要点
マルチモーダル深層学習って何?Vision-Language Modelって何?という方向けに、
Google Colabで実際に学習済みモデルを動かしながら技術概要を理解していただけるチュートリアル記事です。
マルチモーダルの時代が到来
この10年、ディープラーニングの登場により、画像の分類や、文章読解(日本語等の自然言語によるQA)などが高い精度で自動化できるようになりましたね。
しかし、画像は画像、自然言語は自然言語・・・と、それぞれに特化した手法の開発が中心で、それらが混在したマルチメディア(マルチモーダル)の問題へのチャレンジは少ない状況に長らくありました。マルチモーダルの重要性は人間の様々な知的判断の場面を思い返せば分かりますね。実課題解決において重要なAI技術分野といえます。
シングルモーダルが中心だった潮目はこの1年くらいで変わり、昨今、マルチモーダルな深層学習モデルの学術研究が急速に増えています。
今回の記事ではマルチモーダル深層学習の一つであるVL-T5という技術について紹介します。
**ただの論文紹介じゃ面白くないので、日本語化もして、誰でも使えるようモデルも公開しました。**Google Colabがあれば、すぐにお試しいただけます!
ご紹介するVL-T5は下図のように、画像と質問文を入力すると回答を文章で返してくれる深層学習モデルです。
お好きな画像と質問文で試していただくことも可能ですので、色々試して・考察して・遊んでいただければと思います。
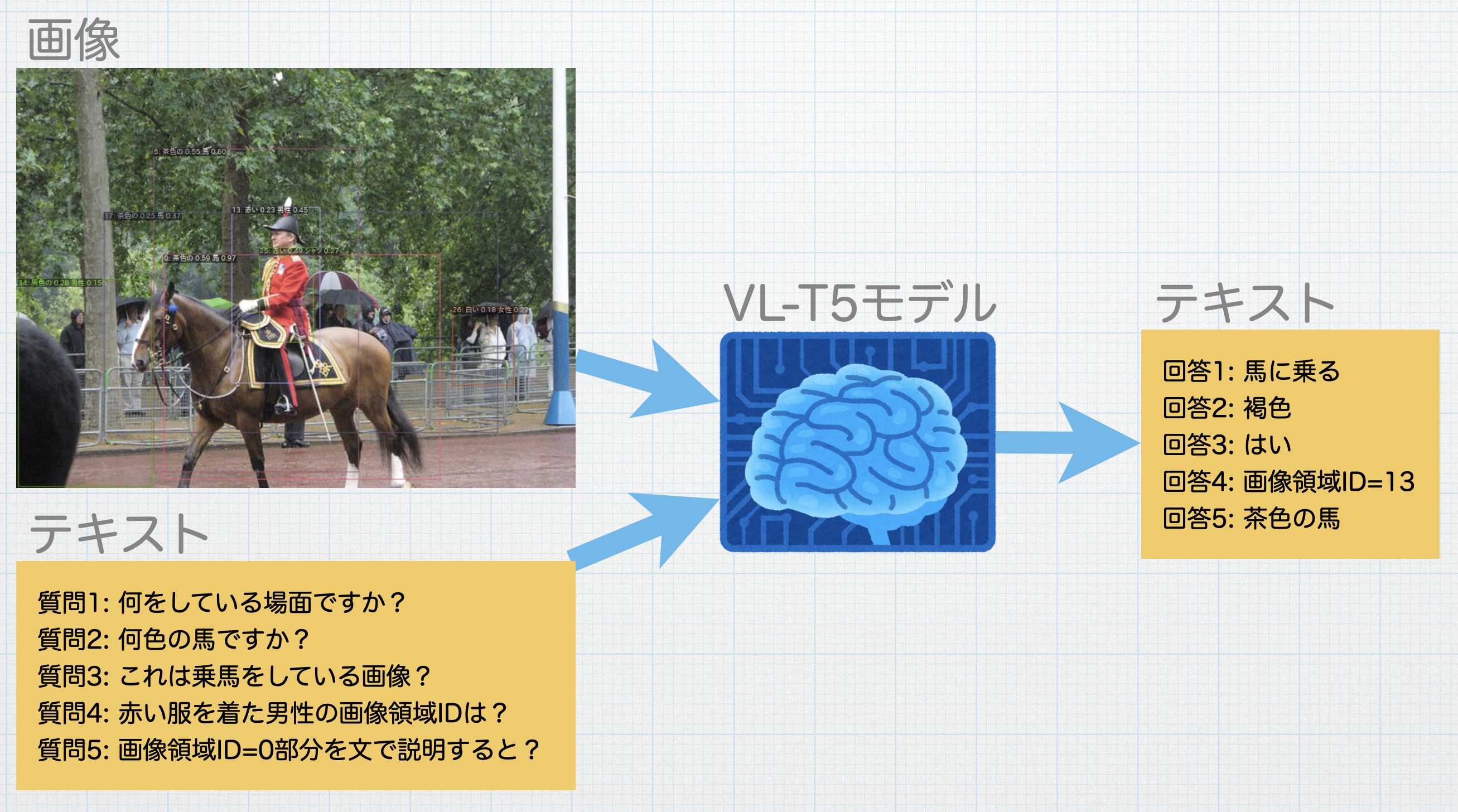
VL-T5とは?
