SPSS Modelerを使って、装置故障分析を行ってみます。
-
稼働確認環境
- Modeler 18.6
- Windows 11
-
データ
- 完成ストリーム
A.データの入力
A1. センサーデータを入力
01過去装置センサーデータ.csvというファイルをModelerのキャンバスにドラッグアンドドロップします。
出力タブからテーブルノードを選択し、ドラッグアンドドロップした01過去装置センサーデータ.csvと接続します。
テーブルノードを選択状態にして、五角形に三角の「選択内容を実行」ボタンで実行します。

装置ID、稼働日数、温度、電力、油塗布のデータが入っています。装置ID毎に各稼働日のセンサーの情報が入っているイメージで、装置が変わると、稼働日はまた0から始まるデータになっています。

確認し終わったら赤い×ボタンで閉じます。
A2. 故障データを入力
同様に02装置故障データ.csvを配置します。

01過去装置センサーデータ.csvとテーブルノードの間のリンクを右クリックで削除します。
02装置故障データ.csvとテーブルノードの間のリンクし、右クリックで実行します。

02装置故障データ.csvには、装置ID、稼働日数、そして故障したかどうかがT/Fのフラグで入っています。

確認し終わったら赤い×ボタンで閉じます。
テーブルノードはここでは一旦、右クリックで削除しておきます。

B.データ加工
B1. データ結合
「レコード設定」タブからレコード結合ノードを選び、キャンバスにドラッグアンドドロップします。
そして、01過去装置センサーデータ.csvと02装置故障データ.csvから接続します。

レコード結合ノードを右クリックして、「編集」を選びます。

「レコード結合」タブで「レコード結合方法」で「キー」を選びます。そして、「装置ID」、「稼働日数」の順に→ボタンで結合キーを設定します。これで「プレビュー」ボタンをクリックしてください。
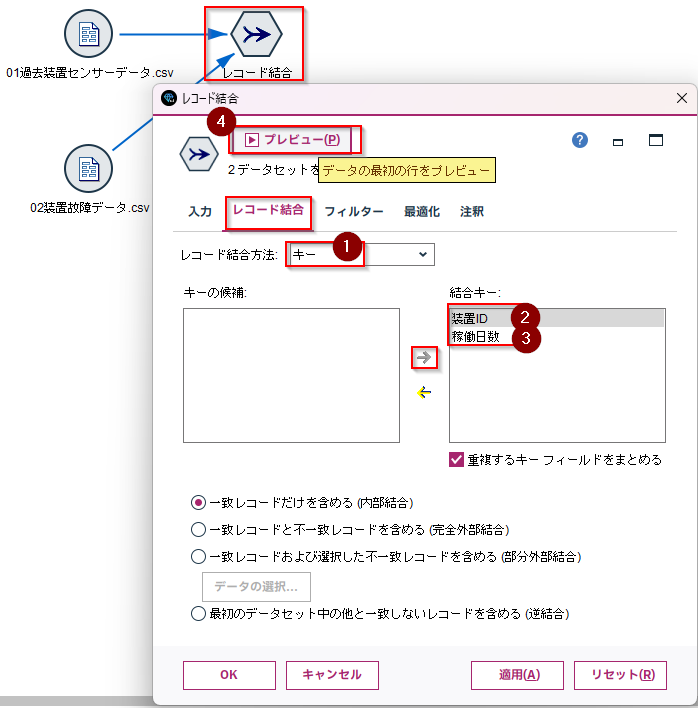
二つのCSVが結合できたことがわかります。

B2. 変数のロール設定
どの変数が説明変数でどの変数が目的変数かを設定します。
「フィールド設定」タブから「データ型」ノードを選び、キャンバスにドラッグアンドドロップします。
そして、「レコード結合」ノードから接続し、右クリックで「編集」を選びます。

「値の読み込み」ボタンを押して、装置IDのロールを「なし」、故障のロールを「対象」に設定します。そして「OK」 で閉じます。

C.データ探索
これで機械学習の準備はできましたが データの中身をあらかじめ確認して前処理やデータの探索をしておきたいと思います。
C1. 欠損値の代入
「出力」タブから「データ検査」ノードを選び、キャンバスにドラッグアンドドロップします。
そして、「データ型」ノードから接続し、右クリックで「実行」をします。

