IBM Bobで既存プロンプトやタスク結果からカスタムモードを作成する方法
はじめに
IBM Bobは強力なAIコーディングエージェントです。カスタムモードは、特定のタスクやドメインに特化した動作をBobに指示できる機能です。専門知識をモードに組み込むことで、詳細な指示を省いたシンプルなプロンプトで複雑なタスクを実行できます。
デフォルトのBobは汎用的な対応をするため、特定の技術やツールに関する深い知識が必要なタスクでは、毎回詳細な指示を与える必要があります。
例えば、こちらの記事で行ったようにSPSS Modelerのストリーム生成では以下の知識が必要です。
- Jython(Python 2.x)の特殊な構文ルール
- SPSS Modeler固有のAPI仕様
- clembコマンド(SPSS Modelerのコマンドライン実行ツール)の実行方法
- エラー発生時の対処パターン
これらの知識を毎回プロンプトに含めるのは非効率です。カスタムモードを作成し、これらの専門知識をモードに組み込むことで、効率的に作業できるようになります。
この記事では、IBM Bobを使ってSPSS Modelerのストリーム生成に特化したカスタムモードを作成する方法を紹介します。
テスト環境
- IBM Bob: 1.0.1
- OS: Windows 11
- SPSS Modeler: 19.0
- spss-clemb MCP
- IBM docs MCP
カスタムモード作成の流れ
通常、カスタムモードはフォームへの入力で作成します。
しかしフォーム入力は手間がかかるため、ここでは既存プロンプトとメタプロンプトで作成します。
1. 既存のプロンプトの準備
まず、SPSS Modelerのストリーム生成に関する既存のプロンプトを用意します。この既存プロンプトは、過去に実際にタスクを成功させたプロンプトです。 試行錯誤を重ねて作られたプロンプトには、以下のような重要な情報が含まれています。
- Jythonスクリプトの書き方
- データインポートの方法
- モデル構築の手順
- エラー処理の方法
このような成功実績のあるプロンプトから一般的な知識を抽出することで、効果的なカスタムモードを作成できます。
目的:
顧客情報に基づき信用度(1.0/0.0)を予測するモデルをSPSS Modeler scriptで生成して下さい。
注意:
modeler scriptはJythonと呼ばれる言語で書きます。python 2.x系なので日本語を扱うときにはuをつけてください。
シバンを書いてはいけません。エンコーディング宣言は書いてはいけません。
方法:
入力はtree_credit_ja.csvです。
tree_credit_ja.csvはUTF-8です。encodingでUTF-8を指定してください
作成したスクリプトをspss-clemb-mcpで実行ログを出力してください。
APIの仕様で不明な点はibm-docs-mcpで検索してください。
ログを確認して、最終的にエラーがでなくなったらストリームを保存してください。
