SPSS Modelerを使って、時系列センサーデータを用いた、連続型を目的変数とした二変量解析を行います。
多数のデータの中から目的変数に関係する説明変数を探すことは容易ではなく、やみくもに集計・可視化しても効率的ではありません。この記事では次の手順で、目的変数と関係が強そうな説明変数を探していきます。
- 探索すべき説明変数の優先度をつける
- 変数の尺度の関係から適切な統計量と可視化方法で説明変数を確認する
- 時系列データの場合は元データで確認する
目的変数が連続型かカテゴリ型で、「2.変数の尺度の関係から適切な統計量と可視化方法で説明変数を確認する」の工程が異なるため記事を二つに分けています。
- ①連続型を目的変数とする二変量解析←この記事
- ②カテゴリ型を目的変数とする二変量解析
すでに②の記事を実行された場合は「B.データ加工」までは同じ手順ですので、「C.連続型を目的変数とした二変量解析」から始めてください。
-
稼働確認環境
- Modeler 19.0
- Windows 11
-
データ
- 完成ストリーム
A.データの入力
A1. ストリームオプションの設定
最初に、プレビューで参照できる行数を増やします。
「ツール」→「ストリームのプロパティ」→「オプション」を選択します。

データプレビューの最大行数を 1000 に設定し、「OK」で閉じます。

A2. センサーデータを入力
01センサーデータ反応期.csv を Modeler のキャンバスにドラッグ&ドロップします。

右クリックし「プレビュー」を選択します。

タイムスタンプ、ロットID、idx、温度、振動のデータが記録されており、ロットIDごとに10秒間隔でセンサー値が格納されています。ロットIDが変わると idx は 1 に戻ります。

確認し終わったら赤い×ボタンで閉じます。
続いて「データ型」ノードを接続し、「値の読み込み」を押して ロットID の尺度を「名義型」に変更します。

A3. ロットデータを入力
同様に02ロットデータ.csvを配置し、プレビューで確認します。

このデータは石油化学製品を模したもので、製品の条件(製品グレード・原料・反応器ID)と結果(色調異常・品質値)が、ロットIDごとに1行で記録されています。

確認し終わったら赤い×ボタンで閉じます。
01センサーデータ反応期.csvと同様に、データ型ノードを接続し、「値の読み込み」ボタンを押しロットIDの尺度を「名義型」に変更しOKで閉じます。

B.データ加工
B1. データ集計
01センサーデータ反応期.csv はロットIDで複数行に分かれていますので、ロット単位に集計します。
レコード集計ノードでキーフィールドにロットIDを選び、集計フィールドに温度と振動を選び、平均、最小、最大、標準偏差にチェックをつけてOKで閉じます。

プレビューをみると以下のようにロットIDで一意のレコードになりました。これで02ロットデータ.csvと結合してロット単位で二変量解析が可能になります。

B2. レコード結合
「レコード設定」タブからレコード結合ノードを選び、キャンバスにドラッグ&ドロップします。
そして、01センサーデータ反応期.csvと02ロットデータ.csvから接続します。
レコード結合ノードを右クリックして、「編集」を選びます。
「レコード結合」タブで「レコード結合方法」で「キー」を選びます。そして、「ロットID」を→ボタンで結合キーを設定し、OKで閉じます。

これで「プレビュー」してください。
二つのCSVを結合できたことがわかります。

C.連続型を目的変数とした二変量解析
これでロット単位での分析の準備はできました。この記事では品質値という連続型を目的変数にして、品質値に関係ある変数が何なのかを調べていきたいと思います。
C1. 変数のロール設定
目的変数として 品質値(連続型)を使用し、どの説明変数が関係しているかを調べます。
「フィールド設定」タブから「データ型」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、「レコード結合」ノードから接続し、右クリックで「編集」を選びます。
「値の読み込み」ボタンを押して、
-
ロットID,色調異常→ ロール「なし」 -
品質値→ ロール「対象」
を設定します。