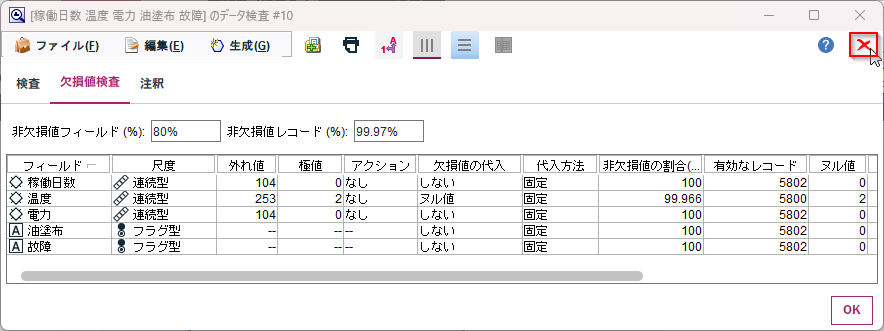
「欠損値」のタブを開きます。外れ値やヌル値などが何件あるかが表示されます。

ここでは「温度」に2件のヌル値がありますので、欠損値の代入を行ってみます。
「温度」の欠損値の代入から「指定…」を選びます。

「代入時」に「ヌル値」を選び、「代入方法」は「固定」のままにして、「固定」値として「平均値」を選びます。

「生成」メニューから「欠損値スーパーノード」を選びます。
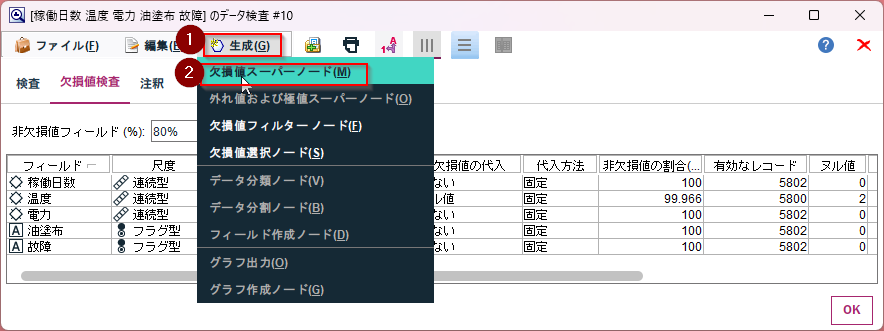
「OK]で進みます。

データ検査ノードを赤い×ボタンで閉じます。
欠損値の代入というスーパーノードができているのでこれを「レコード結合」ノードと「データ型」ノードの間にいれてつなぎなおします。
そして、右クリックで「ズームイン」を選びます。
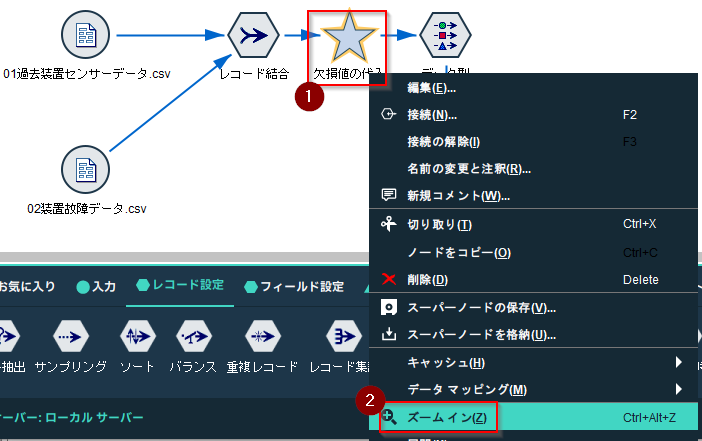
「温度 個の置換」というノードができています。スーパーノードとは複数のノードをまとめるノードです。今回は「温度」のみの欠損値処理を行いましたが、他の変数も処理していれば、このスーパーノードの中に一緒に格納されます。
右クリックで「編集」を選びます。

