はじめに
はじめまして、sakitaです !
Qiita初投稿になります!
今回はAmazon S3 Vectorsを使ってみました。
Amazon S3 Vectors は、Amazon S3上でベクトル検索を行うことができる新しい機能として発表されました。
従来、RAG(Retrieval-Augmented Generation)を構築する場合は、
- OpenSearch
- pgvector
- Pinecone
などのベクトルデータベースを用意する必要がありましたが、
S3 Vectorsの登場により、よりシンプルな構成でベクトル検索を実装できるようになりました。
S3 Vectorsは比較的新しい機能で、発表当初は利用できるリージョンが限られていましたが、
現在は東京リージョンでも利用できるようになっています。
今回はこの S3 Vectors を使って、
Amazon Bedrock Knowledge Baseと組み合わせた最小構成のRAGを試してみました。
目次
やること
今回は Amazon S3 Vectors を使って、最小構成でRAGを構築してみます。
Amazon S3 にアップロードしたPDFをそのままベクトル検索可能にし、
Amazon Bedrock を使って RAG(検索拡張生成)を構築します。
RAG(検索拡張生成)とは
RAG(Retrieval-Augmented Generation)は、
- ドキュメントを検索(Retrieval)
- 検索結果をプロンプトに追加(Augment)
- LLMが回答生成(Generation)
という仕組みで回答精度を高める方法です。
通常のLLMは学習済み知識しか使えませんが、RAGを使うことで
- 社内ドキュメント
- FAQ
- マニュアル
などをもとに回答できるようになります。
S3 Vectorsとは?
S3 Vectors は、Amazon S3 上にベクトルデータを保存し、
ベクトル検索を行うことができる新しいストレージ機能です。
従来のRAG構成では、ベクトル検索を行うために
- OpenSearch
- pgvector
- Pinecone
などの専用ベクトルデータベースが必要でした。
しかし S3 Vectors を使うことで、
- 専用の検索クラスター不要
