こんにちは!
私はチームラボに2022新卒入社した駆け出しエンジニアです。
この度、パッケージチーム新卒エンジニアの研修の一環としてAWSに外部研修に行ってきました!
今回はその研修の概要とそこでの課題で作成した成果物について書き記しておこうと思います。
AWS JumpStart for NewGradsとは
新卒1年目のエンジニアの方々を対象とした、3日間の実践的な研修プログラムです。
将来的にAWS活用をリードする人材になるための第一歩をスムーズに踏み出せるようなコンテンツをというコンセプトで企画されているため、単なるAWSサービスの学習だけでなく、グループに分かれて要件に合った適切なアーキテクチャを検討・設計する経験を積む部分にフォーカスした内容となっています。
AWS Japan様
今年度はオンライン開催でしたが、Web系やゲーム系の企業含めて新卒1年目のエンジニアが250名以上参加する大規模なイベントになりました。
研修の概要
研修はAWSサービスやアーキテクチャ設計の説明とグループワーク、ハンズオンドリルの3構成で、以下のスケジュールで行われました。
| 1日目 | 2日目 | 3日目 | |
|---|---|---|---|
| 午前 | AWSサービスの紹介とアーキテクティング講座 | グループワーク | グループワーク |
| 午後 | グループワーク ハンズオンドリル |
グループワーク ハンズオンドリル |
成果発表会 |
グループワークは、出題された課題に対して4~5人のグループに分けてアーキテクチャ検討を行い、研修最終日に作成したアーキテクチャを発表するというものでした。
また、ハンズオンドリルではEC2を利用したスケーラブルなWebサイト構築、サーバーレスなAPI構築などを行いました。
この記事ではチームラボから参加した新卒エンジニアのうち①蕪木、②荒川、③齋藤、④ゆっきーの4人がグループワークで作成した各所属グループの成果物を紹介します!
グループワークの内容について
今回のプログラムでは、【大規模なチャットサービスを作る】想定でAWSサービスを利用したアーキテクチャ設計を検討するという課題が出題されました。課題ではチャットやデータ流量、必須機能であったり細かい要件が設定されましたが、この要件については公開NGとのことでしたので、この記事での説明は割愛いたします。これから行う4人の説明にてなんとなく感じ取ってもらえたらと思います!
①蕪木グループ
まずは蕪木のグループが作成したアーキテクチャから紹介していきます!
前提
私のグループはAWSでのインフラ構築経験が浅いメンバーがほとんどで、さあどうぞ!と課題が始まってもポカーン...状態でした。そのため、とりあえずサーバーを利用する最低限のWebサービスのためのインフラ構成を作り、その都度必要なAWSサービスを追加していくことで要件を実現しようと考えました。
そこで、まずはチャットサービスのユーザーストーリーを考え、実際の画面遷移などに落とし込んでいきました。

また、この課題には様々な要件がありましたが、私たちは以下の2つの要件を次のように解釈しました。
- スタンプ機能 → 決済機能(画像/動画投稿機能の要件が別で設定されていたため)
- 提供エリア → マルチリージョン構成(2国間で提供予定であったため)
加えて、チャットサービスで扱うデータの種類(友達、グループ、メッセージなど)に応じてDBを使い分けることにしました。
成果物
その他、細かい試行錯誤を経て3日間で作り上げたアーキテクチャがこちらです!

リージョン(青枠)が2つ、その中にAZ(赤枠)が2つ、そしてELBからサーバーへ...、全体としては図の一番上のユーザーからルート53によって各リージョンに振り分けられる流れになっており、考えられうるベーシックの極みのような構成になりました。
アーキテクチャ解説
ここで、中の構成について局所的に説明していきます。

まず、サービス内のアカウント管理において認証機能は必須!だと考えられるので、認証用にCognitoを配置しました。そして、前述したようにスタンプの要件を決済機能の追加と捉えたのとユーザーのクレジットカード情報などを取得・保持するのは荷が重い...と考えたため、ストライプという外部決算サービスを使用することにしました。
元々はルート53からELB、そしてEC2にという流れでしたが、終盤にリアルタイムでチャットをするために毎秒新規メッセージ取得のためのGetリクエストをそもそも送る必要があるのか...?という話になり、急遽API gatewayも設置しました。
そして局所図左下のELBによって振り分けられたEC2によって、チャットサービスのさまざまな処理を行なっていくという流れになっています。
次にDB周りの構成についてです。
用途に応じてDBを使い分けるという意図で、まずどんなDB(サービス)があるのか調べるところから始まったグループワークでしたが、最終的にこのような配置になりました。