C2. 重要特徴量のランキング
説明変数が多い場合、「特徴量選択」ノードを使うと目的変数に対する関連度がランキングされます。
目的変数が連続型の場合
- 説明変数が連続型 → 相関係数の t 検定の p 値
- 説明変数がカテゴリ型 → F 検定の p 値
で重要度が評価されます。異なる検定のp値は本来比較できませんが、とりあえずランキングしてくれるのはとても便利です。
何かモデルを作って「予測変数の重要度」で、重要な変数を評価することもあると思いますが、「特徴量選択ノードのランキング」と「予測変数の重要度」の違いは以下になります。
| 特徴量選択ノードのランキング | 予測変数の重要度 | |
|---|---|---|
| 目的変数と各説明変数の二変量(目的変数と単一説明変数の1対1関係)での関係の評価 | 〇可能 | △その説明変数単独ではあまり影響していなくても、他の説明変数との組み合わせの影響で上位にランキングされることがある |
| 統計量での評価 | 〇t値、F値、カイ二乗値といった一般的な検定統計量で評価される | △あるモデルのアルゴリズムに依存した評価であり、必ずしも一般的解釈が可能ではない |
| 複数変量(目的変数と複数説明変数の関係)による影響評価 | ×1対1の二変量での関係の評価 | 〇複数変量で重要な項目も上がる |
| 相対的影響度 | ×各項目それぞれの重要度 | △各変数間での相対的影響度がわかる。ただしモデルのアルゴリズムに依存 |
モデルの「予測変数の重要度」と異なり、特徴量選択は1対1の二変量の関係に着目しており、解釈しやすい点が利点です。
「モデル作成」タブから「特徴量選択」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、「データ型」ノードから接続し、右クリックで「編集」をします。
スクリーニングの設定で、「最小変動係数」の値を0.01に設定してください。微妙な変動であっても目的変数に影響を与えていることがあります。
「実行」をします。

今回、
- 連続型の説明変数の中では
振動_Max - カテゴリ型の説明変数の中では
反応器ID
が上位となりました。

この後、この振動_Maxと反応器IDについて統計量とグラフでどのような関係があるのかを理解していきます。
D.統計量と可視化による確認
目的変数と説明変数の尺度(連続型かカテゴリ型か)の関係によって、関係を表現する統計量と可視化方法には、基本的な選択肢があります。
| 目的変数と説明変数の関係 | グラフ | 記述統計量 | 検定統計量 | ノード |
|---|---|---|---|---|
| 連続型vs連続型 | 散布図 | 相関係数 | t値 | データ検査 |
| 連続型vsカテゴリ型 | 色分けヒストグラム、箱ひげ図 | 平均値 | F値 | 平均値 |
| カテゴリ型vsカテゴリ型 | 積み上げ棒グラフ、正規化棒グラフ、ヒートマップ | 割合 | カイ二乗値 | クロス集計表 |
D1. 連続型 vs 連続型
連続型vs連続型の場合、記述統計量は「相関係数」、可視化は「散布図」で見ていくことが基本になります。
Modelerでは「データ検査」ノードを使うと、「相関係数」も「散布図」も一覧で見ることができて簡単です。
「出力」タブから「データ検査」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、「データ型」ノードから接続し、右クリックで「実行」をします。