すぐ試してみたい!という方は「動かしてみよう」の節までお進みください。
マルチモーダル深層学習とは画像やテキスト(言語)、音声、数値などなどの形態(モーダル)を複数ミックスしたデータを扱う深層学習です。
その中でも画像と言語をミックスしたデータを扱うモデルはVision-Language Model(Vision and Language modelやVisual-Language modelなど)と呼ばれます。
VL-T5のアーキテクチャ
VL-T5はVision-Language Modelの一種であり、言語用に事前学習された深層学習モデルT5(日本語モデルはこちら)をベースに、画像データも扱えるよう入力を拡張した深層学習モデルです。下図のように画像と質問文(言語データ)を受け取り、回答文(言語データ)を返すアーキテクチャになっています。
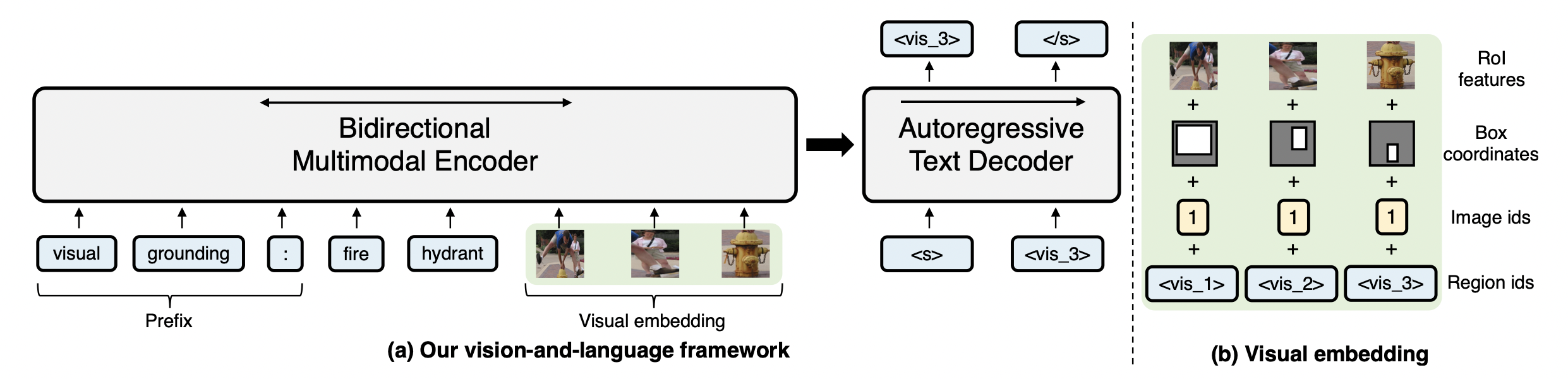
図の出典: Unifying Vision-and-Language Tasks via Text Generation
アーキテクチャのポイントは次のとおりです。
- Encoder-Decoder部分にT5モデルを用います(BARTを用いるパターンもありますが説明は省略します)。つまり、Transformer Encoderを用いて画像と言語の両モーダルのデータの関係パターンを捉え、Transformer Decoderを用いて言語データの生成パターン(作文の方法)を捉えます。
- Encoder-Decoder部分のニューラルネットワークの初期値には、言語データのみで事前学習したモデル(素の事前学習済みT5モデル)を用います。今回の日本語VL-T5モデルでは拙作の事前学習済みモデルを利用しました。
- 言語データをトークン列として表現してEncoderに入力するのはオリジナルのT5と同じです。
- 画像データは、既存の物体検出器(Faster R-CNN)を用いて検出した各物体を一つのトークンのようにみなして、Encoderに入力します。具体的には、物体検出器を用いて各物体を囲む四角の領域の画像特徴量(RoI feature)とbounding boxの座標を線形変換してできた固定長のベクトルをそのトークン相当の埋め込みベクトルとします。
- これで言語データも画像データ(正確には物体検出器により抽出された物体)も、同様にトークン列として扱うことができるようになります。
-
VL-T5の論文ではVision-Languageに関するマルチタスク学習を事前学習として行い、その後に個別タスクへのファインチューニングを行っています。今回の日本語VL-T5モデルは、日本語データセットを作り、この事前学習相当までを行ったものになります。したがって、そのマルチタスク学習で現れた次の4種類の問題を解くことができます(正確には、いわゆるMasked Language Modelタスクも解けますが地味なので省略)。
- vqa: 画像に関する一般的な質問応答
- image text match: 説明文と画像全体の意味の一致有無予測(true/false)
- visual grounding: 与えられた説明文に対応する画像領域IDの予測
- caption region: 与えられた画像領域IDの説明文の生成
Vision-Language Modelには他にも様々あります。例えば論文 An Empirical Study of Training End-to-End Vision-and-Language Transformers にて手法が分類・整理されていますので、そこから辿るといいでしょう。
ただし、活発に学術研究が行われている状況にあり、数週ごとに新しく最高精度記録を更新するモデルが現れていますので、モデルも情報も陳腐化する速度が速い点に注意が要ります。
今回、VL-T5を検証対象に選んだ理由は扱えるタスクの幅広さです。
日本語T5の記事で述べたことですが、T5は様々なタスクを統一的に扱える高い柔軟性を持ち、かつ、性能も優れている深層ニューラルネットワークです。
VL-T5もT5と同様に高い柔軟性を備えており、今後様々実験をしてみるのに便利であるため、サクッと日本語モデルを作って、ここでご紹介した次第です。どうぞご活用ください。
なお、今回作成した日本語VL-T5モデルのおおまかな精度は次のとおりです。
※どれも回答文の一字一句完全一致で評価しているので、厳しめ評価になっています。実用上はもっと精度が高いでしょう。
- vqa: 53.6%
- image text match: 96.1%
- visual grounding: 72.7% ※正解が複数あるタスクなのに、現状、ランダムに選ばれた1個の正解との一致で評価しているので、本当はもっと精度が高いです。9割超えるくらい?
- caption region: 78.2%
余談: 何かおかしくない?
やや余談になりますが、言語のみで事前学習した深層学習モデルを、異なるモーダルである画像特徴量も入力できるように転移学習させるのって変じゃない?大丈夫なの?と思った方もおられるのではないでしょうか。