サービスのメイン機能チャットについてはチャット流量に関する要件が設定されていました。そのため、それを捌き切れるようにDAX(DynamoDB Accelerator)を挟んだDynamoDBにメッセージを保存する構成に設定し、保存されたメッセージの検索機能実現のためにElasticsearch(OpenSearch)を配置しました。また、アカウントやグループ管理機能のためにNeptuneを配置しました。Neptuneはフルマネージド型のグラフ DBサービスで、今回の目的でもあるチャットサービスにおいて重複しうる友達やグループというネットワーク型のデータを管理するのに最適だと考えました。最後にレプリカを作成したAuroraも配置し、Neptuneと同様に DBクラスター内に配置しました。Auroraでは前述した2種類のDBで扱わないスタンプ購入情報など、サービスに必要なその他のデータを格納することを目的としています。
以上が蕪木グループのアーキテクチャ図の説明になります!
改善点
前述した通り、リアルタイムでのチャット機能実現のため、WebSocket APIを使えるAPI gatewayを設置しました。このサービスによって、リアルタイムの双方向通信の実現を考えましたが、そもそもこれを使用する場合EC2などのサーバー配置構成が必要なく、サーバーレスな構成の方が適しているように思います。また、必要のない限りはパブリックサブネットに置かない!という精神のもと、サーバーやDBなどを全てプライベートサブネットに配置しましたが、時間に余裕があればAWS WAFなどのセキュリティ対策のためのサービスの設置を検討してもよかったのかなと思いました。最後に、今回は要件にあった機能実現のために必要なサービスを考え、このアーキテキクチャに落とし込んでいきましたが、サービスごとの使用料金などを度外視していたため実用的な設計になっているかどうかは検討の余地がありそうです...!
②荒川グループ
続いて荒川のグループのアーキテクチャについて紹介します!
前提
私たちのグループは、今流行りであるサーバーレスを取り入れたアーキテクチャを作る方針で進めました。
しかし、私含めグループのメンバー全員がサーバーレスのAWSのサービスに触れたことがない状態で、非常に苦戦しました。
それでもサーバーレスを選んだ理由としては、今流行りということもありますが、折角の学習機会なので、わからないけどどうやら便利そうなものを使ってみようというのが大きかったです。
その中で、AppSyncとLambdaのクオーター上限を引き上げることを前提として置き、この問題は一度発生しないものとして考えました。
成果物
試行錯誤の上、サーバーレスを基本として構成したアーキテクチャがこちらです。
全体図

アーキテクチャ解説
サーバーレスで、全体的にシンプルな構成にしました。
ここからもう少し詳細な紹介をしていきます。

ページ配信については、S3とAmplifyでReactの同期的なページを配信することによって実現しました。SNSアプリの既読情報の通知などもこのAmplifyのSubscriptionによって実現します。セキュリティ面についてはAWS WAFによって強化しようと考えています。
ユーザー認証については、Cognitoのよって外部プロバイダを使用することにしました。
これは、パスワードなどの機密性の高い情報を保持するより、信頼性の高い外部プロバイダに一括することにより安全なのと、今回は人数が少ない中で短い時間での実装を前提として考えているので、なおさらCognitoを使うことが最善だと考えました。

画像上半分が、投稿データのフローです。
投稿されたデータは、まずDynamoDBに保存します。保存する内容としては、
・メッセージ
・画像、動画、スタンプのURL
・既読情報
の3つです。
検索機能の実装は、Dynamo DBに保存されたデータをLambdaでOpen Searchに転送して実現します。
ちなみにこのOpen SearchはマルチAZ構成にする予定です。
画像下半分が、ユーザーデータのフローです。
一度Dynamo DBに保存し、それをLambdaを使用してAuroraに転送する想定です。
Auroraを使いたい理由として、友達情報などはAuroraのようなRDBMSを使うのが便利と考えたためです。
しかしAuroraは書き込みがそこまで強くないため、一度Dynamo DBに保存し、それをLambdaで流すという処理にしました。
検索機能の実装にはLambdaを使用する予定です。
改善点
今回AppSyncとLambdaのクオーター上限は前提として問題にならないとしましたが、ここは検討しなければいけない点だと思います。なかなか難しいですが、、、
また、システム監視の検討についても考えなければいけない点です。現在のアーキテクチャだと、保守性が低いので監視設定は必須だと考えます。こちらは、何を使用するかから考える必要があると思います。
最後に、コスト面での検討も考えなければいけない点です。サーバーレスの構成にしたので、コストの算出が非常に難しく実際に稼働しなければわからない点が数多くあります。こちらも今後検討する必要がありそうです。
③齋藤グループ
続いて齋藤が参加したグループで作成した成果物について紹介していきます!
前提
私達のグループは、業務で触れたことのあるAWSサービスについてある程度の知見はあるものの、
アーキテクチャ全体の設計や適切なAWSサービスを選んだ経験はないといった状況でした。
そのため、ハンズオンの内容も参考に要件を満たす最小構成のアーキテクチャを作成した後、
アーキテクチャの問題点や追加したい機能等を詰めブラッシュアップしていく形で検討を進めました。
※ 参考に初日に考えた最小構成のアーキテクチャ図はこちらになります!