- 常時起動リソース不要
- S3ベースで低コスト
- Bedrockと簡単に連携可能
という構成でベクトル検索を実装できます。
今回の構成では、Amazon Bedrock Knowledge Base を利用し、
ベクトルストアとして Amazon S3 Vectors を選択することで、
ベクトル化から検索までを自動で実行しています。
Knowledge Baseを利用することで、S3 Vectorsを直接操作することなく、
テキスト抽出・チャンク分割・ベクトル化・検索を自動で行うことができます。
構成
- Amazon S3(元データ保存)
- Amazon S3 Vectors(ベクトル保存)
- Amazon Bedrock(Embedding & LLM)
- Amazon Bedrock Knowledge Bases(RAGを管理してくれる機能)
※ S3 は元PDFの置き場、S3 Vectors はベクトル化したデータ(検索用)の置き場です。
構築手順
① S3バケットの作成 & ファイルアップロード
1. S3を開く
- サービス検索で「S3」を選択
2. 汎用バケットの作成
| 項目 | 設定 |
|---|---|
| バケット名 | 任意 |
| リージョン | ap-northeast-1(東京) |
| その他 | すべてデフォルト |
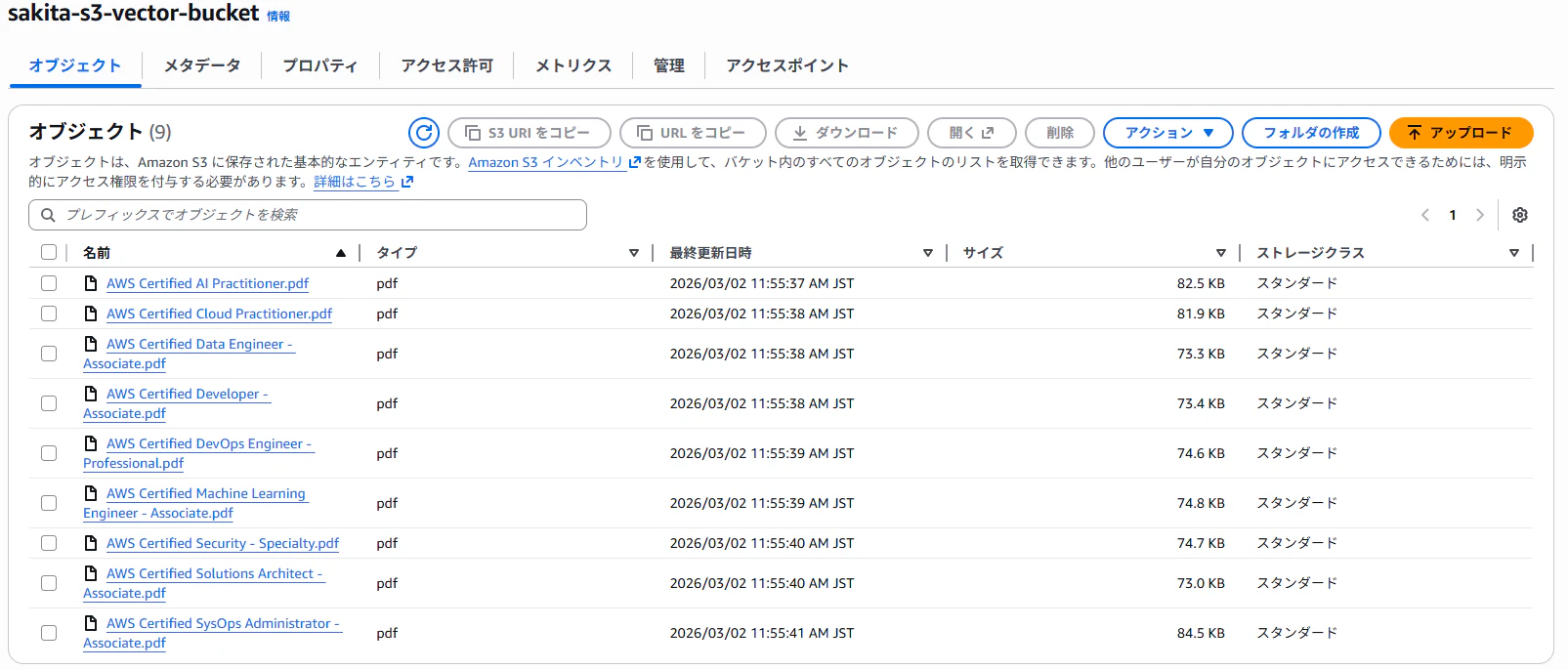
3. PDFをアップロード
今回は過去のAWSの試験結果のPDFをアップロード
② Bedrock Knowledge Bases の作成
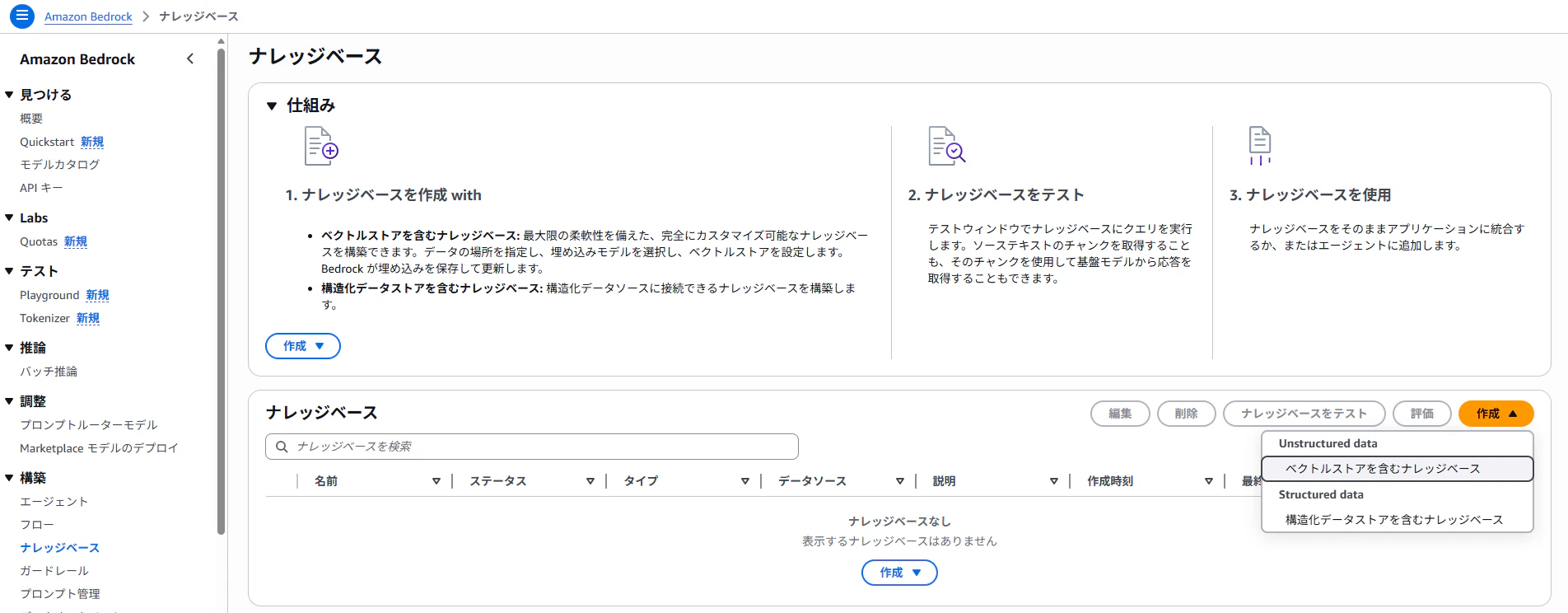
1. Amazon Bedrock を開く
- 左メニュー
「構築 → ナレッジベース」を選択
2. ナレッジベースを作成
- ベクトルストアを含むナレッジベース
設定内容
■ データソース
- Amazon S3 を選択
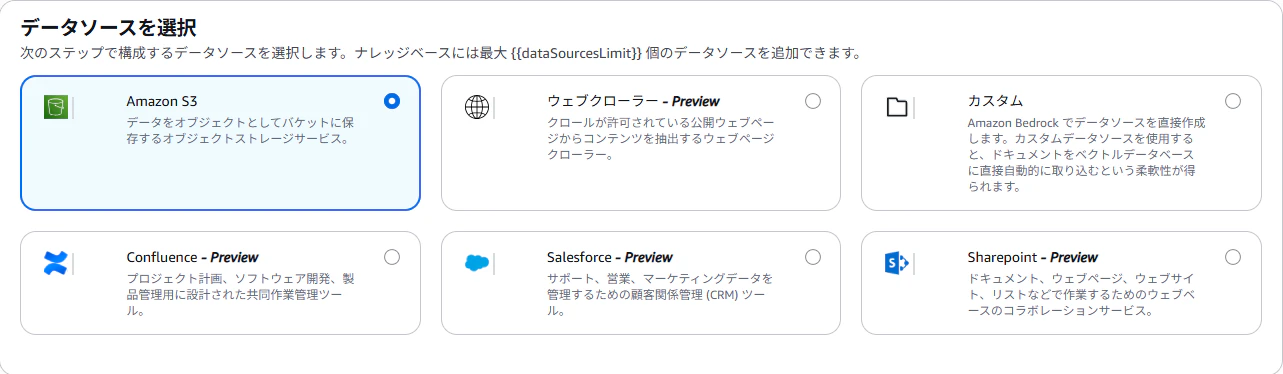
- 先ほど作成したバケットを指定

- 次へ
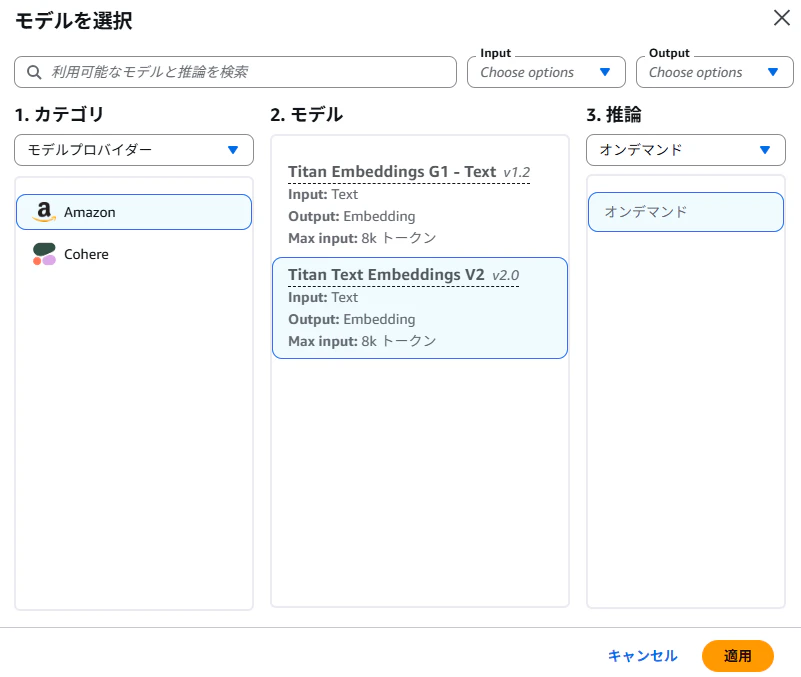
■ 埋め込みモデル
- Titan Text Embeddings V2 を選択