これって、人間でいうと、言葉を扱う言語野を視覚にも使うということですよね。
直感的には変ですよね。そんないい加減なことをして良いのかと。
でも実は問題ない(むしろ良い)という意外な研究結果が出ています。
この論文の主張は、人間でいうと言語野の神経回路は一切変えず、視覚刺激を言語野に通す前部分の変換処理を行う神経回路だけ学習可能にするだけで(正確には出口側もちょっと学習)、精度の高い画像認識用に言語野を使えてしまうという不思議な事実があるということです。論文では画像以外のモーダルへも適用して同様に肯定的な結果を得ています。
人間と深層学習モデルは別物でありますが、もしかしたら事故などで脳を損傷した人が様々な処理能力を回復していく過程で似たことが起こるのかもしれないという妄想が沸き起こってくる興味深い話です。
以上、余談でした。
さて、本題であるVL-T5の実験に戻りましょう。
動かしてみよう
簡単に試してみれるよう、Google Colab用Notebookと学習済み深層学習モデルを公開しました。
モデルと日本語化したソースコードはNotebookの処理で自動的にダウンロードされますので、手動でダウンロードする必要はありませんが一応リンクを載せておきます。
本節では、Google Colabの基本は知っていることを前提に、今回のNotebookの動かし方についてかいつまんで説明していきます。
まずはGoogle Colab用Notebookをブラウザで開いてください。
すべてのセルを一括実行すればOKとしたかったのですが、、、matplotlibでの日本語出力の関係で、一度ランタイムを再起動することになりますのでご注意ください。再起動をしないと図中の日本語が文字化けします。
以下、処理を順番に説明していきます。
まずはライブラリ等をインストールします。
In[1]で日本語化したソースコード等を読み込み、In[2]で依存ライブラリをインストールします。
!git clone https://github.com/sonoisa/VL-T5-ja
!pip install -q transformers==4.7.0 sentencepiece wget
matplotlibにて日本語を出力できるようにするために次の4つの処理を実行します。
日本語フォントをインストールし、それを利用するようmatplotlibの設定を変更しています。本題ではないので詳細は省略させてください。
!apt-get -y install fonts-ipafont-gothic
!rm /root/.cache/matplotlib/fontList.json
import matplotlib
MATPLOTLIBRC = matplotlib.matplotlib_fname()
!cat {MATPLOTLIBRC} \
| grep -v "#font.sans-serif" \
| grep "font.sans-serif"; \
if [ $? = 1 ]; then echo "font.sans-serif: IPAexGothic, IPAPGothic" >> {MATPLOTLIBRC}; fi
matplotlib.font_manager._rebuild()
ここまで実行したら一度、ランタイムを再起動します(「ランタイム」メニューで「ランタイムを再起動」を選択)。
仮に再起動をしないと図中の日本語が文字化けします。
もしColabのランタイムを再起動せずに設定反映するいい方法をご存知の方がおられましたら、ご教授いただけると非常に助かります。
さて、これでライブラリ等の準備が完了しましたので、本題に入っていきます。
以下、ランタイムを再起動した関係でIn[*]の番号がまた1から開始になっていますのでご注意ください。
作業ディレクトリを、GitHubからダウンロードした日本語化したソースコードや設定ファイル等が収められたディレクトリに切り替えます。
%cd VL-T5-ja/VL-T5/
推論処理の用いるデバイスを設定します。GPUがあればそれを使うようにします。
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
学習済み日本語VL-T5モデル(深層学習モデルとトークナイザーモデル)をHugging Face model hubからダウンロードします。
そのままですがmodelがVL-T5の深層学習モデルで、tokenizerがトークナイザーです。
# 学習済みモデルとトークナイザーを読み込む
from vlt5_model import VLT5Model
from vlt5_tokenizer import VLT5Tokenizer
MODEL_PATH = "sonoisa/vl-t5-base-japanese"
model = VLT5Model.from_pretrained(MODEL_PATH)
model.to(device)
model.eval()
tokenizer = VLT5Tokenizer.from_pretrained(MODEL_PATH,
max_length=24,
