SPSS Modelerで時系列データをつかった故障分析を行います。
以前公開したSPSS Modelerで故障予知では、あらかじめ時系列データを予測用に加工していました。今回はすこしレベルアップして以下の2本の記事に分けて、未加工の時系列のデータから故障分析をしてみたいと思います。
①試行錯誤をしながらデータ探索(本記事)
②時系列データを加工しながら、故障予知
この記事は①を行っていきます。
ノードがどのパレットにあるかなどの説明は省きます。
稼働確認環境
Modeler 18.2.1
Windows 10 64bit
利用データと完成ストリーム
以下からダウンロードしてください。
https://github.com/hkwd/200414FailureAnalysisWithTimeSeries/archive/master.zip
データ:Cond4n_e.csv
完成ストリーム:05explore_machineerr.str
データの読み込み
ドラッグアンドドロップでCond4n_e.csvをキャンバスに置き、「テーブル」ノードを接続し「実行」してみます。

以下のようなデータが表示されます。各列の意味は以下です。
M_CD: マシンコード
UP_TIIME: 起動時間
POWER: 電力
TEMP: 温度
ERR_CD: エラーコード

M_CDとERR_CDが右寄せになっており数値データとして扱われていますが、これはコードなので文字型のデータであるべきです。
テーブルを赤い×ボタンで閉じます。

「Cond4n_e.csv」のノードをダブルクリックし、可変長インプットノードのプロパティを開き、「データ」のタブを開き、M_CDとERR_CDの「上書き」にチェックをつけ、「ストーレジ」を整数から文字型に変更します。変更ができたら「プレビュー」をクリックしてください
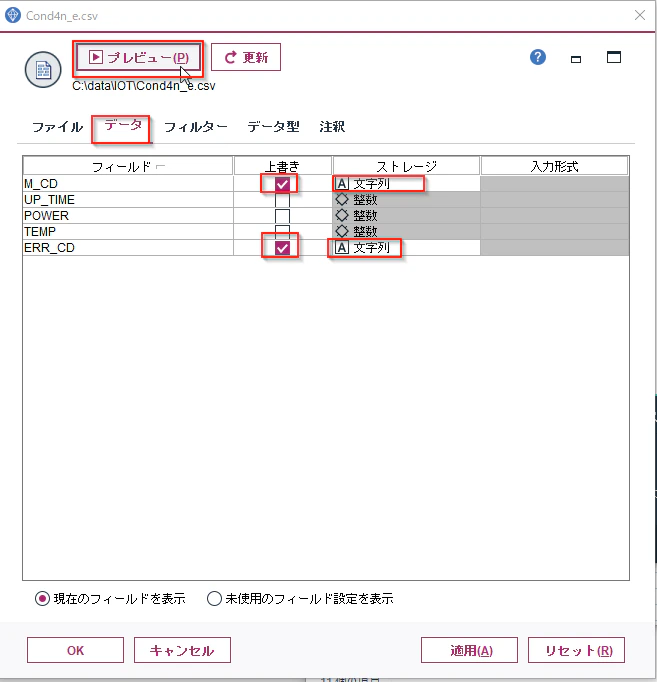
M_CDとERR_CDが左寄せになりました。
プレビューは赤い×ボタンで閉じてください。

「Cond4n_e.csv」のノードのプロパティは「OK」で閉じてください。

データの探索
ここからはデータにどんな傾向があるかを確認してみます。
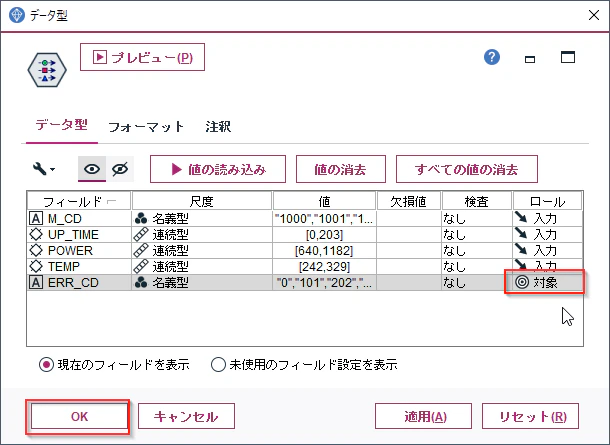
「Cond4n_e.csv」のノードに「データ型」ノードをつないで、ダブルクリックしてプロパティを開き、「値の読み込み」ボタンをクリックしてください。

