SPSS Modelerで時系列データをつかった故障予知を行います。
以前公開したSPSS Modelerで故障予知では、あらかじめ時系列データを予測用に加工していました。今回はすこしレベルアップして以下の2本の記事に分けて、未加工の時系列のデータから故障分析をしてみたいと思います。
①試行錯誤をしながらデータ探索
②時系列データを加工しながら、故障予知(本記事)
この記事は②を行っていきます。
ノードがどのパレットにあるかなどの説明は省きます。
実行環境
Modeler 18.2.1
Windows 10 64bit
利用データと完成ストリーム
以下からダウンロードしてください。
https://github.com/hkwd/200414FailureAnalysisWithTimeSeries/archive/master.zip
学習データ:Cond4n_e.csv
スコアリングデータ:Cond4n_e104.csv
参照ストリーム:05explore_machineerr.str
完成ストリーム:04transform_machineerr5.str
データの読み込み
ドラッグアンドドロップでCond4n_e.csvをキャンバスに置き、Cond4n_e.csvのノードをダブルクリックし、可変長インプットノードのプロパティを開き、データのタブを開き、M_CDとERR_CDの「上書き」にチェックをつけ、「ストーレジ」を整数から文字型に変更します。
Cond4n_e.csvのノードのプロパティは「OK」で閉じてください。
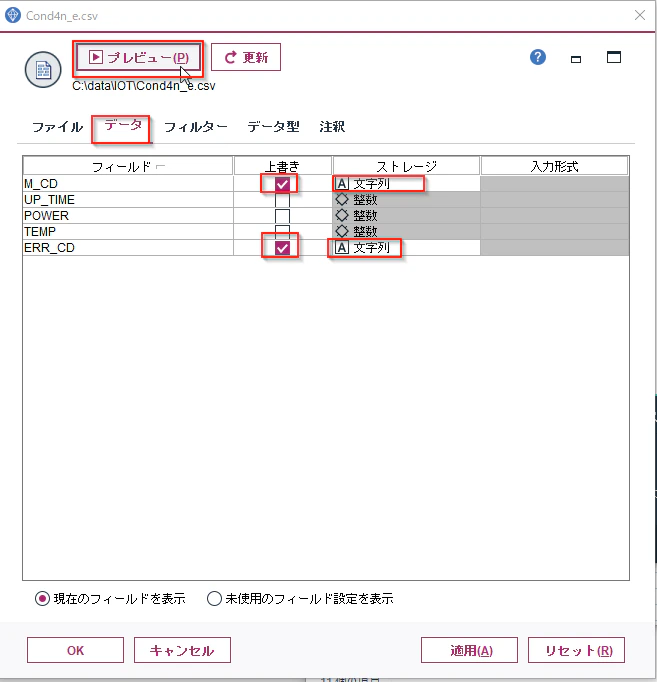
テーブル」ノードを接続し「実行」してみます。

以下のようなデータが表示されます。各列の意味は以下でした。
M_CD: マシンコード
UP_TIIME: 起動時間
POWER: 電力
TEMP: 温度
ERR_CD: エラーコード
M_CDとERR_CDは左寄せの文字型で表示されています。

データのソート
もう一度テーブルノードを実行してみます。
少し下までスクロールしてみると85行目でM_CDが変わり、UP_TIMEが0になっていることがわかります。
各マシンの毎にPOWER、TEMP、ERR_CDが時系列に入っているデータということです。

時系列データの加工をする場合には時系列が正しく並んでいる必要があります。このデータは正しくソートされていそうですが、念のためM_CD、UP_TIMEでソートをします。
ソートノードを接続し、ダブルクリックしてプロパティを開きます。