「温度」を平均値で置換する処理が自動的に作られているのがわかります。
「OK」で閉じます。

ちなみに欠損値の代入には「無作為」や「アルゴリズム」による予測補完メニューもありますし、時系列データの線形補間も可能です。
キャンパスで右クリックして「ズームアウト」を選び、メインのストリームに戻ります。

再度、「データ検査」ノードを右クリックで「実行」をします。

「欠損値」のタブを開くと、「温度」のヌル値が0になったことがわかります。

C2. データの概要の把握
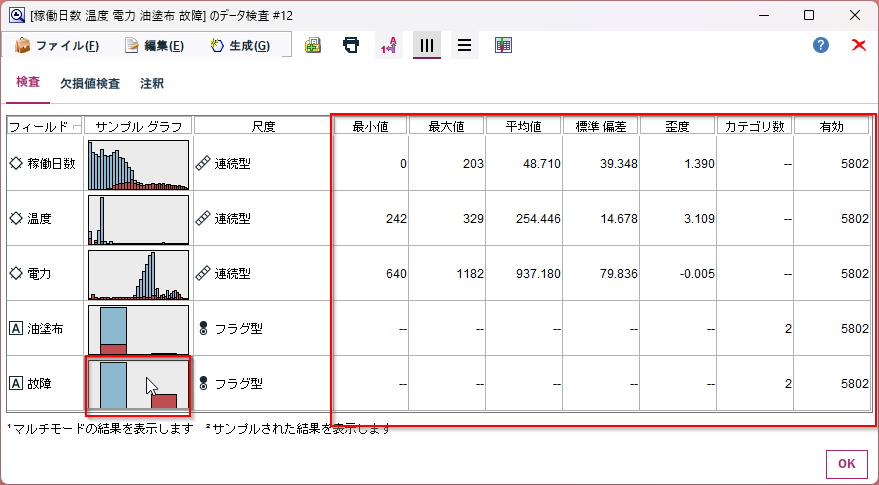
検査タブでは、平均値や最大値などの基本的な統計情報を確認することができます。
またサンプル グラフでは目的変数の「故障」で色分けをしてグラフを作成しています。「故障」のグラフをダブルクリックをしてください。
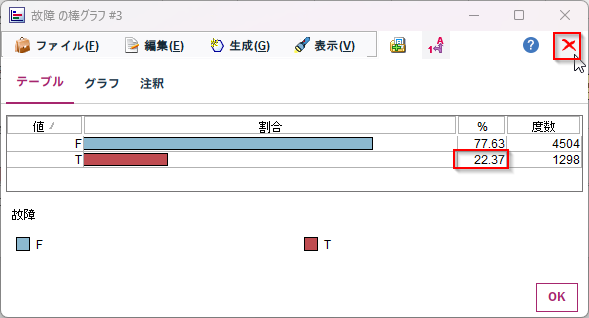
「故障」のグラフが拡大されます。
全体としては22.37%が故障だとわかります。
赤い×ボタンでグラフを閉じます。
以下は「いいえ」で閉じます。

次に「稼働日数」のグラフをダブルクリックして拡大します。
稼働日数が進むと故障の割合が増えていくことがわかります。
赤い×ボタンでグラフを閉じます。

以下は「いいえ」で閉じます。
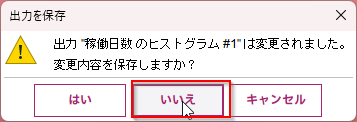
「温度」のグラフをダブルクリックしてみます。温度が低い場合と高い場合に故障が多いように見えます。ここでは高い場合に注目してみます。

詳しく調べてみます。
表示メニューからインタラクティブをチェックします。

ちなみに懐中電灯のアイコンしか見えず、表示メニューが隠れていることがあります。この場合は、グラフのウィンドウを広げると、メニュー名が出てきます(もしくは懐中電灯のアイコンをクリックしてもよいです)。