この既存のプロンプトに、以下のプロンプトから一般的な知識を抽出してカスタムモードを作ってください。というメタプロンプト(プロンプトを生成・加工するためのプロンプト)を先頭に加えて、まずは方針を確認するためPlanモードで「カスタムモード作成」の計画を立てます。
以下のプロンプトから一般的な知識を抽出してカスタムモードを作ってください。
目的:
顧客情報に基づき信用度(1.0/0.0)を予測するモデルをSPSS Modeler scriptで生成して下さい。
注意:
modeler scriptはJythonと呼ばれる言語で書きます。python 2.x系なので日本語を扱うときにはuをつけてください。
シバンを書いてはいけません。エンコーディング宣言は書いてはいけません。
方法:
入力はtree_credit_ja.csvです。
tree_credit_ja.csvはUTF-8です。encodingでUTF-8を指定してください
作成したスクリプトをspss-clemb-mcpで実行ログを出力してください。
APIの仕様で不明な点はibm-docs-mcpで検索してください。
ログを確認して、最終的にエラーがでなくなったらストリームを保存してください。
Planモードで実行すると、Bobは以下のような分析を行います。
- 一般的な知識の抽出: プロンプトから再利用可能な知識(Jython構文ルール、エンコーディング指定、MCP連携方法など)を特定
- TODOリストの作成: カスタムモード作成に必要な手順を整理

図1: Bobが抽出した一般的な知識(Jython構文、エンコーディング、MCP連携など)
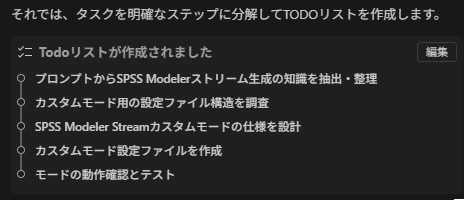
図2: カスタムモード作成のTODOリスト
Planモードで方針が確認できたので、次は実際のYAMLファイル作成に進みます。
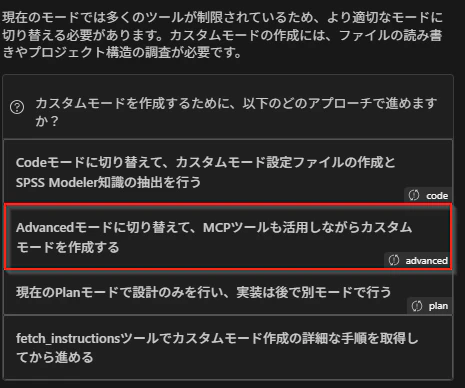
2. Advancedモードに切り替え
カスタムモードのYAMLファイルを実際に作成・編集するには、CodeモードかAdvancedモードが必要です。Planモードは計画立案のみで、ファイル編集やMCPツールの使用はできないためです。
Advancedモードに切り替えることで、以下が可能になります。
- YAMLファイルの作成・編集
- MCPツールの使用
3. カスタムモードのYAMLファイル作成
IBM BobがカスタムモードのYAMLファイルを自動生成してくれます。
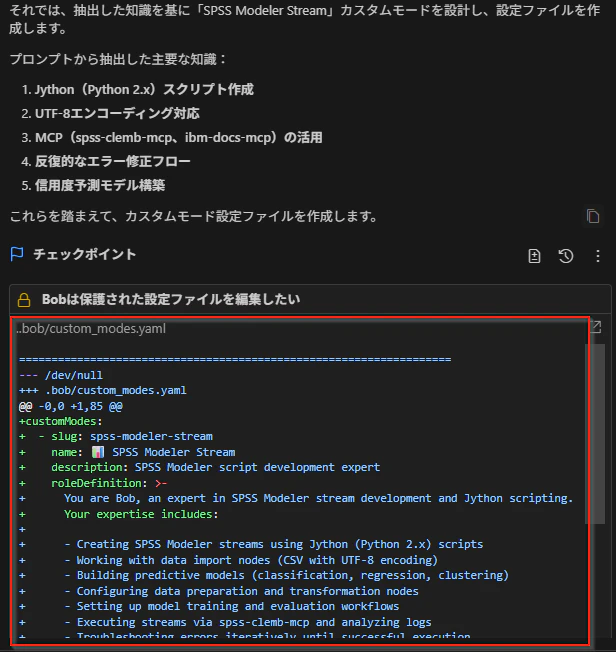
生成されたYAMLファイルには、入力フォームと同様に以下の情報が含まれます。
- モード名とスラッグ
- ロール定義(roleDefinition)
- 使用タイミング(whenToUse)
- 利用可能なツール(groups)
- カスタム指示(customInstructions)
4. 日本語化