「相関」で降順に並べ替えます。
「特徴量選択」ノードでランキング最上位だった振動_Maxが、相関係数が0.73で最も高い変数として出てくることがわかります。
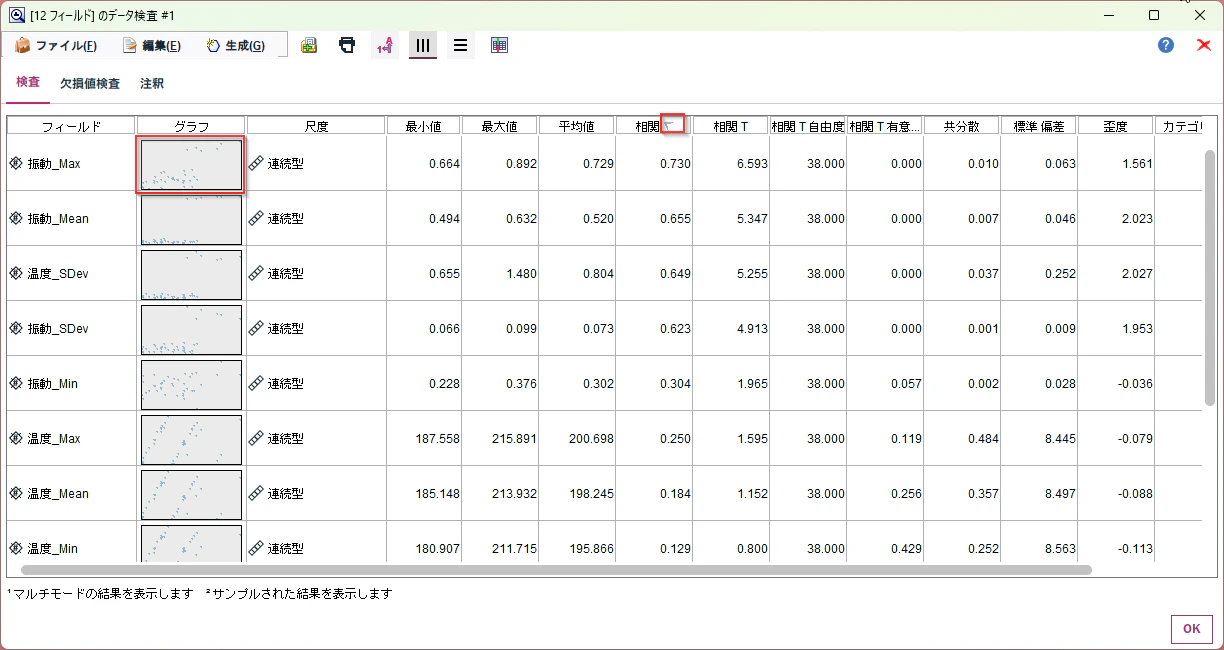
グラフをダブルクリックすると、散布図を拡大して関係を確認できます。散布図によって可視化することで、相関係数だけではわからない非線形の関係、外れ値の影響、分布の形を確認できます。
散布図を見ると、強い正の相関があるほか、中央のデータが少ないなど分布の特徴も確認できます。

このように「データ検査」ノードでは相関係数が高い順に説明変数との関係をみていくことが可能です(負の相関があることもあるので、昇順で並べ替えてみることも重要です)。効率的に目的変数と関係ありそうな連続型の変数を探索出来ます。
D2. 連続型 vs カテゴリ型
連続型vsカテゴリ型の場合、記述統計量は「平均値の差」、可視化は「色分けヒストグラム」や「箱ひげ図」で見ていくことが基本になります。
カテゴリ型で最上位だった 反応器ID を確認します。

D2-1. 平均値(記述統計量)
まず平均値の差を確認してみるには「平均値」ノードが便利です。
「出力」タブから「平均値」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、「データ型」ノードから接続し、右クリックで「編集」をします。
- グループ化フィールド:
反応器ID(説明変数) - テストフィールド:
品質値(目的変数)
を設定し実行します。