赤い縦棒のアイコンをクリックして、260度よりちょっと下の位置でクリックをします。
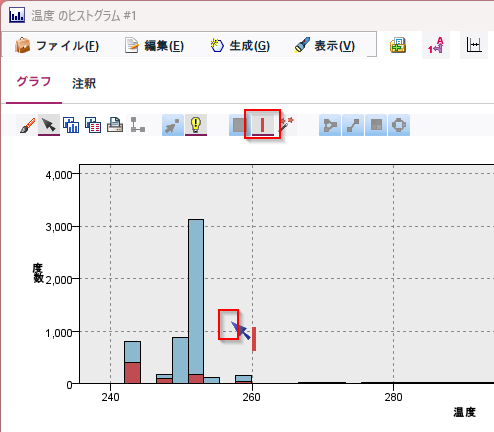
以下のように赤い区切り線がひかれました。

ここで、「生成」メニューから「バンドのフィールド作成ノード」を選びます。

赤い×ボタンでグラフを閉じます。
以下は「いいえ」で閉じます。

データ検査ノードを赤い×ボタンで閉じます。

「バンド」というフィールド作成ノードができています。

データ型ノードに、この「バンド」というノードをつなぎ、右クリックで「編集」を選びます。
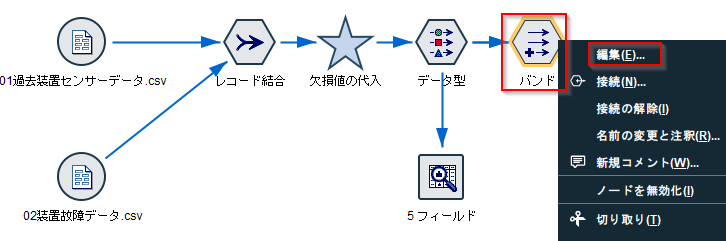
先ほどヒストグラムで引いた赤い区切り線の位置で「バンド1」と「バンド2」を分けるフラグが作られています。このようにグラフをみながらコーディングなしに、処理を作る事ができます。
ここではこの後の動きを合わせるために値の設定条件を温度 < 255に書き換えて、「OK」で閉じてください。

さらに「テーブル」ノードを接続し、右クリックで「実行」します。
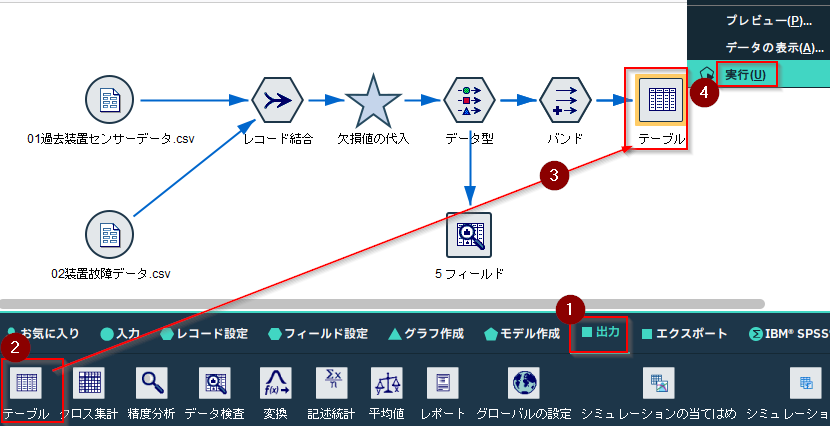
温度が高い状態に絞り込みたいので、209行目の「バンド2」クリックして選択します。またここでは、分析上は意味がないのですが、複数の条件を指定できることを体験いただくために、別の行である200行目の油塗布の「F」をCTRLを押しながら選択します。そして、「生成」メニューから「条件抽出ノード(AND)」を選びます。
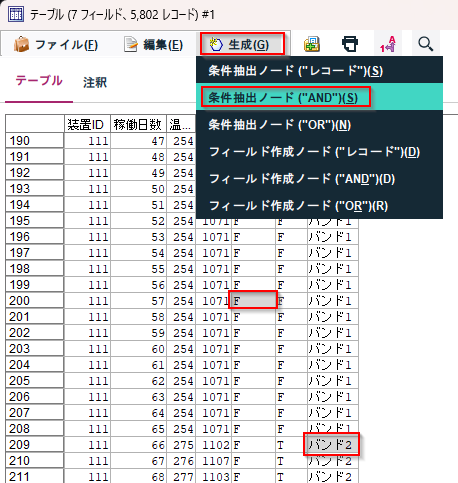
「(生成)」という条件抽出ノードがキャンバスにできていますので、「バンド」ノードに接続して、「編集」を選択します。

