transformerに関して(ざっくりまとめ)
・transformerとは
最近自然言語処理を勉強していて、transformというのを学んだので少しまとめてみました。勉強中ですので間違い等ございましたらご指摘いただけると幸いです。 transformerとは、transformerにある文字列を入力するとそれを変換して別の文字列を出力するもの。 例えば、 「"I am John Cena."」 という文字列をtransfornerに入力すると「私はジョンシナです。」とかえすみたいな感じです。形態素解析に関して
文字列はまず単語に分解する必要がある。英語の場合は、"I am John Cena."みたいに文章が単語ごとに分けられているため単語に分割する必要がないが、日本語の場合は「私はジョンシナです。」のように文章が単語で分けられていない。そこで単語単位に分解するために形態素解析を行う。形態素解析とは簡単に言うと、文章を単語単位に分割し、それぞれの形態素の品詞等を判別する作業のことです。具体的例なとして、「私はジョンシナです。」を形態素解析すると「"私","は" , "ジョンシナ","です" , "。"」となります。単語をどのようにして扱うのか??
文章を単語に分解した後、その単語はどのように扱われるのかというと数値に変換します。例えばthis = [0.2 , 0.4 , 0.5],is = [0.1 , 0.7 , 0.35]のような感じです。これらの特徴が何を表しているのかというとそれぞれの単語の特徴を表している。この[0.2 , 0.4 , 0.5]や[0.1 , 0.7 , 0.35]のことを単語ベクトルという。
単語はどのようにして単語ベクトルへ変換されるのか??
簡単に言うと解析したい自然言語をすべて形態素解析し、出てくる単語を集める。その後ワンホットエンコーディングのような感じで単語をベクトル化する。例えば今回分析したい文章で出てくる単語が「I am John Cena.」だけだったとすると
I = [ 1 , 0 , 0 , 0 ]
am = [ 0 , 1 , 0 , 0 ]
John Cena = [ 0 , 0 , 1 , 0 ]
. = [ 0 , 0 , 0 , 1 ]
のようにone-hotベクトルに変換することができる。この単語ベクトルをエンコーダーで変更する。そのことにより単語が特徴量に変更することができる。このone-hotベクトルをエンコーダーで変更したベクトルのことをembeddingベクトルと呼ぶ。