「理想可能なフィールドの設定から取得」ボタンでM_CD、UP_TIMEの列を選択し、昇順になっていることを確認し、「OK」で閉じます。

目的変数(ラベル)の作成
前回①試行錯誤をしながらデータ探索の最後にERR_CDを目的変数にモデルをつくるだけだと予測にはあまり使えないという話をしました。
前回作成した05explore_machineerr.strを開いて、モデルのM_CD=104の出力結果を見てみます。
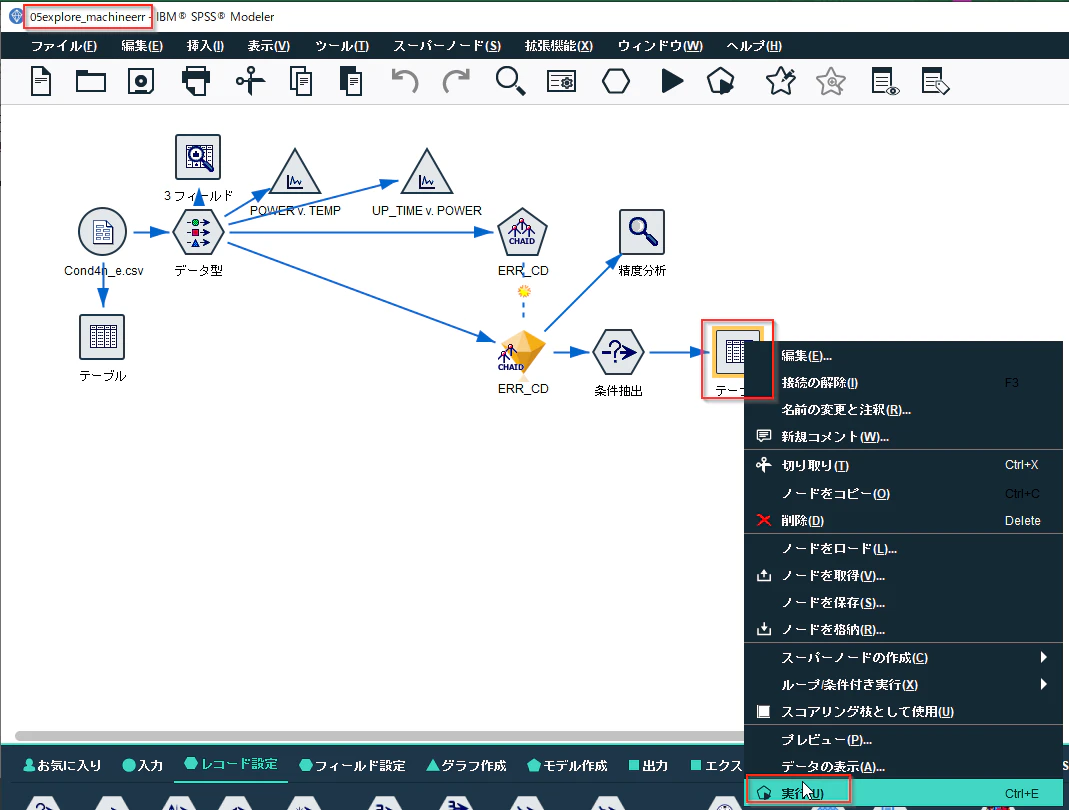

このデータを見るとM_CD=104のマシンは43時間目で101のエラーが発生しています。しかしモデル($R-ERR_CD列)が101のエラーを判別できたのは59時間目です。
故障を予知するということは、モデルは実際の発生よりも前にエラーが発生することを予測しなければ意味がありません。
事前に予測ができれば、点検や部品交換などをおこなってエラーを回避することができれるかもしれません。では何時間前に予測できれば良いのでしょうか?
これはデータを見るだけではわかりません。業務担当者と話をして何時間前に予測ができれば対処が可能かを話して決めることになります。
ここでは5時間前にわかればよいと想定して分析を進めます。
05explore_machineerr.strは閉じて、先ほど作成していたストリームに戻ってください。
5時間前にエラーが発生することを予測するためにはどうすればよいでしょうか?
それには5時間後のエラーコードを目的変数にするという方法があります。この変数は元データにはないので新たに生成します。
フィールド作成ノードを接続し、ダブルクリックしてプロパティを開きます。