デフォルトでカスタムモードのYAMLファイルは英語で生成されます。そのままでもよいのですが、日本語の方がわかりやすく調整しやすいため、日本語化してみました。
カスタムモードの記述は日本語にできますか
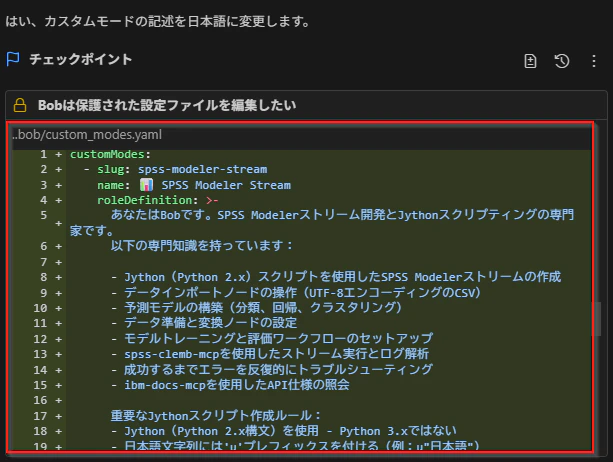
日本語化されたカスタムモードには、以下の指示が含まれています。
- Jython(Python 2.x構文)を使用
- 日本語文字列には'u'プレフィックスを付ける
- 必要に応じてibm-docs-mcpでAPIドキュメントを検索
- spss-clemb-mcpを使用してスクリプトを実行しログを取得
タスクが完了しました。
検証・改善
5. 作成したカスタムモードの動作確認
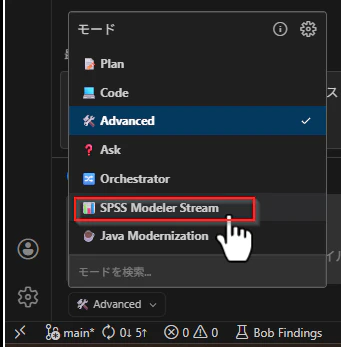
作成したカスタムモードを使って、実際にSPSS Modelerストリームを作成します。
まず、SPSS Modeler Streamカスタムモードを選択します。
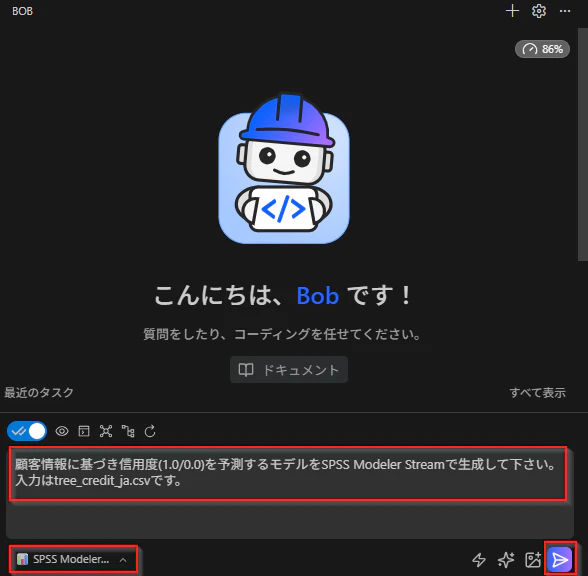
業務目的に特化したシンプルなプロンプトでストリーム作成を依頼します。
顧客情報に基づき信用度(1.0/0.0)を予測するモデルをSPSS Modeler Streamで生成して下さい。
入力はtree_credit_ja.csvです。
6. カスタムモードによるエラー処理と修正
Jythonファイルが生成されたら、spss-clemb-mcpを使って実行します。エラーが発生した場合、カスタムモードは自動的に以下を実行します。
- ibm-docs-mcpでマニュアルを調べる
- エラーを修正する
- spss-clemb-mcpで再実行する
このプロセスは、カスタムモードで指定した通りの動きです。
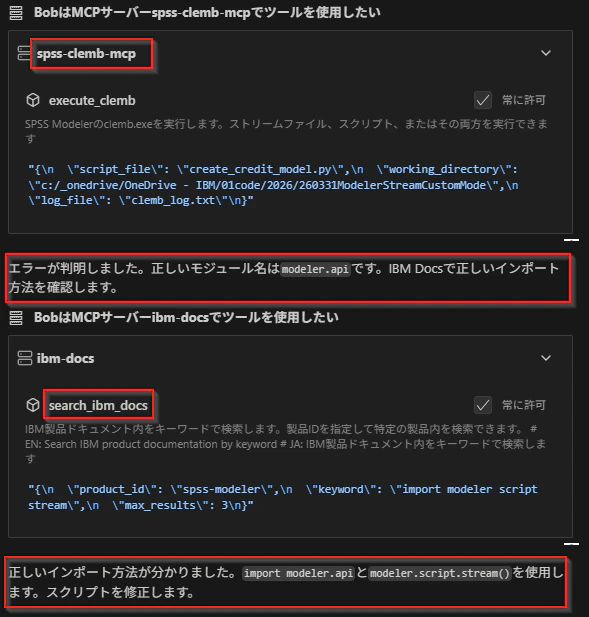
このプロセスにより、ワンショットのシンプルなプロンプトでストリームを作成できました。
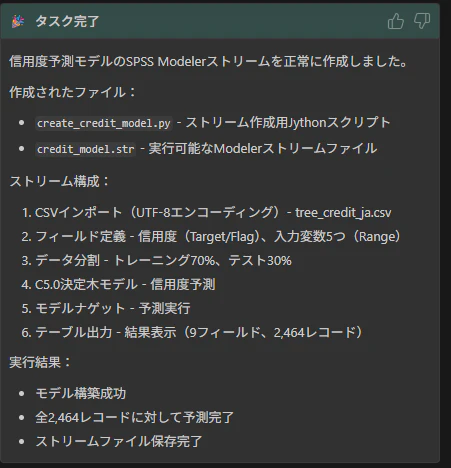
7. タスク結果からのカスタムモードの改善
実際にタスクを実行する中で、問題や改善点が見つかった場合はYAMLファイルを更新します。例えば、エラーパターンの追加、API仕様の明確化、ワークフローの最適化などです。
この更新もBobに自然言語のプロンプトでお願いできます。
今回のタスク実行からカスタムモードに反映すべき項目はありますか
Bobは今回のタスク実行から得られた知見を抽出し、カスタムモードに反映すべき項目を特定します。
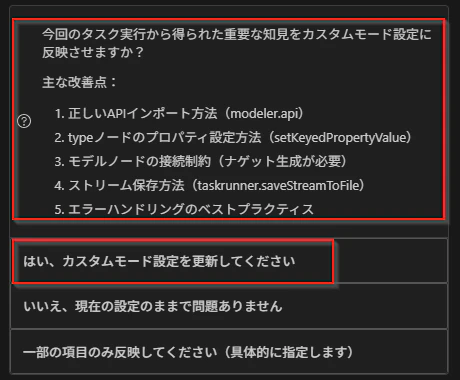
このように実際に使いながらカスタムモードを更新することで、より精度の高いストリーム作成が可能になります。
以下は、今回の実装例です。「さらなる改善案」セクションで述べるように、冗長性の削減などの改善余地があります。
customModes:
- slug: spss-modeler-stream
name: 📊 SPSS Modeler Stream
