前回の記事では、Jetson Nano上でAWS IoT GreengrassのML Inferenceを試しました。
Jetson Nano Developer KitでAWS IoT GreengrassのML Inferenceを試す
ただし、前回はCPUを利用した推論が行われていました。今回は、GPUを使った推論を実行するための方法について紹介します。(この記事は前回の記事の環境ができている前提での設定となります)
MXNetをソースコードからビルド
apt-getを利用した方法だと、CUDA9向けのMXNetがインストールされるため、JetsonNanoのGPUを使いたい時に動きません。(JetsonNanoだとCUDA10の為)
そこで、同じスレッドで紹介されている通り、ソースコードからのビルドが必要になります。
細かいコマンドは、このスレッドに書かれている内容(1. Allocate swap 〜 4. Install MXNet)を参照してほしいのですが、注意点として2つあります。
- Swapfileは8Gのサイズが必要
- 手持ちが16GのSDカードだった為、空き領域が少なく試しに4GでSwapfileを作ったらビルドの途中でコケました
- 32GのSDカードを手に入れてビルドしました
- make -j3のコマンドがすごく長い
- ビルドにめっちゃ時間が掛かります。寝る前に実行して朝確認するぐらいの感じでやるといいでしょう
- 誤ってターミナルを閉じたらコマンドがコケるので、
nohup make -j3 &で、ターミナル落としても大丈夫なようにしましょう
pythonから確認
pythonのコマンドでインタプリタを開いて、GPUが利用可能か確認します
nvidia@nvidia-jetson:~$ python
Python 2.7.15+ (default, Nov 27 2018, 23:36:35)
[GCC 7.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import mxnet as mx
>>> a = mx.nd.ones((2,3), mx.gpu())
>>> print((a*2).asnumpy())
[[2. 2. 2.]
[2. 2. 2.]]
うまくインストールできたようです!
GPUのモニター
jtopというコマンドがあるので、これをインストールして使えるようにします。(READMEのインストールを参考にしてください)
sudo jtop コマンドを実行すると以下のような画面で確認できます。

Lambdaの修正
28行目の引数に context='GPU0' を追加します。
global_model = load_model.ImagenetModel(model_path, 'MXNET', 'synset.txt', 'squeezenet_v1.1')
↓
global_model = load_model.ImagenetModel(model_path, 'MXNET', 'synset.txt', 'squeezenet_v1.1', context='GPU0')
新しいバージョンをデプロイし、エイリアスの参照バージョンを変更します。
Greengrass上のLambdaの修正
Lambdaの設定変更
メモリを2GBに変更するのと、/sys ディレクトリへの読み込みアクセスを有効化する

