この章では、Power Queryを使用して複雑なデータ構造を操作するための技術を学びます。特に、ネストされたリストやレコード、階層的なデータ構造の展開、フラット化、集計などの手法に焦点を当てます。また、異なるデータ型が混在するデータや、階層データを操作する際のベストプラクティスについても解説します。これらのスキルを身に付けることで、複雑なデータ構造を効果的に扱い、分析やレポート作成に役立つ形式に変換できるようになります。
3.1. ネストされたリストやレコードの操作
3.1.1 ネストされたデータ
Power Queryでは、リストやレコードなどの構造を持つデータを扱うことができます。
let
t = Table.FromRows(
{
{"Question", "Response1", "Response2", "Response3"},
{"Overall quality?", "High", "Medium", "Low"},
{"Ease of use?", "Good", "Average", "Poor"},
{"Would you recommend?", "Yes", "No", "No"}
}
),
Source = Table.FromRecords(
{
[Survey = "a", Results = t],
[Survey = "b", Results = t],
[Survey = "c", Results = t]
}, type table [ Survey = text, Results = table]
)
in
Source
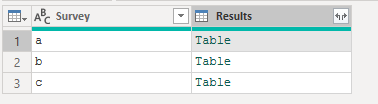
3.1.2 ドリルダウン(Drill Down)
興味のある列名を右クリックし、「ドリルダウン」を選択します。

この操作では、Result列がリストに変換されます。
let
t = Table.FromRows(
{
{"Question", "Response1", "Response2", "Response3"},
{"Overall quality?", "High", "Medium", "Low"},
{"Ease of use?", "Good", "Average", "Poor"},
{"Would you recommend?", "Yes", "No", "No"}
}
),
Source = Table.FromRecords(
{
[Survey = "a", Results = t],
[Survey = "b", Results = t],
[Survey = "c", Results = t]
}, type table [ Survey = text, Results = table]
),
Results = Source[Results]
in
Results
代わりに、興味のあるセルを選択し、右クリックして「ドリルダウン」を選択します。
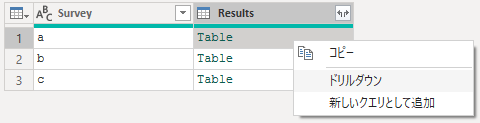
その結果は、セルに入っていたテーブルが表示されます。
let
t = Table.FromRows(
{
{"Question", "Response1", "Response2", "Response3"},
{"Overall quality?", "High", "Medium", "Low"},
{"Ease of use?", "Good", "Average", "Poor"},
{"Would you recommend?", "Yes", "No", "No"}
}
),
Source = Table.FromRecords(
{
[Survey = "a", Results = t],
[Survey = "b", Results = t],
[Survey = "c", Results = t]
}, type table [ Survey = text, Results = table]
),
Results = Source{0}[Results]
in
Results

3.1.2 テーブルの展開(Table.ExpandTableColumn)
列名Resultsの右上にある左右に矢印が分かれるアイコンをクリックすると、a ~ c のセルにあるテーブルの内容が展開されます。

let
t = Table.FromRows(
{
{"Question", "Response1", "Response2", "Response3"},
{"Overall quality?", "High", "Medium", "Low"},
{"Ease of use?", "Good", "Average", "Poor"},
{"Would you recommend?", "Yes", "No", "No"}
}
),
Source = Table.FromRecords(
{
[Survey = "a", Results = t],
[Survey = "b", Results = t],
[Survey = "c", Results = t]
}, type table [ Survey = text, Results = table]
),
#"Expanded {0}" =
Table.ExpandTableColumn(
Source,
"Results",
{"Column1", "Column2", "Column3", "Column4"},
{"Results.Column1", "Results.Column2", "Results.Column3", "Results.Column4"}
)
in
#"Expanded {0}"

3.1.3 リストの展開と操作
Power Queryのリストは、一連のデータの集合を表し、数値、テキスト、レコード、さらには他のリストなど、さまざまな要素を含むことができます。

リストの各要素を別々の行や列に展開する方法を紹介します。例えば、ある列に格納された顧客の注文履歴がリスト形式の場合、そのリストを展開して注文の詳細を個別に表示します。
// リストを含むテーブルの例
let
Source = Table.FromRecords({
[CustomerID = 1, Orders = {101, 102, 103}],
[CustomerID = 2, Orders = {201, 202}],
[CustomerID = 3, Orders = {301, 302, 303, 304}]
}),
// Orders列(リスト)を展開
ExpandedOrders = Table.ExpandListColumn(Source, "Orders")
in
ExpandedOrders