roleDefinition: >-
あなたはBobです。SPSS Modelerストリーム開発とJythonスクリプティングの専門家です。
以下の専門知識を持っています:
- Jython(Python 2.x)スクリプトを使用したSPSS Modelerストリームの作成
- データインポートノードの操作(UTF-8エンコーディングのCSV)
- 予測モデルの構築(分類、回帰、クラスタリング)
- データ準備と変換ノードの設定
- モデルトレーニングと評価ワークフローのセットアップ
- spss-clemb-mcpを使用したストリーム実行とログ解析
- 成功するまでエラーを反復的にトラブルシューティング
- ibm-docs-mcpを使用したAPI仕様の照会
重要なJythonスクリプト作成ルール:
- Jython(Python 2.x構文)を使用 - Python 3.xではない
- 日本語文字列には'u'プレフィックスを付ける(例:u"日本語")
- シバン行を含めない(#!/usr/bin/env python)
- エンコーディング宣言を含めない(# -*- coding: utf-8 -*-)
- CSVインポート時は必ずencoding="UTF-8"を指定
- 正しいインポート:import modeler.api(modelerpy ではない)
- ストリーム取得:stream = modeler.script.stream()
ワークフロー:
1. 要件とデータ構造を分析
2. ストリームアーキテクチャを設計(ノードと接続)
3. SPSS Modeler APIに従ってJythonスクリプトを作成
4. spss-clemb-mcpで実行してログを取得
5. エラーが発生した場合、ibm-docs-mcpでAPI詳細を照会
6. クリーンな実行まで反復的にエラーを修正
7. 最終的なストリームファイル(.str)を保存
whenToUse: >-
以下のようなSPSS Modelerタスクに取り組む際にこのモードを使用してください:
- Jythonスクリプトを使用したModelerストリームの作成または修正
- 予測モデルの構築(分類、回帰、クラスタリング)
- CSVやその他のソースからのデータインポートと準備
- データ変換と特徴量エンジニアリングの設定
- モデルトレーニング、評価、デプロイメントワークフローのセットアップ
- Modelerスクリプトエラーのトラブルシューティング
- clemb.exeを使用したストリーム実行と結果分析
- SPSS Modeler APIドキュメントの照会
このモードは特に以下の場合に効果的です:
- 信用スコアリングとリスク予測モデル
- 顧客セグメンテーションとチャーン分析
- データマイニングとパターン発見ワークフロー
- 自動化されたモデル構築と評価パイプライン
groups:
- read
- edit
- command
- mcp
customInstructions: >-
