_rest_url VARCHAR2(4000) := 'http://127.0.0.1:8000/vicuna/invoke';
LangServe は localhost の 8000 (デフォルトのポート) で待ち受けてます。
また /vicuna は LangServe 向けコードの 27行目 に記載したものです。
/invoke は LangServe が自動で用意してくれるテキスト生成用のエンドポイントです。
また 92~96行目 については資格証明に対応する引数の指定がなくなっています。
使ってみる
まずはRAGを使わずに質問してみます。
質問内容は「Oracle Database 23aiの主要な新機能は何ですか?」です。
APEXで実装したアプリはRAG利用前提のため、curl コマンドで素のLLMに質問してみます。
curl -X 'POST' \
'http://127.0.0.1:8000/vicuna/invoke' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"input": "Oracle Database 23aiの主要な新機能は何ですか?",
"config": {},
"kwargs": {}
}'
回答は以下になります。
LLMの学習データには23aiの情報がないため、ハルシネーションを起こしています。
(見やすいように適宜改行を入れています。)
{
"output": "\n\nOracle Database 23aiには、以下のような主要な新機能が含まれています。
\n\n1. AI-driven自動化: Oracle Database 23aiでは、AIを活用した自動化技術が導入されており、
データベースの管理やパフォーマンス最適化、セキュリティなどの面で、より迅速かつ効果的な自動化が可能になっています。
\n2. データベース構造アプリケーション: Oracle Database 23aiは、データベースの構造を簡単かつ迅速に作成および管理できるツールを提供しています。
これにより、開発者がより効率的なデータベース設計および管理が可能になります。
\n3. 自動バックアップと冗長性: Oracle Database 23aiは、AIを活用した自動バックアップ機能を提供しています。
これにより、データベースのセキュリティや冗長性が向上し、データ損失リスクが低減されます。
\n4. サイバーセキュリティ: Oracle Database 23aiは、AIを活用したサイバーセキュリティ機能も提供しています。
これにより、データベースからの不正アクセスや攻撃に対する防御力が向上します。
\n5. 高可用性: Oracle Database 23aiは、AIを活用した高可用性機能を提供しています。
これにより、データベースのダウンタイムが最小限に抑えられ、システム全体の信頼性が向上します。
\n6. パフォーマンス最適化: Oracle Database 23aiは、AIを活用したパフォーマンス最適化機能も提供しています。
これにより、データベースのパフォーマンスが向上し、システム全体の応答性が向上します。
\n\n以上が、Oracle Database 23aiの主要な新機能です。",
"metadata": {
"run_id": "a2681e37-5dab-4887-b9c8-edef9da151f0",
"feedback_tokens": []
}
}
次にRAGを使って同じ質問をしてみます。
読み込ませるドキュメントには下記Oracle公式のブログ記事を使います。
Oracle Database 23aiを発表: 提供開始
こちらを docx ファイルに保存し、RAGアプリにアップロードします。
RAGなしパターンと同じ質問「Oracle Database 23aiの主要な新機能は何ですか?」を投げてみます。
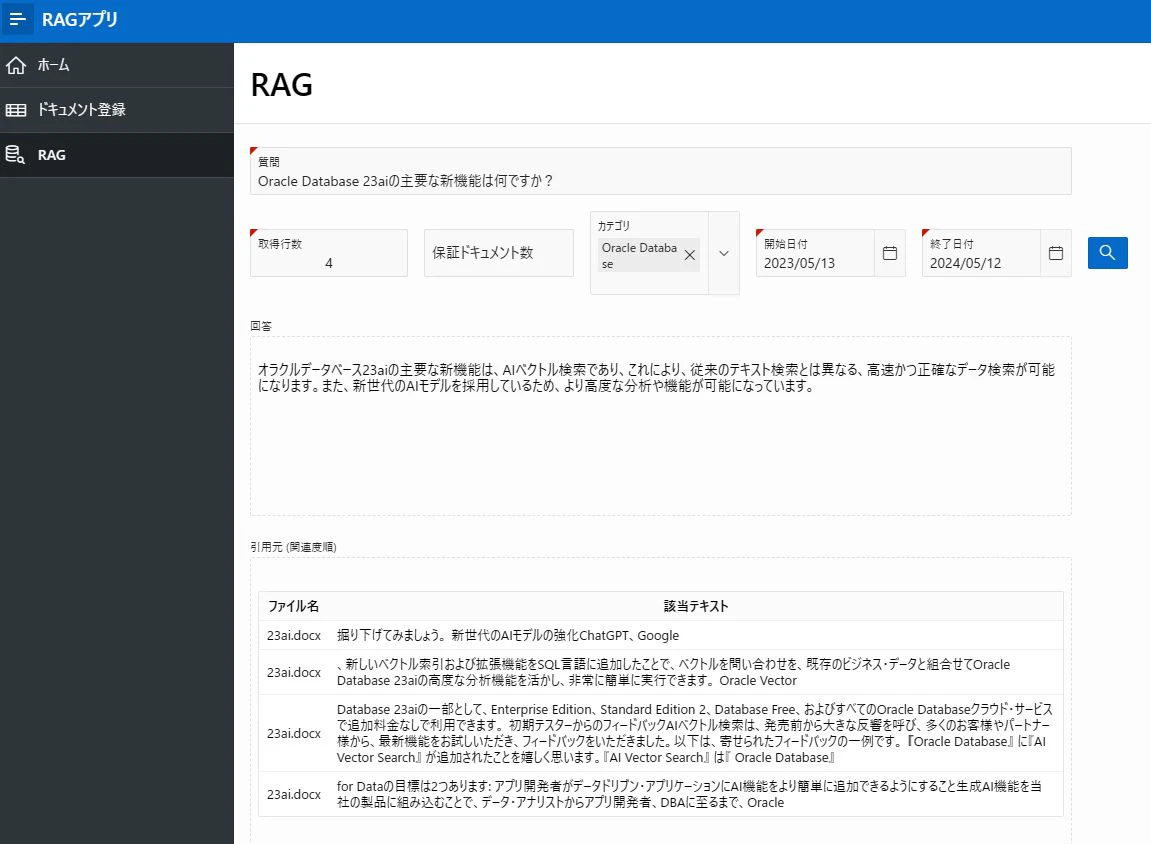
上記の通り、ブログ記事の関連テキストをベクトル検索によって抽出し、それらを引用した回答が生成されています。
RAGなしパターンよりは正確ですが、若干怪しい記述も見受けられます。
こうした問題はより精度の高いEmbeddingモデルに置き換えたり、チャンクサイズをチューニングするなどの工夫が必要です。
おわりに
以上の通り、外部サービスを使わずともRAGアプリを実装できました。
機密性の高いデータを生成AIと組み合わせて活用したいケースにおいて、本記事の内容が参考になりましたら幸いです。