表示を「詳細」に設定するとより詳しい情報が出ます。
この結果から品質値が、反応器IDがR1では0.519、R2では0.243であり、重要度が1.0であり、統計的に有意な差があると判断されます。
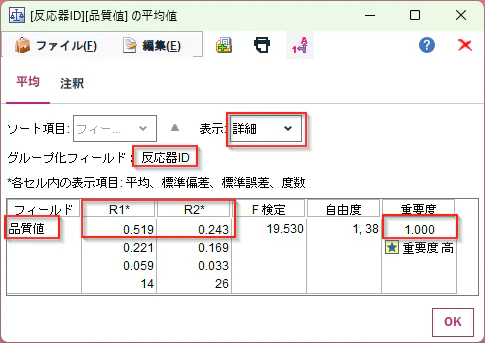
平均値は「集計」ノードでも出すことができますが、「平均値」ノードだと検定も行えることが特徴です。
D2-2. 可視化
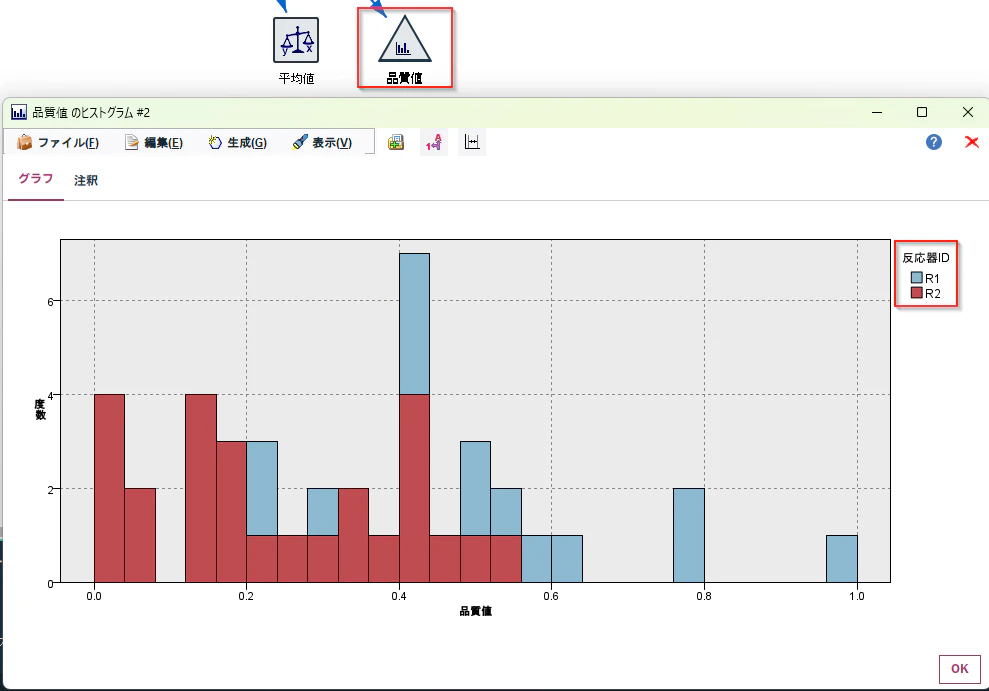
まず、色分けヒストグラムを作ってみます。
「グラフ」タブから「ヒストグラム」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、「データ型」ノードから接続し、右クリックで「編集」をします。
フィールドに品質値(目的変数)を設定し、オーバーレイの色に反応器ID(説明変数)を設定し、「実行」ボタンを押します。