ローカルリソースを追加
GPUを利用する場合は、LambdaからGPUリソースにアクセスする必要があるため、以下のローカルリソースの追加を行います。
| リソース名 | リソースタイプ | デバイスパス/ソースパス | 送信先パス | Lambda 関数の関連 |
|---|---|---|---|---|
| nvhost-ctrl-gpu | デバイス | /dev/nvhost-ctrl-gpu | - | 読み取りと書き込みアクセス |
| shm | ボリューム | /dev/shm | /dev/shm | 読み取りと書き込みアクセス |
| nvhost-ctrl | デバイス | /dev/nvhost-ctrl | - | 読み取りと書き込みアクセス |
| nvhost-prof-gpu | デバイス | /dev/nvhost-prof-gpu | - | 読み取りと書き込みアクセス |
| nvmap | デバイス | /dev/nvmap | - | 読み取りと書き込みアクセス |
| nvhost-dbg-gpu | デバイス | /dev/nvhost-dbg-gpu | - | 読み取りと書き込みアクセス |
設定例
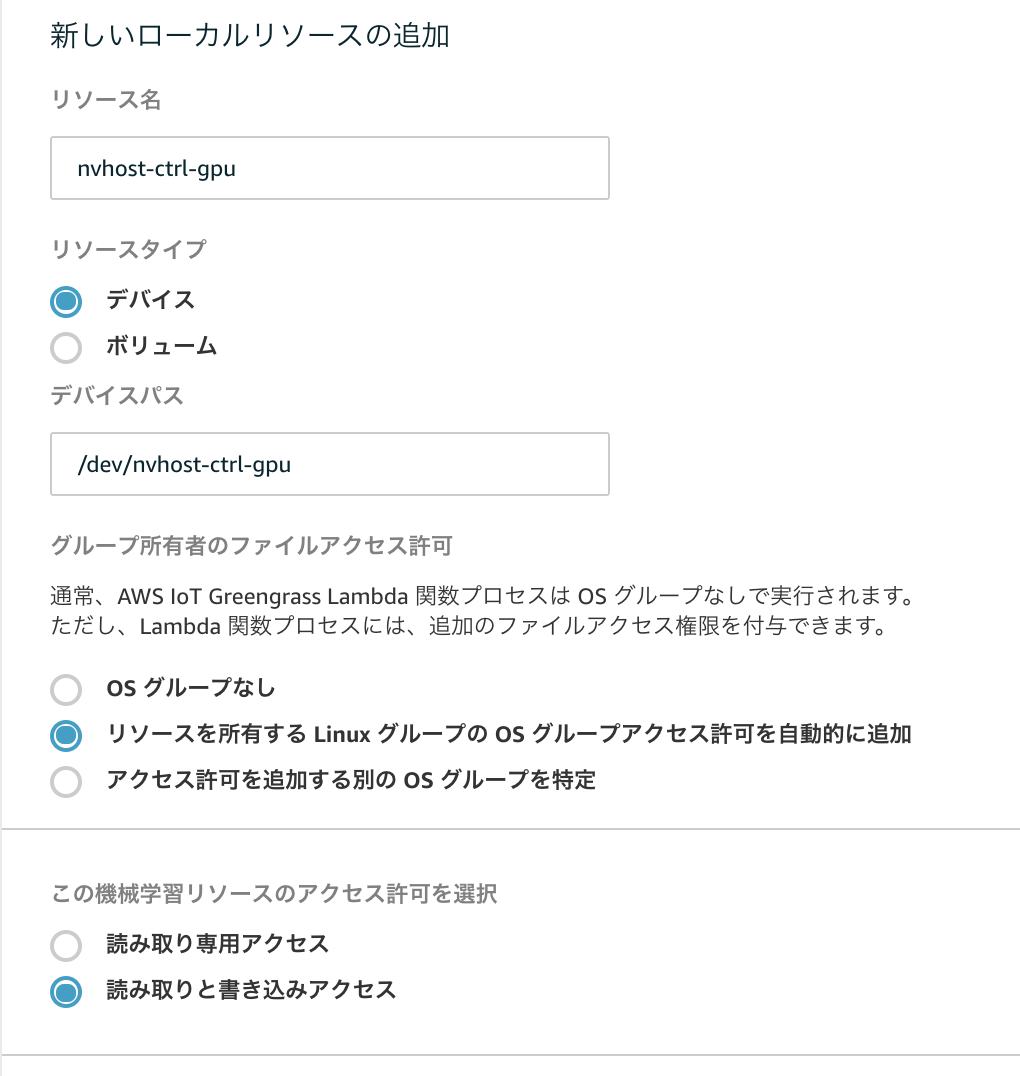
最終的にローカルリソースはこのような設定

動作確認
マネージメントコンソールからGreengrassのデプロイを実行します。
jtopでみると、GPUの使用率が上がって、使われているのがわかります。

Lambdaのコードを以下のように修正して、カメラから画像を取り出して推論する時間を出力するようにしました
42 start = time.time()
43 predictions = global_model.predict_from_cam()
44 elapsed_time = time.time() - start
45 print("elapsed_time:{}".format(elapsed_time))
GPUの場合
[2019-09-05T16:22:55.017+09:00][INFO]-elapsed_time:0.0266320705414
[2019-09-05T16:22:55.018+09:00][INFO]-[(0.11811499, 'n04372370 switch, electric switch, electrical switch'), (0.07899597, 'n03476991 hair spray'), (0.067904234, 'n04485082 tripod'), (0.066124074, 'n02783161 ballpoint, ballpoint pen, ballpen, Biro'), (0.057746205, 'n03017168 chime, bell, gong')]
CPU利用の場合
[2019-09-05T16:23:43.222+09:00][INFO]-elapsed_time:0.319680929184
[2019-09-05T16:23:43.223+09:00][INFO]-[(0.1585841, 'n04372370 switch, electric switch, electrical switch'), (0.07223587, 'n02783161 ballpoint, ballpoint pen, ballpen, Biro'), (0.059364777, 'n03476991 hair spray'), (0.056694258, 'n03876231 paintbrush'), (0.051916137, 'n03804744 nail')]
GPUだと推論にかかった時間がelapsed_time:0.0266320705414ですが、CPU利用の場合はelapsed_time:0.319680929184と、10倍ぐらい早くなっているのが確認できました。
まとめ
GPUを使うとかなり早くなりますね。
Greengrassのドキュメントに書かれているリソースとは違ったので、指定するローカルリソースを調べるのはなかなか大変ですが、今回はstraceコマンドを使って、何にアクセスしているかを確認して設定しました。
免責
発言内容は個人的な意見であり、所属する企業を代表するものではありません。
掲載しているソースコードは、サンプルレベルの物ですので動作を保証するものではありません。