テーブルノードで選んだ項目がバンド = "バンド2" and 油塗布 = "F"という条件式になって自動的に設定されています。
このようにデータの中から抽出したい項目を選べば、処理を作る事ができます。異なるレコードからも組合せを選べるので、画面に表示されていないレコードのパターンの条件式も作れます。
「OK」で閉じてください。
「グラフ作成」タブの中から 「棒グラフ」を選び、 「(生成)」のノードに接続をします。そして右クリックで「編集」をします

「フィールド」に「故障」を選び、「実行」します。

温度が255度以上で、かつ油塗布 = "F"という条件では故障の割合が「79.79%」となっています。全体では2割程度が故障でしたので、温度が255度以上で、かつ油塗布 = "F"という条件だと、かなり故障率が高まることがわかります。

D.決定木モデル作成
ここまでで、データの前準備や探索を行ってきました。次に機械学習のモデルを作っていきたいと思います。人間にも理解しやすく、予測だけではなく原因分析にも便利な決定木のモデルを作っていきます。
D1. データの分割
データを学習データとテストデータに分けていきます。過学習を避けるために、モデルの作成には学習データのみを使い、テストデータは評価のために使います。
「フィールド設定」タブから「データ区分」ノードを選び、キャンバスにドラッグアンドドロップします。
そして、「データ型」ノードから接続し、右クリックで「編集」を選びます。

学習データとテストデータのサイズを80:20で入力して、「OK」で閉じます。

D2. 決定木モデル作成
「モデル作成」タブから「CHAID」ノードを選び(右の方にスクロールすると見つかります)、キャンバスにドラッグアンドドロップします。
そして、「データ区分」ノードから接続し、右クリックで「実行」します。