また、必須要件やこのチャットサービスの開発チームが置かれている状況を想像して、グループで独自に以下の想定を加えました。
- 複数の国のユーザ間でチャットできる必要がある
- 開発メンバーが少ない!
- 「3日でアーキテクチャを仕上げる」という課題だったので、開発リソースも少ないのでは、というある種の縛りを設けました。
↑ の前提のもと、私達のグループでは、
「少ない開発メンバーであっても高い信頼性・スケーラビリティ・パフォーマンスを担保する設計」
にこだわり、AWSのマネージドサービスを積極的に活用することにしました。
成果物
3日間のグループワークを経て最終的なアーキテクチャ図は以下のようになりました!
※ 初期からブラッシュアップを重ね、数えて7世代目のアーキテクチャとなりました。

全体としては、一部のグローバルで共有できるリソース・サービスを除き
同じサービスをそれぞれのリージョンに複製する形でマルチリージョン構成を実現しています。
これにより「複数の国をまたいだユーザ間でチャットできる必要がある」という想定を満たすような作りとなっています。
単一リージョンに注目すると、機能によって大きく3層の構造に分けることができます。
| 名称 | AWSサービス |
|---|---|
| 配信・LB | CloudFront, ELB (ALB), S3, Lambda@Edge, WAF |
| コンテナ | ECS(Fargate + Auto Scaling) |
| DB | DynamoDB, RDS Aurora |
配信・LB層でアクセスを受け取り、
コンテナ層でチャットサービスの処理をしてDB層にデータを貯める、
静的コンテンツは配信・LB層からそのまま配信する、
といった流れでリクエストを処理していくようになっています!
アーキテクチャ解説
アーキテクチャ検討の中で特にこだわった部分について詳しく見ていきます。
1. データの性質に応じて保存先を分ける
チャットサービスでチャットをするにあたって、チャットメッセージだけでなく、
アカウント・グループの情報や既読管理などのデータを保管し、アクセスできる必要があります。
特にチャットメッセージは膨大な量となるため、性能や料金面で適切なサービスを考える必要があります。
そこで、「データの性質に応じて保存先を分ける」ことによってこれらの問題を解決しようと考えました。
チャットメッセージについては、AWSのNoSQLサービスである「DynamoDB」を利用することにしました。
決め手としては、容量が無制限であることやフルマネージドサービスであることが挙げられます。
細かい要件には言及しませんが、複数の国で利用され、チャットという性質上メッセージという比較的小さなテキストデータが大量にやり取りされるということで、
容量無制限であることはほぼ必須かなと考えました。
アカウント・グループ・既読管理については、リレーショナルDBである「RDS Aurora」を利用しました。
関係を保持する部分までDynamoDBにはせずRDBMSに任せる、という方針にしました。開発リソースが限られている想定のためDynamoDBで頑張るのではなく広く実績のあるRDBを採用し、
AWSが推奨していることと後述のGlobal Databaseの機能を利用するためAuroraを選択しました。
(リレーションを張る・検索をする、といった観点からもRDBのほうが得意なのかな、ともグループでは考えていました)
こだわったポイントとしては、DBへの負荷を軽減できるのでは?と考えRDSとECSの間にElastiCacheを入れている部分になります。
(後々調べたところ、今回のようなケースではヒット率が低くなり効果が現れにくいとのことでした)