リスト関数の活用
List.Transform、List.Accumulate、List.Countなどのリスト関数を活用してリストを操作し、データの抽出や集計を行うことができます。
// 各顧客の注文数を計算する例
let
Source = Table.FromRecords({
[CustomerID = 1, Orders = {101, 102, 103}],
[CustomerID = 2, Orders = {201, 202}],
[CustomerID = 3, Orders = {301, 302, 303, 304}]
}),
OrderCount =
Table.AddColumn(
Source,
"OrderCount",
each List.Count([Orders]),
Int64.Type
)
in
OrderCount

3.1.4 レコードの展開と操作
レコードは、関連するフィールド(属性)とその値の組み合わせを持つデータ構造です。Excelでの「テーブルの1行」に似た構造です。
レコード内の各フィールドを新しい列として展開する方法を紹介します。たとえば、顧客データの「住所」が1つのレコードに格納されている場合、それを展開して「郵便番号」「都道府県」などの個別フィールドに分けます。
// レコード内の住所フィールドを展開する例
let
Source =
Table.FromRecords(
{
[
CustomerID = 1,
Address = [
PostalCode = "123-4567",
Prefecture = "Tokyo",
City = "Chiyoda"
]
],
[
CustomerID = 2,
Address = [
PostalCode = "234-5678",
Prefecture = "Osaka",
City = "Kita"
]
],
[
CustomerID = 3,
Address = [
PostalCode = "345-6789",
Prefecture = "Fukuoka",
City = "Hakata"
]
]
}),
ExpandedAddress =
Table.ExpandRecordColumn(
Source,
"Address",
{
"PostalCode",
"Prefecture",
"City"
}
)
in
ExpandedAddress


レコード関数の活用
Record.FieldやRecord.ToTableを使って、特定のフィールドを抽出したり、レコードをテーブル形式に変換します。
// 特定のフィールドを抽出する例
let
Source =
[
PostalCode = "123-4567",
Prefecture = "Tokyo",
City = "Chiyoda"
],
Prefecture = Record.Field(Source, "Prefecture")
in
Prefecture
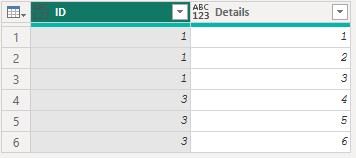
3.1.5 混合型データの処理
列内にリストとレコードが混在する場合、Power Queryでの処理方法が異なります。リストとレコードの判別方法を説明し、それぞれに適した処理手法を紹介します。
// 列内にリストとレコードが混在する場合の処理
let
Source = Table.FromRecords({
[ID = 1, Details = {1, 2, 3}],
[ID = 2, Details = [Name = "Alice", Age = 30]],
[ID = 3, Details = {4, 5, 6}]
}),
ProcessedTable =
Table.AddColumn(
Source,
"Type",
each if Value.Is([Details], type list) then "List" else "Record"
)
in
ProcessedTable

データ型を統一するために、Type.Is関数を使って型を確認し変換します。
// 列内にリストとレコードが混在する場合の処理
let
Source = Table.FromRecords({
[ID = 1, Details = {1, 2, 3}],
[ID = 2, Details = [Name = "Alice", Age = 30]],
[ID = 3, Details = {4, 5, 6}]
}),
// リストのみ抽出し、展開
ProcessedTable =
Table.SelectRows(
Source,
each Value.Is([Details], type list)
),
Result = Table.ExpandListColumn(ProcessedTable, "Details")
in
Result
3.2 複数レベルの階層データの操作
3.2.1 階層データの展開
階層データのフラット化
親子関係を持つデータを操作する際、Path列を作成して、フラットなテーブルにします。
// 階層構造を持つデータの展開例
let
Source = Table.FromRecords({
[EmployeeID = 1, ManagerID = null, Name = "CEO"],
[EmployeeID = 2, ManagerID = 1, Name = "Director"],
[EmployeeID = 3, ManagerID = 2, Name = "Manager"],
[EmployeeID = 4, ManagerID = 3, Name = "Employee"]
}),
Hierarchy =
Table.AddColumn(
Source,
"Path",
each
if [ManagerID] = null
then Text.From([EmployeeID])
else Text.From([ManagerID]) & " -> " & Text.From([EmployeeID])
)
in
Hierarchy

3.2.2 階層データの集計
階層データを累積的に集計する手法を紹介します。たとえば、部門ごとの売上を集計し、上位階層に累積する方法を説明します。
// 部門別売上を集計する例
let
Source = Table.FromRecords({
[Department = "A", Level = 1, Sales = 1000],
[Department = "A1", Level = 2, Sales = 500],
[Department = "A2", Level = 2, Sales = 300],
[Department = "B", Level = 1, Sales = 1200],
[Department = "B1", Level = 2, Sales = 400]
}),
GroupedSales =
Table.Group(
Source,
{"Department"},
{
{
"TotalSales",
each List.Sum([Sales]),
type number
}
}
)
in
GroupedSales