do_lower_case=True)
model.resize_token_embeddings(tokenizer.vocab_size)
model.tokenizer = tokenizer
次のコードでは、画像特徴量生成に用いる物体検出モデル(Faster R-CNNモデル)と物体検出結果の表示に用いる設定ファイルをダウンロードしています。
"./VG/object_vocab.txt"と"./VG/attributes_vocab.txt"は日本語訳した物体の分類ラベルと属性ラベルです。
frcnnが物体検出モデルで、image_preprocessが画像ファイルを読み込む前処理関数です。重要なのはこの2個です。
from IPython.display import clear_output, Image, display
import PIL.Image
import io
import json
import torch
import numpy as np
from inference.processing_image import Preprocess
from inference.visualizing_image import SingleImageViz
from inference.modeling_frcnn import GeneralizedRCNN
from inference.utils import Config, get_data
import unicodedata
import wget
import pickle
import os
# OBJ_URL = "https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/objects_vocab.txt"
# ATTR_URL = "https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/attributes_vocab.txt"
GQA_URL = "https://raw.githubusercontent.com/airsplay/lxmert/master/data/gqa/trainval_label2ans.json"
VQA_URL = "https://raw.githubusercontent.com/airsplay/lxmert/master/data/vqa/trainval_label2ans.json"
# objids = get_data(OBJ_URL)
# attrids = get_data(ATTR_URL)
objids = []
with open("./VG/objects_vocab.txt") as f:
for obj in f.readlines():
obj = unicodedata.normalize("NFKC", obj)
objids.append(obj.split(",")[0].lower().strip())
attrids = []
with open("./VG/attributes_vocab.txt") as f:
for attr in f.readlines():
attr = unicodedata.normalize("NFKC", attr)
attrids.append(attr.split(",")[0].lower().strip())
gqa_answers = get_data(GQA_URL)
vqa_answers = get_data(VQA_URL)
frcnn_cfg = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
frcnn = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=frcnn_cfg)
frcnn.to(device)
image_preprocess = Preprocess(frcnn_cfg)
# for visualizing output
def showarray(a, fmt='jpeg'):
a = np.uint8(np.clip(a, 0, 255))
f = io.BytesIO()
PIL.Image.fromarray(a).save(f, fmt)
display(Image(data=f.getvalue()))
次のコードで質問の対象となる画像を指定します。
デフォルトではサンプル画像をダウンロードして使用するように書かれています。
もし、自前の画像ファイルを利用する場合は、Colaboratoryにその画像ファイルをアップロードし、画像ファイルの絶対パスをimage_filename変数に指定してください(例: "/content/IMG_2178.jpeg")。
image_filename = None
# image_filename = "/content/IMG_2178.jpeg"
if image_filename is None:
# サンプル画像をダウンロードする
URL = "https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/images/input.jpg"
image_filename = wget.download(URL)
次に、デバッグの意味も込めて、物体検出器(Faster R-CNN)により抽出された画像領域の様子を見てみます。
物体検出モデルfrcnnを用いて物体検出を行った結果(物体の領域(bounding box)とその分類ラベル)をfrcnn_visualizer.draw_boxesメソッドで描画します。
frcnn_visualizer = SingleImageViz(image_filename, id2obj=objids, id2attr=attrids)
images, sizes, scales_yx = image_preprocess(image_filename)
images = images.to(device)
output_dict = frcnn(
images,
sizes,
scales_yx = scales_yx,
padding = 'max_detections',
max_detections = frcnn_cfg.max_detections,
return_tensors = 'pt'
)
# add boxes and labels to the image
frcnn_visualizer.draw_boxes(
output_dict.get("boxes"),
output_dict.get("obj_ids"),
output_dict.get("obj_probs"),
output_dict.get("attr_ids"),
output_dict.get("attr_probs"),
)
showarray(frcnn_visualizer._get_buffer())
normalized_boxes = output_dict.get("normalized_boxes")
roi_features = output_dict.get("roi_features")
例えばサンプル画像については下図のような出力結果が得られます。
少々(かなり)見にくいかもしれませんけれども、各四角が物体検出器で検出された物体です。
四角枠の左上に画像領域ID(後で大事になります)とその物体の属性ラベルと分類ラベルが確信度付きで表示されます。
- 例:「13 赤い 0.23 男性 0.45」は、画像領域ID=13、23%の確信度で赤く、45%の確信度で男性であることを意味しています。
この各画像領域(常に36個あります)について画像特徴量(roi_features変数に格納された固定長のベクトル)が計算され、その36個の系列が文字トークンと同様にVL-T5に入力されることになります。
ここで物体検出が上手くいっていないようであれば、その後段となるVL-T5による回答もうまくいきません。

次は質問文を準備します。
今回用意した学習済み日本語VL-T5モデルでは次の4種類の質問に答えることができます。
- vqa: 画像に関する質問応答
- image text match: 説明文と画像全体の意味の一致有無予測(true/false)
- visual grounding: 与えられた説明文に対応する画像領域IDの予測
- caption region: 与えられた画像領域IDの説明文の生成
各質問文には、質問の種類が分かるよう、先頭に"vqa:"等のタグを付ける必要があります。
なお、質問文中の<vis_extra_id_XX>は画像領域ID=XXを表す特別なトークンです。
questions = [
"vqa: 主に何をしていますか?",
"vqa: 馬の上の人が着ている服は何色ですか?",
"vqa: 何色の馬ですか?",
"vqa: 人間は何人いますか?",
"vqa: 馬は何頭いますか?",
"vqa: 茶色の馬はいますか?",
"vqa: 褐色の馬はいますか?",
"vqa: 灰色の馬はいますか?",
"image text match: 乗馬をしている",
"image text match: 乗馬をしていない",
"image text match: 海辺",
"image text match: 公園",
"image text match: オリンピック",
"image text match: 近代5種競技",
"visual grounding: 中央の馬",
"visual grounding: 茶色の馬",
"visual grounding: 男性",
"visual grounding: 乗馬している人",
"visual grounding: 歩道で見ている人",
"caption region: <vis_extra_id_17>",
"caption region: <vis_extra_id_0>",
"caption region: <vis_extra_id_13>",
"caption region: <vis_extra_id_25>",