CHAIDの黄色のアイコンのモデルナゲットが自動的に生成されます。右クリックで「編集」を選びます。

ビューアータブを開き、「度数情報を表とグラフで表示」のアイコンをクリックして決定木を表示します。
全体では故障は③22.019%です。それを④稼働日数で分けています。稼働日数が進むごとに赤いグラフが大きくなって、故障の割合が大きくなっていることがわかります。
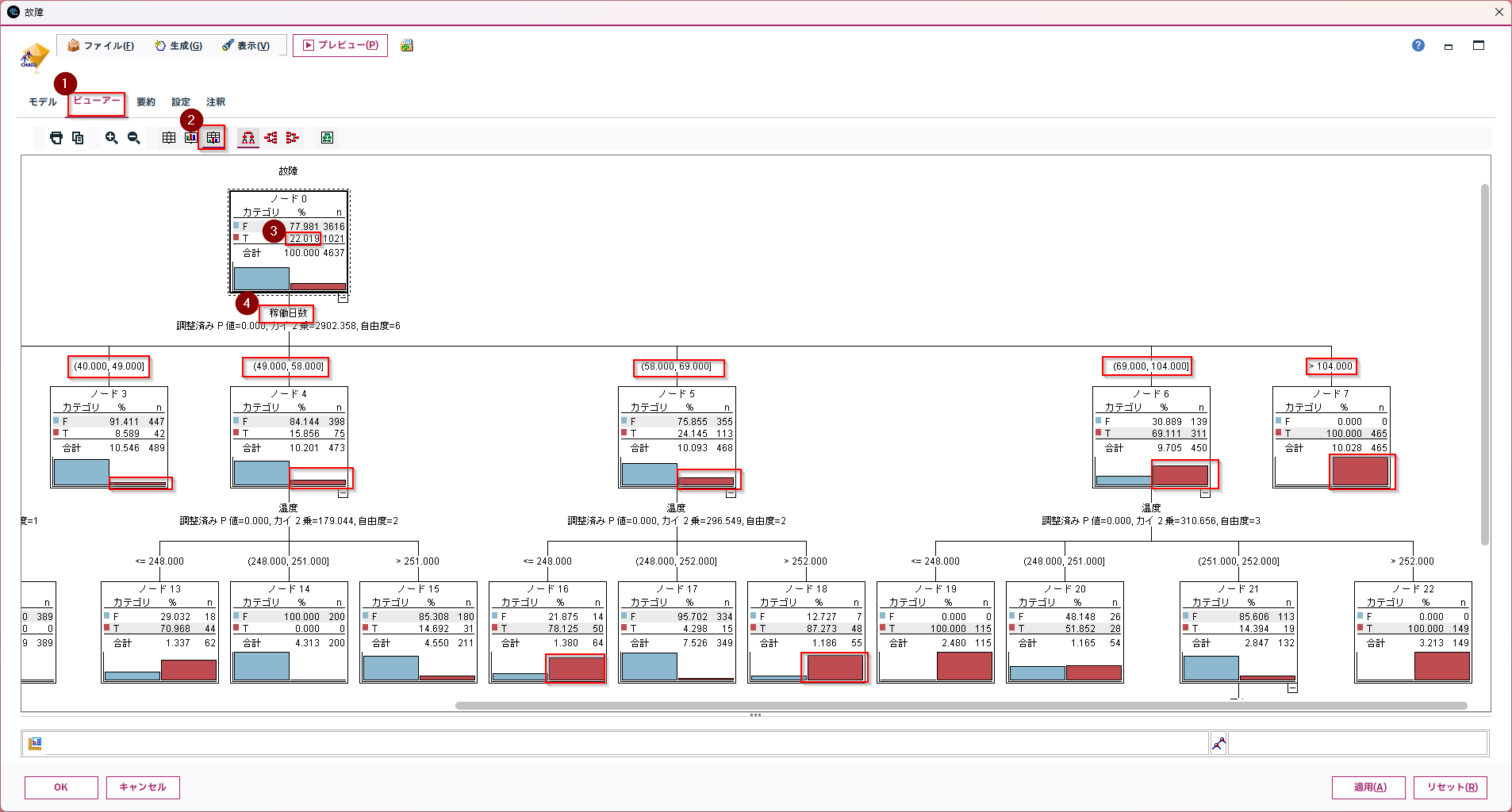
「稼働日数」が①58日から69日の間の故障率は②24.145%ですが、「温度」が③248度以下の場合と④252度より大きい場合、故障率が高いことがわかります。

このように複数要因の条件で、問題のルールが見えてくるので、要因分析には決定木が便利です。
また、CHAIDは多分岐の決定木です。同じ説明変数が条件を変えて何度も出てくるCARTのような2分岐の決定木アルゴリズム(例:稼働日数>49 AND 稼働日数>58のように何度も「稼働日数」の条件がでてくる)よりも理解しやすい特徴があります。
D2. モデルの精度確認
「出力」タブから「データ検査」ノードを選び、キャンバスにドラッグアンドドロップします。
そして、「CHAID」のモデルナゲットから接続し、右クリックで「編集」を選びます。

「一致行列」にチェックをつけて、「実行」します。

テストデータに対して94.85%の精度だったことがわかります。
赤い×ボタンで閉じます。

E. スコアリング
良いモデルができたので、新しいセンサーデータをこのモデルでスコアリングを実行して、将来のエラーを判定してみます。
E1. 装置ID1000のスコアリング
新しいセンサーデータの入っている03新規装置センサーデータ1000.csvをファイルから選び、キャンバスに置きます。
そして右クリックしプレビューで中身を確認します。
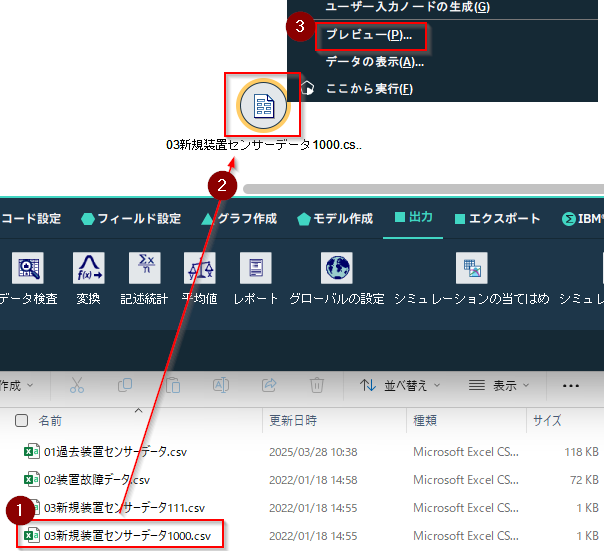
このファイルには装置ID1000のセンサーのデータだけがあります。「故障」の列はありません。
赤い×ボタンで閉じます。