2. マルチリージョンでのチャットデータ共有
複数の国のユーザ間でチャットを実現するためにマルチリージョン構成としていますが、
どのようにチャットデータを共有するかが問題となります。これは、AWSが提供している機能を利用することで解決しました。
以下で簡単に紹介したいと思います!
- DynamoDB Global Tables
- 「フルマネージドのマルチリージョン、マルチアクティブのグローバルデータベース」
- リージョン間でデータをレプリケートして更新の競合を解消する作業が必要ない!
- RDS Aurora Global Database
- 「単一の Amazon Aurora データベースを複数の AWS リージョンにまたがって運用」
- 「どのリージョンでも秒未満でデータにアクセス」
3. チャットメッセージ検索機能の実現
DynamoDBに格納されているチャットメッセージに対して検索を行うのは一筋縄ではいきません。
さすがにチャットメッセージを全件取得するわけにはいかないので、どのように行うかを検討していきました。結果として、Amazon OpenSearch Serviceを使用することにしました。
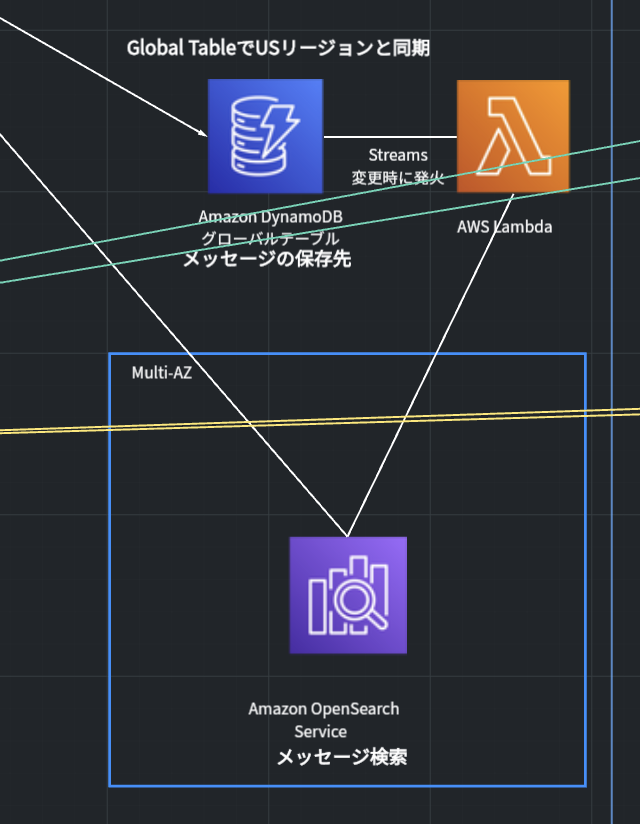
DynamoDB Streamsを利用することでDynamoDBのデータ変更時にLambdaが起動するようにし、Lambda内でDynamoDB内のメッセージデータをOpenSearchに同期することにしました。
それによってメッセージのOpenSearchへの自動反映及びOpenSearchによるチャット検索機能が実現できると考えました。
改善点
今回のアーキテクチャ検討では、開発リソースが少ないことを想定しマネージドサービスを多用する設計としていますが、
実運用を考えるとやはりコストが多くなってしまうため、コストを下げる工夫をする必要があります。
また、メッセージ交換をWebSocketで行う想定をし、ECSコンテナで全て捌き切ることを考えていましたが、具体的にどのようにやるかについては詰めきれていない部分がありました。
エンドポイントを別に用意し処理させる・AWS AppSyncを採用するなどすれば、より信頼性やパフォーマンスの高いアーキテクチャとなったのかも、と振り返って思います。
より深い検討が必要な部分としては、監視とバックアップ部分があると思います。時間的制約もあり、CloudWatchやAWS Backupのアイコンを配置して終わってしまっていますが、
どのような項目を監視するのか、どうバックアップを行うのかなどを詰めていく必要があるかなと思います。
④ゆっきーグループ
こんにちは!!ゆっきーです!!この章では私たちのグループの考えた前提とそれを踏まえて考えたアーキテクチャを紹介します!
前提
私たちのグループでは、与えられたパラメータに忠実に高可用性を担保することを意識しながらアーキテクチャを考えていきました。以下に実際にどのパラメータに対してどのように考えたのかを示します。
チャット流量
L○NE並の流量を誇るそうです。秒間接続数とかクオーターはもちろん、DBもそれなりのサイズのものを用意しないと対応できなくなりそうです。
データ流量
多いことはわかりましたが、具体的にどう対処すべきか私たちにはわかりませんでした。
メッセージ保存期間
「指定期間は保存できなければならない」と「ある期間経ったら保存する必要はない」の二通りの捉え方があると考えました。運営がどっちを意図したのかはわかりませんが、私たちは後者の方針で進めることにしました。
ピーク時間帯
特定の時間にアクセスが集中するとのことです。時間をトリガーにしてオートスケールできると良さそうですね。
提供エリア
複数の国とのことで一筋縄ではいかなそうです。マネージドサービスに頼れる部分はマネージドサービスに頼って実装を楽にしたいですね。
フロントエンド配信プラットフォーム
昨今のNext.js(Nuxt.js)の流行り様を考えると、今回の開発もこの辺から選ぶことになりそうです。とすると、単なる静的ページホスティングに加えてコンピューティングリソースも必要になりそうです。
チャット機能・既読管理・スタンプ
他アプリにUXで負けるわけには行かないので、リアルタイム更新に対応する必要がありそうです。サーバを介することまで考えるとWebSocketを使うことになりそうです。
アカウント管理
セキュアかつマネージドに実現したいので、自力実装ではなく既にある認証基盤を活用したいです。
メタ情報管理
今回はマルチリージョンにする必要があるため、その辺をマネージドに実装できるDBがあると嬉しいです。また、メタ情報はさまざまなクエリで検索されることが予想されるため、RDBの中からDBを選びたいです。
画像・動画配信
配信はストレージとCDNを使って配信するとして、アップロードはどうしましょうか。表示するサムネイルは統一したいですし、ストレージ配置前にサムネイル作成ができると嬉しそうです。
通知
実装しても良いとは思いますが、楽できるなら楽したいです。AWSだとSNS当たりが使える気がします。
チャット検索
自力実装でも良いのですが、今回の要件にお金は含まれていないため、せっかくなら高性能なサービスを使ってマネージドに実現したいです!
成果物
全体図
3日間、SAの方のアドバイスを受けながら調整を繰り返し、最終的に完成したアーキテクチャがこれです!