■ ベクトルデータベース
- 新しいベクトルストアをクイック作成
- Amazon S3 Vectors を選択

この設定で、裏側で S3 Vectors のベクトルバケットが自動作成されます。
- 設定を確認して、ナレッジベースの作成をする
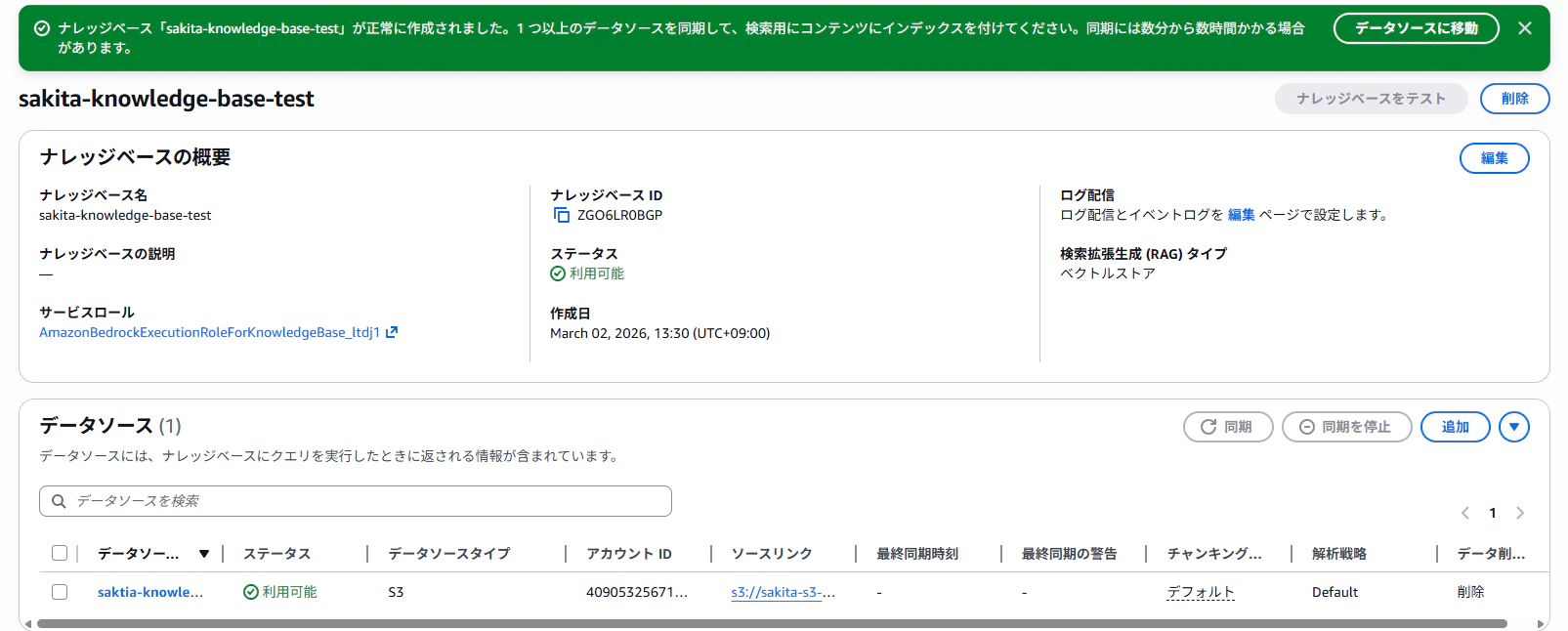
③ データの同期(ベクトル化)
- データソースの「同期」を実行

このタイミングで裏側では以下の事が行われます。
- PDFのテキスト抽出
- チャンク分割
- Embedding生成
- S3 Vectorsへ保存
④ 動作確認
1. ナレッジベースのテスト
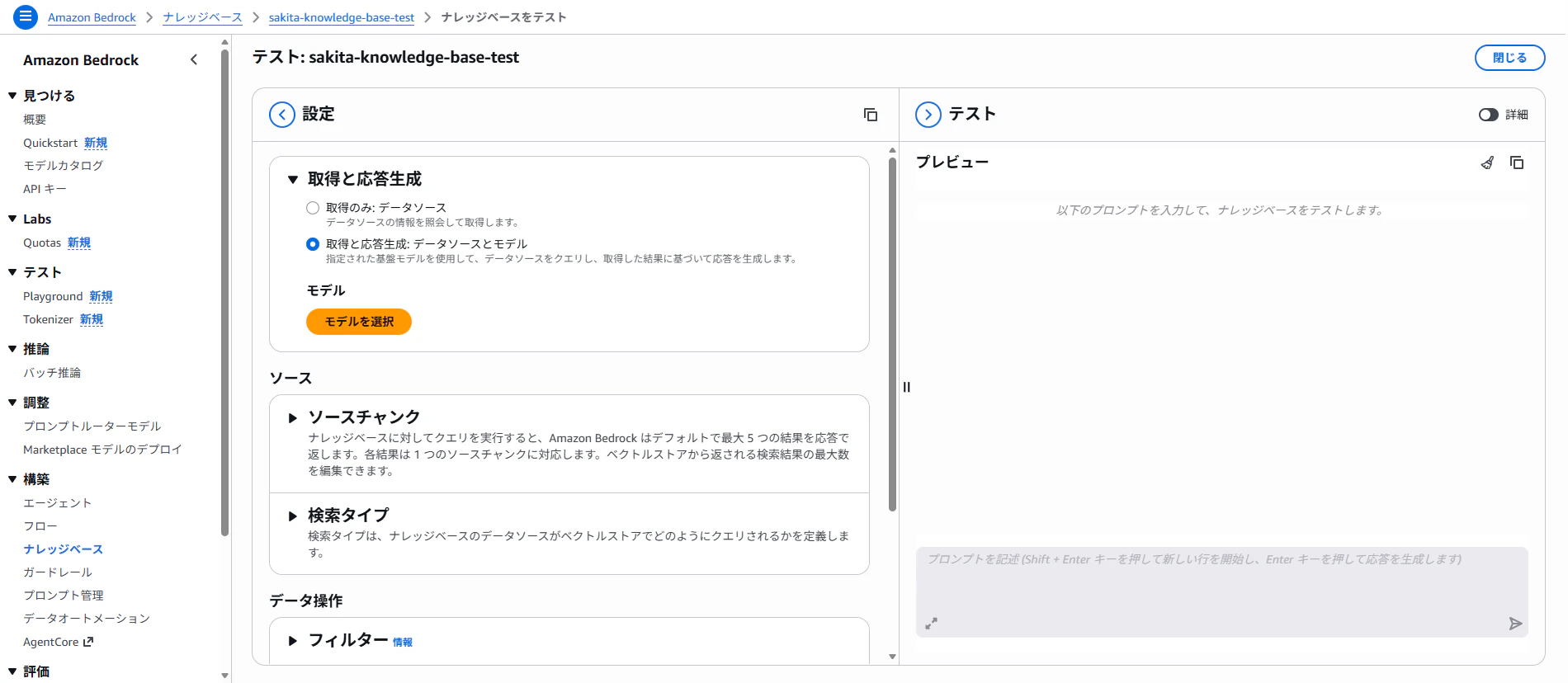
2. 「取得のみ」を選択
- 「取得のみ」は Retrieval(検索)だけを実行し、取得したチャンク(文章断片)をそのまま表示します。

質問:
AWS Certified Solutions Architect - Associateの試験の点数は?
→ 1. AWS Certified Solutions Architect - Associate 試験結果のお知らせ