「派生フィールド」名に「ERR_CD_5FUTURE」という名前を指定します。
そして「派生」で「条件付き」を選択します。

そして
IF: M_CD = @OFFSET(M_CD,-5)
Then: @OFFSET(ERR_CD,-5)
Else: undef
を設定します。
@OFFSETという関数は現在処理している行の前や後の行を参照するという関数です。
M_CD が5行先と同じ場合に5行先のERR_CDを設定する、M_CD が5行先と違う場合はNULL(undef)を設定するという意味です。
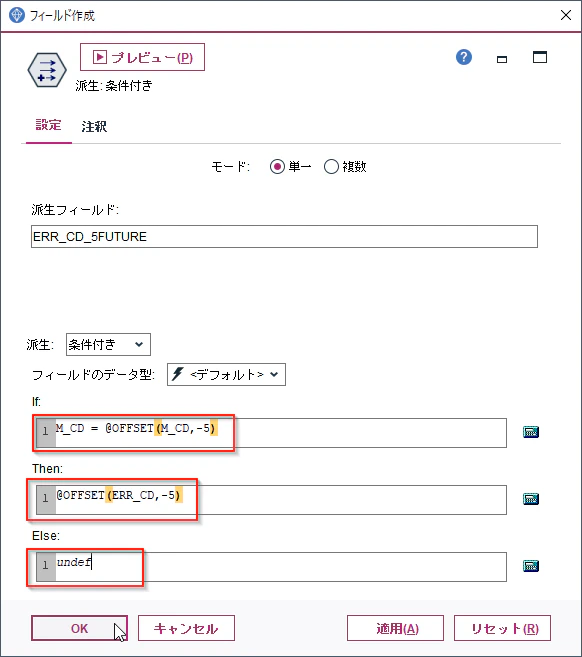
OKで閉じてください。
少し難しいのでデータを見てみましょう。
101のエラーの発生しているM_CD=104のデータを見てみましょう。
レコード設定タブから、条件抽出ノードを接続し、M_CD='104'を入力し、OKで閉じてください。
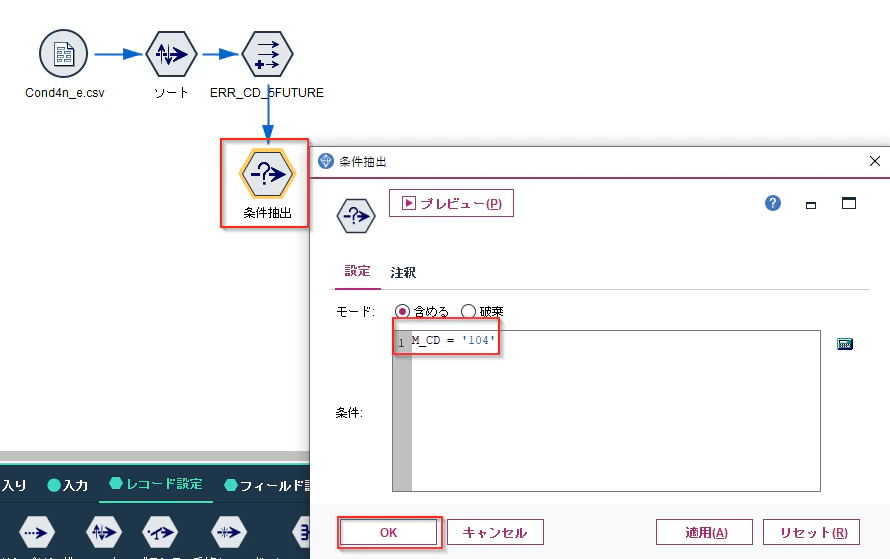
「テーブル」ノードを接続し実行してください。
43時間目に101のエラーが発生していますが、新しく生成したERR_CD_5FUTUREには38時間目から101のデータが入っています。@OFFSETを使うことで5行後ろのデータを持ってきたのです。
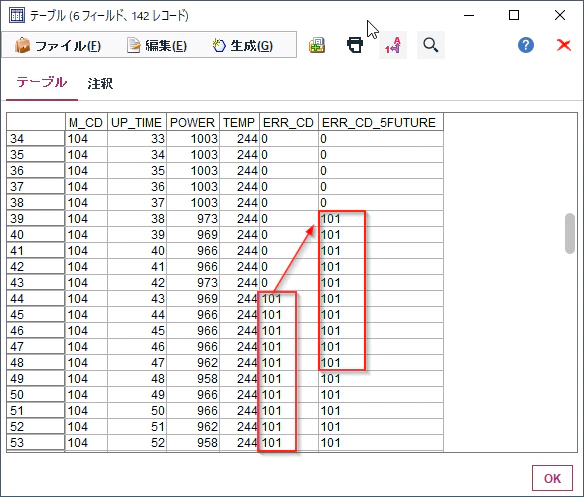
次に一番下までスクロールしてください。ERR_CD_5FUTUREの最後の5行は$null$になっています。これは5時間先のエラーコードのデータがそもそも存在しないということです。
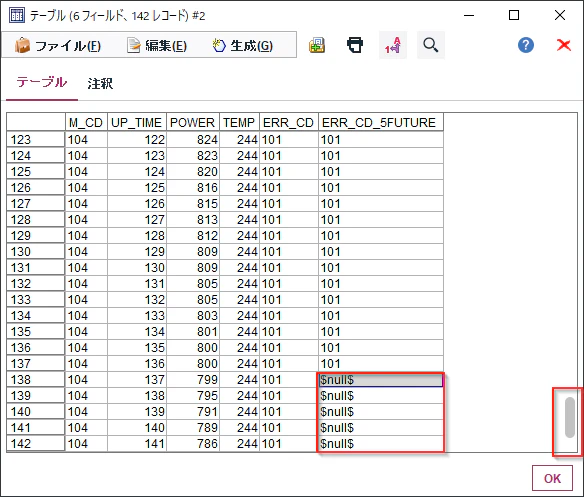
これらのデータは予測には使えませんので削除します。
ERR_CD_5FUTUREが$null$のセルを選び、「生成」のメニューから「条件抽出ノード(AND)」を選び、テーブルノードは赤い×ボタンで閉じてください。