例としては
I = [ 1 , 0 , 0 , 0 ] ⇒エンコーダー⇒ $x_1$ = [0.3 , -0.3 , 0.6 , 2.2]
この$x_1$がembeddingベクトル
こんな感じの考えがここに詳しく(参考にさせていただきました。)
https://ishitonton.hatenablog.com/entry/2018/11/25/200332
文字列はどのようにして扱うのか??
これまで単語をベクトルに変換することにはできたがでは文字列はどのようにして変換されるのかというとX = "I am John Cena." ⇒ ["I", "am" ,"John Cena","."](単語に分ける)⇒ $x_1$ , $x_2$ , $x_3$ , $x_4$ (単語をベクトルに変換 $x_n$ はembeddingベクトル)⇒X = [$x_1$ , $x_2$ , $x_3$ , $x_4$] このように行列に変換される。トランスフォーマーに関して
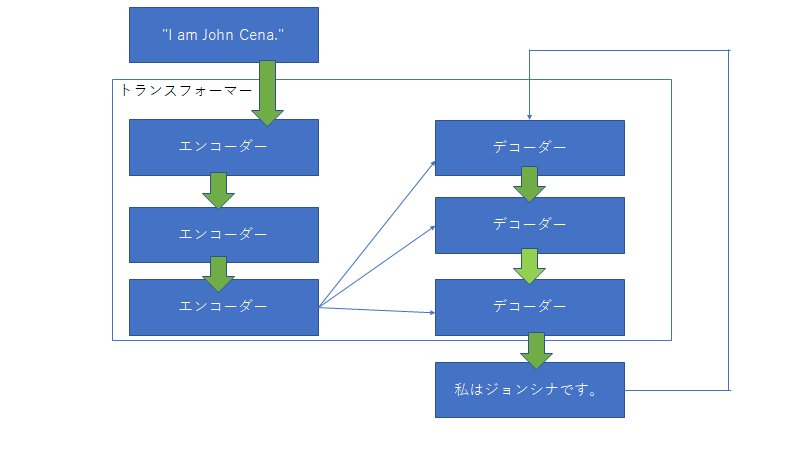
トランスフォーマーは文字列を入力するとある文字列を返すもの。中身に関していうと上図のように多くのエンコーダーとデコーダーからなる。入力された文字列はまず初めにエンコーダーに入る。エンコーダーの中身は下図
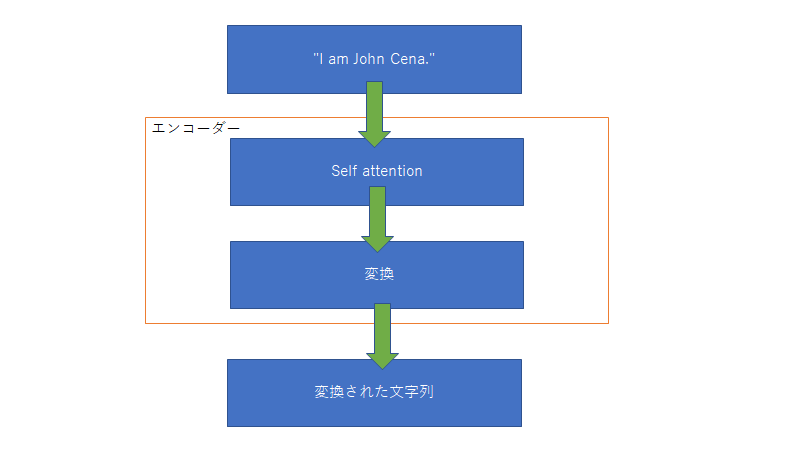
このself attentionは入力された文字列の単語同士の関係性についてみている。また単語同士の関係性が強いというのはそれぞれの単語ベクトルの類似性を見ている。そのため、類似性を調べるには行列の内積を調べればいいってことになる。そして変換は一般的なニューラルネットワークを用いて変換される。
そしてデコーダーはエンコーダーからの入力を用いて次の単語を予測する。
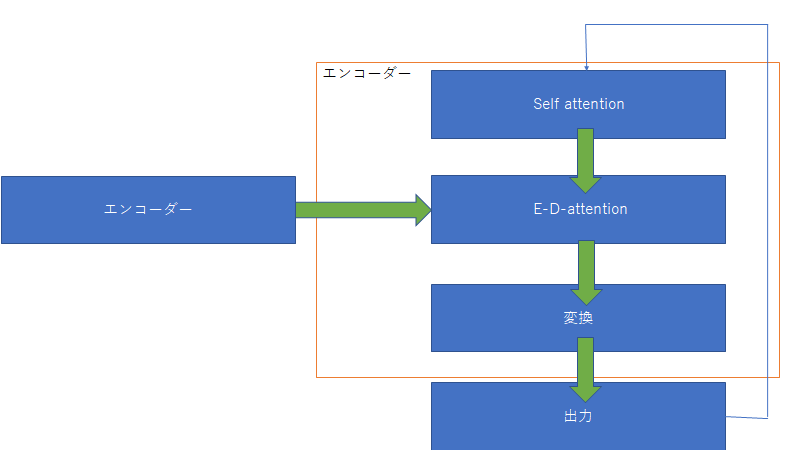
このE-D-attentionは入力と出力の関係性を見ている。
ざっくりとしたtransformerはこんな感じです。
ちゃんと知りたい方は
https://qiita.com/omiita/items/07e69aef6c156d23c538
ほぼこれを参考にさせていただきました!
めちゃくちゃわかりやすいです!
https://www.youtube.com/watch?v=BcNZRiO0_AE