このデータから「故障」を予測してみます。
モデルナゲットを右クリックしてコピーします。

キャンバスの何もないところで右クリックして、貼り付けします。

貼り付けたモデルナゲットに03新規装置センサーデータ1000.csvから接続します。
さらに出力タブからテーブルノードを選び、キャンバスにドラッグアンドドロップします。
そして、モデルナゲットノードと接続します。
それからテーブルノードを右クリックして、「実行」します。
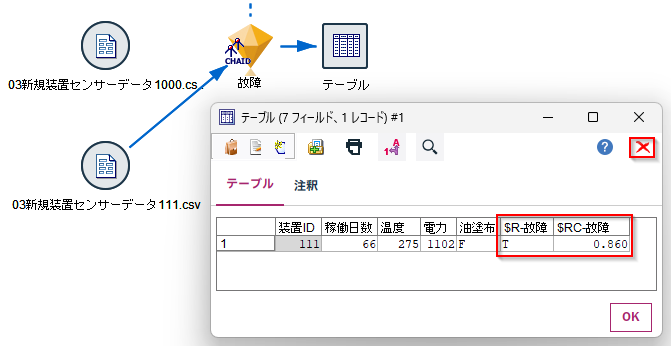
新たに$R-故障と$RC-故障の列が追加されています。
$R-故障が予測結果です。$RC-故障がその確度を示しています。$R-故障がFなので、この装置ID1000は故障しないと予測し、その確度は9割以上であると予測をしています。

E2. 装置ID111のスコアリング
別の装置のセンサーデータの入っている03新規装置センサーデータ111.csvをファイルから選び、キャンバスに置きます。そして右クリックしプレビューで中身を確認します。
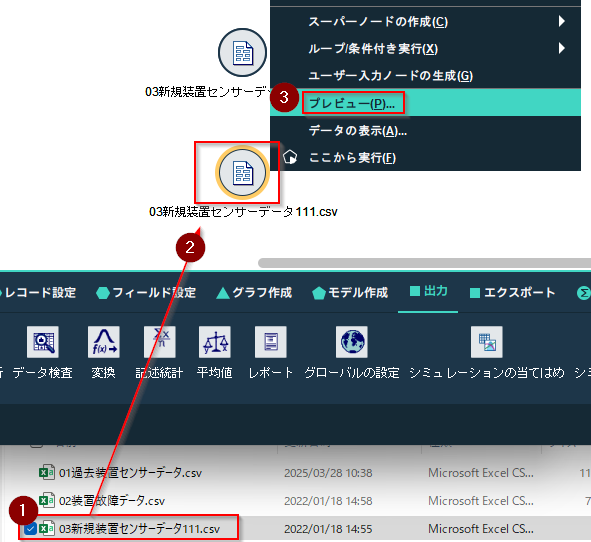
このファイルには装置ID111のセンサーのデータだけがあります。
赤い×ボタンで閉じます。

03新規装置センサーデータ1000.csvからのモデルナゲットへのリンクをはずし、03新規装置センサーデータ111.csvからモデルナゲットに接続しなおします。
それからテーブルノードを右クリックして、「実行」します。

この装置ID111は故障すると予測し、その確度は8割以上であると予測をしています。
どういうルールで故障すると予測したのかを調べてみます。
モデルナゲットを右クリックして「編集」を選びます。
設定タブで「ルール識別子」にチェックをいれ、「プレビュー」します。