キャンバスの左上に自動生成された条件抽出ノードがありますので、ダブルクリックしてプロパティを開きます。
以下のように自動的にERR_CD_5FUTUREが$null$のレコードを見つける条件が生成されています。

「モード」を「破棄」にします。ERR_CD_5FUTUREが$null$のレコードを破棄するという意味になります。
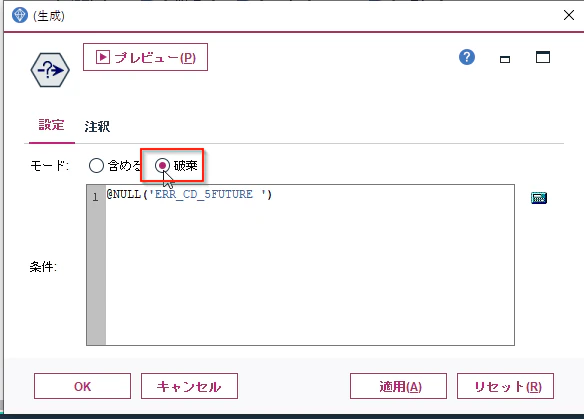
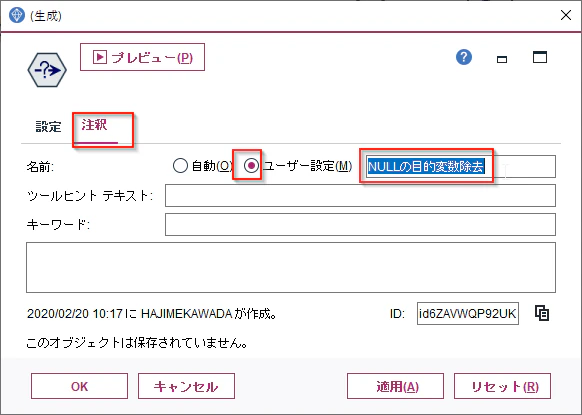
ノードの名前が「(生成)」のままだとわかりにくいので、注釈のタブに移り、「名前」をユーザー設定にし、「NULLの目的変数除去」と入力し、OKで閉じてください。
「ERR_CD_5FUTURE」のフィールド作成ノードと「M_CD='104'」の条件抽出ノードの間に接続し、テーブルノードを実行します。
ERR_CD_5FUTUREが$null$の行が削除されたことが確認できました。