"caption region: <vis_extra_id_26>",
]
これでVL-T5に入力される画像とテキストの準備が完了しましたので、次のコードで推論を実行し回答を得ます。
準備した画像特徴量とテキストを引数にmodel.generateメソッドで回答文を生成しています。
tokenizer.batch_decodeメソッドでトークン列を文字列に変換しています。
後々での可視化処理のため、回答文に現れた画像領域IDをbox_ids変数に入れています。
全体の処理の流れは非常にシンプルですね。
引き続き、次節でこの推論処理の結果について考察していきます。
import re
box_ids = set()
for question in questions:
input_ids = tokenizer(question, return_tensors='pt', padding=True).input_ids.to(device)
vis_feats = roi_features.to(device)
boxes = normalized_boxes.to(device)
output = model.generate(
input_ids=input_ids,
vis_inputs=(vis_feats, boxes),
)
generated_sent = tokenizer.batch_decode(output, skip_special_tokens=False)[0]
generated_sent = re.sub("[ ]*(<pad>|</s>)[ ]*", "", generated_sent)
if "<vis_extra_id_" in generated_sent:
match = re.match(r"<vis_extra_id_(\d+)>", generated_sent)
box_id = int(match.group(1))
box_ids.add(box_id)
print(f"{question}")
print(f" -> {generated_sent}")
動作結果を見て、考察してみよう
サンプル画像に関する質問文の推論結果(全量)は次のようになります。
奇数行目が質問文、その次の行の矢印の右側が推論結果(回答)です。
これらを質問文の種類ごとに分けて考察していくことにします。
vqa: 主に何をしていますか?
-> 馬に乗る
vqa: 馬の上の人が着ている服は何色ですか?
-> 赤
vqa: 何色の馬ですか?
-> 褐色
vqa: 人間は何人いますか?
-> 3
vqa: 馬は何頭いますか?
-> 2
vqa: 茶色の馬はいますか?
-> はい
vqa: 褐色の馬はいますか?
-> はい
vqa: 灰色の馬はいますか?
-> いいえ
image text match: 乗馬をしている
-> true
image text match: 乗馬をしていない
-> true
image text match: 海辺
-> false
image text match: 公園
-> false
image text match: オリンピック
-> false
image text match: 近代5種競技
-> true
visual grounding: 中央の馬
-> <vis_extra_id_0>
visual grounding: 茶色の馬
-> <vis_extra_id_5>
visual grounding: 男性
-> <vis_extra_id_13>
visual grounding: 乗馬している人
-> <vis_extra_id_13>
visual grounding: 歩道で見ている人
-> <vis_extra_id_34>
caption region: <vis_extra_id_17>
-> 茶色の人々
caption region: <vis_extra_id_0>
-> 茶色の馬
caption region: <vis_extra_id_13>
-> 赤い男性
caption region: <vis_extra_id_25>
-> 赤いジャケット
caption region: <vis_extra_id_26>
-> 立っている女性
1. vqa: 画像に関する質問応答
まずは画像に関する幅広い質問に答える問題について回答(推論)結果を見てみましょう。
シャープ(#)マークの右側が正解・不正解の評価を含む私のコメントです。
vqa: 主に何をしていますか?
-> 馬に乗る # 正解!
vqa: 馬の上の人が着ている服は何色ですか?
-> 赤 # 正解!
vqa: 何色の馬ですか?
-> 褐色 # 正解!
vqa: 人間は何人いますか?
-> 3 # 外れ!数勘定は苦手のようです。
vqa: 馬は何頭いますか?
-> 2 # 外れ!左下の丸いのが一瞬馬かと思いましたが、よく見たら人間の後頭部のようです。
vqa: 茶色の馬はいますか?
-> はい # 正解!
vqa: 褐色の馬はいますか?
-> はい # 正解!茶色≒褐色です。
vqa: 灰色の馬はいますか?