CSVのデータを読んで、尺度や値の範囲が認識されます。
ロールでERR_CDを「対象」として設定します。これは目的変数(ラベル)を設定しています。
設定が終わったら「OK」で閉じます。
「データの検査」ノードを接続し、実行します。
データの要約を表示してくれます。
カテゴリ数をみるとM_CDが70なので、70台のマシンのデータがあることがわかります、ERR_CDをみると4なので、エラーのパターンは4つあることがわかります。
次にERR_CDのグラフをダブルクリックしてください。

エラーコード0が79%ですので、これが正常データだと推測できます。そして101,202,303のエラーがそれぞれ数パーセント発生していることがわかります。

確認ができたら、赤い×ボタンで閉じてください。
以下の保存ダイアログは「いいえ」で閉じてください。
データ検査ノードの結果に再度戻ります。
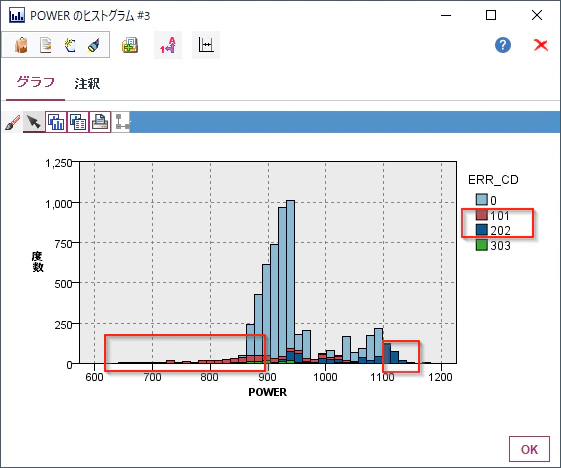
平均をみると電力が941ワットだったり、温度が254度だということがわかります。POWERのグラフをダブルクリックして拡大して下さい。

電力が低いときに101が起きやすく、逆に高いときに202がおきていることがわかります。
確認ができたら、赤い×ボタンで閉じてください。
保存ダイアログは「いいえ」で閉じてください。
「欠損値検査」のタブに移ると各列の外れ値の数や欠損値の数を調べることができます。今回のデータには欠損値はありませんでした。

確認ができたら、赤い×ボタンで閉じてください。
もう少しデータを探索してみます。
「散布図」ノードを接続して、ダブルクリックしてプロパティを開いてください。

以下のように設定をして実行してください。

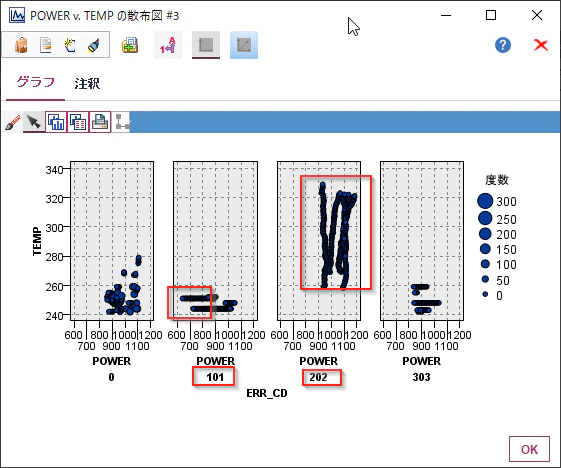
エラーコードと電力と温度の関係がグラフ化されます。
これをみると101は電力が低いときにおこりやすく、202は電力も温度も高いときにおこっていることがわかります。
確認ができたら、赤い×ボタンで閉じてください。
保存ダイアログは「いいえ」で閉じてください。
次に散布図をもう一つ接続して、ダブルクリックしてプロパティを開きます。