3.3 混合データ型の正規化と標準化
データセット内に異なるデータ型(数値、テキスト、日付など)が混在している場合、データを正規化して標準化することが重要です。
3.3.1. データ型変換のベストプラクティス
Power Queryの「データ型の変更」機能を使用して、データ型を確認し、適切な型に変換することで、誤った変換によるデータ損失を防ぎます。
テキスト型から数値型への変換
テキスト型として保存されている数値データを数値型に変換する手法を紹介します。
// テキスト型の数値データを数値型に変換
let
Source = Table.FromRecords({
[CustomerID = "1", SalesAmount = "1000"],
[CustomerID = "2", SalesAmount = "2000"],
[CustomerID = "3", SalesAmount = "1500"]
}),
ChangedType =
Table.TransformColumnTypes(
Source,
{
{"CustomerID", Text.Type},
{"SalesAmount", Int64.Type}
}
)
in
ChangedType

3.3.2. 日付や数値データの標準化
異なる日付フォーマットが存在する場合、共通のフォーマットに変換して一貫性を持たせます。
下記のデータは、様々な日付形式をDate.FromTextでCultureを指定することで変換しています。
let
Source =
Text.Combine(
{
"ID,Name,Date,DateFormat",
"1,Alice,2024-11-25,ja-JP",
"2,Bob,11/25/2024,en-US",
"3,Charlie,25-11-2024,en-GB",
"4,Diana,""November 25, 2024"",en-US",
"5,Ethan,""2024年11月25日"",ja-JP",
"6,Fiona,25.11.2024,en-GB",
"7,George,20241125,ja-JP",
"8,Hannah,25/11/24,en-GB",
"9,Ian,11/25/24,en-US",
"10,Jenna,""25th November 2024"",en-GB"
},
"#(cr)#(lf)"
),
CsvData = Csv.Document(Source),
#"Promoted Headers" = Table.PromoteHeaders(CsvData, [PromoteAllScalars=true]),
AddColumn =
Table.AddColumn(
#"Promoted Headers",
"Change Type",
each Date.FromText(_[Date], [Culture=_[DateFormat]]),
type date
)
in
AddColumn
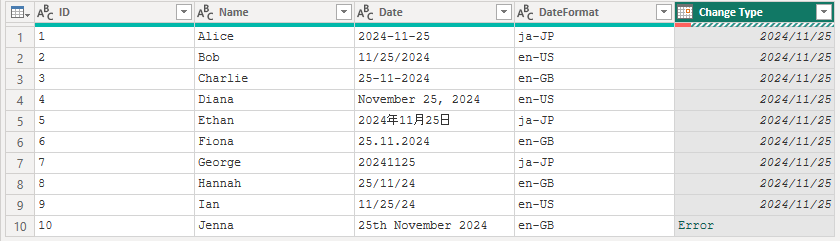
"25th November 2024" のような形式は、日付の部分(25thなど)が通常の数値ではなく英語表記(序数詞: "th" や "st" など)を含むため、標準的な日付解析ライブラリでは直接的に変換できません。th st nd rd の文字を取り除く処理が必要になります。
日付形式とCultureの一覧は、『雑・Excel入門試論 - 脱VLOOKUPの思考 10 - セル - 日付と時刻の書式設定』を参照してください。
3.3.3. テキストデータの標準化と正規化
// 顧客名から前後の不要なスペースを削除
let
Source = Table.FromRecords({
[CustomerID = 1, CustomerName = " Alice "],
[CustomerID = 2, CustomerName = " Bob "]
}),
TrimmedData = Table.TransformColumns(Source, {{"CustomerName", Text.Trim}})
in
TrimmedData

// 数字以外の文字を削除
let
Source = Table.FromRecords({
[CustomerID = 1, CustomerNumber = "0000-1111-2222"],
[CustomerID = 2, CustomerNumber = "3333/4444 5555"]
}),
RemovedData =
Table.TransformColumns(
Source,
{
{
"CustomerNumber",
each Text.Select(_, {"0".."9"})
}
}
)
in
RemovedData

// 顧客データの「氏名」を「姓」と「名」に分割
let
Source = Table.FromRecords(
{
[Number = 1, Name = "Johnson,Alice"], // 間にカンマ
[Number = 2, Name = "斎藤 悟"], // 間に半角スペース
[Number = 3, Name = "三木 宗男"] // 間に全角スペース
},
type table [Number = number, Name = text]
),
#"Split Column by Delimiter" =
Table.SplitColumn(
Source,
"Name",
Splitter.SplitTextByAnyDelimiter(
{",", " ", " "}, // カンマ、半角・全角スペースのいずれかで分割
QuoteStyle.Csv
),
{"姓", "名"}
)
in
#"Split Column by Delimiter"

さらに、Text.Clean や Text.Lower Text.Middle Text.Remove などの関数を使用して文字列を整えることができます。