→ 2. AWS Certified SysOps Administrator - Associate 試験結果のお知らせ
→ 3. AWS Certified Developer - Associate 試験結果のお知らせ
→ 4. AWS Certified Data Engineer - Associate 試験結果のお知らせ
→ 5. AWS Certified Security - Specialty 試験結果のお知らせ
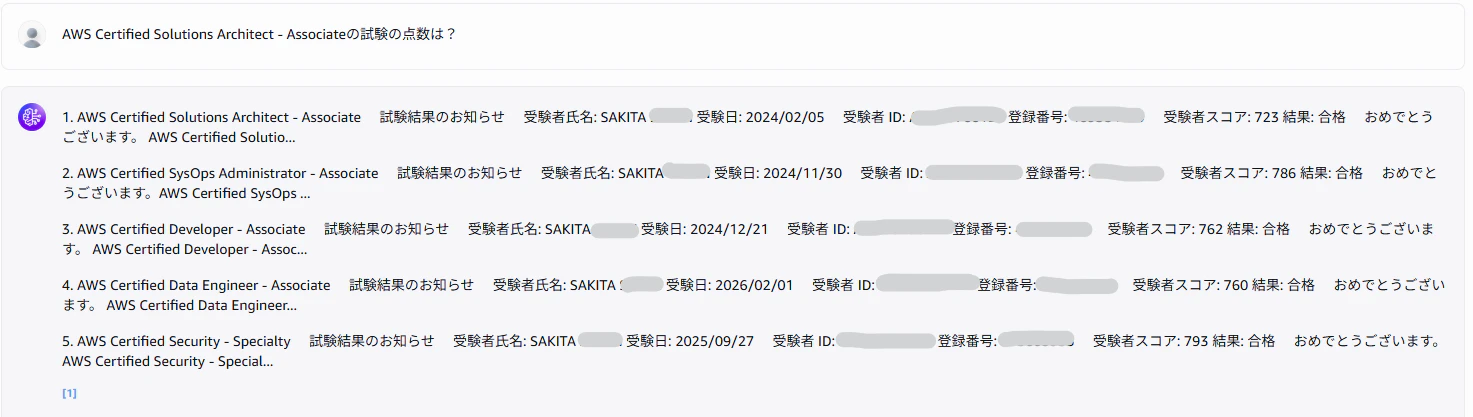
- PDFから取得した文章のみ表示
- LLMによる整形はされない
- 自然な文章ではなく、見にくい
3. 取得と応答生成(RAG)
- 「取得と応答生成」では、取得したチャンクを根拠としてLLMが回答文を生成するため、自然な文章の回答になります。
モデル:
- Anthropic Claude 3.5 Sonnet
質問:
AWS Certified Solutions Architect - Associateの試験の点数は?