以下のように設定をして実行してください。
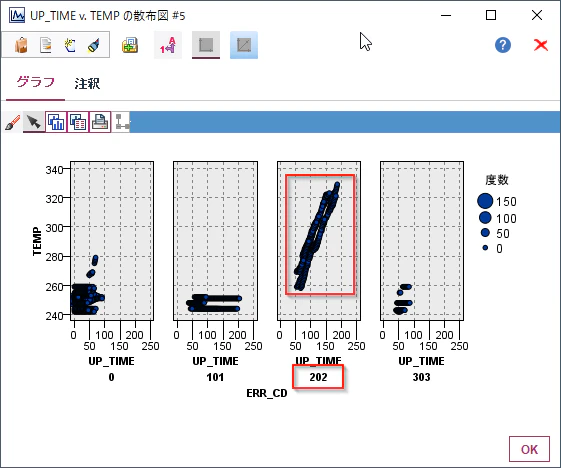
エラーコード毎の経過時間と温度の関係がわかります。
202のエラーは時間経過とともに温度が上がっていることがわかります。
モデルの作成
ここまでで電力や温度が高かったり低かったり、またその組み合わせによってエラーが起きそうであるることが分かりました。
ここでは機械学習のアルゴリズムをつかって、これらのエラーコードの発生分類を行ってみます。
「CHAID」という決定木のモデル作成ノードを「データ型」ノードと接続して、実行してください。

自動生成されたモデル「ERR_CD」をダブルクリックしてください。
予測変数の重要度が表示されています。
ERR_CDを分類するためにはTEMPが最も重要であることがわかります。
また、UP_TIMEやM_CDも次いで重要です。

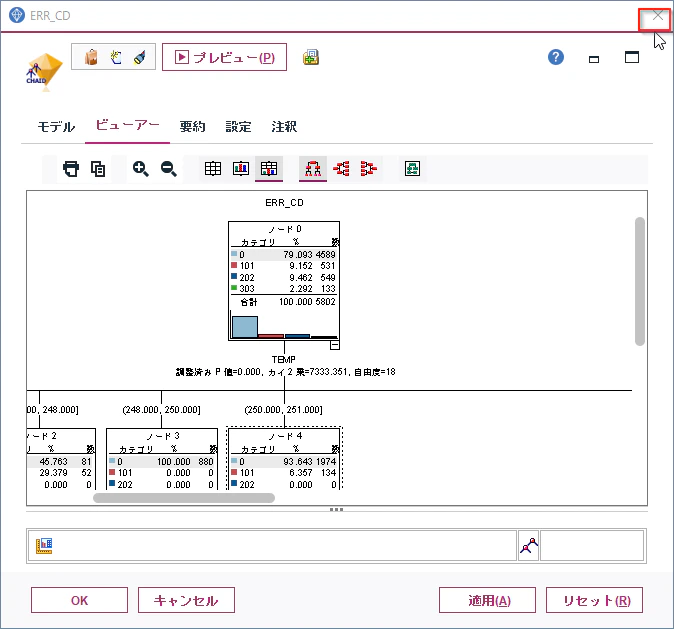
次に「ビューアー」タブに移って、「度数情報を表とグラフで表示」をクリックしてください。
「CHAID」のアルゴリズムはこのようなツリーでモデルの情報を表現します。
これをみると101のエラーは全体では9%しか発生しませんが、TEMPが244度以下、かつUP_TIMEが69時間以上だと98%の確率で発生していることがわかります。