メタ情報APIをECS × Fargateのコンテナで、チャットAPIをAppSyncをメインにしたサーバーレスで実現しました。以下で詳しく説明します。
アーキテクチャ解説
メタ情報API
メタ情報APIの構成を詳しくみていきましょう!

コンピューティングをFargateに、負荷分散をALBに、DBとしてはAmazon Aurora Global Databaseを採用しています。工夫した点としては以下のようなものが挙げられます。
- Multi AZ構成にしてDRに対応した
- リードレプリカ・ElastiCacheを用いてクエリの内容をキャッシュすることで、DBへのアクセス負荷を減らした
- RDS Proxyを用いることで、Fargateからの接続数が増えDBに負荷がかかることを防いだ
チャットAPI
チャットAPIの詳細をみていきましょう!

AppSyncを用いたGraphQLをベースに、DBはDynamoDB Global Tables、画像のためのストレージにはS3を採用しています。AppSyncはWebSocketにも対応しているため、マネージドにリアルタイム通信を実現できます。また、チャットのDynamoDBへの書き込みをトリガーにDynamoDB Streamsを起動し、Lambdaを経由してOpenSearchへの書き込みを行っています。OpenSearchはチャットの検索機能において使用します。
工夫した点としては以下の様なものが挙げられます。
- 大量アクセスを捌くため、AppSyncのクオーターをあげておく。
- アップロードされた画像のサムネイルを作成するため、AppSyncとS3の間にLambdaを設けている。また、画像処理は重い処理なため、負荷分散のためにSQSによるキューイングを行っている。
改善点
料金周りについてまだ検討の余地があるように感じました。特に、RDS Proxyの料金は高いため、本当に必要になってから導入を検討する、とかで良いように思います。
また、今回は自分らのグループの方針でAWSにサービスを限定しましたが、実際に実装するときは他社のサービスもうまく使ってコスト面や実装しやすさを調整していくと良さそうだと感じました。
感想
タイトなスケジュールで実施された3日間の研修でしたが、1からサービスを設計するという新卒エンジニアではできないような体験ができました!また、様々な企業から来た多くの参加者たちで行ったグループワークや発表は、同世代のエンジニアたちとコミュニケーションをとる良い機会になったと思います。加えて、この記事にもあるようにグループごとに様々なアーキテクチャを見ることができ、共通の要件であっても様々なソリューションがあることを実感できました!
最後に、学びの多いイベントとなりましたが、これからはこの経験を実務に活かしチームラボのソリューションをよりレベルアップしていきたいです!