-> いいえ # 正解!いないこともチェックできているのが偉いです。
傾向を分析してみましょう。数勘定以外は正解していますね。
数勘定が苦手である理由としていくつかの可能性があると考えます。
- 一つは、画像の情報は一旦物体検出器(Faster R-CNN)を用いて物体を捉えているであろう領域に切り分けられ(下図参照)、各画像領域がそれぞれ別個のトークンのようにVL-T5モデルに入力されるアーキテクチャであることに起因するものです。物体検出のタイミングで物体を取りこぼしたり、逆に重複抽出したりしてしまうため、正確に数を勘定するのには適さない画像特徴量になっているという可能性があります。仮にVL-T5モデルの気持ちになって考えてみると、検出から漏れた物体のカウントはできないですし、重複している画像領域が多数あると(実際、多数ある)間違って多くカウントしがちになるでしょう。一般に物体検出器の出力を用いるアーキテクチャはカウント問題には不向きであることが容易に想像できますね(要検証)。とはいえ、他の問題には適した画像特徴量にはなっているので一長一短です。
2. もう一つは、訓練データの問題です。訓練データにおいて、数勘定の問題が少なかったり、その答えのパターン(個数)に偏りがある(例えば答えは1~数個に正解が多く偏っている)ため、特徴を捉える回路を十分に学習で獲得できていないという可能性です。
この画像では問題になっていませんが、実は、物体検出器を用いることによる問題は他にもあります。それは、物体検出器は固定種類の物体しか認識できないということです。具体的には下記リンク先の1,600の種類、400の属性しか認識できません。
- 認識できる物体の種類: https://github.com/sonoisa/VL-T5-ja/blob/main/VL-T5/VG/objects_vocab.txt
- 認識できる物体の属性: https://github.com/sonoisa/VL-T5-ja/blob/main/VL-T5/VG/attributes_vocab.txt
例えば、恐竜の写真を認識させようと思っても認識できません。私の場合、試してみたら「犬」と認識されてしまいました。
もし、認識できる物体の種類の少なさが問題になるケースではCLIPのように、明示的な物体の分類ラベルを用いない、より多くの種類を認識できるモデルを画像特徴量化に用いるのがいいでしょう。
2. image text match: 説明文と画像全体の意味の一致有無予測
これは与えられた画像と説明文の意味の一致有無をtrue/falseで答えるという問題です。
image text match: 乗馬をしている
-> true # 正解!
image text match: 乗馬をしていない
-> true # 不正解!理由は後述。
image text match: 海辺
-> false # 正解!
image text match: 公園
-> false # 正解?質問が悪い!どこなのでしょうか、ここは。
image text match: オリンピック
-> false # 正解?またも質問が悪い!
image text match: 近代5種競技
-> true # おや?問題が悪いけれども、近代5種競技の馬術競技の雰囲気に似ていなくもない。
後半質問が悪くてごめんなさいVL-T5さん、、、オリンピックの時期に実験していたネタなので・・・。
後半はいいとして、気を取り直して傾向を分析してみましょう。
正解してほしい質問「image text match: 乗馬をしていない -> false」が不正解(意味が一致すると誤判定)となった理由は十中八九、訓練データの作り方が原因です。現状、このタスクの負例には、正例の文章の否定形ではなく、別の画像の説明文を用いています。そのような訓練データであるから、肯定・否定といった文章の細かな意味を捉えなくても、トピックの近さを捉えるだけで当たるタスクになってしまっており、肯定・否定といった文全体の意味理解ではなく、特定の単語が含まれるかどうか程度のトピック予測器として学習されているものと思われます。(BERTのNSPと同じ問題)
脱線になりますが、それにしても、イラストあるんだろうなぁと思いつつ探すとヤハリある「いらすとや」さんの銀の弾丸感すごいですね。
近代五種:

乗馬の姿が確かにそっくりです。
3. visual grounding: 与えられた説明文に対応する画像領域IDの予測
これは与えられた説明文に相当する画像領域のIDを答える問題です。
今回は物体検出器が常に36個の画像領域を抽出するため、重なっていることがあり、正解となる画像領域は複数個あるという問題になっていますが、回答は1個だけ返すという仕様になっています。
visual grounding: 中央の馬
-> <vis_extra_id_0> # 正解!人も入ってはいますが。
visual grounding: 茶色の馬
-> <vis_extra_id_5> # 正解!人の部分が除かれています。ちょっぴり頭もですが。
visual grounding: 男性
