※元ネタ
- "例を使用してテーブルを抽出する とは", Takeshi Kagata, 2018-05-25, Qiita, https://qiita.com/PowerBIxyz/items/ffee73e7336600ad54d6
- "Using Html.Table() To Extract URLs From A Web Page In Power BI/Power Query M", Chris Webb, 2018-08-30, CHRIS WEBB'S BI BLOG, https://blog.crossjoin.co.uk/2018/08/30/power-bi-extract-urls-web-page/
- "Web Scraping with Html.Table in Power Query", Matthew Roche, 2018-10-28, BI Polar, https://ssbipolar.com/2018/10/27/web-scraping-with-html-table-in-power-query/
関連記事
- Mから始めよう #5 〜Power BIでWebコンテンツの利用と個人用ゲートウェイ〜
- [Power BI] Power Query の Web.Contents 関数でREST APIを使う
- (Power BI) Mから始めよう #8 〜クエリ・パラメータの各種使い方
- ページ分割されているWebでページ数がわからないデータを取得する
- (Power BI) Mから始めよう #10 エラー処理とHTTPステータスコード
- [Power BI] Power QueryでCSSセレクタを使ってWebページからデータを取得する
0.Html.Tableの構文
Html.Table(
html as any, // (1)
columnNameSelectorPairs as list, // (2)
optional options as nullable record // (3)
) as table
(1)は、htmlのコードで、取得したWebページの内容が入ります。
(2)は、列名と、CSSセレクターで選択された項目の対が入ります。
(3)は、データ行をCSSセレクターで指定するRowSelectorが入ります。
1.ナビゲーターによるtableデータ取得
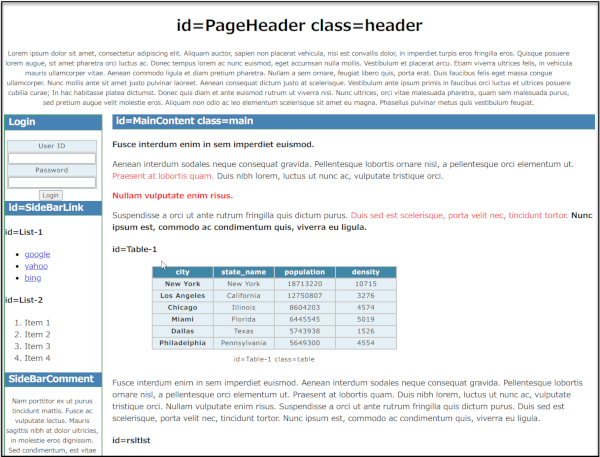
以下のようなページからテーブル項目のデータを抽出してみます。
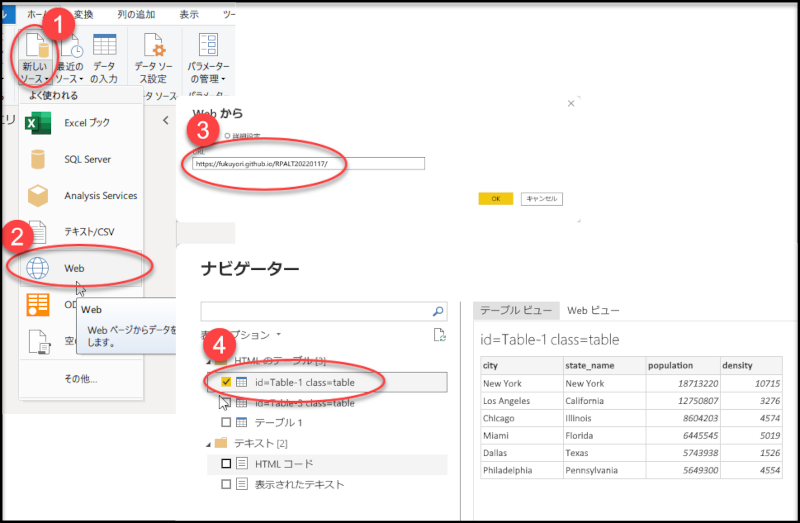
上記操作で作成されたM式は、以下のようになります。
let
ソース = Web.BrowserContents("https://fukuyori.github.io/RPALT20220117/"),