→ AWS Certified Solutions Architect - Associateの試験スコアは723点でした。合格基準点は720点で、合格判定を受けています。
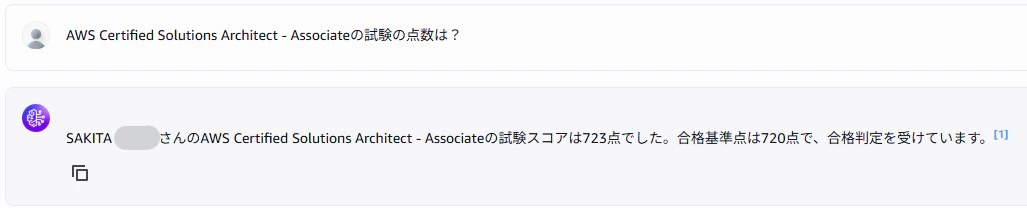
- 実際にAWS Certified Solutions Architect - Associateの試験結果のPDFに入っている受験者スコアと同じ点数で取ってこれていることが確認できました。
(それにしてもギリギリの合格。。)

4. ナレッジベースを使わずに質問(LLM単体)
質問:
AWS Certified Solutions Architect - Associateの試験の点数は?
→ AWS Certified Solutions Architect - Associate試験の詳細は以下の通りです:
→ 合格ライン: 720点以上 (100-1000点のスケール)
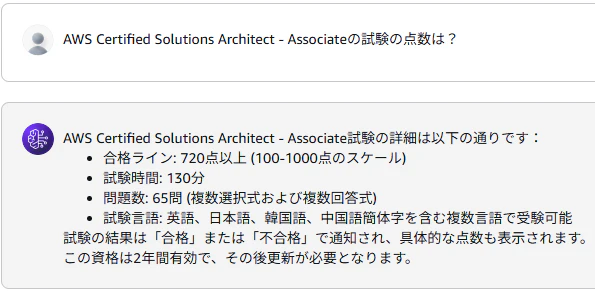
- RAGを使わない場合、PDFの内容は参照されず、一般的な試験情報が回答として返ってきました。
- RAGを使用することで、S3に保存したPDFの内容をもとに正確な回答が生成されることが確認できました。
コスト
今回の検証では、
- S3保存: 数円
- Embedding生成: 数円
- LLM推論: 数十円
程度で実施できました。
OpenSearchを使用する構成と比較すると、非常に低コストでRAGを構築できます。
まとめ
今回は、Amazon S3 にアップロードした PDF をもとに、
Amazon Bedrock Knowledge Base を利用し、
ベクトルストアとして Amazon S3 Vectors を使用した RAG を構築しました。
S3 Vectors を利用することで、
- OpenSearchなどの専用ベクトルデータベース不要
- 追加のクラスター構築なし
- S3ベースの低コスト構成
でRAGを実装することができました。
- PoC
- 社内ナレッジ検索
- 小規模データでのRAG検証
といった用途では、非常にシンプルで扱いやすい構成だと感じました。
一方で、大規模なデータ検索や高度な検索チューニングが必要な場合は、
OpenSearchなどのベクトル検索基盤を利用する構成の方が適しているケースもあると思います。
用途に応じて
- シンプルに試したい → S3 Vectors
- 本格的な検索基盤 → OpenSearch
と使い分けるのが良さそうです。
最後まで読んでいただきありがとうございました!
S3 VectorsはシンプルにRAGを試したい場合にとても便利なので、
これから触ってみる人の参考になれば嬉しいです!