(注)ここでは最終結果だけでなくエラーの試行錯誤も含めて書いていきます。
また中途半端でもアップし後々更新することとします。
大目的
政府発表の文章を学習とかさせてみたいと思っています。(大雑把)
数値だけのものより日本語を含むものを読み込ませて日本語の形態素解析なんかも含めて実施したいと思います。
今回の目標
とりあえず読み込ませる
経緯
読み込む文章の選定
日銀短観や街角景気指数などが思いついたのですが、見てみると数字の羅列ばかりのため断念しました。日本語が多そうな経済白書をサンプルにしてみようと思います。
印刷用全体版のall_01.pdf~all_03.pdfを利用します。
PDFの読み込み
以下を参考にしました。
https://qiita.com/korkewriya/items/72de38fc506ab37b4f2d
https://tech.bita.jp/article/18
参考にしたサイトを見ながら作ってみます。
なお、PDFは今回DLしソースと同じフォルダに保管しました。
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from cStringIO import StringIO
(略)
エラーとなりました。
ModuleNotFoundError: No module named 'cStringIO'
from cStringIO import StringIO
がPython2用のモジュール構成のようです。 以下のように修正しました。
from io import StringIO
続きです。
def convert_pdf_to_txt(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
laparams.detect_vertical = True
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
ansStr = ""
fp = open(path, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.get_pages(fp):
interpreter.process_page(page)
str = retstr.getvalue()
ansStr = ansStr + str
fp.close()
device.close()
retstr.close()
return ansStr
ansText = convert_pdf_to_txt("all_01.pdf" )
file = open('pdf.txt', 'w')
file.write(ansText)
file.close()
これもエラーとなりました。
UnicodeEncodeError: 'cp932' codec can't encode character '\ufb01' in position 91751: illegal multibyte sequence
91751バイト目の文字が悪さをしているようです。
print(ansText[91751:91751])
で表示させてみると何も出ない、また[91750:91753]とすると「・・・」となります。
不正な文字があるようなので以下のサイトを参考にエラーを回避してみました。
https://qiita.com/butada/items/33db39ced989c2ebf644
一旦バイト列に変換(エラー無視)します。最後の4行を以下のように変更しました。
ansText = convert_pdf_to_txt("all_01.pdf", )
b = ansText.encode('cp932', 'ignore')
ansText_A = b.decode('cp932')
file = open('pdf.txt', 'w')
file.write(ansText_A)
file.close()
出力することができました。
<テキスト>
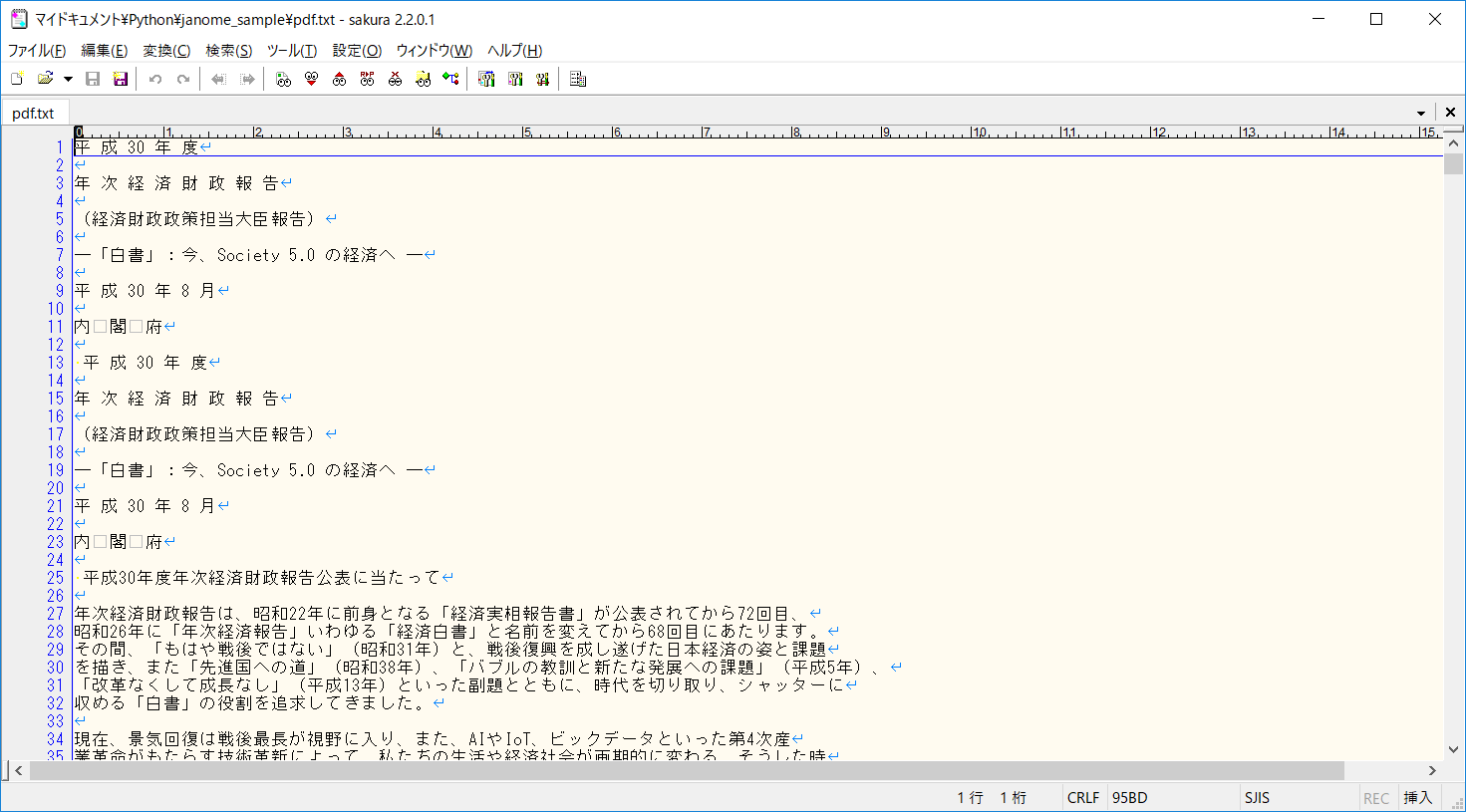
<元PDF>