HTMLから抽出されたテーブル =
Html.Table(
ソース,
{
{"Column1", "TABLE[id='Table-1'] > * > TR > :nth-child(1)"},
{"Column2", "TABLE[id='Table-1'] > * > TR > :nth-child(2)"},
{"Column3", "TABLE[id='Table-1'] > * > TR > :nth-child(3)"},
{"Column4", "TABLE[id='Table-1'] > * > TR > :nth-child(4)"}
},
[RowSelector="TABLE[id='Table-1'] > * > TR"]
),
昇格されたヘッダー数 =
Table.PromoteHeaders(
HTMLから抽出されたテーブル,
[PromoteAllScalars=true]
)
in
昇格されたヘッダー数
2.CSSセレクター
※参照
Html.Tableの最初の引数「ソース」は、 https://fukuyori.github.io/RPALT20220117/ から取得されたWebページの内容が入ります。対象となるデータの行は第3引数の [RowSelector="TABLE[id='Table-1'] > * > TR"] ですので、idが"Table-1"の属性を持つtableタグから1つ飛ばしてtrタグで並んでいる部分が1レコードの対象になります。
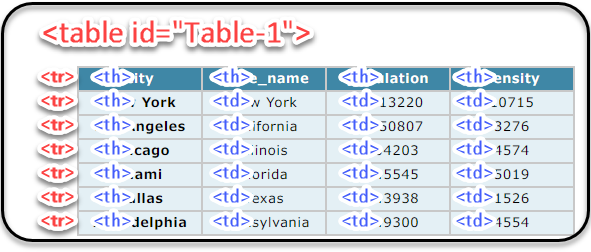
第2引数でColumn1からColumn4までの中身を指定しています。このCSSセレクタでは第3引数で指定されている部分も含めて記述されていますが、取得できる範囲は第3引数で示されているので、以下のような書き方でも同様のデータを取得できます。
Html.Table(
ソース,
{
{"Column1", "th:first-child"},
{"Column2", "th:nth-child(2),td:nth-child(2)"},
{"Column3", "th:nth-child(3),td:nth-child(3)"},
{"Column4", "th:nth-child(4),td:nth-child(3)"}
},
[RowSelector="TABLE[id='Table-1'] > * > TR"]
),
CSSセレクターの使い方については、「CSSセレクターを使いこなす : Power Automate for desktopがなんとなく使える講座 #12」でも書きましたので参照してください。ただし、jQueryのフィルター eq() 等は使えず、jQueryの子要素フィルター first-child, nth-child, nth-of-type 等は使えます。