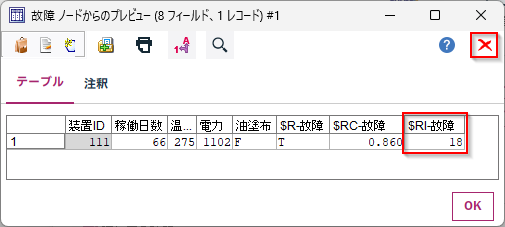
新たに$RI-故障の列が追加されています。この「18」が決定木内のリーフIDを示しています。
赤い×ボタンで閉じます。
ビューアータブを開き、「度数情報を表とグラフで表示」のアイコンをクリックして決定木を表示します。
③がノード18です。このリーフをルートからたどると、④「稼働日数」が58日から69日の間で、⑤「温度」が④252度より大きいので、⑥故障率8割以上と判定したことがわかります。
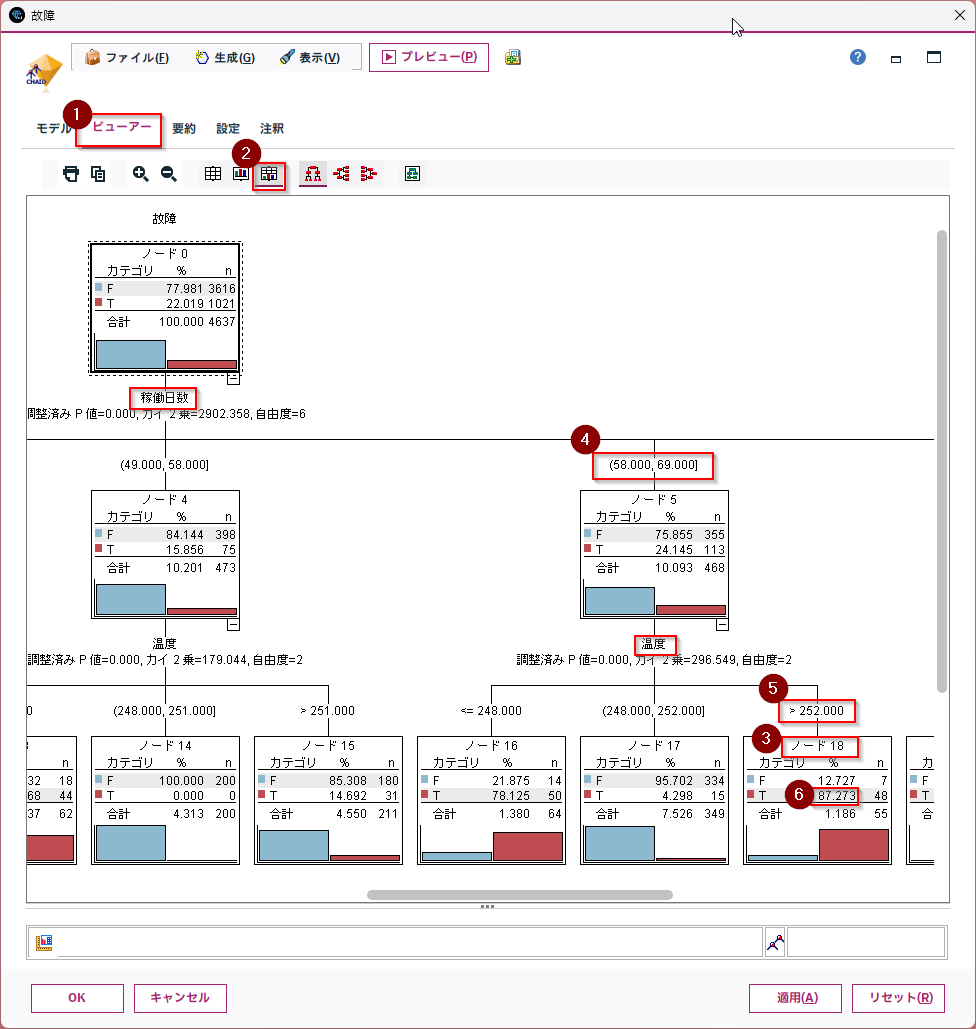
このように判別の根拠を調べることができます。
参考
SPSS Modelerによる製造系データの分析ハンズオン・コンテンツへのリンク #SPSS_Modeler - Qiita