赤い×ボタンで閉じてください。
予測モデル作成1
では、今作成した「ERR_CD_5FUTURE」を目的変数として予測モデルを作ってみましょう。
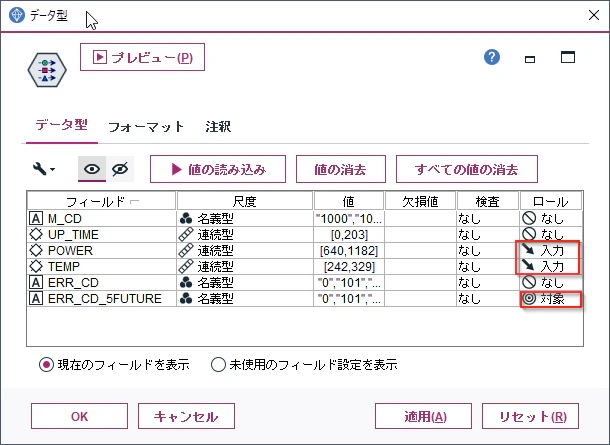
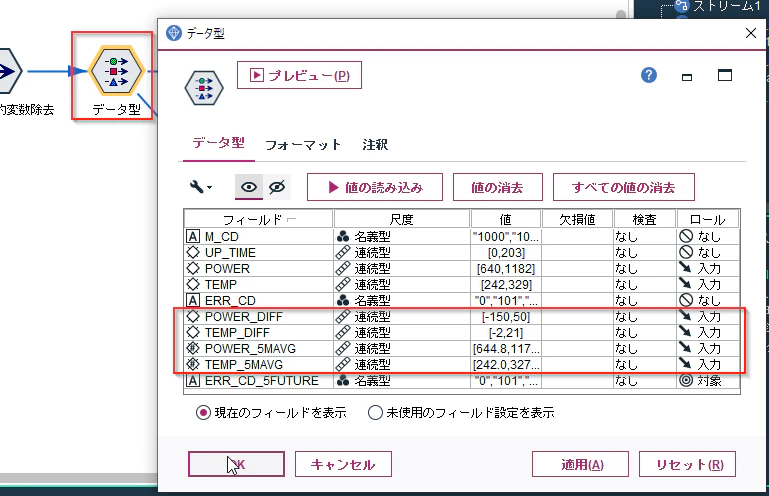
「NULLの目的変数除去」ノードにデータ型ノードを接続し、プロパティで「値の読み込み」ボタンをクリックしてから、以下のように設定します。
「ERR_CD」を対象ではなく、新たに生成した「ERR_CD_5FUTURE」を対象にすることがポイントになります。これで5時間先のエラーが予測対象になりました。OKボタンで閉じます。
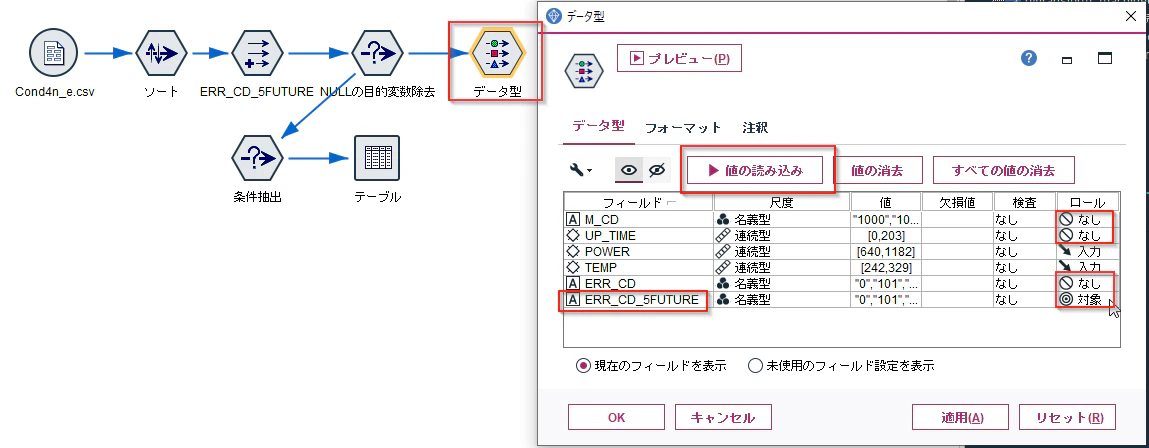
モデル作成ノードの「CHAID」を接続し、実行してください。
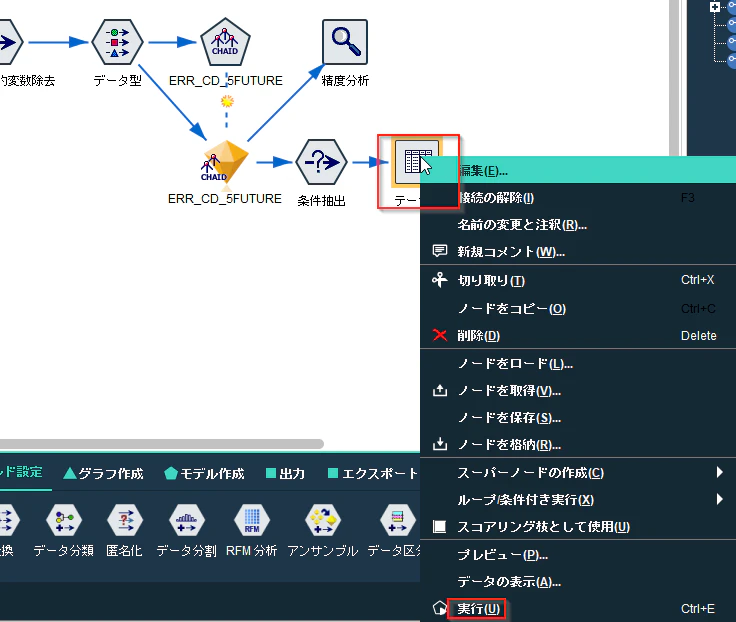
生成された「ERR_CD_5FUTURE」のモデルナゲットに先ほど作った「M_CD='104'」の条件抽出ノードとテーブルノードを接続します。そして、テーブルノードを実行してください。
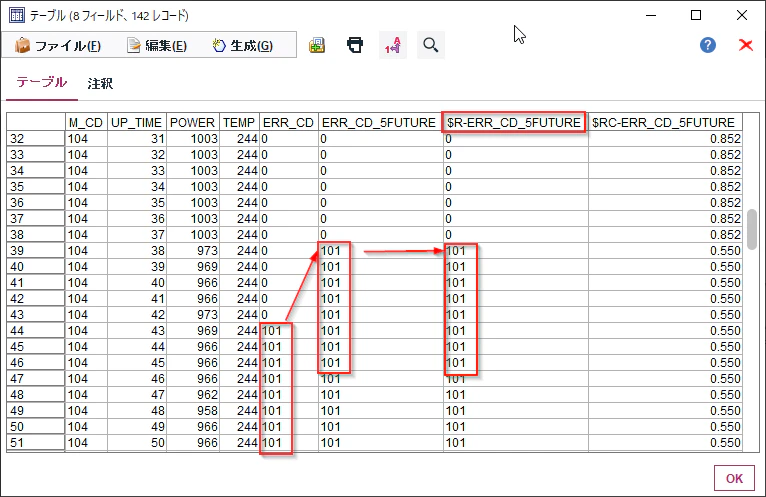
実際のエラーが発生する5時間前の38時間目の時点で「$R-ERR_CD_5FUTURE」で101のエラーが予測できています。このモデルであれば故障の”予知”が可能です。
赤い×ボタンで閉じてください。
モデルの性能を精度で確認してみます。
「精度分析」ノードを接続して、実行してください。
精度は93.86%でした。

