1列内にある区切り文字(改行やカンマなど)を含む文字列を列展開にする

1.想定される利用目的
・履歴やタグのようなリスト構造を持つフィールドの利用
2.サンプルストリームとデータのダウンロード
3.サンプルストリームの説明

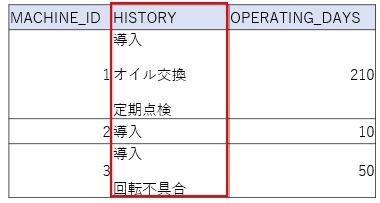
a.入力するデータは以下の通りです。
「改行」が区切り文字で複数のデータが一つのフィールドに記録されています。データ数は行によって異なっていてもかまいません。
b.[フィールド作成]ノードを編集します。
まず、「HISTORY」列に何件のデータがあるかを数えて、何列用意すればいいかを調べます。
count_substring(HISTORY,'\n')+1
で区切り文字の数をカウントします。「\n」は改行コードを意味しています。区切り文字の数+1がデータ数になります。
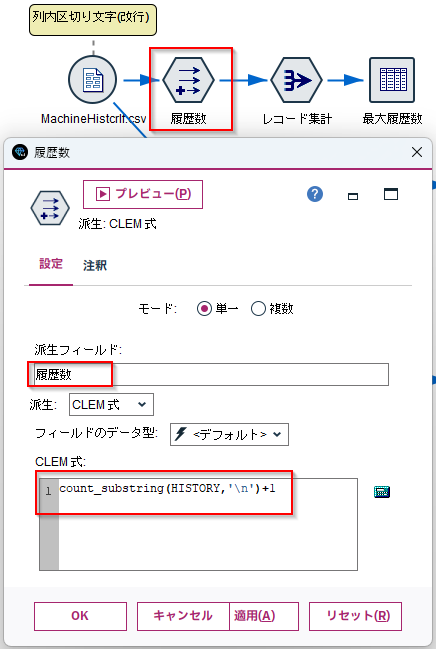
[プレビュー]を実行します。

c.[レコード集計]ノードを編集します。
[履歴数]列の「最大」を集計します。
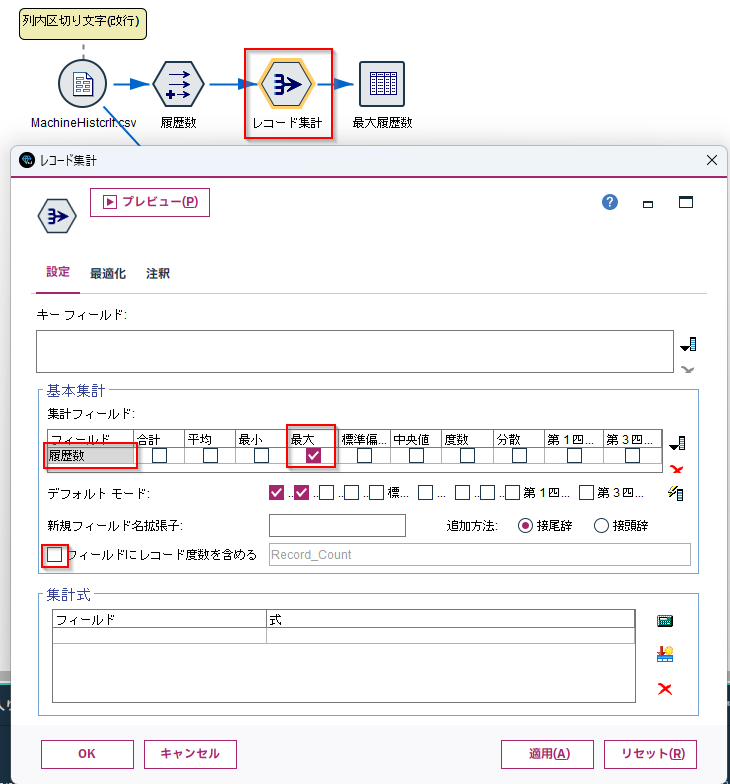
結果は3件でしたので、3列用意する必要があります。
d.[フィールド作成]ノードを編集します。
[HISTORY]列を区切り文字(改行コード)で一つずつ取り出していきます。
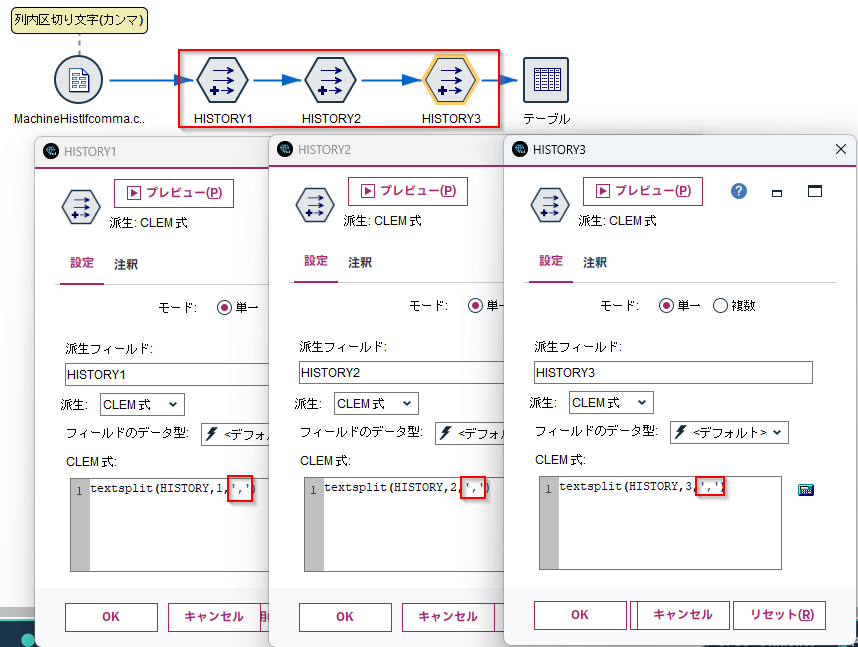
3列分の[フィールド作成]ノードを作ります。
textsplit(HISTORY,1,'\n')
textsplit(HISTORY,2,'\n')
textsplit(HISTORY,3,'\n')

[テーブル]を実行します。3列に分割できました。

注意事項
カンマ区切りの場合は区切り文字を変える必要があります。
textsplit(HISTORY,1,',')
4.参考情報
区切り文字を含むフィールドの値を縦持ちする(SPSS Modeler データ加工逆引き7-16) #SPSS - Qiita
当記事では横持で展開しましたが、こちらは縦持ち展開する記事です。
アンケートの複数回答可 (MA)列をフラグに分解する(SPSS Modeler データ加工逆引き2-14) #SPSS -
当記事では展開データは不明という想定でしたが、中身がわかっている場合にはこちらの記事のようにフラグ化するようなことも可能です。
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)