平均値ノードで確認したように、確かに反応器IDR1の時には品質値が高く、R2の時には品質値が低いことが確認できます。
次に箱ひげ図を作ってみます。
「グラフ」タブから「グラフボード」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、「データ型」ノードから接続し、右クリックで「編集」をします。
視覚タイプに「箱ひげ図」を選び、Xに反応器ID(説明変数)、Yに品質値(目的変数)を設定し、「実行」ボタンを押します。
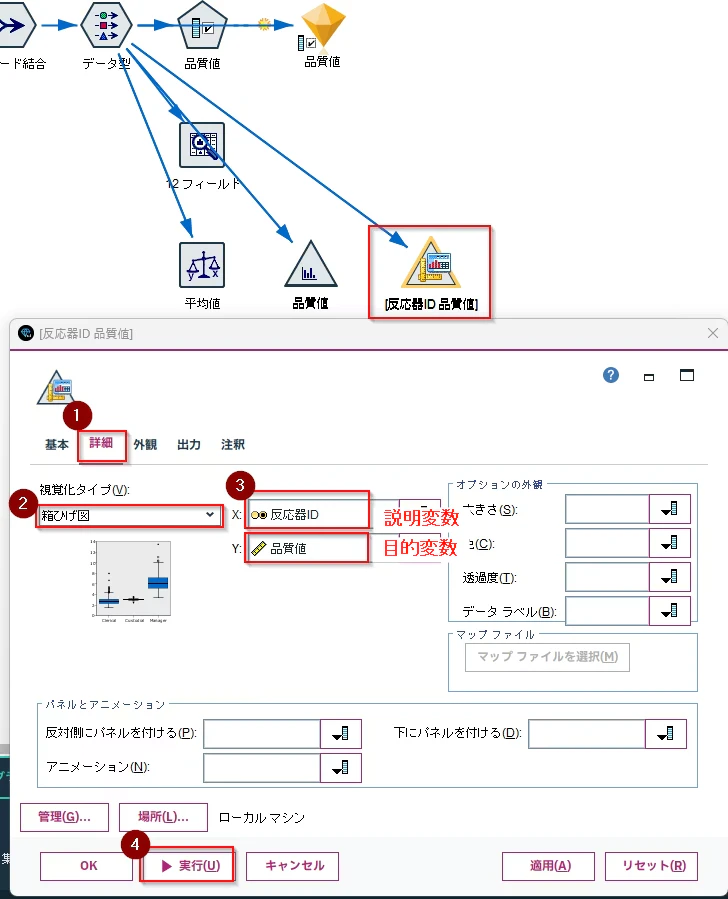
以下のように箱ひげ図でR1とR2の違いを確認できます。
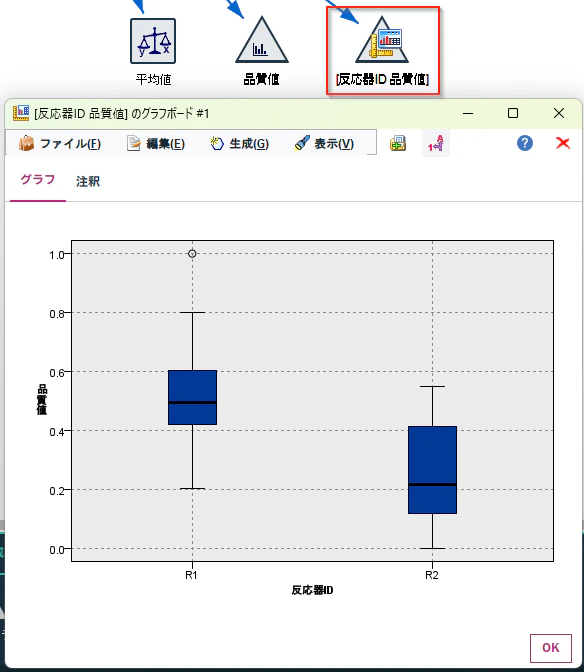
可視化することで、平均値の差だけではわからない分布の形・ばらつき・外れ値・群の重なりが確認できます。
D2-3 色分けヒストグラムと箱ひげ図の使い分け
色分けヒストグラムと箱ひげ図の使い分けには以下のような基準があります。
| グラフ | 適する場面 | 短所 |
|---|---|---|
| 色分けヒストグラム | 分布の形状や重なりを見たいとき(例:正規性の違い、ピークの位置)。カテゴリが少ない(2~3群)場合に有効 | 群が多いと見づらい |
| 箱ひげ図 | 各カテゴリの代表値とばらつきを一目で比較できる。群が多くても比較しやすい | 分布の形(山が一つか二つか)はわかりにくい |
例えば3群ある説明変数の製品グレードについて色分けヒストグラムと箱ひげ図を出してみます。箱ひげ図をみると製品グレードがA<B<Cの順に品質値の高いことが一目でわかります。一方で色分けヒストグラムをみないと、製品グレードBは0.3や0.4などの真ん中の品質値がなく多峰の分布になっていることはわかりません。