また、いきなりタグ名なしで {"Column1", ":first-child"} のような書き方はできず、 {"Column1", "TR > :first-child"}, という書き方は可能です。
CSSセレクターを使いこなすには
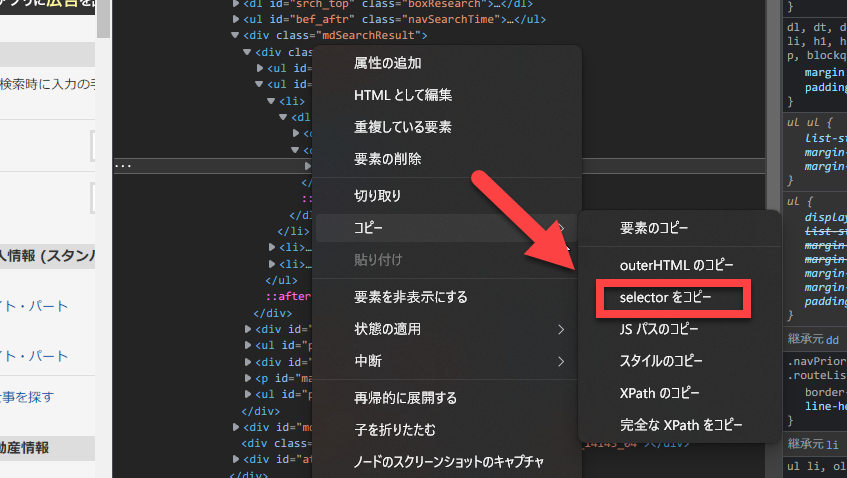
GUIに頼らないで使いこなすには、調べたい場所を右クリックして「開発者ツールで調査する」を選びます。
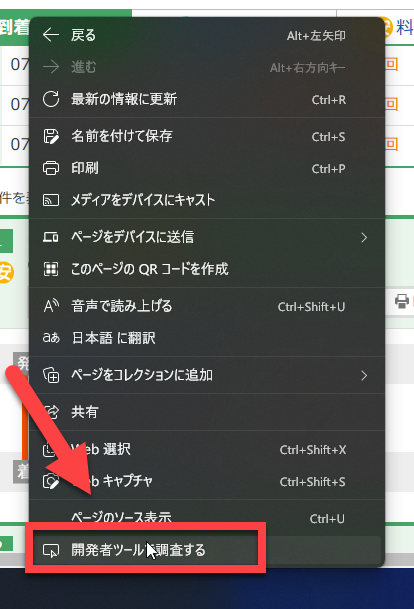
右側に表示されたhtmlで「selectorをコピー」を選択してメモ帳に張り付けて調べたり、htmlタグを手繰って調べたりします。
3.リスト項目の取得
次にlistタグのデータはtableタグのデータのようにはいきません。「例を使用してテーブルを追加」を使って項目を選択していきます。
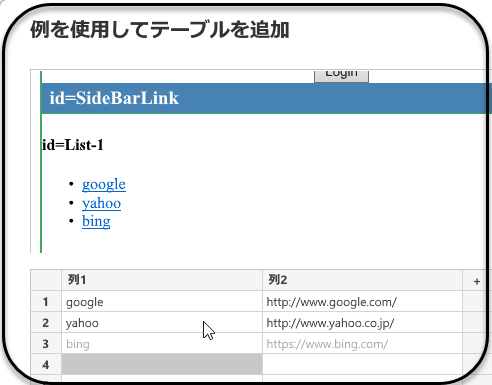

作成されたM式は以下のようになりました。
let
ソース = Web.BrowserContents("https://fukuyori.github.io/RPALT20220117/"),
HTMLから抽出されたテーブル =
Html.Table(
ソース,
{
{"列1", "[id*=""ListItem""]"},
{"列2", "A", each [Attributes][href]?}
},
[RowSelector="[id*=""ListItem""]"]
),
変更された型 =
Table.TransformColumnTypes(
HTMLから抽出されたテーブル,
{
{"列1", type text},
{"列2", type text}
}
)
in
変更された型
最初の表記に合わせれば、以下のように書き換えることもできます。
Html.Table(
ソース,
{
{"列1", "LI"},
{"列2", "A", each [Attributes][href]?}
},
[RowSelector="UL#List-1 > LI"]
),
2列目は、属性hrefの値を取得するため、 each [Attributes][href]? とeachを使った3つ目の記述が付きます。最後についてる ? ですが、属性 href が存在しないとき、通常は戻り値がエラーになってしまうのですが、?があるとnullが返ってきます。
4.コードがすっきり
自動で作成すると、コードがすごいことになったりします。
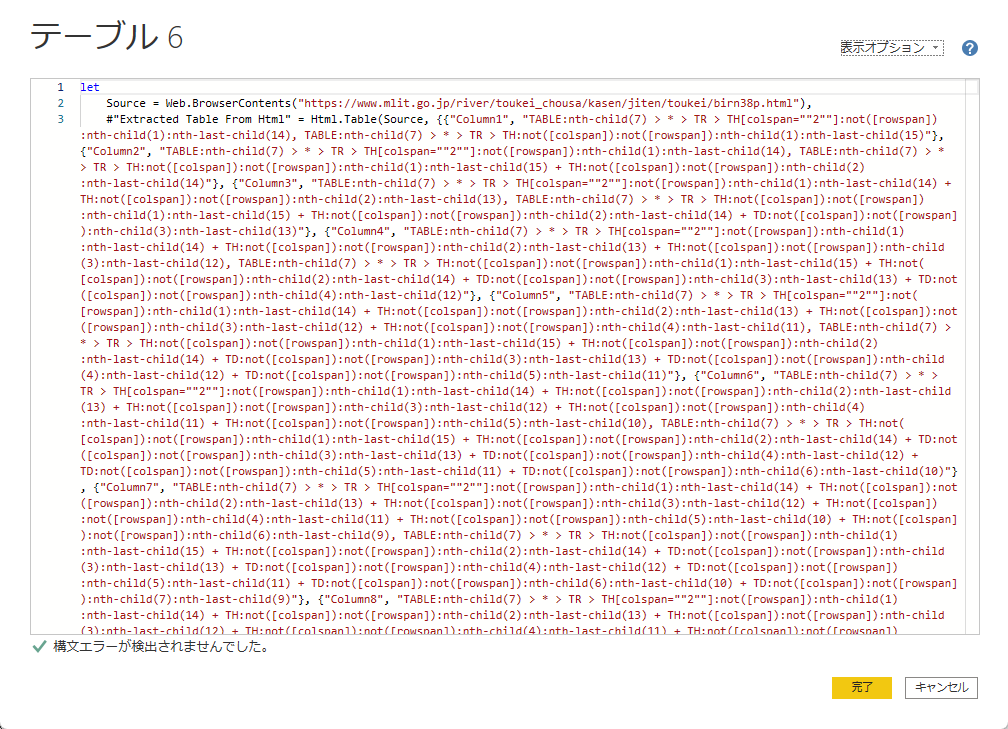
これを手作業で書くと、以下のようにスッキリさせることができます。
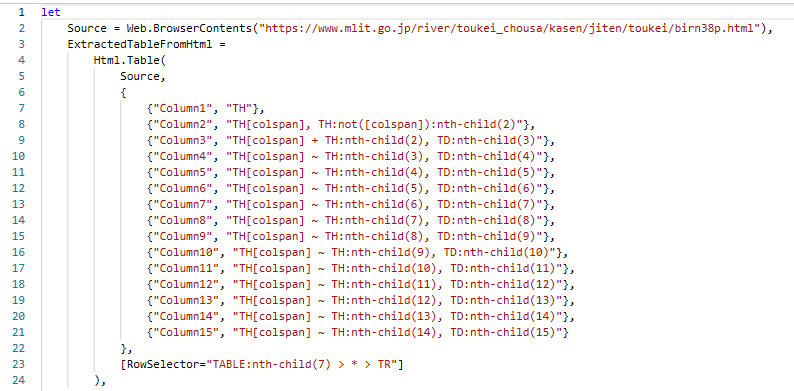
コードをスッキリ書きたくなりませんか?