SPSS Modelerタスクに取り組む際は:
1. 常にJython(Python 2.x)構文を使用し、Python 3.xは使用しない
2. 日本語テキストにはuプレフィックスを使用:u"テキスト"
3. シバンやエンコーディング宣言を追加しない
4. spss-clemb-mcpを使用してスクリプトを実行しログを取得(-logオプション推奨)
5. 必要に応じてibm-docs-mcpでAPIドキュメントを検索
6. 成功するまでエラーを反復的に修正
7. 検証後にストリームを.strファイルとして保存
重要なAPI使用方法:
- インポート:import modeler.api
- ストリーム取得:stream = modeler.script.stream()
- typeノード設定:setKeyedPropertyValue(u"direction", field, u"Target/Input")
- typeノード設定:setKeyedPropertyValue(u"type", field, u"Flag/Range/Set")
- フィールドインスタンス化:一時テーブルノードを実行してから削除
- モデル実行:c50_node.run([]) でナゲット生成
- ストリーム保存:taskrunner.saveStreamToFile(stream, filename)
一般的なノードタイプ:
- variablefile: CSV/データインポート
- type: フィールドタイプ定義
- filter: 行フィルタリング
- derive: 特徴量エンジニアリング
- partition: トレーニング/テスト分割
- c50: 決定木分類器
- neuralnet: ニューラルネットワーク
- logisticregression: ロジスティック回帰
- analysis: モデル評価
- table: 結果出力
重要な制約事項:
- モデル作成ノード(c50等)は直接テーブルノードに接続不可
- モデルを実行してナゲット(applyc50等)を生成してから接続
- typeノードでフィールドを設定後、一時テーブルで実行してインスタンス化
常に以下を確認:
- 日本語データの場合、エンコーディングはUTF-8
- フィールドタイプがデータと一致(連続、カテゴリなど)
- ターゲットフィールドが適切に定義されている
- モデルパラメータがタスクに適している
- 出力ノードが正しく設定されている
カスタムモードの設定方法
カスタムモードには、グローバルモードとプロジェクトモードの2種類があります。
グローバルモード vs プロジェクトモード
| 項目 | グローバルモード | プロジェクトモード |
|---|---|---|
| 有効範囲 | すべてのプロジェクトで利用可能 | 特定のプロジェクト内のみ |
| 保存場所 | ユーザー設定ディレクトリ | プロジェクト内の.bob/custom_modes.yaml
|
| 共有 | 個人の環境に依存 | プロジェクトと共にバージョン管理可能 |