D2-4 複数カテゴリの可視化
また、連続型同士の比較で「データ検査ノード」で一度に複数の散布図がだせるのと異なり、連続型の目的変数でカテゴリ型の説明変数との関係を可視化する場合、「ヒストグラム」などのグラフを一つずつ作成する必要があり手間がかかります。
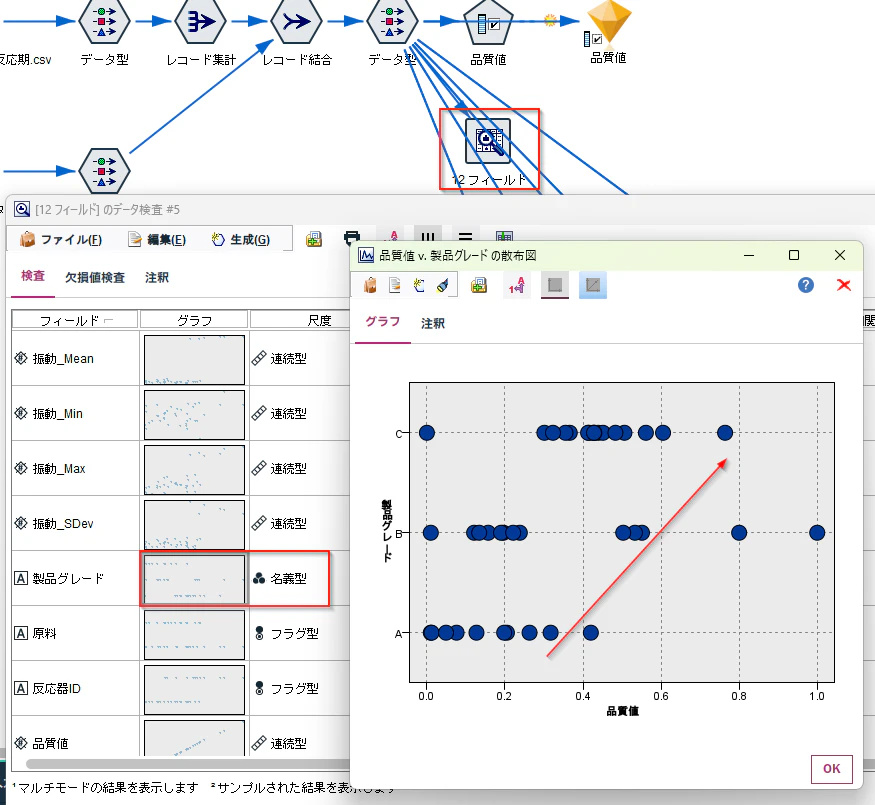
一応、「データ検査ノード」でも、複数のカテゴリ型説明変数の「ストリッププロット」が一覧表示されます。「ヒストグラム」などよりやや視認性は劣りますが、ざっと比較するには便利です。
例えば、以下では製品グレードが、A<B<Cの順に品質値が高い雰囲気はわかります。
E.時系列グラフでの可視化
集計値は分かりやすい反面、時系列の特徴が失われます。要因を深掘りするには、元の時系列データを確認することが重要です。
例えば、今回関連の高い説明変数として振動_Maxが最上位でしたが、振動が最大になったのはプロセスの中の前半なのか、後半なのか、全般におきているのかなどは振動_Maxからだけではわかりません。またそれはロットごとに同一の傾向なのか違っているのかなどもわかりません。
ですので、品質に影響する要因として有力な振動が時系列データとして実際にどのように変化していたのかを見ていきます。
E1. 時系列データの準備
集計する前のセンサーデータとロットの品質データを結合していきます。
「レコード設定」タブから「レコード結合」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、01センサーデータ反応期.csvを集計する前の「データ型」ノードと02ロットデータ.csvの「データ型」ノードから接続し、右クリックで「編集」をします。
レコード結合に「キー」を選び、結合キーにロットIDを設定し、「OK」します。

「レコード設定」タブから「ソート」ノードを選び、キャンバスにドラッグ&ドロップします。「レコード結合」ノードから接続し、右クリックで「編集」をします。
ソート項目にロットIDとidxを設定し、「OK」します。