特徴量抽出
もう少し性能を上げてみたいと思います。
前回以下のようなグラフを書いて、時間経過とともに温度が上がっていることがわかっていました。
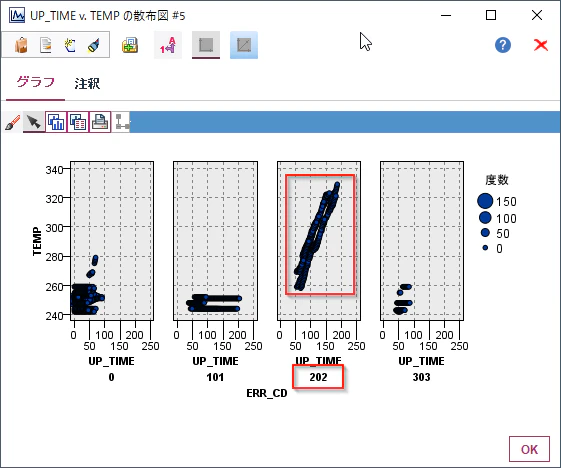
データ型ノードのプロパティを改めて見てみるとこのモデルはある時間のPOWERとTEMPからのみERR_CD_5FUTUREを判別しています。
つまりデータの前後関係はみていないということになります。
データを見てみましょう。
レコード設定タブから、条件抽出ノードを接続し、M_CD='1001'を入力し、OKで閉じてください。

テーブルノードを実行します。
以下の例なら63時間目にPOWER=886ワットとTEMP=251度という条件だけで101エラーが発生すると誤判別しています。

時系列データはその変化を新しい特徴量として加工することでより説明力を高めることができます。
データの差をとったり、移動平均をとってならすことで多少のブレを吸収したりすることができます。
では、まず差分をとってみます。
ソートノードとERR_CD_5FUTUREのフィールド作成ノードの間を広げて、新しいフィールド作成ノードをつなぎます。
ダブルクリックしてプロパティを開きます。
モードを「複数」に設定します。そして、利用可能なフィールドの設定から取得ボタンを押して、POWERとTEMPを選びます。フィールドリストに表示されます。
フィールド名拡張子に「_DIFF」を設定します。
そして派生で「条件付き」を選びます。
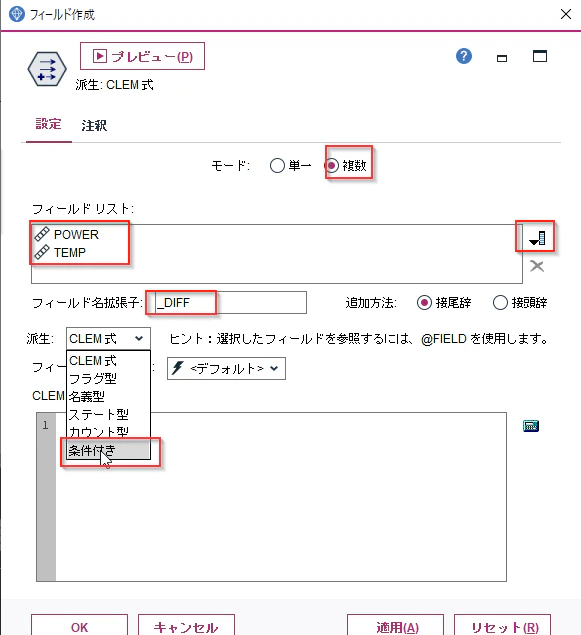
以下を設定します。
If: M_CD = @OFFSET(M_CD,1)
Then: @DIFF1(@FIELD)
Else: undef
先ほどERR_CD_5FUTUREを生成した時の応用になります。
@OFFSETという関数は今いる行の前や後の行を参照するという関数でした。
@DIFFは1行前との差分を計算します
@FIELDはフィールドリストにあげた複数の変数に対して同じ処理を行うという意味です。
M_CD が1行前と同じ場合にPOWERとTEMPについて1行前との差分を設定し、M_CD が1行前と違う場合はNULL(undef)を設定するという意味です。
設定ができたらOKで閉じてください。
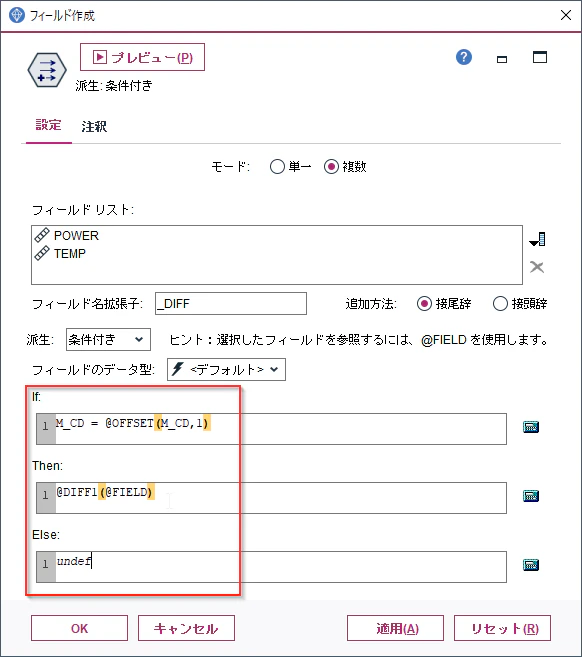
テーブルノードを実行します。

