MNISTとは?
手書き文字を識別するMachine Learningのときに使われれるデータです。
これはアメリカ国立標準技術研究所から提供されたものです。
文字のデータとは?
MINSTでは28x28、0から255までのデータになります。トレーニングデータは60000枚があり、テストデータは10000枚があります。
一番濃いのは1、一番薄いのは0になります。
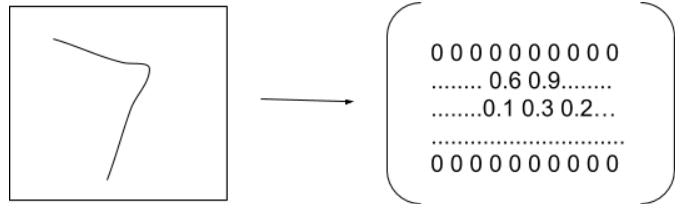
そして28x28の画像データを水平に展開します。(784になります)
そしてこの画像データは実際なんの数字なのか?
0~9なので、長さ10の配列の中にもし3だったら3番目が1になる…みたいな感じです。

ニューラルネットワーク
人間の頭の中には10億以上の神経細胞でニューロンでつなげて情報を伝えています。そして人工ニューラルネットワーク(パーセプトロン)は刺激によって0かまた1かを出力する、人間の頭をシミュレーションできるではないか?と。
単層
複数の入力Nodeをそれぞれの重み(連結強度)をかけバイアスを超えると発火。そのあと0~1の間に出力するように(活性化関数)が考えられ性能が改善された。(Relu,softmaxなど)
多層
いわゆる単相を重ねることです。4層以上になるとDeep Learningにも言われます。
そして今回使うの層の構成はこうになります:

流れ
- データを収集する
- データを正規化する
- モデルの定義
- 最適化手法と損失関数などの定義
- トレーニング
- 精度の検証
環境設定
今回はANACONDAを使います。まず仮想環境を作って起動し、Tensorflowをインストールします。
conda info -e
activate tf
pip install tensorflow
データを収集する
今回はGoogleのサーバーからダンロードしますが、実際使うとカメラの画像とかWEBからどかいろんな手があります。
データセットの中身は、
x:手書き数字画像(28×28)
y:正解のラベル(xの画像が表す数字)
なので:
(x_train, y_train):モデルの学習用
(x_test, y_test):モデルの評価用
import tensorflow
from tensorflow import keras
import matplotlib.pyplot as plt
batch_size=128
num_class=10
epochs=20
(x_train,y_train),(x_test,y_test)=keras.datasets.mnist.load_data()
ではダンロードされたデータをみてみよう。つまり60000枚のトレーニングデータがあって、10000のテストデータがあります。
len(x_train)#60000
len(x_test)#10000
そして画像を確認してみますと、うん、ありますね~
for i in range(10):
plt.subplot(2,5,i+1)
plt.title('train:{}'.format(str(i)))
plt.imshow(x_train[i].reshape(28,28),cmap=None)
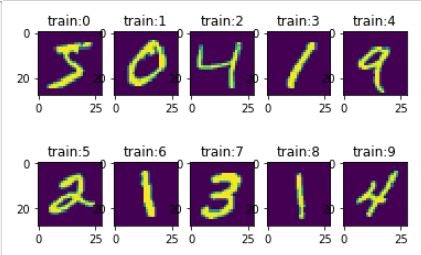
そしてラベルの一応Checkしてみよう。x_trainの画像の数字と一緒にだね。
y_train[0:10] #array([5, 0, 4, 1, 9, 2, 1, 3, 1, 4], dtype=uint8)
データを正規化する
0~1まで収めるように変換します。
x_train,x_test=x_train/255.0,y_train/255.0
モデルの定義
レイヤの定義をします。ここでSequentialモデルを使います。
# モデルの定義
models=keras.models.Sequential([
#データを直列に並びます。
keras.layers.Flatten(),
#Denseは全結合層、全ゼルから入力を受ける、activationは活性化関数、0-1の間を出力
keras.layers.Dense(512,activation='relu')
#Dropoutは20%のデータを捨てて偏りを減らす
keras.layers.Dropout(0.2),
#10個に収束します
keras.layers.Dense(10,activation='softmax')
])
Flatten
入力をフラット化します。つまり、リストの入れ子になっているデータを1つのリストに展開します。
(Ex. [[1,2,3],[4,5,6],[7],[8,9]]->[1,2,3,4,5,6,7,8,9])
最適化手法と損失関数などの定義
# 最適化の手法と繋がります
# よく使われるのはAdma,RMSprop,SGD
models.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
トレーニング
models.fit(x_train,y_train,epochs=20)
epochs?
ミニパッチ(無作為でデータを取り出す)で重み更新を繰り返す。
画像/バッチサイズ回数で更新を行います。
この例では60000枚から128つづ取り出して60000に足したら一回分のTrainingが完成って感じす。
もし過学習ならこのepochs数をへらす、未学習なら増やすって感じいかな?
精度の検証
# 学習に未使用のデータの識別能力
models.evaluate(x_test,y_test)
結果
0.9659、いわゆる97%くらいってことかな?100枚の中に3枚間違えるってことですね。
10000/10000 [==============================] - 1s 56us/sample - loss: 0.5450 - acc: 0.9659
[0.5450065596220207, 0.9659]
最後に
もし精度があがらないならLayerの構成をもう一度考え、それでもあがらないならデータを増やしたりいろいろ工夫しましょう。
kerasライブラリー
https://keras.io/ja/
matplotlib
https://matplotlib.org/api/pyplot_api.html