もう一つ別のルールを見てみます。
このルールではTEMPが251度から252度の間でMC_CDが284だと41%の確率で101が発生しています。

このように決定木では、人間がある程度理解できる形で分析ができます。
ですので、ルールの意味を考えてみることができます。
例えば、M_CDはマシンのIDであり、それ自身は本来的には意味はないはずで、予測には使ってはいけないかもしれません。一方で問題の発生しやすいマシンのIDがあるとしたら、その設置状況の気温などに別の要因の影響を受けているかもしれません。そういう場合はマシンの設置場所の気温を説明変数に加えることを検討すべきかもしれません。
また、もしかするとこのデータは、エラーが発生する40時間前から切り出されたデータであって、実際にはもっと長い時間運用されているのかもしれません。その場合UP_TIMEも使うべきではないかもしれません。
このような事情はデータからだけではわからないこともあります。業務の担当者と話をして、本当にこれらのデータに意味があるのか、それとも使うべきでないのかを業務の観点から判断してもらう必要があります。
SPSS ModelerではこのようにわかりやすいGUIで分析の結果を表示するので、業務担当者にも直感的に理解してもらいやすいことが特徴です。
では、ここではM_CDとUP_TIMEはエラーコードの分類には使うべきではないという想定でモデルを作り直してみます。
黒い×ボタンを押してモデルの表示を閉じてください。
データ型ノードをダブルクリックして、プロパティを開きます。
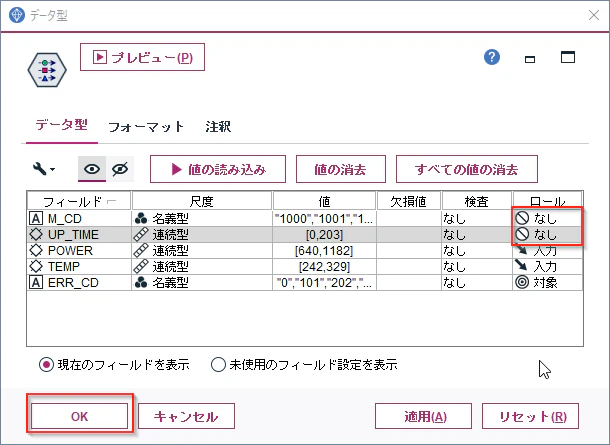
「M_CD」と「UP_TIME」のロールを「なし」に設定します。これはM_CDとUP_TIMEは分類の説明変数に使わないという意味になります。
「OK」をクリックして閉じます。
モデルを作成しなおします。
「CHAID」ノードで右クリックして実行します。
再作成された「ERR_CD」のモデルナゲットをダブルクリックして開きます。

M_CDやUP_TIMEを用いずにTEMPとPOWERだけでモデルが作成されています。

次に「ビューアー」タブに移って、「度数情報を表とグラフで表示」をクリックしてください。
TEMPが244度以下、かつPOWERが879ワット以下だと93%の確率で101のエラーが発生しています。

このように非常に簡単にモデルを作成しなおせることで、いろいろな試行錯誤を行うことができます。この程度の操作であれば、業務担当者の目の前で一緒にその変化を確認してもらうこともできます。
なお、現場の業務担当者の方は温度と電力が低いときに101のエラーが起きやすいことが知っているかもしれません。しかしモデルをつくることによって、具体的に何度以下、何ワット以下の時に何パーセント起きているということがわかります。既存の業務知識を定量化することができるのです。
次回故障の予知に向けて
ここまで時系列データをつかってデータを探索し、エラーコードの分類モデルを作り、どういうときにどのエラーが発生するのかを調査してみました。
しかし故障の”予知”をしようとするときに、このモデルは実はあまり役に立ちません。なぜでしょうか?
データを見て考えてみましょう。
レコード設定タブから条件抽出ノードを「ERR_CD」のモデルナゲットに接続して、ダブルクリックしてプロパティを開きます。

エラーが発生しているマシンのM_CD = '104'の条件を設定しOKで閉じます。

「テーブル」ノードを接続し、実行してください。
このデータをみて、なぜこのモデルが故障の”予知”にはあまり役に立たないかを考えてみてください。
$R-ERR_CDがモデルによって判別されたエラーコードを示しています。ヒントは以下のような予測と実績の比較をしてみるとわかってきます。
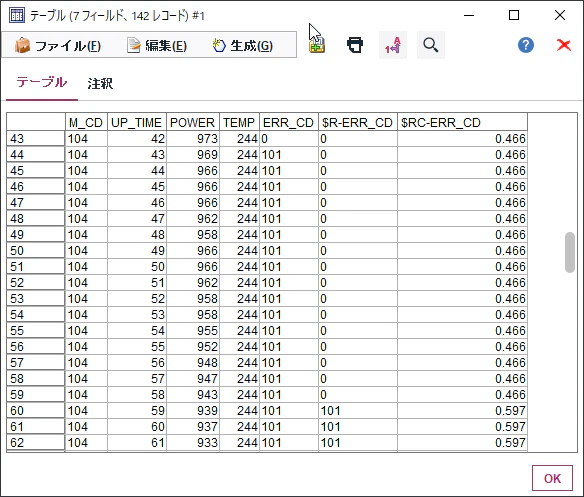
「なぜか」の答えは、次回の故障予知の回にお話しします。
参考:SPSS Modelerによる製造系データの分析ハンズオン・コンテンツへのリンク - Qiita