右クリックでプレビューしてみると時系列のセンサーデータとロットデータが結合されたことがわかります。

E2. 時系列データの可視化
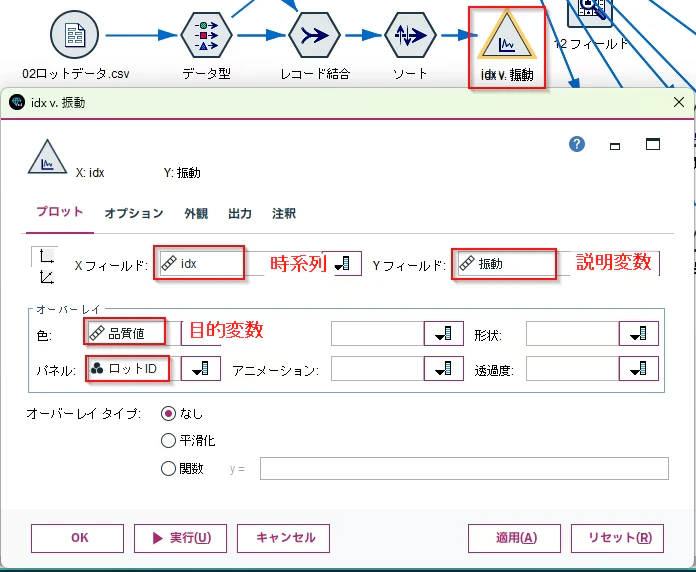
「グラフ」タブから「散布図」ノードを選び、キャンバスにドラッグ&ドロップします。
そして、「ソート」ノードから接続し、右クリックで「編集」をします。以下の設定をして「OK」します。
Xフィールド: idx(時系列)
Yフィールド: 振動(説明変数)
色: 品質値(目的変数)
パネル: ロットID
次に、オプションタブにうつり、「スタイル」を「線」に設定して「実行」します。
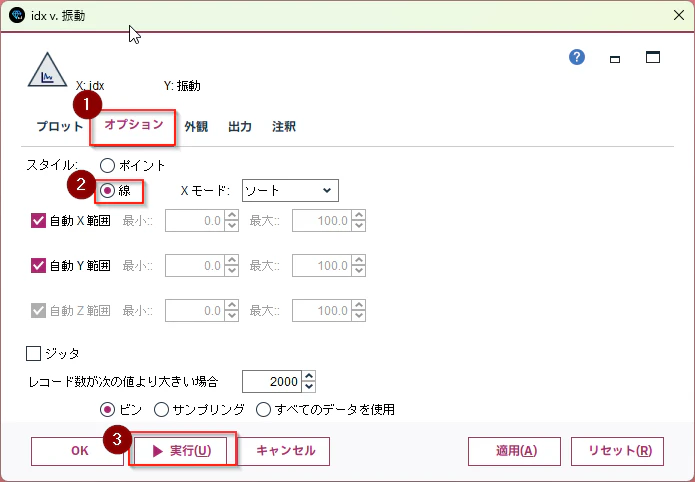
各ロットIDごとに振動の時系列データが表示されます。
これをみると確かに振動が大きい時に品質値の色が濃いので高いことがわかります。

ただ、ロットの数が多すぎて時系列の変動がわかりにくいので、ここでは品質値が低い例としてロットID2、品質値が高い例としてロットID6に絞り込んで拡大してみます。
「レコード設定」タブから「条件抽出」ノードを選び、ロットID = 2 or ロットID = 6を条件に設定し、OKします。

再度、「散布図」ノードを右クリックし、「実行」します。
品質値が低いグラフの色が見づらいので、背景色を変更します。
「表示」メニューの「編集モード」を選択します。
背景をクリックし、色の選択メニューから「ライトグレー」を選びます。

時系列グラフでみることで、統計量の振動_Maxが示していたロットID2よりロットID6の振動の最大が高いことだけではなく、周期的な振動パターンが確認できます。

この後はさらに他のロットも確認して、この傾向が一般的にいえるかを確かめていくのがよいと思います。
F.まとめ
この記事では以下の手順で二変量解析を行いました。
- 探索すべき説明変数の優先度をつける
- 変数の尺度の関係から適切な統計量と可視化方法で説明変数を確認する
- 時系列データの場合は元データで確認する
F1. 探索すべき説明変数の優先度をつける
説明変数が多い場合、「特徴量選択」ノードで目的変数に対する関連度の高い変数をランキングできます。
F2. 変数の尺度の関係から適切な統計量と可視化方法で説明変数を確認する
連続型 vs. 連続型、連続型 vs. カテゴリ型 など、変数の組合せにより確認すべき統計量とグラフが異なります。
| 目的変数と説明変数の関係 | グラフ | 記述統計量 | 検定統計量 | ノード |
|---|---|---|---|---|
| 連続型vs連続型 | 散布図 | 相関係数 | t値 | データ検査 |
| 連続型vsカテゴリ型 | 色分けヒストグラム、箱ひげ図 | 平均値 | F値 | 平均値 |
| カテゴリ型vsカテゴリ型 | 積み上げ棒グラフ、正規化棒グラフ、ヒートマップ | 割合 | カイ二乗値 | クロス集計表 |
F3. 時系列データの場合は時系列の元データで確認する
統計量では時系列の特徴が失われるため、元データを時系列で確認することが重要です。
F4.最後に
統計的に関連が見られても、必ずしも因果関係があるとは限りません。業務知識を組み合わせて要因を深掘りしていくことが重要です。
参考
SPSS Modelerによる製造系データの分析ハンズオン・コンテンツへのリンク #SPSS_Modeler - Qiita