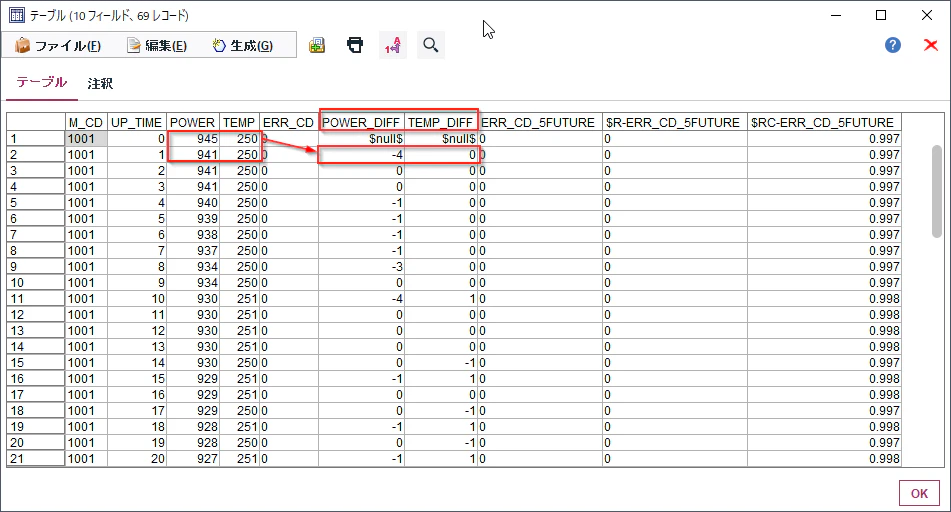
POWER_DIFFとTEMP_DIFFという列が生成されています。
1時間目のPOWER_DIFFは1時間目の941ワットから0時間目の945ワットを引いた-4ワットとなっています。
次に移動平均の特徴量を生成してみます。
_DIFFのノードをコピーして利用します。
右クリックして、「ノードをコピー」を選んでください。
そしてキャンバスに貼り付けます。
「_DIFF」ノードと「ERR_CD_5FUTURE」ノードの間に入れてから、ダブルクリックしてプロパティを開き、以下を設定します。
フィールド名拡張子:_5MAVG
If:M_CD = @OFFSET(M_CD,4)
Then:@MEAN(@FIELD,5)
Else:undef
@MEANはN行前までのデータの平均を計算します
M_CD が4行前と同じ場合に、POWERとTEMPについて自行から4行前までのデータの平均を設定し、M_CD が4行前と違う場合はNULL(undef)を設定するという意味です。
設定ができたらOKで閉じてください。

テーブルノードを実行します。
POWER_5MAVGとTEMP_5MAVGという列が生成されています。
4時間目のPOWER_5MAVGは0時間目からの4時間目までの945,941,941,941,940ワットの平均である941.6ワットとなっています。

モデルの再作成
では、これらの新たにつくった特徴量変数をつかってモデルを作り直してみましょう。
まず、データ型ノードをダブルクリックしてプロパティを開きます。
自動的に新たに作った特徴量変数が説明変数として登録されていることを確認したら、OKで閉じてください。
モデル作成ノードの「CHAID]を実行します。
モデル再作成されたのでテーブルノードを実行してみます。
59時間目からの過去のデータも使うことで、先ほど誤判定をしていた63時間目の予測もうまくいっていました。