-> <vis_extra_id_13> # 正解!これは文句なし。
visual grounding: 乗馬している人
-> <vis_extra_id_13> # 正解?答えが一意に定まらない悪い問題ですが、可能性が高いものを答えられています。
visual grounding: 歩道で見ている人
-> <vis_extra_id_34> # 正解?これも答えが一意に定まらない悪い問題ですが、答えの可能性が高いものを答えられています。
次のコードを実行すれば、回答に現れた画像領域IDに絞って枠等を表示することができます。
frcnn_visualizer = SingleImageViz(image_filename, id2obj=objids, id2attr=attrids)
# add boxes and labels to the image
frcnn_visualizer.draw_boxes(
output_dict.get("boxes"),
output_dict.get("obj_ids"),
output_dict.get("obj_probs"),
output_dict.get("attr_ids"),
output_dict.get("attr_probs"),
box_ids=box_ids
)
showarray(frcnn_visualizer._get_buffer())
実行結果は下図の通りです。答えが一意に定まらない悪い問題を除けば、高い精度で正解できていますね。

4. caption region: 与えられた画像領域IDの説明文の生成
これは与えられた画像領域IDの部分の説明文を答える問題です。
質問文の画像領域IDがどこを指しているのかは、下図をご参照ください。
caption region: <vis_extra_id_17>
-> 茶色の人々 # 不正解!中央の馬と人々のいる領域です。
caption region: <vis_extra_id_0>
-> 茶色の馬 # 正解!中央の馬の領域です。
caption region: <vis_extra_id_13>
-> 赤い男性 # 正解!馬に乗った人の領域です。
caption region: <vis_extra_id_25>
-> 赤いジャケット # 正解!馬に乗った人の洋服の領域です
caption region: <vis_extra_id_26>
-> 立っている女性 # 正解?右側の人々の領域です。肉眼では女性かどうか分かりません・・・。

結果を分析してみましょう。
質問「caption region: <vis_extra_id_17>」が「茶色の人々」になってしまったのは、おそらく馬の茶色と人々という情報が混ざってしまったからでしょう。これは物体検出器を用いて画像特徴量を作るというアーキテクチャが根本原因であると予想されます。物体検出器で四角の領域に画像を切り取り、その画像に含まれる物体や背景の情報(物体の種類情報や色などの属性情報、テクスチャなど)が丸っと一つの固定長ベクトルに押し込まれるため、馬の茶色と人々両方含まれる画像領域だとこのような「茶色の人々」という誤りが起きてしまうのでしょう。この問題の克服方法の一案は、今回のように四角領域で切り取るのではなく、Semantic Segmentationのように任意の形状で領域を切り取れる技術を用いることでしょう。
とはいえ、今回のように画像領域IDを用いて、深層学習モデルと簡単に対話できる点は物体検出器を用いるアーキテクチャの利点ですので、一長一短です。
まとめ
Vision-Language Modelの一種であるVL-T5について、日本語モデルとお試し用のColab Notebookを公開しました。
お好きな画像と質問文で試していただくことも可能ですので、色々試して・考察して・遊んでいただければと思います。
VL-T5の実験結果から分かること:
- T5同様、楽に様々なタスクを表現できる。精度も悪くない。
- 画像特徴量の生成に物体検出器を用いていることの良し悪し両面がでている。
- 良い面: 画像領域IDを用いることで、物体の場所に関するタスクを容易に定式化できる。
- 悪い面: 数勘定が苦手。認識可能な物体の種類が限定される。画像領域に複数の物体が写っている場合、特徴量が混じることによる誤認識が起こる。
マルチモーダル深層学習は活発に学術研究が行われている状況にあり、数週ごとに新しく最高精度記録を更新するモデルが現れていますので、今後の進展に期待です!

免責事項
本モデルの作者は本モデルを作成するにあたって、その内容、機能等について細心の注意を払っておりますが、モデルの出力が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。本モデルの利用により、万一、利用者に何らかの不都合や損害が発生したとしても、モデルやデータセットの作者や作者の所属組織は何らの責任を負うものではありません。利用者は本モデルやデータセットの作者や所属組織が責任を負わないことを明確にする義務があります。