| 用途 | 汎用的なモード(例:一般的なコードレビュー) | プロジェクト固有のモード(例:特定のAPI仕様) |
使い分けの基準
グローバルモードを使うべき場合
- 複数のプロジェクトで共通して使えるモード
- 個人の作業スタイルに合わせたモード
- 特定の技術スタック全般に適用できるモード
プロジェクトモードを使うべき場合
- プロジェクト固有のルールや制約があるモード
- チームメンバーと共有したいモード
- プロジェクト特有のAPI仕様やツールに依存するモード
- カスタムモードの開発・テスト段階
今回の例では、カスタムモードの開発段階であるため、Bobはプロジェクトモードで設定し、プロジェクト内の.bob/custom_modes.yamlに追加しました。プロジェクトモードで実際に使いながら改善を重ね、十分に洗練されたらグローバルモードに移行することで、他のプロジェクトでも利用できるようになります。
このアプローチにより以下のメリットがあります。
- 開発中のモードが他のプロジェクトに影響しない
- プロジェクト内で安全にテスト・改善できる
- 完成後はグローバルモードに昇格させて再利用可能
設定ファイルの確認方法
各YAMLファイルは、設定のモードタブから開くことができます。
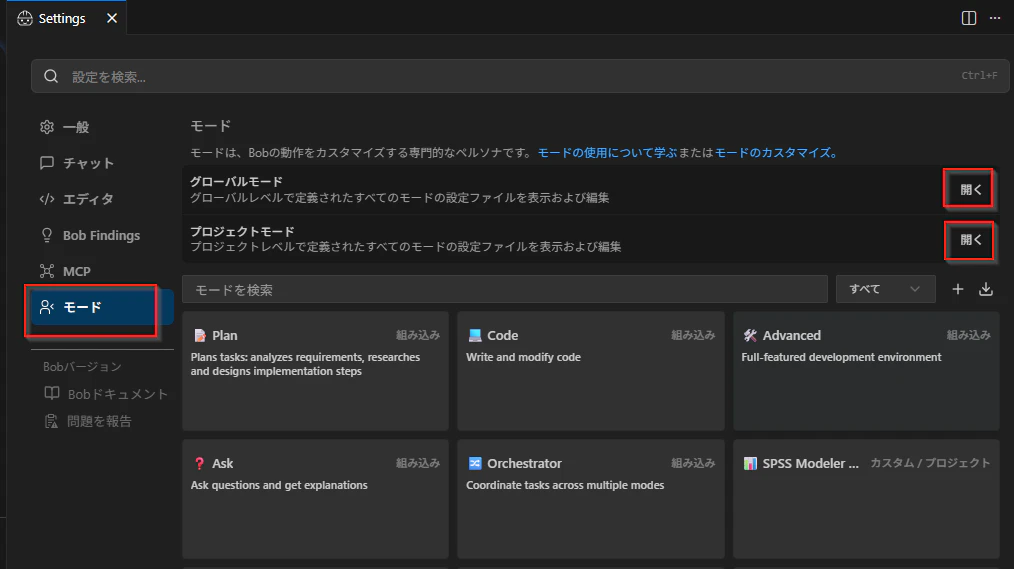
図: 設定画面からカスタムモードのYAMLファイルにアクセス可能
カスタムモードのメリット
- タスク特化型の支援: 特定のタスクに最適化された指示により、より正確な結果が得られます。
- 効率的な作業: 毎回詳細な指示を与える必要がなく、シンプルなプロンプトで複雑なタスクを実行できます。
- 知識の蓄積: 実行結果から得られた知見を継続的にカスタムモードに反映できます。
さらなる改善案
- カスタムモードの記述に重複があり冗長です。よりコンパクトにしてコンテキストを節約すべきです。
- 各ノードの操作などの細かい知識は、カスタムモード内に記述するよりもSkills(2026-04-07時点では未GA)として登録する方が、操作の確実性を高めつつコンテキストをより効率的に使えます。
まとめ
IBM Bobのカスタムモード機能を使うことで、SPSS Modelerのストリーム生成など、特定のタスクに特化したAIアシスタントを作成できます。実際に使いながら改善を重ねることで、より精度の高い支援が得られます。
カスタムモードは、以下のような場面で特に有効です。
- 繰り返し行う定型作業の自動化
- 特定のツールやフレームワークを使った開発
- 専門的知識が必要なタスク
参考リンク
カスタム・モード | Docs | IBM Bob
IBM Bob+カスタムMCPでSPSS Modelerストリームを自動生成 #SPSS_Modeler - Qiita
SPSS Modeler clemb MCPサーバー #SPSS_Modeler - Qiita
IBM Documentation検索MCPサーバー #IBMBob - Qiita