確認ができたら赤い×ボタンで閉じてください。
精度分析ノードを実行します。
全体の精度としても、特徴量を作る前の93.86%から95.47%に向上しました。

スコアリング
このモデルをつかって、センサーデータを毎時間、判定するスコアリングをしてみます。
ドラッグアンドドロップでCond4n_e104.csvをキャンバスに置き、Cond4n_e104.csvのノードをダブルクリックし、可変長インプットノードのプロパティを開き、データのタブを開き、M_CDとERR_CDの「上書き」にチェックをつけ、「ストーレジ」を整数から文字型に変更します。
Cond4n_e.csvのノードのプロパティは「OK」で閉じてください。

テーブルノードを接続します。もう一つのテーブルノードと区別できるように名前を変えます。ダブルクリックしてプロパティを開いてください。
出力のタブで「出力名」に「ユーザー設定」を選び、「スコアリング」と入力して、実行ボタンをクリックします。
M_CD=104のマシンの38時間目の状態で、5時間後の43時間目にエラーが発生するかを予測します。差分や移動平均の特徴量変数をつくるために4時間前の34時間目以降のデータが必要になります。

確認ができたら、赤い×ボタンで閉じてください。
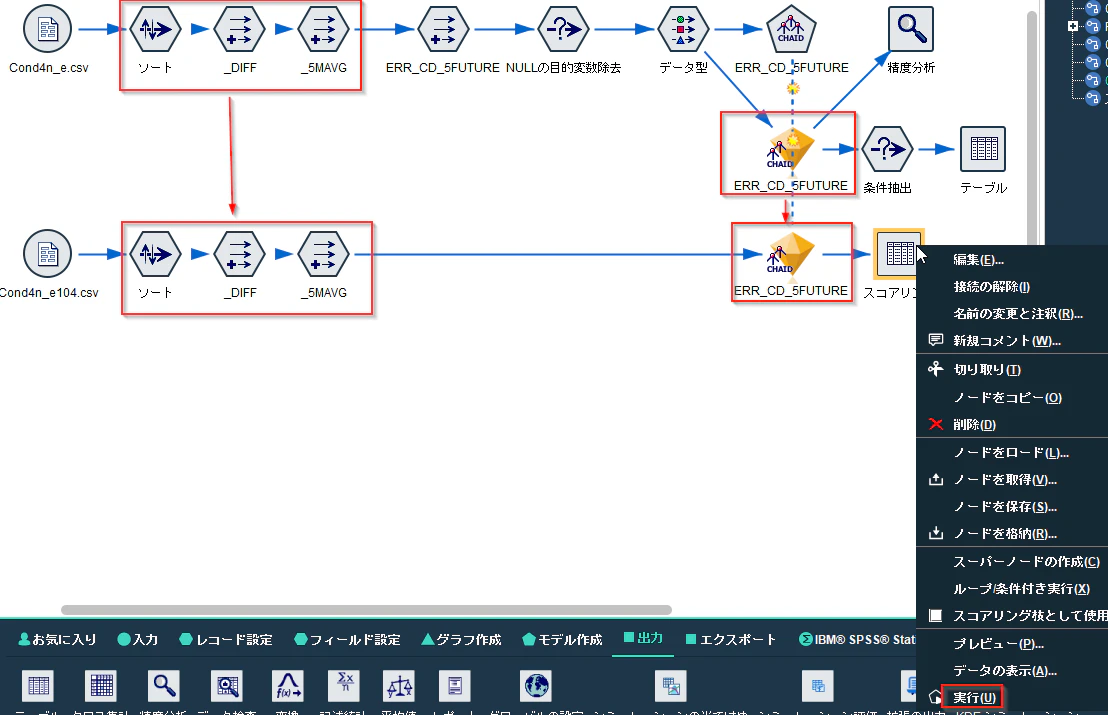
「Cond4n_e104.csv」の入力ノードと「スコアリング」のテーブルノードの間に、特徴量変数を作る「ソート」「_DIFF」「_5AVG」の3つのノードと「ERR_CD_5FUTURE」のモデルナゲットノードをコピーしてつなぎます。
そして、「スコアリング」のテーブルノードを実行してください。
次のように現在の38時間目の時点ではエラーは起きていませんが、5時間後には101のエラーが発生することを予測しています。5時間の間になんらかの対処を行うことでエラーを回避できるかもしれません。

おわりに
2回にわけて、時系列データをつかった故障分析を行いました。試行錯誤をしながらデータを理解し、時系列の前後のレコードを活用することが重要だということがお分かりいただけたかと思います。
SPSS Modelerは、試行錯誤が行いやすく、また@OFFSETのような前後のレコードにアクセスする関数があるので、このような分析が行いやすいことを感じていただければ幸いです。
参考
SPSS Modelerによる製造系データの分析ハンズオン・コンテンツへのリンク - Qiita